Robot Coverage Control by Neuromodulation
9
0
0
Texte intégral
Figure
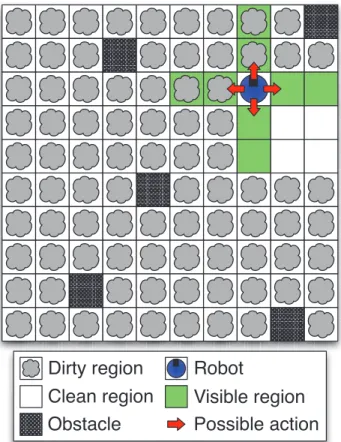

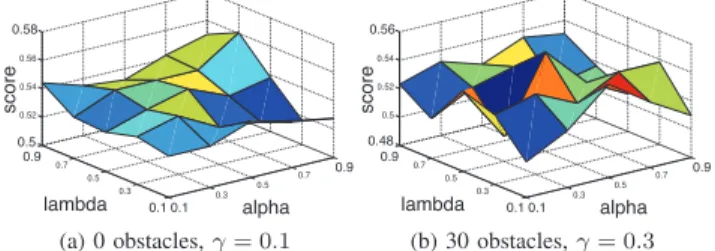

+2

Documents relatifs
