Distributed Slicing in Dynamic Systems
Texte intégral
Figure
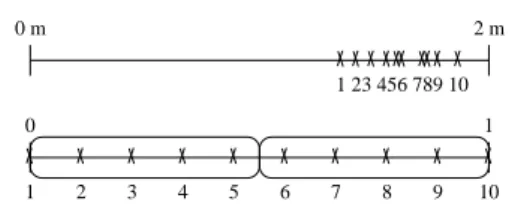

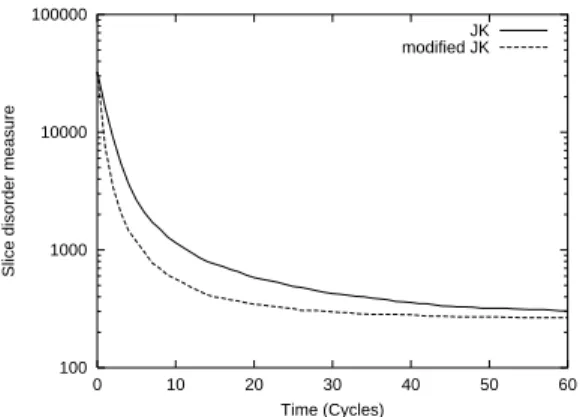
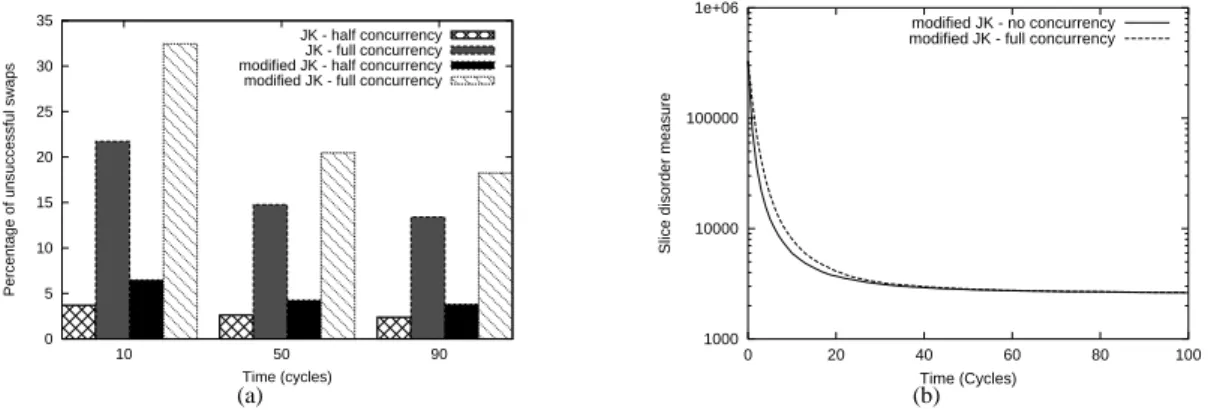

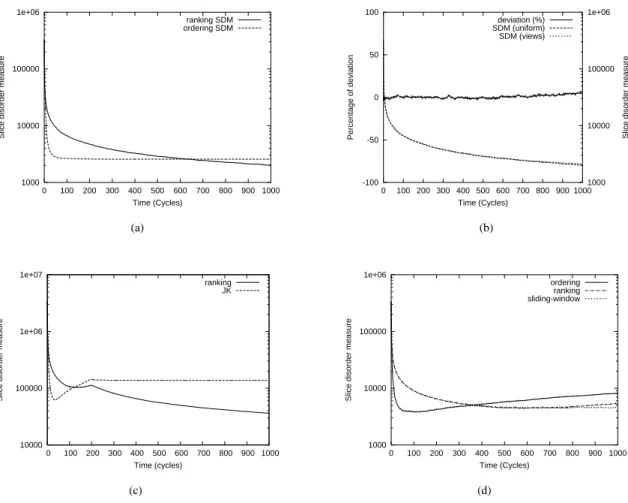
Documents relatifs
In the related work section, we will explain why most of previous work dealing with Distributed Virtual Reality over a Grid (DVR-G) are not suitable for our in virtuo
The design values for allowable projected heat flux density spans from 2 to 4.7 MW/m² (Fig. 1), the panels with a higher heat load capacity being used in heavily loaded wall
For dispersion curve inversion, physical conditions between parameters V s and V p (linked by Poisson’s ratio) may limit the parameter space with complex boundaries.. Other
Unit´e de recherche INRIA Rennes, Irisa, Campus universitaire de Beaulieu, 35042 RENNES Cedex Unit´e de recherche INRIA Rhˆone-Alpes, 655, avenue de l’Europe, 38330 MONTBONNOT ST
Evaluating self-reported pressure ulcer prevention measures in persons with spinal cord injury using the revised Skin Management Needs Assessment Checklist: reliability study... Values
While the broadcast flooded the network with 8.4✂N messages, the geographic routing with its location service sent to the network 5✂N messages, and PTH sent 2.4✂N messages. Not
One special resource allocation problem however appears in dynamic systems with continuous state variables, where the allocation of a certain amount of a resource also depends on
We extend the Class Dependence Graph (ClDG) [16] of object-oriented languages to the case of HQL, and propose a refinement of dependence graph for removing false dependences
