Framework for Real-time collaboration on extensive Data Types using Strong Eventual Consistency
par
Constantin Masson
Département d’informatique et de recherche opérationnelle Faculté des arts et des sciences
Mémoire présenté à la Faculté des études supérieures en vue de l’obtention du grade de Maître en sciences (M.Sc.)
en informatique
Decembre, 2018
c
Université de Montréal Faculté des études supérieures
Ce mémoire intitulé:
Framework for Real-time collaboration on extensive Data Types using Strong Eventual Consistency
présenté par: Constantin Masson
a été évalué par un jury composé des personnes suivantes: Famelis Michalis, président-rapporteur
Eugene Syriani, directeur de recherche Boyer Michel, membre du jury
Real-time collaboration is a special case of collaboration where users work on the same artefact simultaneously and are aware of each other’s changes in real-time. Shared data should remain available and consistent while dealing with its physically distributed aspect. Strong Consistency is one approach that enforces a total order of operations using mechanisms, such as locking. This however introduces a bottleneck. In the last decade, algorithms for concurrency control have been studied to keep convergence of all replicas without locking or synchronization. Operational Transformation and Conflict-free Replicated Data Types (CRDT) are widely used to achieve this purpose. However, the complexity of these strategies makes it hard to integrate in large software, such as modeling editors, especially for complex data types like graphs. Current implementa-tions only integrate linear data, such as text. In this thesis, we present CollabServer, a framework to build collaborative environments. It features a CRDTs implementation for complex data types such as graphs and gives possibility to build other data structures.
Keywords: Concurrency Control, Concurrent Algorithms, Distributed Systems, Optimistic concurrency control, Software Engineering, Shared Data, Strong Even-tual Consistency
RÉSUMÉ
La collaboration en temps réel est un cas spécial de collaboration où les utilisateurs travaillent sur le même élément simultanément et sont au courant des modifications des autres utilisateurs en temps réel. Les données distribuées doivent rester disponibles et consistant tout en étant répartis sur plusieurs systèmes physiques. "Strong Consistency" est une approche qui crée un ordre total des opérations en utilisant des mécanismes tel que le "locking". Cependant, cela introduit un "bottleneck". Ces dix dernières années, les algorithmes de concurrence ont été étudiés dans le but de garder la convergence de tous les replicas sans utiliser de "locking" ni de synchronisation. "Operational Trans-formation" et "Conflict-free Replicated Data Types (CRDT)" sont utilisés dans ce but. Cependant, la complexité de ces stratégies les rend compliquées à intégrer dans des logi-cielles conséquents, comme les éditeurs de modèles, spécialement pour des data struc-tures complexes comme les graphes. Les implémentations actuelles intègrent seulement des data linéaires tel que le texte. Dans ce mémoire, nous présentons CollabServer, un framework pour construire des environnements de collaboration. Il a une implémen-tation de CRDTs pour des data structures complexes tel que les graphes et donne la possibilité de construire ses propres data structures.
Keywords: Algorithme de concurrence, Data distribuée, Génie logiciel Gestion de concurrence, Strong Eventual Consistency, Système distribués
ABSTRACT . . . iii
RÉSUMÉ . . . iv
CONTENTS . . . v
LIST OF TABLES . . . ix
LIST OF FIGURES . . . x
LIST OF APPENDICES . . . xii
LIST OF ABBREVIATIONS . . . xiii
ACKNOWLEDGMENTS . . . xiv
CHAPTER 1: INTRODUCTION . . . 1
1.1 Context . . . 1
1.2 Problem Statement and Thesis Proposition . . . 2
1.3 Contributions . . . 3
1.4 Outline . . . 3
CHAPTER 2: STATE OF THE ART . . . 4
2.1 Consistency in Distributed Systems . . . 4
2.1.1 CAP Theorem . . . 4
2.1.2 ACID properties . . . 5
2.1.3 BASE properties . . . 5
2.1.4 Strong Consistency . . . 6
2.1.5 Eventual Consistency . . . 7
2.1.6 Strong Eventual Consistency . . . 7
vi
2.2 Real-time . . . 8
2.2.1 Real-time software . . . 8
2.2.2 Real-time collaboration . . . 8
2.2.3 Requirements for collaboration . . . 9
2.3 Concurrency Control Algorithms . . . 10
2.3.1 Pessimistic Locking . . . 11
2.3.2 Optimistic concurrency control . . . 12
2.4 Existing tools . . . 16
CHAPTER 3: FEATURE MODEL FOR COLLABORATIVE ENVIRON-MENTS . . . 18
3.1 Features for collaborative environments . . . 18
3.1.1 Methodology . . . 19
3.1.2 Collaboration Scenario Support . . . 19
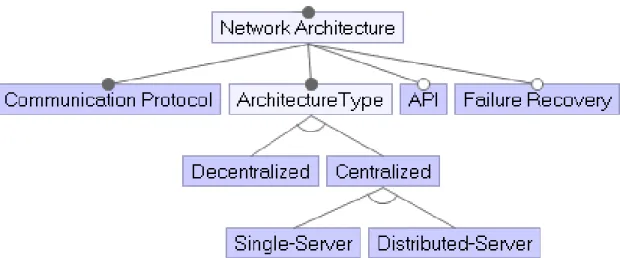
3.1.3 Concurrency . . . 21 3.1.4 Data Storage . . . 26 3.1.5 Network Architecture . . . 27 3.1.6 Conflict Management . . . 30 3.1.7 Multi-User . . . 31 3.1.8 Client Type . . . 35 3.1.9 Execution . . . 36
3.2 Examples and instantiation . . . 36
3.2.1 Obeo Designer . . . 37
3.2.2 WebGME . . . 37
3.2.3 GenMyModel . . . 38
3.2.4 MetaEdit+ . . . 38
3.3 Discussion . . . 39
3.3.1 Locking and dependencies . . . 39
3.3.2 Versioning for Models . . . 39
3.3.4 Why should we use User Presence Awareness . . . 40
3.3.5 Note about Push Notification . . . 40
CHAPTER 4: CONCURRENCY CONTROL ALGORITHM . . . 42
4.1 CollabServer CRDT algorithm implementation . . . 42
4.1.1 Operation-based CRDT . . . 42
4.1.2 Last-Writer-Wins (LWW) and timestamps . . . 44
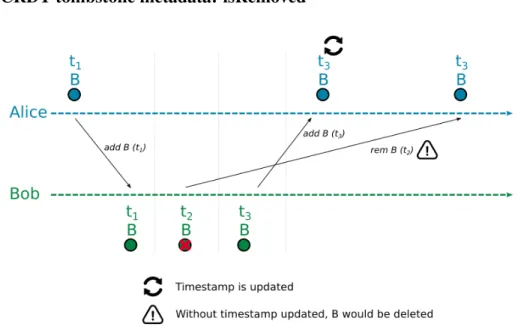
4.1.3 CRDT tombstone metadata: isRemoved . . . 45
4.1.4 Return value for CmRDT update method . . . 46
4.1.5 CRDT internal representation, iterators and special query methods 47 4.2 CollabServer CRDT Primitives . . . 47 4.2.1 LWWRegister . . . 47 4.2.2 LWWSet . . . 48 4.2.3 LWWMap . . . 54 4.2.4 LWWGraph . . . 54 4.3 Summary . . . 61
CHAPTER 5: COLLABSERVER FRAMEWORK . . . 63
5.1 Overview . . . 63
5.1.1 Requirements . . . 63
5.2 CollabServer framework architecture . . . 64
5.2.1 Data Structures: collab-data-crdts . . . 65
5.2.2 Client: collab-client-interface . . . 66
5.2.3 Server: collab-server . . . 67
5.2.4 Network: collab-common . . . 67
5.3 CollabServer framework integration . . . 68
5.3.1 Understanding CollabData Operation notification system . . . . 68
5.3.2 Create timestamp with total-order . . . 69
5.3.3 Build custom CollabData . . . 70
5.3.4 Integrate collab-client-interface . . . 71
viii
5.4.1 Timestamp . . . 72
5.4.2 SimpleGraph . . . 73
5.4.3 Integration with CollabServer . . . 73
5.4.4 Support with Modelverse database . . . 73
CHAPTER 6: EVALUATION . . . 75
6.1 CollabServer framework analysis . . . 75
6.1.1 Packages metrics description . . . 75
6.1.2 Packages metrics analysis . . . 76
6.2 Usability . . . 78
6.3 Correctness . . . 79
6.3.1 Tests covering . . . 79
6.3.2 GoogleRealtimeAPI, Yjs, and CollabServer comparison . . . . 81
6.4 Potential improvements . . . 83
6.4.1 Garbage collector . . . 83
6.4.2 LWW and offline collaboration . . . 84
6.4.3 Server optimization . . . 84
6.4.4 Security . . . 85
6.4.5 Extensive Data Type . . . 85
6.4.6 Timestamps with different timezones . . . 86
CHAPTER 7: CONCLUSION . . . 87
7.1 Summary . . . 87
7.2 Outlook . . . 88
4.I Summarize the CollabServer CRDT algorithm design choices . . 62 4.II Summarize the CollabServer CRDTs . . . 62 6.I CollabServer framework packages: table of metrics for
abstract-ness, instability, and distance . . . 77 6.II Comparative table of the supported data types in CollabServer,
LIST OF FIGURES
2.1 Example of collaboration on graph . . . 10
2.2 State-based CRDTs: example with a set of numbers . . . 15
2.3 Operation-based CRDTs: example with a set of numbers . . . 16
3.1 Top-level features and constraints . . . 18
3.2 Collaboration scenario features . . . 19
3.3 Concurrency features . . . 21
3.4 Data Storage Features . . . 26
3.5 Network Architecture Features . . . 28
3.6 Conflict Management Features . . . 30
3.7 Multi-User features . . . 32
3.8 Client Type Features . . . 35
3.9 Execution features . . . 36
4.1 CmRDT operations commutativity . . . 42
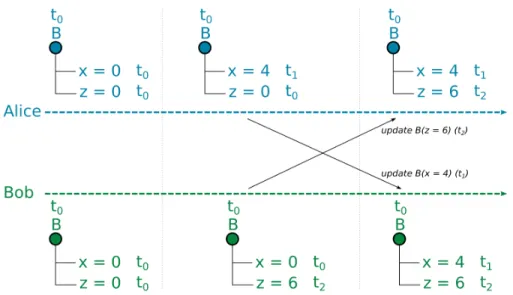
4.2 Example of fine-grained timestamps in CmRDT Graph with at-tributes . . . 43
4.3 Timstamps requirements in case of identical operations . . . 44
4.4 CRDT tombstone metadata isRemoved illustrated . . . 45
4.5 Boolean return type for CmRDT update methods . . . 46
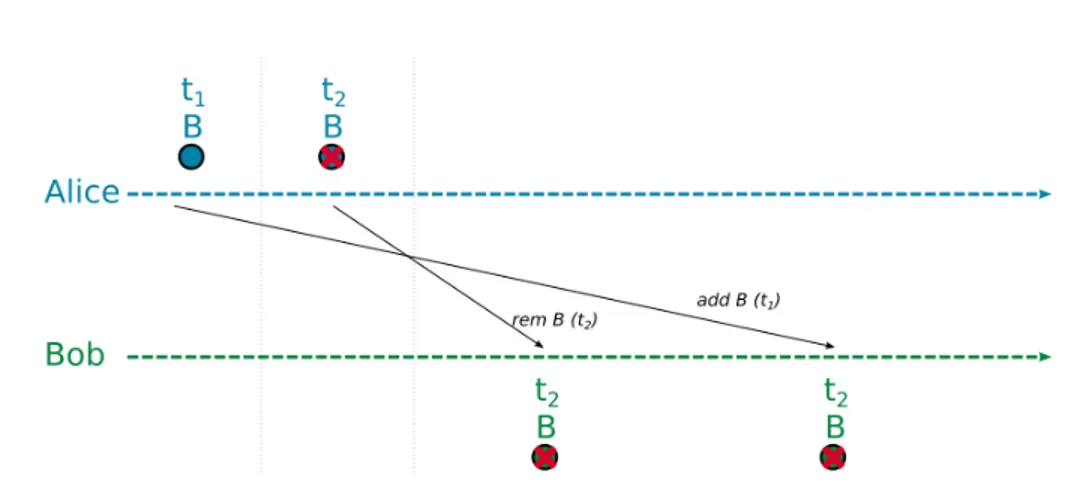
4.6 LWWRegister: example of collaboration with the update method . 48 4.7 LWWSet: example of collaboration where clear call is earlier than add timestamp . . . 49
4.8 LWWSet: example of collaboration where clear call is older than add timestamp . . . 49
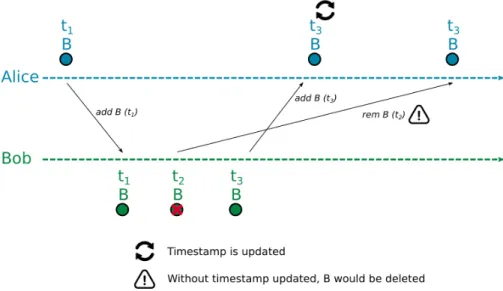
4.9 LWWSet: example of collaboration with concurrent add || add calls 51 4.10 LWWSet: example of collaboration with concurrent add || remove calls . . . 51
4.11 LWWSet: example of collaboration with remove received before add . . . 53 4.12 LWWGraph: example of addEdge with a simple case of already
existing vertices. Vertices timestamps are updated . . . 56 4.13 LWWGraph: example of addEdge with addEdge received before
addVertex. Method addEdge re-add the vertices source and desti-nation . . . 56 4.14 LWWGraph: example of concurrent addEdge and removeVertex.
Illustrate why addEdge also re-add the vertices source and desti-nation . . . 57 4.15 LWWGraph: example of concurrent addEdge and removeVertex.
Method addEdge may delete the newly created edge if one of its vertices are marked as deleted . . . 57 4.16 LWWGraph: example of removedEdge operation received before
addVertex and addEdge . . . 59 4.17 LWWGraph: example of clearVertices operation . . . 60 5.1 UML Package diagram of the CollabServer framework showing
dependencies. Packages in red are part of CollabServer. . . 64 5.2 UML Diagram for CollabData abstract class . . . 65 5.3 CollabData Operations notification system . . . 69 5.4 Example of collab-client-interface integration by several end-user
clients with different roles . . . 71 5.5 GraphEditor collaboration scenario using CollabServer framework
and Modelverse database . . . 74 6.1 AI Graph of the CollabServer packages . . . 77
LIST OF APPENDICES 1 lwwregister_update(value, timestamp) . . . 47 2 lwwset_query(key) . . . 48 3 lwwset_clear(timestamp) . . . 50 4 lwwset_add(key, timestamp) . . . 52 5 lwwset_remove(key, timestamp) . . . 53 6 lwwgraph_queryVertex(vertexID) . . . 55 7 lwwgraph_removeVertex(vertexID, timestamp) . . . 55
8 lwwgraph_addEdge(source, dest, timestamp) . . . 58
9 lwwgraph_removeEdge(source, dest, timestamp) . . . 60
10 lwwgraph_clearVertices(timestamp) . . . 61
CmRDT Commutative Replicated Data Type CvRDT Convergent Replicated Data Type
CRDT Conflict Free Replicated Data Type EC Eventual Consistency
LWW Last Writer Wins
RTC Real Time Collaboration SC Strong Consistency
ACKNOWLEDGMENTS
I would like to express my sincere gratitude to my advisor Eugene Syriani for the continuous support of my study and research, for his patience, motivation, enthusiasm, and immense knowledge. He gave me the opportunity to work as his teaching assistant, which was a great and constructive experience.
I thank my fellow labmates in the GEODES Group, for the stimulating discussions and for all the fun we have had in the last two years. Thanks to Thomas for being my awesome desk-mate during the last summer semester. I really enjoyed the discussions we had about code designs and software architectures, which helped me to design Col-labServer, in particular its networking architecture. Thanks to Nicola, Samuel, and Remi for their devotion in the student life at UdeM and for all the fun they gave us. I would like to thank Céline Bégin for her kindness and her efficiency as well as the whole UdeM administration team. Thanks to Baila and Brice for being my "poutine eater" partners during these nights of work in the lab, and thanks to "Blanche Neige Restaurant" for being our official poutines food provider. Thanks to Adrien for his help on the off-topics projects I have been working on, such as engine programming and 3D rendering. I would like to sincerely thank Michalis Famelis for his huge help in writing my cover letter and resume, that significantly helped me getting my post-master job. I thank Edouard for the really interesting discussion we have had. Thanks to Raouf for taking the time to share his immense knowledge about Linux and systems administration. Thanks to the coffee machine that gave its best during these two years to provide us with a daily coffee. Thanks to Gnu and Panda, the two plushes on my desk, for listening to my programming reflections that would have stayed in my mind without them.
Last but not the least, I would like to thank all my family, my parents, and my friends for all the support they gave me during the whole adventure. Thanks to my SSD for crashing when I needed it, fortunately, this attempt to destroy hours of work was a fail, thanks to the git backups. Thanks to the cats, dogs, raccoons, and pandas for being super funny animals that distracted me during the breaks.
INTRODUCTION
1.1 Context
In computer science, a distributed system is a network of independent computers that appears to the users as one unique system. Data and computing resources are replicated on multiple remote locations, which gives several advantages, such as fault tolerance, performance, and availability for remote users distributed geographically. In case of node failure, a transparent mechanism allows to automatically restore the system back to a valid state. Users are not aware of distribution and the whole system is seen as a unique entity. Distributed systems may require a consensus mechanism to deal with concurrency. Paxos [37] and Raft [46] are examples of common consensus algorithms in distributed systems.
Collaboration uses the same notions to provide its users a shared data that may be edited concurrently over the network. Real-time collaboration is a special case of collab-oration where users work on the same document simultaneously and are aware of other changes in real-time. However, due to the network aspect of collaboration, operations may be applied with unexpected latency due to some replicates. Therefore collaborative editing faces the technical challenge of remaining available and consistent while dealing with physically distributed data, as stated by the CAP theorem [54] described in Sec-tion 2.1.1. In any case, at the end of collaboraSec-tion, all replicates should converge to the same state. Different approaches exist in order to keep convergence. Strong Consistency enforces a total order of operations [36] so that all users see the exact same execution or-der, but requires a consensus mechanism. Locking [6] is a simple approach that has been used in collaborative environment [30, 45]. It allows only one user to concurrently edit a specific data element at a time, so that conflicts are removed altogether. It is designed for client/server architectures. Locking introduces an important bottleneck since users have to wait for a resource to be released before applying any modification. To overcome
2 this issue, several algorithms for concurrency control without locking have been studied [17, 21, 55].
Operational Transformation (OT) [18] resolves the locking problem by applying transformations on received operations. Concurrent editing is supported and users may collaborate in real-time on the same document. It is designed for client/server archi-tectures. GoogleDoc is an example of large-scale industrial software that uses OT algo-rithm. Conflict-free Replicated Data Types (CRDTs) [55] is another concurrency control algorithm that focuses on data design so that no locking is required. It is well suited for peer-to-peer architectures but may be used for client/server architectures as well.
Lock-free concurrency control algorithm implementations generally support only linear data, such as text (e.g., GoogleDoc, Etherpad). More complex and sophisticated data structures, like graph-based specifications, are hard to design and implement. The original authors of CRDT algorithm introduce an example of more advanced tree data structure, called TreeDoc [50]. Moreover, they discuss theoretically graph data types in their complementary CRDTs study [57]. There are many software applications that re-quire collaboration of more complex data. This is the case of Model-Driven Engineering (MDE) [35, 53] which uses models with strong semantics. MDE models are typically encoded as graphs due to the complexity of there relations [62].
1.2 Problem Statement and Thesis Proposition
Building collaborative environments is not an easy task. One has to design and in-tegrate features required by collaborative environments, such as network architecture, concurrency algorithm (e.g., locking, OT, CRDT), user awareness (e.g., list of current collaborators) and other possible features (e.g., undo/redo stack [11]). To ease these software design and architecture choices, we present a feature diagram for collaborative environments [42]. It may be used as a base of reflection in order to build any collabo-rative environment.
Lock-free concurrency control algorithms such as OT and CRDT are well-documented in the literature [17, 55], but their current implementations suffer from a growing
com-plexity as soon as the shared data type becomes more sophisticated. Therefore, existing software have their own implementations specific for their data structures and general purpose implementations of these algorithms are still rare and uncommon (e.g., Google-RealtimeAPI [26], YATA [44]). To achieve collaboration using such algorithms, one has to do his own implementation, which is a complex and error-prone task. Our framework tries to minimise this endeavor by providing a set of CRDTs primitives that allow the developer to integrate more advanced data types, such as graph.
1.3 Contributions
The goal of this thesis is to ease the creation of collaborative software by giving tools that hide its complexity. This thesis proposes a novel framework, called CollabServer, based on CRDT to collaborate on extensive data types. It extends the current CRDT approaches and implementations by providing a set of collaborative data primitives as building blocks to construct more complex data structures. This framework helps de-velopers build new CRDT data structures fit for their purpose. We provide an efficient implementation in C++ available online1.
1.4 Outline
This thesis is organized as follows. In Chapter 2, we introduce distributed systems principles and present existing work on real-time collaboration. In Chapter 3, we enu-merate and describe the features required for a collaborative environment. In Chapter 4, we present our CRDT implementation used by CollabServer framework. In Chapter 5, we describe the architecture of the CollabServer framework along with implementation details. In Chapter 6, we discuss the evaluation of our solution. Finally, we conclude in Chapter 7.
CHAPTER 2
STATE OF THE ART
In this chapter, we introduce the principles for distributed systems as well as some existing algorithms for collaboration.
2.1 Consistency in Distributed Systems
Shared data is distributed on several nodes. Therefore challenges in distributed sys-tems/databases is to keep all nodes consistent. In this section, we are investigating the principles that operations should conform to when they manipulate distributed data. The goal is not only to ensure data consistency among the nodes, but also to satisfy the user experience: delays, consistency, intent, etc. These properties have been formally dis-cussed by different principles for distributed data, such as CAP Theorem, ACID, and BASE principles.
2.1.1 CAP Theorem
The Brewer’s theorem (a.k.a., CAP theorem) [7] states that it is impossible for a distributed data store to simultaneously provide more than two of the following three guarantees.
Consistency Every read receives the most recent write or an error Availability Every request receives a (non-error) response without
guar-antee that it contains the most recent write
Partition Tolerance The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network
CAP theorem does not state that one has to choose two of these three but one has to choose between Consistency and Availability in case of network failure [8, 9]. However, in normal conditions (Network with no failure and acceptable latency), all three
guaran-tees may be provided successfully. CAP has been criticized [34, 54] for this ambiguity it may introduce.
2.1.2 ACID properties
Database systems have data entries that may be created, queried, updated, and deleted. These are the four basic operations applicable on a database, and are designated by the CRUD acronym [33] (i.e., Create, Read, Update, Delete). ACID stands for Atomic-ity, Consistency, Isolation, and Durability. ACID properties are widely used in relational database. Any sequence of operations that satisfy ACID properties is called a transaction and represents a logical operation.
Atomicity means that a sequence of operations that constitute a transaction are all applied successfully, or none of them. This guarantee to see the transaction as a unique atomic operation and does not partially update the database in case of failure.
Consistency means that the transaction brings a valid state to a valid state, according to the integrity constraints imposed by the database. A transaction leading to an incon-sistent state fails and is not applied. As an example, a transactionTmay try to update an SQL entry that has value range constraint. If this transaction would break this constraint upon application, then the whole transaction fails so that it remains valid.
Isolation means that transaction does not interfere with other transactions executed concurrently. Moreover, concurrent transactions leave the database in a state that is the same as if they were applied sequentially.
Durability means that, upon completion, a transaction is guaranteed to be recorded in durable storage and is visible to other transactions. As an example, transaction should not be committed if only saved in a temporary buffer (power failure would lose this transaction and lead to inconsistency).
2.1.3 BASE properties
Traditionally, ACID has been used for relational databases. However, new unstruc-tured database model, such as NoSQL database, goes in favor of BASE [10]. Such
6 databases rely on a distributed data to provide high availability and flexibility. For this purpose, the ACID model becomes an overkill. The principles of BASE are Basic Avail-ability, Soft State, and Eventual Consistency (EC). The former guarantees that data re-mains available even in the presence of multiple failures. This is achieved by using a distributed approach of the data that is replicated on several nodes. Soft State stipulates that the database does not have to be in a consistent state all the time and, because of EC, may change even once it stops receiving operations. Eventual Consistency is the last but not least BASE property. Basic Availability through a distributed model allows data to diverge at some replicas. EC guarantees that, at some point in the future, data from all replicas will converge to a consistent state. EC is explained in further details in Section 2.1.5.
2.1.4 Strong Consistency
Strong Consistency (SC) goes along with ACID properties, concurrency is resolved by processing operations sequentially so that ACID properties are guaranteed. Opera-tions are applied in a sequential order by a central consensus and sent to every replica upon completion [36]. This ensures that only a consistent state is observed by all users at all times but introduces needs for locking [30, 31, 45]. One central consensus server is responsible of queuing operations in a specific order to process them sequentially in that very order. Upon completion, newly applied operations are broadcasted to all users so that they all see the latest value. As soon as a user sends its operation request, he waits for an answer from consensus before applying it locally. Because of possible slow network or high consensus server load, this action often leads to poor performance. As an example, the user may experience slow User Interface (UI) reactivity because of a high amount of concurrent users. Invalid operation are refused by consensus and an er-ror message is returned. This, however makes roll-back features easy to implement since an operation is locally applied only upon global validation.
2.1.5 Eventual Consistency
Eventual Consistency (EC) [66] allows replicas to temporarily diverge locally but eventually converge in the same state. Operations are not orchestrated by a central con-sensus, instead, they are applied in parallel by different replicas. Upon application, a local operation is broadcasted to all users through a propagation mechanism. The prop-agation must ensure eventual delivery [47]. This is independent of the network commu-nication protocol (e.g., UDP). In other words, an operation executed at a local replica is eventually executed at all replicas. EC is a consistency model with convergence: replicas that have executed the same operations eventually reach an equivalent state. EC offers low latency at the risk of returning stale data (i.e., deprecated data) since, unlike SC, local data is not guaranteed to be up-to-date. However, replicas are guaranteed to con-verge when the system has been quiesced for a period of time so that all operations have been applied on each replica. Consensus bottleneck from SC is removed and relocated in each replica. In case of conflict, a global decision must exist so that all replicas apply the same resolution. In case of EC, this is called reconciliation [1].
2.1.6 Strong Eventual Consistency
Strong Eventual Consistency (SEC) is a special case of EC. Reconciliation, resolv-ing conflicts at a local replica, is hard to design and may require manual intervention (e.g., manual merge in version control system). SEC removes this limitation by introduc-ing rules in order to have a unique outcome for concurrent updates with a deterministic outcome for any conflict [39]. There is no longer a need for consensus or synchroniza-tion, since any kind of update is allowed and conflicts are removed altogether. This is specially appropriate for real-time collaboration. Every update is immediately applied and persisted. Replicas that have executed the same updates have equivalent state. Un-fortunately, SEC may be very hard or impossible to implements for certain data type [28].
8 2.1.7 Optimistic Replication
Whenever a modification is applied locally, waiting for the server acknowledgement may be long (As seen in Section 2.1.4). Optimistic Replication [52] goes in favor of EC by having a data duplicate on each user’s machine. Updates are first applied locally and then broadcasted using a propagation system with eventual delivery (such system has already been described in Section 2.1.5). Eventually, all replicas converge. There are two type of changes propagation: state transfer where the whole state is sent, and operation transfer which only sends the atomic edit. Operation transfer is usually preferred over state transfer for it requires less data to be passed over the network.
2.2 Real-time
In this section, we introduce the concept of real-time in software engineering, then we discuss in further details the case of real-time collaboration.
2.2.1 Real-time software
Real-time software are subject to a well defined time constraint such as a maximum response delay called deadline. Any processing must finish before it reaches this defined deadline or it will fail. This requirement may vary among software as well as failure consequences. For instance, real-time guidance systems for aircrafts have deadline in the order of few milliseconds and failures are critical, whereas real-time video games may have a similar deadline with less critical consequence in case of failure (e.g., screen freezing for a short time).
2.2.2 Real-time collaboration
Real-time software have a wide range of uses in real-world applications, such as embedded systems and communication software. Real-time collaboration is a specific kind of retime application that focuses on shared data across multiple users and al-lows them to work on the same data simultaneously. It is often used through a graphical
real-time collaboration editor. When real-time collaboration operates over a network, deadlines may not be satisfied in case of network failure. To avoid failure, collaborative software use replication and consistency features such as EC and SEC described in Sec-tion 2.1. The case of real-time collaboraSec-tion may require a deadline in the order of few milliseconds.
Not all collaborative software are real-time. Although multi-user is supported for a single data, they may exchange (or merge) their changes at specific time. This is for instance the case of version control systems which uses Optimistic Replication (Sec-tion 2.1.7) in order to allow several users to work on the same data. Manual merging is used to reunite divergent copies and form a new version.
2.2.3 Requirements for collaboration
Updates have to respect several properties in order to be used in collaborative envi-ronment without creating unexpected behaviors to its user.
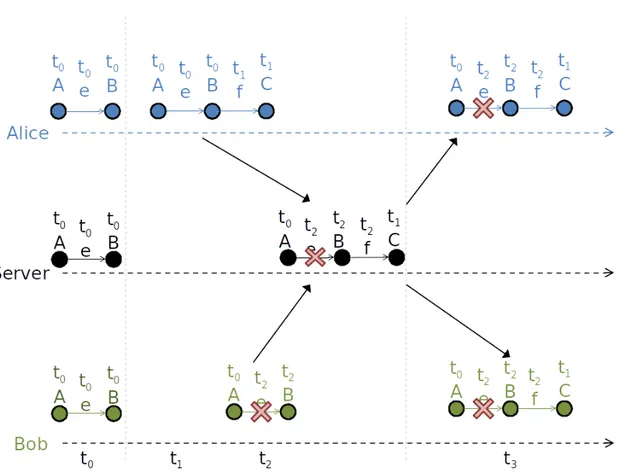
• Convergence: data end up in the same state after all users updates are applied. This is related to the notion of consistency defined in the previous sections (SC in Section 2.1.4, EC in Section 2.1.5, and SEC in Section 2.1.6. Figure 2.1 describes an example of collaboration on graph data. Alice and Bob both apply operations on their local replica and then notify the central server. This server broadcasts changes from Alice to Bob and vice versa. Upon completion, Alice and Bob see the exact same data.
• User intention preservation: original user intention must be preserved. As an ex-ample, Figure 2.1 pictures two users that apply concurrent editing. Alice adds a new vertex C with edge f that links B and C. Concurrently, Bob removes the edge e. Their intentions must be preserved regardless which algorithm is effectively used for concurrency control. Bob’s deletion should not break Alice intention, which is to link B and C with edge f .
• Causality Preservation: whenever two updates are causally related (e.g., create before delete), the user should see them in this valid order. As an example, Alice
10
Figure 2.1: Example of collaboration on graph
from Figure 2.1 adds vertex C and edge f . These operations are causally related, meaning that add edge f can’t exists without the previous operation add vertex C. This order must be respected by all replicas so that Bob and the server receives add vertex C before add edge f .
2.3 Concurrency Control Algorithms
Concurrent updates may conflict: although an operation alone is valid, it may change the context and, hence, be in conflict with concurrent operations. This case requires a concurrency control to resolve this situation. Pessimistic Locking solutions use different levels of locking to ensure SC and avoid conflicts preemptively. Locking a resource makes it unavailable to the others for modification. The user owning the lock must release it so others can modify it. This goes at the cost of productivity since only one
user may own a lock at the same time, which introduce a bottleneck. All other users are required to wait until the resource operated on is available. On the other hand, Optimistic concurrency control uses more advanced concurrency control mechanisms to allow users to work on a whole data at the exact same time. This goes at the cost of algorithm complexity. Because of this growing complexity, these algorithms are more error-prone.
2.3.1 Pessimistic Locking 2.3.1.1 Coarse-grained locking
The whole data is locked until user releases it. This technique is not the most ap-propriate choice for real-time collaboration since only one user may work at the same time on the data (which goes against the very notion of collaboration). This is still rel-evant solution for collaboration that does not require real-time, such as environments with very few users or users working on a data at intervals (e.g., checklist shared by an office where updates are occasional). As an example, this solution is used as the base of concurrency control by WebGME [41] tool which uses global locking on the current data. In order to allow several users to work on the same data, they introduce a complex branching system that checkout a new branch whenever a user tries to work on a locked data. This diverging branch may be manually merged with the original data as soon as the lock is released.
2.3.1.2 Fine-grained locking
To avoid the whole data locked problem, this solution uses more locks to protect smaller portions of data. This may be implemented as a fragment lock where the root data is subdivided into several smaller fragments, each one with a distinct lock. Although only one user may work on one segment at the time, a resource fragmented inNpartitions can accept up toNusers with write operations simultaneously, assuming they each work on a distinct fragment. Obeo Designer is an industrial example of Fine-grained locking implementation that divides models serialized as XML documents into several locked fragments [45].
12 2.3.2 Optimistic concurrency control
2.3.2.1 Compare and Swap
Compare and Swap (CAS) is a multi-threading algorithm used to achieve synchro-nization without locking any resources. It is an atomic operation that, upon completion, checks whether the resource’s original value has not changed during execution. A mis-match means that the resource has been used by another processes and Compare and Swap should fail instead of updating the resource. In order to work, CAS uses three parameters: the old resource value, the new resource value and the resource’s memory location. Although this algorithm was originally designed for multi-threaded computing, it may be used for collaboration. As an example, the software Flip from Irisate uses a variation of CAS in order to achieve real-time collaboration without locking [28].
2.3.2.2 Three-way merge
This is the core algorithm used by version control systems such as Git and SVN. It uses Optimistic Replication so that each user has his own copy of the data and applies updates locally, giving the possibility to work offline. Diverging data are merged in order to create a new version with all users changes. Three-way merge [43] name comes from the algorithm’s pattern: two diverging copies are compared against their common base data. Unfortunately, this is not appropriated for real-time collaboration since merge may requires manual intervention when conflicts cannot be resolved automatically. Moreover, during the merging process, data is locked and not accessible to any user The local user merge his data with current server’s data , therefore the shared data on the server must be locked.
2.3.2.3 Differential Synchronization
Originally developed by Neil Fraser (Google) in 2009 [21, 22], Differential Synchro-nization (DS) uses Optimistic Replication in order to achieve real-time collaboration. DS relies on the Diff / Patch / Match algorithm. Cached modifications are compared with a copy of the previous known version called a shadow copy (diff algorithm [19]) in order
to generate an edit which is sent to a remote replica. The former update its local copy using this received edit (Patch algorithm [20]). DS has a client / server architecture, where the server keeps a shadow copy for each client. Whenever the server receives an edit, it patches its local copy and broadcast the change to the other users. This is a sym-metrical algorithm, nearly identical code is running on server and clients. DS is suitable for any content for which semantic diff and patch algorithm exists. Although DS only sends minimal edits, DS is a state-based algorithm and doesn’t require that applications maintain a history of edits. This makes DS appropriate for applications with synchro-nization features. In case of network failure or unreliable network, DS implements a version checker system to detect dropped edits in order to re-send them. Hence, DS is highly fault-tolerant.
2.3.2.4 Operational Transformation
Operational Transformation was first introduced in 1989, primarily for text [17, 18]. It uses optimistic concurrency control to deal with real-time collaboration and is based on operation transformations [61]. Every edit is an operation (e.g., Add ’x’ at pos 3) which is broadcasted to all other users. Upon reception by a replica, an operation is compared to local operations and transformed before being applied [5], [26]. This mech-anism guarantees that, upon successful application of all operations, replicas converge to the same state. This is an operation-based strategy. GoogleDoc is a great example of a real-time collaborative software based on OT. Unfortunately, OT is considered as a com-plex and error-prone algorithm. Each possible transformation has to be defined, which may grow indefinitely as soon as the number of possible operations grows, therefore OT is often restricted to simple linear data, such as text. Google Wave is a relevant exam-ple of this issue. Because of its extended available data types, its OT imexam-plementation has grown nearly impossible to fully and successfully create for all possible transforma-tions and Google Wave has been cancelled [23]. Moreover, OT has scaling problems in peer-to-peer environments and is best suitable for client/server architectures.
14 2.3.2.5 Conflict-Free Replicated Data Type
CRDT algorithm was presented in 2011 [55] by INRIA researchers (French Institute for Research in Computer Science and Automation). CRDTs are data structures that are replicated concurrently at all replicas using Optimistic Replication with SEC. They can be state-based (CvRDT for Convergent Replicated Data Types) or operation-based (CmRDT for Commutative Replicated Data Types). The CRDT algorithm focuses on operations design in order to accomplish concurrency control instead of using transfor-mations (e.g., OT). An operation represents the smallest atomic edits that a user is able to apply on a data structure (e.g., add one value in a set). Concurrent users may apply operations simultaneously. The idea behind CRDT is that all operations have the follow-ing properties (with OpX for operation X. The notation Op1 + Op2 means that Op1 is applied, then Op2 is applied on the same data):
• Commutativity:
Op1 + Op2 = Op2 + Op1
Applying Op1 followed by Op2 produces the same result as the other way round. • Associativity:
Op1 + (Op2 + Op3) = (Op1 + Op2) + Op3
Applying Op1 followed by the result of Op2 and Op3 produces the same result as applying the result of Op1 and Op2, followed by Op3.
• Idempotent:
Op1 + Op2 = Op1 + Op1 + Op2
Applying the same operation multiple times produces the same result as applying the operation exactly once.
This gives the possibility for operations to be applied in any order (Commutativity, As-sociativity), and be applied more than once without altering the result (Idempotent). Thanks to such properties, CRDT removes the need for a central consensus bottleneck. Each replica follows the exact same rules to apply operations, therefore they are guar-anteed to eventually converge to the same state. It is highly fault tolerant and remains
available even in case of network failure. It was originally designed for peer-to-peer asynchronous collaboration. Each operation has to be designed for a specific data type, which may become hard to implement for more complex data types. Unfortunately, even simple data such as an ascending integer counter is already complex. Therefore, CRDT may not be the most appropriate algorithm for all problems and data. The original re-search study presents several common CRDTs such as counters, set, and graph [57].
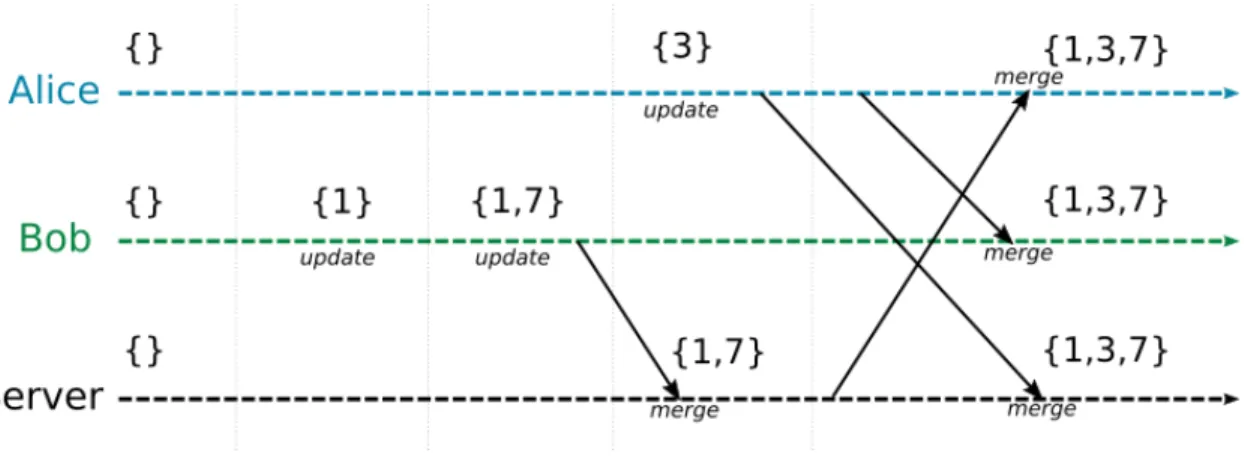
Figure 2.2: State-based CRDTs: example with a set of numbers
State-based object (CvRDT): updates are first applied locally, then the whole data state is sent to all other replicas and merged. An official example of implementation is available online [56]. Formally, CvRDT is defined as the tuple hS, s0, q, u, mi, where S is the global state, s0 is the state at the beginning, q is the query method, u is the update method, and m is the merge method [55]. si ∈ S is the local state at instant i. It may be read with query q(...) and modified with update u(...). At some point, the entire state is sent to other replicas. Received state is merged with local state using merge method m(...), which is commutative, associative and idempotent. Figure 2.2 illustrates the state-based CRDTs. The merge method follows the same rule at all replicas: number are added in the list in ascending order. The state represents the current set of integers at a replicas.
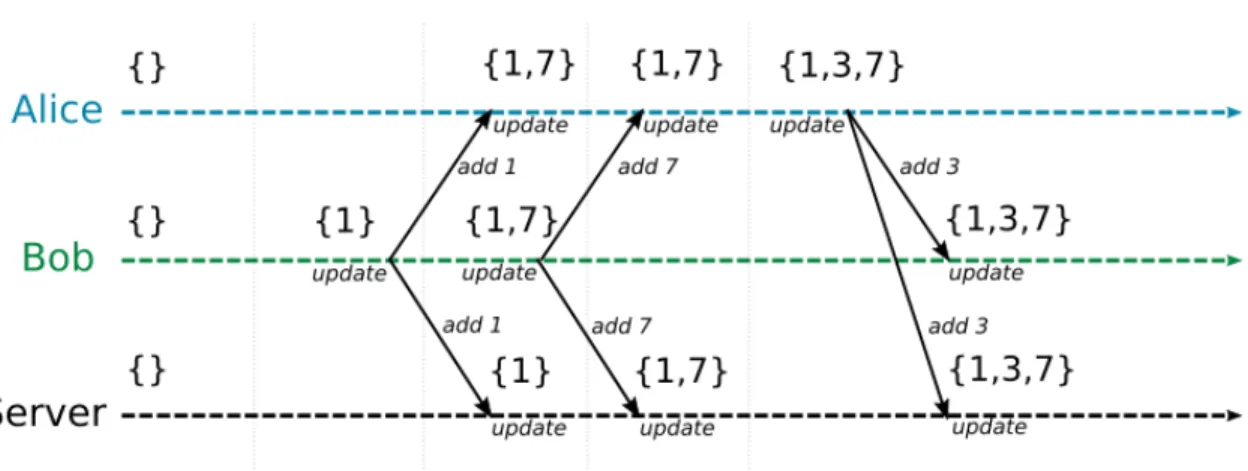
Operation-based object (CmRDT): unlike for CvRDT, only operations are broad-cast to and applied on other replicas instead of sending the whole state. An operation represents a possible data editing (e.g., add element). Operation-based object has the
16
Figure 2.3: Operation-based CRDTs: example with a set of numbers
advantage of using less network traffic. All concurrent operations are commutative and associative. Idempotent property is assured by the propagation mechanism with even-tual delivery as explained in Section 2.1.5. This mechanism ensures that operations are received exactly once at each replica. Formally, CmRDT is defined as the tuple hS, s0, q, t, u, P i. S,s0, and q are the same as for CvRDT. There are additional com-ponents in CmRDT. Method update t(...) is a side-effect-free update only applied on local replica and generates an operation to broadcast. Method update u(...) is then applied on all replicas (local replica as well) and actually does the operation. P is a reliable causally-ordered broadcast communication protocol. Such protocol guarantee that messages are received exactly once by replicas and causally-ordered (idempotent). Any operations that are not causally-ordered must commute. Figure 2.3 illustrates the Operation-based CRDTs. Upon update application at local replica, the operation is sent to all the other replicas. Each update method follows the same rule: number are added in the list in ascending order.
2.4 Existing tools
Google Doc is one of the widely used collaborative tool for text editing. It imple-ments OT algorithm in order to work with lock-free (Optimistic locking) concurrency control. It supports online collaboration with several collaborators in real-time.
data type using OT. A central server keeps the long-term storage data and several clients may collaborate on the same data in real-time. The API provides with a set of ready-to-use built-in data such as String, List, and Map.
Yjs [29] is an open source framework for offline-first peer-to-peer shared editing on structured data like text, richtext, or XML. It introduces a variation of the CRDT algorithm called YATA [44] in order to achieve SEC. YATA stands for Yet Another Transformation Approach. It uses a linked list as its internal representation and can be extended to achieve collaboration on new shareable data types. Operations are placed in this linked list according to a predefined set a rules which creates a total order of operations and removes possibility of conflicts. To support offline collaboration, each operation has a set of metadata used to determine its position in the list (total order) and doesn’t rely on time based value such as timestamps. Yjs is a web-based tool written in JavaScript and may be pluggable with several kinds of databases such as in-memory storage. YATA introduces an implementation of garbage collector to avoid ever-growing memory.
Irisate Ohmstudio is a real-time collaborative digital audio workstation. It has a client/server architecture which mixes both SC and Optimistic Replication. Updates (called transactions) are applied locally before being propagated to the server. A trans-action may be refused by the central server consensus and rolled back locally. This gives fast responsiveness with guarantee of consistency across all users. In order to remove the consensus bottleneck, ohmstudio uses its own concurrency control based on CAS algorithm. Collaborative features are internally bundled inside a framework called Flip which is reusable for extensive data types. Advanced real-time collaboration features are well-supported by flip, such as user undo/redo stack, history with owner, and collab-orators informations (e.g., cursor position, selection. . . ).
CHAPTER 3
FEATURE MODEL FOR COLLABORATIVE ENVIRONMENTS
In this chapter, we present a feature model for collaborative environment. This chap-ter was originally part of a paper presented during the CommitMDE 2017 workshop [42] and focused on collaborative environments for Model-Driven Engineering (MDE).
3.1 Features for collaborative environments
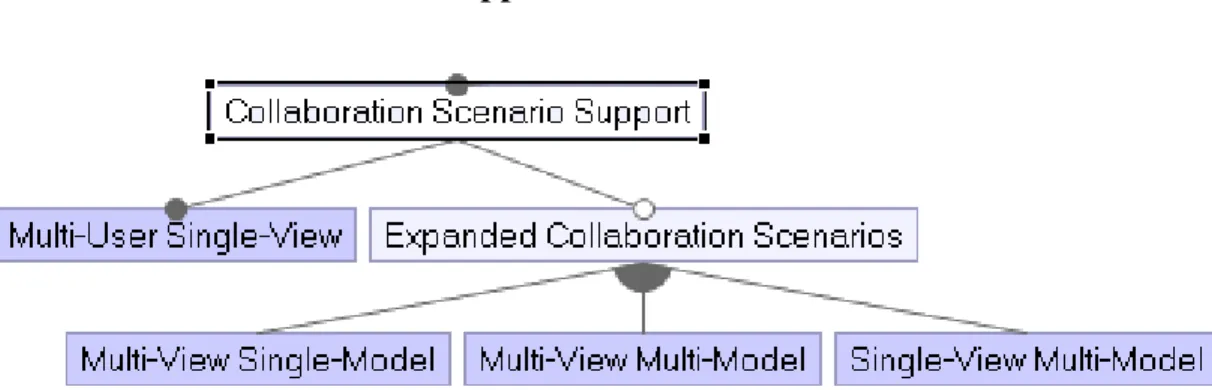
Modeling environments that directly support the collaboration of many stakeholders on the same model(s) working independently are collaborative modeling environments. These environments may be offline systems utilizing features similar to a version control system to manage the shared artifacts or may allow collaborators to interact remotely in realtime. We explored a variety of existing tools and potential solutions to identify a set of features for the implementation of collaborative modeling environments. In this section, we introduce and briefly discuss each feature. Figure 3.1 shows the top-level feature diagram and the constraints of the model. The complete feature model is available online in ReMoDD [12].
Execution Concurrency Network Architecture Conflict Management Multi-User
Realtime Execution => "Conflict Awareness" "Distinction Mechanism" v "Sandbox Mode"v v ¬ API => ClientType Legend: Mandatory Optional Or Alternative Abstract Concrete Collapsed
Collaborative Modeling System
Collaboration Scenario Support Data Storage Client Type
Undo-Redo => History
User-Specific v "All Visible" v Identified v "Ownership System" => "User Identification" Realtime => Multi-User "Push Notification"
Manual => "Conflict Awareness" Versioning => History Persistent Offline => "Batch Operations" "Multi-View Multi-Model" => "Multi-View Single-Model"
v
v
3.1.1 Methodology
The feature model presented in this paper is the outcome of an iterative process. To identify the feature of collaborative modeling systems, we investigated all kinds of collaborative environments. Our sources are: our own software (AToMPM [14]), MDE-specific environments (such as OBEO [45], MDEForge [4], GenMyModel [16] and, CDO), and other collaborative environments (such as GoogleDoc [26], Eclipse Che, Ohm Studio [28], Overleaf and, DropBox [27]).
We relied on published articles related to the collaboration aspect tools when avail-able. We also reviewed technical documentation as well as relevant blogs, tutorials, and videos that explain the technical implementation of the tools. Finally, we experienced each tool ourself when freely available. In some cases, we studied specific algorithms, in particular conflict management algorithms used by several collaborative environments, such as Operational Transformation, locking mechanisms, and the DropBox synchro-nization algorithm explained.
From the collected set of data, we identified which features are specific to MDE collaborative environments.
3.1.2 Collaboration Scenario Support
Figure 3.2: Collaboration scenario features
An abstract model is the abstract syntax of a model conforming to the metamodel of a given DSL. Conceptually, a view is a projection (in whole or part) of an abstract model utilizing the most appropriate representation of a subset of the model’s elements for the
20 needs of the modeler. An environment that does not support views could be categorized as supporting only a single complete view for each model. Therefore, we can detail the possible collaboration scenarios for both tools explicitly supporting views and those not supporting views in similar terms. In collaborative modeling, we previously identified four possible collaboration scenarios [14], that we briefly describe here. In the following, we commonly refer to scenarios with only two collaborators, but recognize the scenarios can scale to an arbitrary number of collaborators.
3.1.2.1 Multi-User Single-View
Users are working on the same view of the model. They both see the same informa-tion in the same language and with the same concrete syntax. The changes made by a user are reflected automatically to others.
3.1.2.2 Multi-View Single-Model
Users work on distinct views of the same model. The views may present the same, overlapping, or disparate sets of elements in the same or different concrete syntax. Mod-ifications on the abstract model of elements present in both views are perceived by the other user.
3.1.2.3 Multi-View Multi-Model
Each user is working on a different view and each view is a projection of a different model. These models have some dependency or satisfy a global constraint. Only changes on elements related between the abstract models are perceived by both users.
3.1.2.4 Single-View Multi-Model
This is similar to Section 3.1.2.3, but the dependency is defined at the view level, not at the model level, such as an aggregation of elements from both models. A user may work on a view that projects several models while another is working on one of the
Figure 3.3: Concurrency features
projected models. A change on an element used in the view is propagated to all views with the same element.
3.1.3 Concurrency
Concurrency is concerned with issues related to multiple operations occurring at the same time or in parallel.
3.1.3.1 Locking
When several users are working on the same model(s) concurrently, conflicting up-dates may occur. Simple strategies, such as retaining only the last modification, could result in losing work from one user and goes against the goals of a collaborative envi-ronment. One approach to this issue is to avoid conflicts entirely allowing users to work together transparently. However, the collaborative aspect requires that users are able to work concurrently on components even closely linked. A general overview of the file-sharing problem in the MDE environment is presented in the subversion book [2].
Pessimistic locking is a strategy widely used in concurrent systems. It is based on data locking, which only allows one user to modify the locked data. A naive but simple solution is to use a global Data Lock. All of the model is locked to a specific user and other users cannot access the model until the lock is released. However, this reduces collaboration, because only one user can work on the model at a time. Another solu-tion is to use a Fragment Lock that applies the lock on a fragment (i.e., subset) of the model. In this solution, each user is able to modify a distinct fragment concurrently. The
22 fragments should be as small as possible, minimizing the locked portions of the model. However, the fragment lock approach requires a well structured data format supporting well defined fragments. In the case of XML for example, we might lock the current XML tag and its children. Additionally, fragment locks do not consider dependencies that may indirectly affect the elements locked (e.g., metamodel relationships). OBEO Designer implements data and fragment locking. Another approach relies on Depen-dency Locking. This provides finer granularity that locks the element being modified and its dependencies. Though this technique is seen as only an improvement here, tak-ing dependencies into account may be seen as required by the semantic nature of models. This is discussed in more detail in Section 3.3.
Though we try to minimize the set of elements to be locked, pessimistic locking always blocks access to a set of data. This might lead to a situation where a user waits for a resource to be free. OBEO shows an overview of these locking techniques in their documentation [45]. Optimistic Lock tries to resolve this issue without locking. Instead, it allows the users to modify, possibly the same, elements concurrently and then merges all changes to create one unified new version of the model. For example, this is how Google Docs allows for concurrent changes and relies on the Operational Transformation (OT) algorithm [60] for merging. Unfortunately, though OT works well for text based data, model merging requires merging graphs, which makes this approach hard to apply [63].
3.1.3.2 Collaboration Type
We differentiate two scenarios of collaboration: Realtime and Offline. In the former, the model is modified by several users at the same time; changes are applied on the data immediately; and users are updated of changes made by others immediately. The model is the unique source of truth that all users alter concurrently. Here even the changes from a given user may not be considered complete until acknowledged by a central authority or a set of peers. On the other hand, offline collaboration presents an asynchronous approach. Users may apply modifications on the model without sending the changes right away. This principle is often seen in version control systems (VCS) that allow
working locally and pushing changes at a later time. This prevents immediate conflicts between users, but local versions may diverge and result in complex merging processes later, as in Git.
3.1.3.3 Batch Operations
All modeling systems support a set of atomic operations (e.g., creating or deleting an element) that provide the ability to develop and manage models. We recognize that some systems also allow collecting together these atomic operations in batches. The processing scheme for these batches becomes significant when discussing collaborative systems and handling potential conflicts. Resolve as Atomic resolves a set of operations in an all-or-nothing approach. Every operation in the batch must succeed or none of the operations can be applied. Thus, a single failing operation may result in the need to roll-back changes from a set. Resolve Divided allows processing each operations separately. However, this may result in partial sets being applied thereby generating unexpected or even invalid results.
3.1.3.4 History
In a collaborative environment, storing the complex history of operations applied to a given element can be beneficial. The series of events leading to a conflict or failure may be complex, and not easily understood without a record of the operations. Here we intentionally separate history from versioning. For instance, a basic feature of any VCS is to manage the project history. Therefore, the presence of versioning mandates the presence of some form of history (this is represented as a constraint in the feature diagram). However, a collaborative environment might store some portion or form of history without the presence of a VCS. GenMyModel [16], for example, has a full and complex history feature, that allows replaying the history from a defined start time. His-tory is Persistent if it persists when the environment halts. An example of non-persistent history is an undo / redo stack that only lasts until a given session terminates. Using a VCS implies that the history is persistent. However, it may not be enough to use the VCS
24 history directly, but a user interface (UI) wrapper might be required. VCS integrates the set of changes from the whole project. While working on a specific model, the user does not need all of this information. Therefore, an environment might implement a history wrapper that shows only the current data models history. Identified history adds the user identity information to each modification. This is often the default behavior of a VCS. Allowing attributing a change to a specific user helps in diagnosing a series of events from multiple users that may have led to a conflict or failure.
3.1.3.5 Versioning
VCS are tools that trace all changes for a system and have facilities for managing this history. A single user working on a data model has a complete view of its state at all points and understands the full history of the model naturally. However, several users working on the same data model may lead to misunderstandings and inconsistencies. When trying to merge artefact(s), the data model(s) might be significantly altered since the last connection. Changes performed by other users may be difficult to understand. This introduces the need for versioning systems with history management. It adds the possibility to look back at the changes performed over the intervening time and to un-derstand the full series of changes. Moreover, VCS also support other features such as documentation, reverting previous changes, or listing the added features for a release. A survey on model versioning was provided by Altmanninger et al. [3].
3.1.3.6 Version Control System
VCS play an important role in software development. Tools like Git and SVN are largely used and are very efficient. Therefore, collaborative modeling environments may opt to integrate an External VCS into the environment rather than reinventing the wheel. This places the data under the VCS management and each change is added to the history. However, these VCS use compare and merge mechanisms to integrate the changes into a new version, which require manual intervention. For instance, to integrate new changes made under Git, changes must be commited and pushed manually. Moreover, these
sys-tems are subject to conflicts, which require manual resolution. Employing locking with a version control system may avoid conflicts. Merging is then performed automatically in the background. This approach is utilized by MetaEdit+ that integrates Git with their MDE collaboration [31]. They use fine granularity locking to avoid conflict, that allows processing the merge without risk of conflicts. Furthermore, these VCS are specialized for versioning, comparing and merging text files as opposed to complex semantical data structures in MDE. For these reasons, some modeling systems may opt to build Custom VCS. We discuss these issues in more details in Section 3.3.
3.1.3.7 SandboxMode
Sandbox is used to divorce a user from the typical collaborative environment. This supports experimental or debugging processes. Working in a sandbox environment al-lows developing components that temporary break other components or violate general rules/expectations, without disturbing other users. The modifications may then be inte-grated when complete, potentially resulting in complex merges.
3.1.3.8 Branching Type
Multi Branchingis used to divide the project into several branches. In VCS, branches are a divergent copy of the project where users may work independently from other branches. Branches are often used for new incoming feature that are not stable yet. As soon as the feature is stable and needs to be integrated, a merge with the main branch is done. This eases the team work and separates the maintenance from the new release components. However, a manual merge is required and the new feature(s) may be diffi-cult to integrate with the main branch. New features are built on top of the old base code that may be deprecated. This issue appears when maintenance largely diverges from the main branch. Moreover, dependency ambiguities are complex to resolve, which is emphasized by the semantic nature of models.
Single Branch avoids these issues. No branches are used and every change is per-formed on a single version of the system. In order to separate new features, e.g., to
26 exclude them from the release, Revision Flags may be used. In this way, new features depend on the up to date state of the code, while still hidden from release. One great ex-ample is Google with the Piper VCS which uses only one trunk for all its teams and flags for new features [49]. It is important to note that the use of branches is not always rela-tive to the actual VCS branching support. Though the used VCS may support branching, users (or even environments employing an external VCS) can make the decision not to use branching. This is the case with MetaEdit+ that uses Git as a VCS but does not use Git branching feature.
3.1.4 Data Storage
Figure 3.4: Data Storage Features
Data storage is concerned with how models are stored and managed in the system to enable reuse among collaborators.
3.1.4.1 Workspace Location
In a collaborative environment, data is often saved in a remote place (i.e., the “cloud”). The workspace location is where the data is stored while users are modifying it. Data may be Local, meaning that the relevant models are on the users local machine. This may support an asynchronous workflow as with an offline collaboration type or be a re-sponse to other constraints on the system. Collaboration is often reduced to active screen sharing (single-view single-model) as supported by AToMPM. Since network latency is sometimes high, having a local copy may remove the delay between an operation being
requested and being applied on the data. In contrast, Remote locations do not require loading the project locally. This is useful in the case of a project using a high quantity of memory. Lazy loading may even be used to load specific data only when required.
3.1.4.2 Data Format
Models use a specific data storage format. The choice of format is important and may influence or be influenced by other factors (e.g., the VCS). Some formats may be hard to use with a text-based VCS, hard to fragment for locking, or mandated to be com-patible with a distributed database utilized by the system. Popular formats are JSON (for web-based modeling environments), XMI (for Eclipse-based tools), or NoSQL database formats when scale is an issue.
3.1.4.3 Data Management
Data management refers to managing the basic operations and long-term storage in the system (e.g., CRUD operations). Internal Management implies data is processed by tools internal to the software, whereas External Management reuses existing tools like a distributed database. Namespaces (e.g., URI) are crucial to access a model.
3.1.4.4 Format Optimization
Format Optimizationidentifies the way a system might optimize the model represen-tation/storage for certain actions; e.g., Model Browsing or model Search. Basciani et al. [4] overview different supported query mechanisms for several systems according to the managed artifacts.
3.1.5 Network Architecture
Collaboration requires the use of the network so that instances of the modeling sys-tem on different machines communicate and exchange data.
28
Figure 3.5: Network Architecture Features 3.1.5.1 Communication Protocol
Clients and servers must be able to communicate using a common protocol. TCP/IP is a widely used network protocol. It may be relevant to investigate reliable networks to guarantee no data loss, but at the cost of time performance. Client and server must then use the same data format to communicate information.
3.1.5.2 Architecture Type
This is the network architecture chosen for the collaborative environment. We dis-tinguish two fundamental types of architectures: Centralized and Decentralized. Cen-tralizeduses a central authority. It has the advantage of having one source of truth: the centralized storage is the true version of the work. Alternatively, Decentralized systems distribute authority. An example of Decentralized architecture is Git, though often used in a Centralized way (e.g., Using Github server as the main storage location).
Centralized architecture may be Single-Server or Distributed-Server. This is an in-ternal detail, since end-users see the cluster as only one single-authority. Distributed-Serveradds complexity to handle data synchronization across all storage locations. Nev-ertheless, it adds a layer of security (a single server crash will not affect the whole sys-tem) and performance (distributing processes and storage across a large set of nodes).
This is useful for servers with high traffic demand. An industrial example of this is the Google Piper VCS [49], which is duplicated into 10 servers across the world using the Paxos algorithm [37]. This divides the number of request performed on each unique server and speeds up response time.
3.1.5.3 API
An API, though optional, may be integrated to allow extension of the system and other client implementations. For example, we are working toward an API for collab-orative modeling services to allow building and integrating potentially many distinct clients [13]. Each client may support their own needs and rely upon the common mod-eling services provided by the API to simplify system design and interoperability. APIs are the basis for modeling as a service systems, such as MDEForge. Additionally, an API may be provided purely for internal use to manage operations between layers or nodes in the architecture. For example, there is a simplified API between the MVC and MvK within the architecture described in our prior work [13].
3.1.5.4 Failure Recovery
Hardware and network systems are subject to failure and error, but user experience should not be affected by a technical issue within the system. The possibility of recov-ery is closely relative to the chosen Network Architecture. Decentralized architectures mitigate this issue as each user owns a state of the project. Though the error might be dis-connected from many users, consistency schemes must exist to manage the decentralized authority.
Centralized architectures are notably subject to failure in the case of Single-Server where there is a single point of failure sufficient to take the entire system down, and recovery can be difficult to impossible depending on the severity of the failure. On the other hand, Distributed-Server may implement a failure recovery system. If one server crashes, the system may use another server instead to maintain availability and redundancy may be used to prevent the loss of data.
30 3.1.6 Conflict Management
Figure 3.6: Conflict Management Features
Divergent modifications on the same data model may lead to a conflict when trying to resolve all modifications to a single consistent model state. It is important to detect conflicts and act upon resolving them.
3.1.6.1 Conflict Resolution
Conflict resolution is the process by which all modifications are combined in order to create a new version of the model. Automatic conflict resolution is the ideal solution, where conflicts are resolved automatically. Other features, such as collaboration type and locking, strongly impact the complexity of managing automatic resolution of conflicts. A live collaboration environment with fine grained locking may be conflict free. High risks of conflict appear when using offline collaboration and versioning. Each user works separately on a divergent version of the work. To share his change with others, the user needs to perform a merge action. This could be accomplished through a diff / merge algorithm. In case of unambiguous changes, this action may be transparent to the user. For example, if each user changed different parts of the model(s) without cross dependencies. However, often Manual conflict resolution may be needed. This is the case of WebGME tools that refuse a push request if the server has already been modified [40]. The user must then first pull the latest changes and manually merge them with his own changes before pushing them to the server.
3.1.6.2 Conflict Awareness
When working in collaboration, users should be aware of other users changes. Con-flict Awarenessis the mechanism that warn users of conflicts. Notification may be sent in response to conflict (e.g., 2 users move the same element) or to warn users about po-tential conflict (e.g., elements being edited by other users). It is disruptive for a user to perform a modification that results in unexpected behavior, because the user was not notified of a conflict.
Warningconflict awareness are only mechanisms to inform user about conflicts and concurrent actions. This feature provides only information about conflicts or potential conflicts. This is often used by the GUI, which uses combinations of colors and anima-tion to display the informaanima-tion. OBEO applies this soluanima-tion by drawing a lock icon at the bottom of any locked element. However, this is not only restricted to GUI, this can also be applied in an API. For instance, it can be a special return value of a function in case of conflict, or an object state that changes according to it’s conflict state. The case of a GUI is discussed in more details in Section 3.3.
Prompt Action conflict awareness on the other hand, informs about conflict and re-quests the user take some action, such as in MedaEdit+. The user is prompted to update the model with the server to remove existing locks.
3.1.7 Multi-User
This feature is concerned with the fact that multiple users are interacting with the same or related models.
3.1.7.1 Authentication Method
Collaboration implies that several users are able to access the data models. An au-thentication mechanism can be incorporated to give access only to registered users or to simply track who is responsible for a given operation. User Identification requires such an authentication method. The method may involve utilizing an external authentication method. For example, GenMyModel allows users to connect through their Github
ac-32
Figure 3.7: Multi-User features
count. Alternatively or in addition, Anonymous Access may be provided to allow users to connect without having to register. This can be used for example to allow read-only access. One example outside MDE is the IRC channels that do not require registration.
3.1.7.2 Access Control
Users working in collaboration must be able to access the data model. However, each user may be provided a distinct set of permissions. This is handled by the Access Controlfeature. There are two distinct alternatives: Operation-Based and Data-Based. They may be mixed together in order to have more fine-grained control. Operation-Based restricts what a given user is able to do on any model, based on the possible set of operations (e.g., CRUD operations). A user is granted a specific operation permission that applies on any model from the project. This is similar to a database administrator that has full access to all elements. On the other hand, other users may have a restricted set of allowed operations. Data-Based access control may be provided to control the elements (at model or element level) and operations for those elements available to the user.
Access Controlcan be augmented with an Ownership System that adds the possibility to restrict exceptional permission to only a set of users, as in GenMyModel. A project can be shared with a team and permissions are given to certain users. They also add project visibility. A public project is visible to everyone, though read only, any user can clone the project in its own session, thereby creating a totally new project copied from this public repository.