Geo-Distribute Cloud Applications at the Edge
Texte intégral
Figure

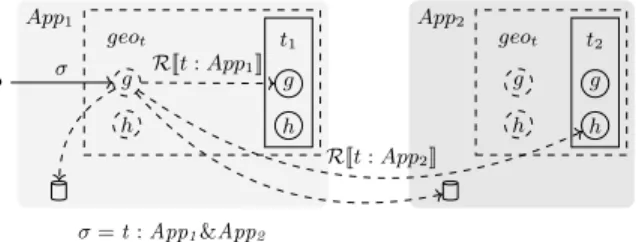
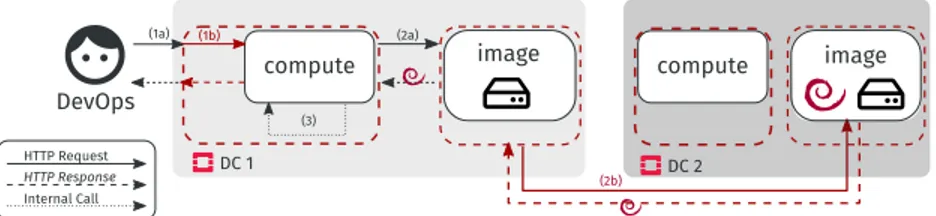
Documents relatifs
L’objectif de cette thèse est de concevoir des modèles et de développer des approches d’optimisation pour résoudre le problème de planification intégrée des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
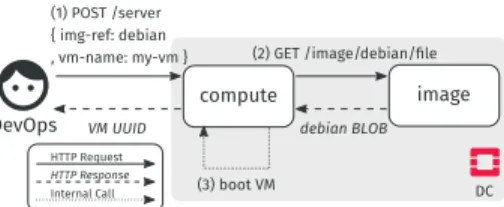
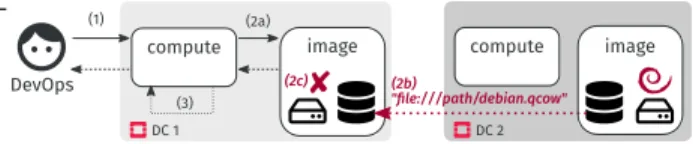
example of Figure 4, the web service on the Edge 1 site calls the chat service.
This paper sketches a new approach for rule-based reasoning, enabling distributed rule evaluation on edge nodes and reducing the latency for IoT applications while avoiding the
Gen- erally speaking, edge computing (either statically or dynamically) migrates core capa- bilities such as networking, computing, storage, and applications closer to devices and
Several derived models were recently proposed, such are HaaS (Hardware as a Service), but their developments are considered out of scope for this report. In all cases, Figure
In general, we observe from our experiments that the hybrid core/edge deployment results in a compromise between the gain of performance of operations that involve services that can
If the dramatic, embodied reading of “This living hand” suggests Frankenstein’s dream of an animated creative text, the reading that considers the poem’s construction of
