Perspectives on Tracing End-Hosts: A Survey Summary
Texte intégral
Figure
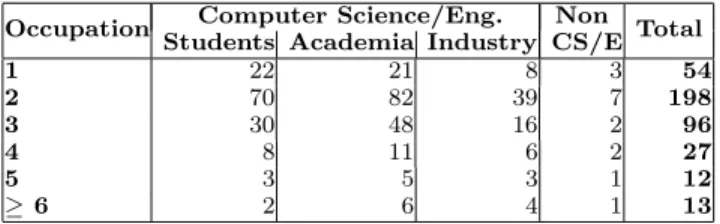

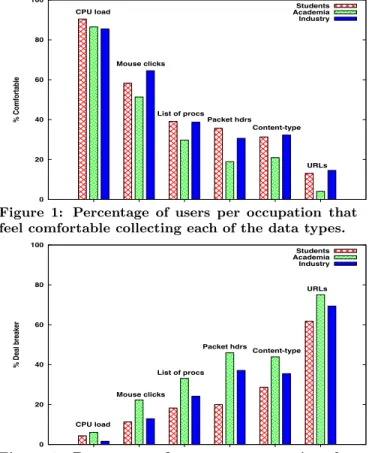
Documents relatifs
Comme le suggère Laurent Siproudhis d ’ emblée dans le titre de son dernier éditorial pour la revue Colon & Rectum (vous noterez en passant la grande souplesse d ’ esprit de
We define a partition of the set of integers k in the range [1, m−1] prime to m into two or three subsets, where one subset consists of those integers k which are < m/2,
❖ Death valley, chasm: need to reach « early majority » customers - Need for financial ressources to allow performance to generate enough revenues - Segment the market, find
In case we use some basic hashing algorithm processing the tricluster’s extent, intent and modus and have a minimal density threshold equal to 0, the total time complexity of the
We use sequence-to-sequence neural models for learning jointly acoustic and linguistic features, without using any externally pre-trained language model to rescore local
The users are given access to the generated personas through system UIs where they can interact with the personas, including selecting each persona and viewing their information
Now the Daily Star suggests people think this time is different because the supposed impending arrival of Nibiru has been presaged by some of the ten
εἰ δὴ τὸ ὂν καὶ τὸ ἓν ταὐτὸν καὶ μία φύσις τῷ ἀκολουθεῖν ἀλλή- λοις ὥσπερ ἀρχὴ καὶ αἴτιον, ἀλλ’ οὐχ ὡς ἑνὶ λόγῳ δηλού- μενα (δι- αφέρει δὲ οὐθὲν οὐδ’ ἂν ὁμοίως
