POUVOIR PRÉDICTIF DES QUESTIONS DE SONDAGE
Mémoire
Amos ALLODEHOU
Maîtrise en économique Maître ès arts (M.A.)
Québec, Canada
Résumé
Les sondages pré-électoraux jouent un rôle important dans les élections en aidant les candidats à sélectionner leur plateforme et les électeurs à coordonner leurs votes. Ils influencent le bien-être de la société à travers les mesures de politiques qui seront mises en œuvre après les élections. Mais, les prédictions obtenues à partir des réponses aux sondages sont souvent biaisées et volatiles. Les biais proviennent soit du format de question utilisé dans le sondage soit du processus cognitif par lequel les individus élaborent la réponse. La négligence de corrélation est l’un des biais cognitifs susceptibles d’affecter les réponses au sondage. Le présent mémoire vise à comparer théoriquement et empiriquement les pouvoirs prédictifs des différents formats de questions posées dans les sondages puis à mesurer l’effet du biais de négligence de corrélation sur les réponses des individus à l’aide d’une expérience de laboratoire. Les sondeurs utilisent trois types de question pour prédire le résultat de l’élection : les questions binaires, binaires avec incertitude et probabilistes. Les résultats théoriques montrent que les questions binaires avec incertitude donnent une estimation plus précise du résultat de l’élection que les questions binaires. Cette précision dépend de la proportion des électeurs indécis dans la population et de la façon dont les répondants interprètent la question. Les questions probabilistes sont plus précises que les deux autres formats de question. Selon les résultats expérimentaux, la corrélation entre les préférences électorales et les coûts de participation aux élections affecte significativement les réponses données par les individus dans les sondages.
Table des matières
Résumé iii
Table des matières v
Liste des tableaux vii
Remerciements xiii
Introduction 1
1 Sondages 5
1.1 Formats de question utilisés dans les sondages . . . 5
1.2 Pouvoir prédictif des sondages . . . 8
1.3 Biais de négligence de corrélation : définition et conséquences. . . 10
2 Modèle 15 2.1 Cadre d’analyse . . . 15
2.2 Questions binaires. . . 16
2.3 Questions binaires avec incertitude . . . 21
2.4 Questions probabilistes . . . 25
2.5 Décision de participation aux élections . . . 25
2.6 Effet du biais de négligence de corrélation sur la réponse au sondage . . 26
3 Expérience 29 3.1 Présentation du dispositif expérimental . . . 29
3.2 Plan expérimental. . . 31
3.3 Traitements de l’expérience . . . 35
3.4 Option externe, prédictions et préférences . . . 38
3.5 Résultats de l’expérience . . . 40
Conclusion 47
Bibliographie 49
Liste des tableaux
1.1 Différents types de question posés dans les sondages pré-électoraux . . . 7
3.1 Ensemble d’informations présentés au sujet . . . 31
3.2 Paramètres des quatre traitements . . . 37
3.3 Prédictions et vote effectif des sujets humains et des agents élèctroniques . . . 43
3.4 Prédictions et vote effectif des sujets humains et de l’agent électronique rationnel par groupes idéologiques . . . 43
3.5 Écarts entre la prédiction individuelle et le vote effectif des modérés . . . 44
3.6 Estimation du biais de négligence de corrélation pour les sujets humains . . . 44
A.1 Liste de questions posées dans les sondages pré-électoraux . . . 53
“I think most of you feel that if we could use explicitly such variables as, e.g., what people think prices or incomes are going to be or variables
expressing what people think the effects of their actions are going to be, we would be able to establish relations that could be more accurate and have more explanatory value”
Haavelmo(1958), Prix Nobel en Économie
Remerciements
Je tiens à exprimer ma profonde gratitude à mes directeurs, les Professeurs Sabine Kröger et Arnaud Dellis pour avoir accepté de superviser et de financer cette recherche, pour leur grande disponibilité et pour leurs avis éclairés. Leur présence à mes cotés a été déterminante pour la réalisation de ce travail. Je remercie également M. Mardochée Bopo Mokengoy pour avoir contribué à l’amélioration de la qualité de ce document par ses commentaires.
Introduction
Les sondages pré-électoraux jouent un rôle important dans les référenda et les élections modernes. Ils affectent les choix de politiques publiques et le bien-être social. En effet, les candidats utilisent les résultats de sondage pour sélectionner leurs plateformes électo-rales et décider de l’effort de mobilisation des électeurs (Shachar et Nalebuff, 1999). Les électeurs utilisent aussi les résultats de sondage pour coordonner leurs votes.
Cependant, les prédictions de certains sondages diffèrent sensiblement des résultats de l’élection. Par exemple, les sondeurs avaient prédit la victoire du parti Wildrose sur le parti Conservateur deux jours avant l’élection provinciale albertaine de 2012. Mais, à l’issue de l’élection, c’est plutôt le parti Conservateur qui sort victorieux avec 44% des votes (au lieu des 32% qui avaient été prédit). Le parti Wildrose vient en deuxième position avec seulement 34% des votes (au lieu des 41% qui avaient été prédit). Les sondeurs se sont également trompés en prédisant un parlement minoritaire lors des élections générales britanniques de 2015. Ces élections se sont en effet soldées par la victoire des Conservateurs sur les Travaillistes avec une majorité absolue des sièges au parlement.
De plus, les résultats des sondages pré-électoraux fluctuent énormément dans le temps comme dans l’espace. Les sondages effectués au Canada lors de l’élection générale onta-rienne de 20141 illustrent bien ces fluctuations. Environ trois semaines avant le jour du
scrutin, la société Forum Research publie les résultats d’un sondage dans lequel le parti libéral et le parti conservateur sont en tête avec les mêmes suffrages. Environ deux se-maines plus tard, la même société prédit la victoire du parti libéral avec 7 points d’avance sur le parti conservateur. Le même jour, la société EKOS annonce que les libéraux et les conservateurs l’emportent avec les mêmes suffrages. A la veille de l’élection , la société
1. Les résultats de sondage pris comme exemple sont tirés des sites web des organismes de son-dages correspondants : http ://poll.forumresearch.com/post/64/liberals-to-form-government-in-ontario/ pour société Forum Research, http ://www.ekospolitics.com/index.php/2014/06/359-vs-359-its-a-virtual-deadlock-as-we-approach-e-day/ et http ://www.ekospolitics.com/index.php/2014/06/an-overview-of-the-campaign-and-a-reasoned-guess-at-the-outcome/ pour société EKOS.
Forum Research maintient sa tendance tandis que la société EKOS prédit la victoire des libéraux avec 6 points d’avance sur les conservateurs. Finalement, les libéraux gagnent l’élection avec 38.6% des votes contre 31.2% pour les conservateurs.
Les fluctuations et les erreurs observées dans les résultats des sondages pré-électoraux peuvent s’expliquer par les fausses déclarations stratégiques des répondants (Forsythe et collab.,1996), l’influence des résultats de sondage sur le comportement des électeurs et des candidats (Erikson et collab.,2002) ou par la méthode de sondage utilisée pour éliciter les préférences individuelles ou collectives (Manski, 1990, 2002; Delavande et Manski, 2010).
Les principaux mécanismes d’élicitation et d’agrégation des préférences sont les sondages et les marchés de prédiction. Les marchés de prédiction sont conçus pour éliciter les an-ticipations des individus sur le résultat de l’élection. Par contre, les sondages invitent les individus à révéler leurs anticipations sur leur propre comportement de vote (inten-tions de vote individuelles) ou leurs anticipa(inten-tions sur le résultat de l’élection (anticipation sur le comportement agrégé de la population) selon le format de question utilisé. En outre, quelle que soit la nature de l’information révélée, la forme de la question peut contraindre le répondant à donner soit une réponse qualitative2 (question binaire3 ou binaire avec incertitude4) soit une probabilité (question probabiliste). Chaque format de
question implique un mécanisme particulier d’élicitation et d’agrégation des préférences de la population.
Les différentes méthodes d’agrégation des préférences ne conduisent généralement pas au même résultat. De plus, certaines méthodes peuvent être plus précises ou plus coûteuses que d’autres. Il est donc important pour les chercheurs et pour les organismes de sondage d’identifier la méthode d’élicitation et d’agrégation des préférences qui donne la meilleure prédiction du résultat des élections. Par ailleurs, les candidats et les décideurs politiques se basent sur les résultats de sondage pour faire des choix de politiques publiques. L’utilisa-tion de sondages erronés peut conduire au choix de politiques biaisées et donc socialement inefficaces.
2. Nous utilisons le terme ‘réponse qualitative’ pour les réponses qui ne peuvent être traitées comme une variable quantitative continue dans le cadre d’une analyse statistique. Il peut s’agir par exemple du nom du candidat qui gagnera les élections.
3. Une question binaire est une question dans laquelle le répondant a le choix entre deux alternatives (ex : Oui/Non, Candidat A/ Candidat B).
4. Une question binaire avec incertitude est une question dans laquelle le répondant a le choix entre trois alternatives (ex : Candidat A, Candidat B, N’est pas sûr).
Plusieurs études se sont déjà intéressées à la question du choix de la meilleure méthode d’élicitation et d’agrégation des préférences dans les sondages d’opinion. Toutes ces études ont procédé à une comparaison théorique ou empirique de deux méthodes ou groupes de méthodes à la fois en se basant généralement sur un nombre limité de critère de comparaison. Par exemple,Manski(1990) a montré que les réponses aux questions binaires (Ex : pour quel candidat allez-vous voter lors des prochaines élections ? ) comportent très peu d’information sur le comportement de vote subséquent des individus. Manski(2002) a mis en évidence les avantages et les inconvénients des questions binaires et des questions probabilistes dans le contexte des élections. Delavande et Manski(2010) ont comparé les questions de sondages pré-électoraux binaires avec incertitude et probabilistes à partir des données de l’ALP (« American Life Panel »).Rothschild et Wolfers(2013) ont comparé les pouvoirs prédictifs des intentions de vote et des anticipations des individus sur le résultat de l’élection. Enfin, Erikson et Wlezien (2012) ont comparé les pouvoirs prédictifs des sondages et des marchés de prédiction en utilisant des données collectées sur les élections américaines entre 1880 et 2008.
Le présent mémoire s’intéresse à l’effet du biais de négligence de corrélation et des diffé-rents formats de question utilisés par les sondeurs sur le pouvoir prédictif des sondages. Il vise à identifier les formats de question qui permettent de mieux prédire le résultat des élections. Les objectifs spécifiques sont d’évaluer le pouvoir prédictif des différents formats de questions posés dans les sondages pré-électoraux puis de mesurer la capacité des répondants à prendre en compte la corrélation entre les préférences électorales et les coûts de participation aux élections.
Les résultats de notre recherche ont un double intérêt. D’une part, ils permettront de mieux prédire le comportement des individus aussi bien dans les élections que dans d’autres contextes (ex : sondage des comportements de consommation, prévision des ventes d’un nouveau produit,. . . ). D’autre part, ils contribueront à la littérature sur le biais de négligence de corrélation (BNC). Il s’agit en effet, du premier travail qui essaie de mesurer l’effet du BNC sur les réponses aux questions de sondage.
Le mémoire s’articule autour de trois chapitres. Le premier chapitre passe en revue la littérature sur les formats de question utilisés dans les sondages. Le deuxième chapitre est consacré à l’extension du modèle théorique deManski(1990) au cas des questions binaires avec incertitude et des questions probabilistes. Le dernier chapitre présente le dispositif expérimental utilisé pour évaluer l’effet du biais de négligence de corrélation et analyse les résultats obtenus dans le cadre d’une expérience pilote de laboratoire.
Chapitre 1
Sondages
1.1
Formats de question utilisés dans les sondages
La formulation des questions est une étape importante de la méthodologie d’enquête. Les organismes de sondage utilisent une grande diversité de format de question dans les sondages pré-électoraux. Le tableau A.1 en annexe fait un inventaire des principaux formats de question posés par les organismes de sondage ou proposés par les chercheurs.
Le tableau1.1ci-dessous classe les différents formats de question du tableauA.1en six ca-tégories selon la nature de l’information demandée au répondant et la forme des réponses possibles. Les organismes de sondage exploitent généralement deux types d’information pour prédire le résultat des élections : les anticipations de l’individu sur son propre com-portement de vote (Type de question I, II et III du tableau 1.1) ou de participation au vote et les anticipations de l’individu sur le résultat de l’élection (Type de question IV, V et VI du tableau 1.1). L’anticipation de l’individu sur son propre comportement de vote correspond à son intention de vote au moment du sondage. Par contre, l’anticipation de l’individu sur le résultat de l’élection résulte d’un processus d’élicitation et d’agrégation propre à l’individu. Nous donnerons plus de détails sur ce type d’anticipation à la section 2.2.2.
Quel que soit le type d’information demandé, le format de question utilisé peut inciter le répondant à donner une réponse binaire (Type de question I et IV du tableau 1.1), une réponse binaire avec la possibilité d’exprimer de l’incertitude sur le vote subséquent (Type de question II et V du tableau 1.1) ou une réponse probabiliste (Type de question III et VI du tableau 1.1).
Les questions binaires invitent le répondant à déclarer son intention de voter ou non pour un candidat donné. Mais, le répondant peut être indécis. Les questions binaires avec incertitude permettent au répondant de renseigner le sondeur sur cette possibilité. Elles constituent un format intermédiaire entre les questions binaires et les questions probabilistes. Les questions probabilistes invitent le répondant à donner sa probabilité subjective de voter pour un candidat donné. Dans la réponse à ce type de question, le répondant peut donner une mesure quantifiable de l’incertitude qui pèse sur son intention de vote.
Les questions binaires, binaires avec incertitude et probabilistes peuvent également être utilisées pour révéler les anticipations des répondants sur le résultat de l’élection. Dans ce cas, les répondants sont invités à prédire le nom du candidat gagnant (question binaire) ou la probabilité que l’un des candidats gagne les élections (question probabiliste). Les répondants peuvent aussi exprimer leur incertitude sur le résultat de l’élection (question binaire avec incertitude). Toutefois, nous n’avons pas trouvé d’exemples de questions binaires avec incertitude sur le résultat de l’élection dans la littérature.
Table 1.1 – Différents types de question posés dans les sondages pré-électoraux Type de question Information demandée Forme de la réponse Exemples I Anticipations de
l’in-dividu sur son propre comportement
Binaire “As it now stands, George Bush, a Republican, will be running for president, as will Michael Dukakis, a Democrat. Who do you expect to vote for president ?”(Burden,1997)
II Binaire avec
incertitude
“Suppose that the presidential election were being held today and you had to choose bet-ween Barack Obama as the Democratic Par-ty’s candidate, and Mitt Romney as the Re-publican Party’s candidate. Who would you be more likely to vote for – Barack Obama, the Democrat, or Mitt Romney, the Republican ? (IF UNSURE :) As of today, who do you lean more toward ?”(CNN/ORC International Poll, 2012)
III Probabiliste “In the governor’s election between Mr.
Rhodes and Mr. Celeste, what is the percent chance that you will vote for Mr. Rhodes ? And what is the percent chance that you will vote for Mr. Celeste ?” (Burden,1997)
IV
Anticipations de l’in-dividu sur le compor-tement agrégé de la population
Binaire “Regardless of whom you support, and trying to be as objective as possible, who do you think will win the election : Barack Obama or Mitt Romney ?” (CNN/ORC International Poll, 2012)
V Binaire avec
incertitude
–
VI Probabiliste “Barack Obama is the Democratic candidate
and John McCain is the Republican candidate. What do you think is the percent chance that each man, or someone else, will win the elec-tion ?” (Delavande et Manski,2012)
1.2
Pouvoir prédictif des sondages
Le principal objectif des sondages pré-électoraux est de donner une estimation précise du résultat des élections. La qualité des estimations obtenues peut être affectée par le format de question choisi. En effet, la nature et la distribution des réponses varient d’un format de question à un autre. Le problème du choix du format de question qui fournit la meilleure prédiction du comportement des individus est une préoccupation récente en économie comparativement aux autres disciplines (Manski, 1990).
Manski (1990) est, à notre connaissance, le premier à modéliser la relation entre les in-tentions déclarées et le comportement subséquent des individus sous l’hypothèse (la plus optimiste) que les individus ont des anticipations rationnelles et que les intentions décla-rées sont les meilleures prédictions de leurs futurs comportements. Il conclut après une démonstration théorique rigoureuse que les questions binaires portant sur les intentions ne permettent pas d’identifier la probabilité que l’individu se comportera d’une certaine manière. Autrement dit, les données d’intentions binaires permettent de borner mais pas d’estimer les parts de vote des différents candidats (ou options) dans une élection bipartite (ou un référendum). Ce problème d’identification vient du fait que le répondant n’a pas la possibilité d’exprimer son incertitude dans la réponse.
En plus du problème d’identification, les questions binaires ont plusieurs limites com-parativement aux questions probabilistes. Selon Manski(2002), les questions binaires ne permettent pas la comparabilité interpersonnelle des réponses obtenues. Prenons l’exemple d’une élection à deux candidats (A et B). Un sondeur peut demander aux électeurs de donner le nom du candidat qu’ils choisiront. Certains électeurs sont indécis au moment du sondage. Deux électeurs ayant des probabilités différentes de voter pour le candidat A peuvent donner la même réponse au sondeur. En revanche, les réponses probabilistes rendent possible la comparaison entre les individus. De plus, les chercheurs peuvent éva-luer la cohérence interne et la précision des réponses probabilistes en utilisant les lois de probabilité ou les probabilités objectives de réalisation des événements anticipés (Manski, 2002).
Delavande et Manski (2010) ont confirmé les résultats de Manski (1990) et de Manski (2002) par un test empirique de comparaison du pouvoir prédictif des questions binaires avec incertitude et des questions probabilistes dans le cadre des élections présidentielles américaines de 2008. Selon ces auteurs, le pouvoir prédictif des questions probabilistes est supérieur à celui des questions binaires avec incertitude. Aussi, le pouvoir prédictif
des différents formats de question diminue-t-il avec l’incertitude qui pèse sur le résultat de l’élection. Les sondages deviennent plus précis à mesure que la date du scrutin se rapproche. Cependant, une meilleure prédiction du comportement de vote pourrait être obtenue en utilisant les deux types de réponses (binaires et probabilistes) ou en utili-sant les réponses courantes et passées du même individu comme variables explicatives. Par ailleurs, les attributs (âge, sexe, race, éducation) des répondants n’améliorent pas le pouvoir prédictif dans les modèles linéaires (Delavande et Manski, 2010).
Les marchés de prédiction1 sont de plus en plus utilisés comme alternative aux sondages.
Les utilisateurs des marchés de prédiction interprètent le prix du marché comme une prédiction du résultat de l’événement d’intérêt. Mais, les preuves théoriques de Manski (2006), Gjerstad (2004) et Wolfers et Zitzewitz (2006a) montrent que le prix d’équilibre obtenu sur un marché de prédiction peut être très différent de la croyance moyenne des agents. Même si les résultats théoriques sont contradictoires, plusieurs auteurs soutiennent que les marchés de prédiction prédisent généralement bien les résultats des événements futurs en pratique. La question du choix de la meilleure méthode fait l’objet d’un débat entre les défenseurs des marchés de prédiction (Forsythe et collab., 1992; Kou et Sobel, 2004;Wolfers et Zitzewitz,2006b;Arrow et collab.,2008;Snowberg et collab.,2013) et les partisans des sondages (Manski,2006;Erikson et Wlezien,2008,2012). Les défenseurs des marchés de prédiction soutiennent que le prix d’équilibre sur le marché agrège efficacement l’ensemble de l’information détenue par les agents et que cet ensemble d’information contient les résultats de sondage. Par conséquent, les marchés de prédiction devraient mieux prédire le résultat des élections que les sondages. Selon les partisans des sondages, le prix d’équilibre observé sur les marchés de prédiction et les résultats des sondages d’opinion (Types de question I et II du tableau 1.1) effectués le même jour ne sont pas directement comparable. En effet, les prix prédisent le résultat final des élections alors que les sondages d’opinion agrègent les préférences individuelles observées le jour du sondage (Erikson et Wlezien, 2008). De plus, le marché peut souffrir de biais comportementaux tel que le « favorite-longshot bias » (Snowberg et collab., 2013)2.
Les approches utilisées par les marchés et les sondages peuvent être combinées en
de-1. Les marchés de prédiction sont des marchés sur lesquels s’échangent des contrats dont les rendements
dépendent de la réalisation d’un événement futur (Wolfers et Zitzewitz,2004).Contrairement aux marchés
financiers, les marchés de prédiction sont essentiellement conçus pour agréger l’information détenue par les agents (Luckner et collab.,2011).
2. En présence de « favorite-longshot bias », les prix d’équilibre observés sur le marché ont tendance à surestimer la vraie probabilité pour les événements peu probables et à sous-estimer la vraie probabilité pour les événements très probables.
mandant aux individus de donner leurs anticipations sur le comportement agrégé de la population dans le cadre d’un sondage. Dans ce cas, l’information n’est plus agrégée par le marché mais par le répondant. Selon Rothschild et Wolfers (2013), cette approche pourrait améliorer la précision des sondages. En effet, ils ont montré à partir d’une série de sondages pré-électoraux portant sur des questions binaires que les anticipations des individus sur le comportement agrégé de la population prédisent mieux le résultat des élections que les intentions de vote. Chaque individu formerait ses anticipations en se basant sur son estimation des intentions de vote d’un plus grand nombre de personnes. Les anticipations sur le comportement agrégé de la population contiendraient donc plus d’information sur le résultat de l’élection que les intentions de vote individuelles. Mais, ces anticipations peuvent également être biaisées selon le degré de connexion entre les différents types d’individus sondés.
Par ailleurs, les anticipations et les intentions de vote d’un même individu peuvent être corrélées. Delavande et Manski (2012) ont montré à partir de questions probabilistes que les anticipations des répondants sur le résultat de l’élection sont fortement et positivement corrélées aux préférences électorales individuelles quelque soient les caractéristiques des individus, la période de sondage ou le type d’élection concerné. Les individus auraient tendance à croire que leur candidat préféré a plus de chance de gagner les élections. Cette corrélation est une régularité empirique appelée « effet de faux consensus (false consensus effect) ». Selon Delavande et Manski (2012), l’effet de faux consensus peut s’expliquer de deux manières différentes : soit l’individu détermine les préférences sociales à partir de ses propres préférences, soit la perception des préférences sociales détermine les préférences individuelles qui affectent à leur tour les préférences sociales à travers le processus d’agrégation (Delavande et Manski, 2012). Cet effet peut également être le résultat d’un comportement stratégique des individus visant à influencer la décision de vote des autres électeurs.
1.3
Biais de négligence de corrélation : définition et
conséquences
Nous avons montré aux sections 1.1 et 1.2 que les sondages prédisent le futur en agré-geant les anticipations révélées par les individus. Ces anticipations peuvent être affectées par de nombreux biais (favorite-longshot bias, false consensus effect,. . . ). L’un des biais récemment mis en évidence est le biais de négligence de corrélation (correlation neglect ).
Le biais de négligence de corrélation s’observe lorsque les individus ne prennent pas en compte la corrélation entre les variables pertinentes dans leurs décisions ou dans la forma-tion de leurs anticipaforma-tions. En effet, les anticipaforma-tions ou les choix optimaux des individus peuvent dépendre de la corrélation entre des variables pertinentes (rendements de diffé-rents actifs, signaux d’informations, décisions de vote et de participation aux élections,. . . ) dans de nombreux contextes (sondages, problème d’allocation de ressources, formation d’anticipations sur les marchés financiers,. . . ). Selon Enke et Zimmermann (2013), la négligence de corrélation est un biais cognitif résultant de l’incapacité des individus à comprendre les implications de la corrélation entre différentes variables sur leurs antici-pations. Il ne s’agit pas d’un arbitrage rationnel de l’individu entre l’élaboration d’une anticipation juste et l’économie de ressources cognitives rares (Enke et Zimmermann, 2013).
La mise en évidence du biais de négligence de corrélation dans les expériences de labo-ratoire a fait l’objet de plusieurs études. Ces études soutiennent l’existence du biais de négligence de corrélation et de déviations par rapport au modèle de l’utilité espérée ou de l’utilité dépendante des rangs (Rank dependent utility)3, même si l’environnement et
le dispositif expérimental utilisé varient d’une étude à une autre.
Par exemple, Kroll et collab. (1988) ont remarqué pour la première fois, dans une expé-rience visant à tester les hypothèses du théorème de séparation et le modèle d’évaluation des actifs financiers (« Capital Asset Pricing Model ») que les décisions d’allocation des individus ne sont pas affectées par les changements dans la matrice de variance-covariance des rendements des titres risqués.
Kallir et Sonsino (2009) ont étudié l’effet d’une variation de la corrélation entre les ren-dements de deux actifs financiers (A et B) sur les décisions d’allocations de ressources chez des étudiants de premier et deuxième cycle des écoles de commerce et gestion. Le dispositif expérimental utilisé comporte cinq problèmes de prédiction et d’allocation de ressources. Dans chaque problème, les étudiants doivent prédire les rendements futurs de l’actif A (B) étant donnés les rendements de l’actif B (A) puis répartir leurs dotations
3. Le modéle de l’utilité dépendante des rangs est un modèle de prise de décision en situation d’in-certitude. Contrairement au modèle de l’utilité espérée, les utilités des différents résultats ne sont pas pondérées par des probabilités mais par la différence des rangs transformés. L’utilité dépendante des
rangs (RDU (L)) d’une loterie L = (p1 : x1, . . . , pn : xn) avec des résultats complètement ordonnés
(x1 ≥ . . . ≥ xn) est donnée par RDU (L) = Pnj=1[w(pj + . . . + p1) − w(pj−1+ . . . + p1)] · U (xj) où
(pj+ . . . + p1) est le rang du résultat xj+1; (pj−1+ . . . + p1) est le rang du résultat xj; w(.) est une
fonction de pondération de probabilité et U (xj) est l’utilité associée au résultat xj (voir Wakker(2010)
initiales entre les deux actifs. Les problèmes sont conçus de sorte que la corrélation entre les rendements des actifs A et B varient de -2/3 à +2/3. De plus, la distribution de l’actif A domine stochastiquement celle de l’actif B. Ainsi, un individu rationnel devrait allouer l’ensemble de ses ressources à l’actif A. L’allocation des ressources à l’actif B se justifie seulement lorsque la probabilité conjointe d’observer des rendements élevés pour l’actif B et des rendements faibles pour l’actif A augmente. Les résultats de la prédiction des rendements montrent que les individus souffrent d’un biais d’appariement des probabi-lités (probability matching). De plus, ils ne prennent pas en compte la corrélation entre les rendements des actifs dans leurs décisions d’allocation de ressources bien qu’ils soient conscients de l’existence de cette corrélation. En outre, les choix d’allocation ne sont pas affectés par le changement de signe de la corrélation.
Eyster et Weizsäcker(2011) ont mis en œuvre une expérience similaire à celle deKallir et Sonsino(2009) pour tester l’existence du biais de négligence de corrélation dans les choix de portefeuilles d’actions. Le dispositif expérimental comporte huit paires de problèmes de choix de portefeuille. Dans chaque paire de problème, les sujets doivent répartir leur dotation initiale entre deux titres ayant le même rendement espéré et dont les rendements historiques peuvent être corrélés ou non selon le problème. Les paires de problèmes sont conçues de sorte qu’il soit possible de déterminer une allocation équivalente (fournissant le même niveau d’utilité) pour chaque allocation faisable choisie par l’individu dans l’un des problèmes. Les résultats montrent que les choix des individus ne sont pas conforment aux modèles standards de choix de portefeuille. Ils mettent en évidence deux types de biais : négligence de corrélation et heuristique 1/n. En effet, les sujets traitent les titres dont les rendements sont corrélés comme s’ils ne l’étaient pas ou répartissent tout simplement leur richesse de façon équitable entre les différents titres quel que soit la variance des rendements.
Enfin, Enke et Zimmermann (2013) ont étudié l’effet de la corrélation entre les sources d’information sur les anticipations des individus et sur le résultat d’un marché financier expérimental. La corrélation entre les différentes sources d’information peut provenir du partage d’une même source par différents médias (cas des agences de presse). Ils utilisent un dispositif expérimental dans lequel les individus sont incités à prédire la future réali-sation d’une variable aléatoire donnée en se basant sur différentes sources d’information. Ces sources d’information peuvent être corrélées ou non selon le traitement. Le dispositif est conçu de sorte que les participants soient informés de l’existence de cette corrélation et que les prédictions d’un individu rationnel diffèrent de celles d’un individu qui souffre
de biais de négligence de corrélation. Les résultats montrent que les individus négligent la corrélation entre les différentes sources d’information au moment de la formation de leurs anticipations.
Le biais de négligence de corrélation peut avoir des conséquences positives (dans les contextes de choix collectif ) ou négatives sur les individus, les marchés ou la population. Eyster et Weizsäcker(2011) ont montré que le biais de négligence de corrélation conduit au choix d’un portefeuille plus (ou moins) risqué que le portefeuille préféré de l’individu selon la nature (positive ou négative) de la corrélation qui existe entre les différents titres. De même, les anticipations des individus souffrant de biais de négligence de corrélation peuvent être artificiellement plus élevées ou plus faibles que celles d’un individu ration-nel (Enke et Zimmermann, 2013). Par ailleurs, dans un marché financier expérimental, la négligence de corrélation entraîne des déviations systématiques et prévisibles du prix d’équilibre par rapport à la valeur attendue sur un marché constitué uniquement d’indi-vidus rationnels (Enke et Zimmermann, 2013). En revanche, dans le cadre des élections, Levy et Razin(2015) démontrent que la négligence de corrélation entraîne la polarisation des opinions mais ne conduit pas nécessairement à un résultat inefficace. En effet, une société composée d’électeurs souffrant de négligence de corrélation peut agréger les infor-mations de manière plus efficace lorsque la distribution des préférences est hétérogène et suffisamment équilibrée.
Chapitre 2
Modèle
2.1
Cadre d’analyse
Dans cette section, nous modélisons la réponse d’un individu aux différents formats de question du tableau1.1(Cf. section1.1) afin d’évaluer leurs capacités respectives à prédire le résultat des élections. La démarche utilisée est basée sur les travaux de Manski(1990, 1995). La preuve proposée pour le cas des questions binaires parManski(1990) est étendue aux cas des questions binaires avec incertitude et des questions probabilistes en prenant en compte la décision de participation. Nous nous limitons au cas des élections à deux candidats (A ou B) ou des référenda. L’hypothèse d’une élection à deux candidats est moins restrictive qu’il n’y paraît. En effet, selon la loi de Duverger (1951), les systèmes politiques qui ont recours au vote de pluralité tendent vers le bipartisme.
Considérons une décision binaire y devant être prise par un individu à une période future (t = 1). Dans le cas d’une élection à deux candidats, la variable y représente le vote effectif de l’individu à la période t = 1 avec y = 1 s’il vote pour le candidat A et y = 0 s’il vote pour le candidat B. Supposons que les organismes de sondage souhaitent éliciter à la période t = 0, les anticipations binaires (b) ou probabilistes (p) de l’individu sur son propre comportement subséquent (o) ou sur le comportement agrégé de la population (g). Par exemple, les organismes de sondage peuvent demander aux individus (à la période t = 0) de donner leur intention de vote pour le candidat A ou leur anticipation sur les intentions de vote des autres membres de la population. Les répondants ont la possibilité d’exprimer de l’incertitude sur leur intention de vote ou de ne pas participer au vote. La décision de participation au vote est une variable binaire a avec a = 1 lorsque l’individu participe et choisit l’une des deux valeurs de y et a = 0 lorsque l’individu ne participe pas
et ne peut choisir aucune des valeurs de y.
Les exemples de futurs choix binaires pour lesquels les sondeurs élicitent les anticipations des individus sont très variés (décision d’achat, événement sportif, élection à deux can-didats, référendum,. . . ). Dans tous les cas, l’objectif des organismes de sondage ou des chercheurs est d’estimer une décision future agrégée E[y] ou P (y) pour l’ensemble des individus, à partir des réponses données par les personnes enquêtées à une période anté-rieure t = 0. Notez que P (y = 1) = E[y] correspond à la proportion des votes recueillis par le candidat A dans le cas d’une élection à deux candidats.
2.2
Questions binaires
Pour prédire les réponses des individus aux différents formats de question, nous avons besoin de faire des hypothèses sur leur comportement. CommeManski(1990,1995), nous supposons dans un premier temps que les individus ont des anticipations rationnelles. Un individu ayant des anticipations rationnelles reconnaît que ces futures décisions dépendent à la fois de l’information dont il dispose au moment du sondage et des futures réalisations d’événements incertains. L’hypothèse d’anticipation rationnelle implique que les répon-dants connaissent le processus qui détermine leur choix et qu’ils répondent en donnant leur meilleure prédiction du futur compte tenu de l’information disponible au moment du sondage. Pour déterminer leurs meilleures prédictions, les répondants minimisent une fonction de perte interne.
Supposons dans un premier temps, que tous les enquêtés participent aux élections (a = 1) ou répondent comme s’ils étaient certains de participer (P (a = 1) = 1). L’hypothèse d’un taux de participation de 100% est plausible dans les pays où le vote est obligatoire (Ex : Belgique, Australie). Notons x les caractéristiques du répondant. Soit bo|a=1l’intention de
vote du répondant avec bo|a=1 = 1 s’il compte voter pour le candidat A et bo|a=1 = 0 s’il
compte voter pour le candidat B. Soit bg|a=1l’anticipation du répondant sur le résultat de
l’élection avec bg|a=1 = 1 s’il estime que le candidat A gagnera l’élection et bg|a=1 = 0 s’il
estime que le candidat B gagnera l’élection. Un chercheur qui observe les caractéristiques (x) du répondant, son intention de vote (bo|a=1) et ses anticipations (bg|a=1) sur le résultat
2.2.1
Intentions de vote individuelles
Pour répondre à une question binaire sur leurs intentions de vote, les individus prennent en compte l’information disponible et l’incertitude qui pèse sur leurs futurs (Manski,1990). Soient st l’information détenue par le répondant à la période t (avec t = {0, 1}), z un
événement incertain dont les réalisations affectent la décision de vote et y(st, z) le
com-portement de vote subséquent du répondant. Sous l’hypothèse d’anticipation rationnelle, le répondant connaît y(st, z) ainsi que la distribution objective de probabilité de
l’événe-ment incertain P (z|st). Par conséquent, le répondant peut déterminer P (y = 1|st) puisque
P (y|st) = R y(s, z)dP (z|st) et pour y = 1, R y(st, z)dP (z|st) = R dP (z|st) = P (z|st) =
P (y = 1|st). La réponse optimale d’un répondant qui minimise une fonction de perte1
quelconque (L(y − b)) est donnée par :
bo|a=1= 1 si P (y = 1|s0) ≥ π
bo|a=1= 0 si P (y = 1|s0) ≤ π
où la valeur de π dépend de la fonction de perte du répondant. Le répondant déclare qu’il votera pour le candidat A tant que sa probabilité subjective P (y = 1|s0) de voter pour ce
candidat est supérieure au seuil π. De plus, la proportion des répondants qui se trompent en déclarant leur intention de vote est inférieure à π et la proportion des répondants dont l’intention de vote coïncident avec le comportement de vote subséquent est supérieure à π. Autrement dit,
0 ≤ P (y = 1|s0, bo|a=1 = 0) ≤ π ≤ P (y = 1|s0, bo|a=1= 1) ≤ 1
Dans le cas particulier de la fonction de perte quadratique L(y − b) = (y − b)2, le gain
espéré pour une réponse binaire b quelconque est E[L|b, st] = P (y = 1|st)(y − b)2+ (1 −
P (y = 1|st))(y − b)2. Il suit que pour b = 1 : E[L|b = 1, st] = 1 − P (y = 1|st) et pour
b = 0 : E[L|b = 0, st] = P (y = 1|st). Pour minimiser ces pertes, le répondant rapporte
b = 1 si 1 − P (y = 1|st) ≤ P (y = 1|st) ; ce qui implique que P (y = 1|st) ≥ 1/2. La valeur
de π est donc de 1/2. Ce résultat tient pour n’importe quelle fonction de perte symétrique.
L’hypothèse d’anticipations rationnelles ne suffit pas pour borner P (y) parce que le cher-cheur ne connaît ni s0 ni π. Pour borner P (y), nous supposons en plus que les
caractéris-tiques observables x des répondants sont un sous-ensemble de s0et que tous les répondants
1. La fonction de perte est une fonction de l’erreur e = y − bo|a=1commise par les enquetés dans leur
utilisent une même fonction de perte connue du chercheur. Dans ce cas, les bornes sont données par :
0 ≤ P (y = 1|x, bo|a=1 = 0) ≤ π ≤ P (y = 1|x, bo|a=1= 1) ≤ 1 (2.1)
Supposons maintenant que le chercheur peut estimer P (bo|a=1 = 1|x) de façon non
para-métrique à partir d’un sondage et qu’il souhaite borner P (y = 1|x). P (y = 1|x) peut être décomposé comme suit :
P (y = 1|x) ≡ P (y = 1|x, bo|a=1= 0)P (bo|a=1= 0|x) (2.2)
+P (y = 1|x, bo|a=1= 1)P (bo|a=1= 1|x)
La proportion P (y = 1|x) des individus qui votent pour le candidat A correspond à la somme pondérée de la proportion des individus qui se trompent en déclarant vouloir voter pour le candidat B et de la proportion des individus pour lesquels l’intention de voter pour le candidat A coïncide avec le comportement de vote subséquent. Les poids sont respectivement la proportion des individus qui déclarent vouloir voter pour le candidat B (P (bo|a=1= 0|x)) et la proportion de ceux qui déclarent vouloir voter pour le candidat
A (P (bo|a=1 = 1|x)). La proportion des individus qui votent pour le candidat B est
(1 − P (y = 1|x)).
Les équations 2.1 et 2.2 impliquent que
0 ≤ P (y = 1|x, bo|a=1= 0)P (bo|a=1= 0|x) ≤ πP (bo|a=1= 0|x) et
πP (bo|a=1 = 1|x) ≤ P (y = 1|x, bo|a=1 = 1)P (bo|a=1= 1|x) ≤ P (bo|a=1= 1|x)
Nous pouvons maintenant dériver les bornes inférieure (LB) et supérieure (U B) de P (y = 1|x) comme suit :
LB = πP (bo|a=1 = 1|x)
U B = πP (bo|a=1= 0|x) + P (bo|a=1= 1|x) (2.3)
L’application de ces bornes par un chercheur peut être illustrée dans un exemple simple de sondage. Soit un sondage dans lequel 68% des répondants déclarent qu’ils voteront pour le candidat A lors des prochaines élections (P (bo|a=1 = 1|x) = 0.68). Si tous les répondants
ont des anticipations rationnelles et minimisent une fonction de perte symétrique (π = 1/2), alors les bornes obtenues à l’équation2.3 se calculent comme suit :
1/2 ∗ 0.68 ≤ P (y = 1|x) ≤ 1/2 ∗ 0.32 + 0.68 ⇒ 0.34 ≤ P (y = 1|x) ≤ 0.84
L’écart entre les bornes (U B − LB) est égal à πP (bo|a=1 = 0|x) + (1 − π)P (bo|a=1 =
1|x). Dans le cas des fonctions de perte symétriques, cet écart est toujours égal à 1/2 quelque soient les réponses des individus à la question binaire posée. Autrement dit, même sous l’hypothèse d’anticipations rationnelles, les estimations obtenues avec des questions binaires ont une très faible précision.
Le chercheur ne connaît pas la vraie valeur de P (bo|a=1|x). Les bornes U B et LB doivent
donc être estimées à partir des réponses au sondage. Des intervalles de confiance peuvent être construits autour des valeurs estimées des bornes.
2.2.2
Anticipations du résultat des élections
Les organismes de sondage demandent parfois aux individus de donner leur anticipation sur le comportement agrégé de la population (bg). Nous souhaitons modéliser le processus
par lequel l’individu détermine la réponse à ce type de question. Rothschild et Wolfers (2013) ont émis l’hypothèse que les répondants agrègent uniquement les intentions de vote des membres de leur réseau social pour répondre aux questions relatives au résultat de l’élection. Par soucis de simplicité, nous faisons l’hypothèse forte que tous les électeurs ap-partiennent à un même réseau social. Nous considérons également que les répondants ont des anticipations rationnelles et prennent en compte la décision de participation des élec-teurs dans leur réponse (bg|a=1). De plus, les répondants ont des ensembles d’information
distincts (si0). Ils connaissent la distribution P (y(s, z) = 1|s) pour toutes les réalisations
de l’ensemble d’information s ainsi que la distribution P (s) de s dans la population à n’importe quelle période.
Les répondants peuvent utiliser deux différentes méthodes pour déterminer leur prédiction du résultat de l’élection (bg|a=1). La première méthode consiste à agréger P (y = 1|si0) pour
tous les individus de la population et à rapporter bg|a=1 = 0 ou bg|a=1 = 1 selon le résultat
de l’agrégation. Dans ce cas, le répondant calcule P (y) = R R y(s, z)dP (z|si0)dP (si0) ;
ce qui implique P (y = 1) = R R dP (z|si0)dP (si0) = R P (z|si0)dP (si0) pour y = 1. La
réponse bg|a=1 à la question binaire sur les anticipations agrégées est donnée par :
bg|a=1 = 1 si P (y = 1) ≥ π
bg|a=1 = 0 si P (y = 1) ≤ π
où π dépend de la fonction de perte du répondant. En suivant la démarche exposée à la section 2.2.1, nous pouvons borner la part de vote du candidat A (P (y = 1)) et calculer
la largeur des bornes :
LB = πP (bg|a=1= 1)
U B = πP (bg|a=1 = 0) + P (bg|a=1 = 1)
U B − U L = πP (bg|a=1= 0) + (1 − π)P (bg|a=1 = 1) (2.4)
Ce résultat montre que la précision des questions portant sur le résultat de l’élection ne dépend pas des caractéristiques du répondant mais uniquement de leur fonction de perte. Si la fonction de perte est symétrique (π = 1/2), la largeur des bornes est égale à 1/2 comme dans le cas des questions binaires sur les intentions de vote individuelles.
La deuxième approche comporte deux étapes. Elle consiste à déterminer et à agréger les réponses bo|a=1(si) que les électeurs auraient données à une question binaire sur leurs
intentions de vote puis à rapporter la meilleure prédiction du résultat de cette agrégation. Ainsi, le répondant calcule P (y = 1|si) = R P (y(s, z) = 1|z)dP (z|si) pour chacun des
membres de la population et déduit leur réponses bo|a=1(si) comme suit :
bo|a=1(si) = 1 si P (y = 1|si) ≥ π
bo|a=1(si) = 0 si P (y = 1|si) ≤ π
où π dépend de la fonction de perte des électeurs. Il calcule ensuite la part de vote ¯P (y = 1) du candidat A en agrégeant les réponses attendues (bo|a=1(si)) puis détermine sa propre
réponse (bg|a=1) selon la valeur de ¯P (y = 1).
¯ P (y = 1) = Z bo|a=1(si)dP (s) (2.5) bg|a=1 = 1 si P (y = 1) ≥ π¯ bg|a=1 = 0 si P (y = 1) ≤ π¯
Les bornes de la part de vote du candidat A et leur largeur sont données par :
LB = π ¯P (bg|a=1= 1)
U B = π ¯P (bg|a=1 = 0) + ¯P (bg|a=1 = 1)
U B − LB = π ¯P (bg|a=1 = 0) + (1 − π) ¯P (bg|a=1= 1) (2.6)
Les deux méthodes décrites ci-dessus ne donnent pas le même résultat. Supposons par exemple que 20% de la population a 95% de chance de voter pour le candidat A et que
80% de la population a 49% de chance de voter pour le candidat A. En utilisant la première méthode avec une fonction de perte symétrique, le répondant calcul la probabilité de voter pour le candidat A en faisant 0.2 · 0.95 + 0.8 · 0.49 = 0.51. Puisque P (y = 1) ≥ 1/2, le répondant rapporte bg|a=1 = 1. Par contre, en utilisant la deuxième méthode, le répondant
calcule la probabilité de voter pour le candidat A en faisant 0.2 · 1 + 0.8 · 0 = 0.2. Puisque P (y = 1|si) ≤ 1/2, il rapporte bg|a=1 = 0. En revanche, bien que les résultats soient
différents, les largeurs des bornes calculées pour les parts de vote sont toutes égales à 1/2 dans le cas d’une fonction de perte symétrique.
2.3
Questions binaires avec incertitude
Nous avons montré à la section 2.2.1 que les estimations obtenues à partir de questions binaires ont une très faible précision. L’utilisation d’une question binaire avec incertitude permet d’obtenir une meilleure précision en réduisant l’écart entre les bornes.
Considérons le cas d’une question binaire avec incertitude dans laquelle le répondant a la possibilité de choisir l’une des trois réponses suivantes : « voter pour le candidat A », « voter pour le candidat B », ou « n’est pas sûr ». Les répondants qui choisissent la troisième option doivent ensuite dire s’ils penchent plus pour le candidat A ou pour le candidat B. Ce format de question divise les répondants en trois groupes (les partisans du candidat A, les partisans du candidat B et les électeurs indécis) étant donné les probabilités subjectives individuelles P (y = 1|st) de voter pour le candidat A.
Soit G une variable qualitative représentant le groupe idéologique (par exemple : démo-crates (D), démodémo-crates modérés (DM) ou républicains modérés (RM) et républicains (R)) auquel appartient le répondant. Pour simplifier les notations dans la suite, nous présen-tons les démocrates (D) comme des partisans du candidat A, les républicains (R) comme des partisans du candidat B et les modérés (DM ou RM) comme des électeurs indécis. Nous considérons également que la variable G prend respectivement les valeurs "1", "2" et "3" si le répondant est un partisan du candidat A, un partisan du candidat B ou un électeur indécis. Soient πL et πH (avec πL≤ π ≤ πH) les seuils de probabilité à l’intérieur
desquels le répondant déclare qu’il n’est pas sûr de son choix. Un répondant affirme qu’il est indécis lorsque πL≤ P (y = 1|st) ≤ πH. Les valeurs prises par ces seuils de probabilité
dépendent de la façon dont le répondant interprète l’expression « n’est pas sûr ». Notez que πL et πH représentent également l’erreur maximale que les partisans des candidats
classent parmi les partisans du candidat A lorsque πH ≤ P (y = 1|st) ≤ 1 ou parmi les
partisans du candidat B lorsque 0 ≤ P (y = 1|st) ≤ πL.
Pour simplifier le reste de la preuve, nous supposons que les deux seuils de probabi-lité (πL et πH) sont identiques pour tous les répondants. Si tous les répondants ont des
anticipations rationnelles et minimisent une fonction de perte symétrique, alors les par-tisans du candidat A ne rapporterons jamais bo|a=1 = 0 et les partisans du candidat
B ne rapporterons jamais bo|a=1 = 1 parce que (P (y = 1|s0, G = 1) ≥ πH ≥ π) et
(P (y = 1|s0, G = 2) ≤ πL ≤ π). Cela signifie que P (bo|a=1 = 0|x, G = 1) = 0 et
P (bo|a=1 = 1|x, G = 2) = 0. En revanche, les électeurs indécis rapportent bo|a=1 = 1 si
π ≤ P (y = 1|s0, G = 3) ≤ πH et bo|a=1 = 0 si πL≤ P (y = 1|s0, G = 3) ≤ π. Ces règles de
décision nous permettent de borner P (y|x, bo|a=1) pour les trois groupes de répondant en
utilisant la démarche présentée à la section 2.2.1.
Pour les partisans du candidat A :
πH ≤ P (y = 1|x, bo|a=1= 1) ≤ 1 (2.7)
Pour les partisans du candidat B :
0 ≤ P (y = 1|x, bo|a=1= 0) ≤ πL (2.8)
Pour les électeurs indécis :
πL≤ P (y = 1|x, bo|a=1 = 0) ≤ π (2.9)
π ≤ P (y = 1|x, bo|a=1 = 1) ≤ πH
Essayons à présent de borner P (y|x) à partir des résultats précédents. Les probabilités P (y = 1|x, G) et P (y = 1|x) peuvent être réécrites comme suit :
P (y = 1|x, G) ≡ P (y = 1|x, G, bo|a=1= 0)P (bo|a=1= 0|x, G) (2.10)
+P (y = 1|x, G, bo|a=1= 1)P (bo|a=1= 1|x, G)
et
P (y = 1|x) ≡ P (y = 1|x, G = 1)P (G = 1|x) + P (y = 1|x, G = 2)P (G = 2|x) (2.11) +P (y = 1|x, G = 3)P (G = 3|x)
Dans chaque groupe G, la proportion des individus qui votent effectivement pour le can-didat A (P (y = 1|x, G)) est une somme pondérée de la proportion des répondants qui se trompent en déclarant leur intention de vote (P (y = 1|x, G, bo|a=1 = 0)) et de la
pro-portion des répondants dont l’intention de vote coïncide avec le comportement de vote subséquent (P (y = 1|x, G, bo|a=1 = 1)). De même, la proportion totale des individus qui
votent effectivement pour le candidat A (P (y = 1|x)) est une somme pondérée de ceux qui votent pour ce candidat dans chaque groupe (P (y = 1|x, G)) ; les poids étant la proportion des individus de chaque groupe dans la population (P (G|x)).
Puisque les partisans du candidat A(B) ne déclarent jamais qu’ils voteront pour le can-didat B(A), alors P (bo|a=1 = 0|x, G = 1) = P (bo|a=1 = 1|x, G = 2) = 0. Les proportions
(P (y = 1|x, G)) des individus qui votent pour le candidat A dans chaque groupe sont calculées à partir de l’équation2.10 :
P (y = 1|x, G = 1) = P (y = 1|x, G = 1, bo|a=1= 1) (2.12)
P (y = 1|x, G = 2) = P (y = 1|x, G = 2, bo|a=1= 0) (2.13)
P (y = 1|x, G = 3) = P (y = 1|x, G = 3, bo|a=1= 0)P (bo|a=1= 0|x, G = 3) (2.14)
+P (y = 1|x, G = 3, bo|a=1= 1)P (bo|a=1= 1|x, G = 3)
En appliquant les bornes des équations 2.7, 2.8 et 2.9 aux équations 2.12, 2.13 et 2.14 , nous obtenons :
πH ≤ P (y = 1|x, G = 1) ≤ 1 (2.15)
0 ≤ P (y = 1|x, G = 2) ≤ πL (2.16)
πLP (bo|a=1= 0|x, G = 3) + πP (bo|a=1= 1|x, G = 3) ≤ P (y = 1|x, G = 3) (2.17)
≤ πP (bo|a=1 = 0|x, G = 3) + πHP (bo|a=1= 1|x, G = 3)
La meilleure précision qu’un chercheur puisse obtenir en estimant P (y = 1|x, G) est de 1 − πH pour les partisans du candidat A et de πL pour les partisans du candidat
B. Pour le groupe des électeurs indécis, la précision obtenue dépend de la fonction de perte des répondants (π), des seuils de probabilité (πL et πH) et de la proportion de
ceux qui penchent plus pour le candidat A (P (bo|a=1 = 1|x, G = 3)) ou le candidat B
(P (bo|a=1= 0|x, G = 3)).
Nous pouvons maintenant borner P (y = 1|x) en appliquant les bornes des équations2.15, 2.16 et2.17 à l’équation 2.11 :
où
LB = πHP (G = 1|x) + (πLP (bo|a=1 = 0|x, G = 3)
+πP (bo|a=1= 1|x, G = 3))P (G = 3|x)
U B = P (G = 1|x) + (πP (bo|a=1= 0|x, G = 3)
+πHP (bo|a=1= 1|x, G = 3))P (G = 3|x) + πLP (G = 2|x)
Les bornes de P (y = 1|x) dépendent des proportions des différents groupes d’électeurs dans la population, de la valeur de π et des seuils de probabilité πL et πH. Pour π = 1/2
et (πL= 1 − πH = ε), la largeur des bornes est :
U B − LB = P (G = 3|x)(1/2 − ε) + (1 − P (G = 3|x))ε (2.18)
L’équation2.18montre que la largeur des bornes dépend uniquement de la valeur prise par ε et de la proportion des électeurs indécis dans l’échantillon (P (G = 3|x)). Cette largeur est toujours strictement inférieure à 1/2 quelles que soient les valeurs de ε et P (G = 3|x).
Prenons un exemple de sondage pour illustrer ces résultats. Supposons que les partisans du candidat A représentent 45% de l’échantillon et que les partisans du candidat B repré-sentent 30% de l’échantillon. De plus, 30% des électeurs indécis rapportent qu’ils penchent plus pour le candidat A. Si tous les répondants minimisent une fonction de perte symé-trique (π = 1/2) et si ε = 0.2, la probabilité de voter pour le candidat A peut être bornée comme suit :
LB = 0.8 ∗ 0.45 + 0.25 ∗ (0.2 ∗ 0.7 + 0.5 ∗ 0.3) U B = 0.45 + 0.25 ∗ (0.5 ∗ 0.7 + 0.8 ∗ 0.3) + (0.2 ∗ 0.3)
⇒ 0.4325 ≤ P (y = 1|x) ≤ 0.6575
et l’écart entre les bornes est donné par U B − LB = 0.25 ∗ (0.5 − 0.2) + (1 − 0.25) ∗ 0.2 = 0.225 < 1/2.
La proportion des électeurs indécis diminue à mesure que le jour du scrutin se rapproche. Par ailleurs, Delavande et Manski (2010) ont montré dans une étude empirique que la précision des sondages augmente à mesure que le jour du scrutin se rapproche. Il se pourrait donc que la largeur des bornes diminue avec la proportion des électeurs indécis. Mais en théorie, ce résultat n’est valable que pour certaines valeurs de ε. En effet, la dérivée partielle de la largeur des bornes par rapport à P (G = 3|x) est égale à 1/2 − 2ε. La largeur des bornes est donc une fonction croissante de P (G = 3|x) lorsque ε < 1/4 et
une fonction décroissante de P (G = 3|x) lorsque ε > 1/4. Pour ε = 1/4, la largeur des bornes est égal à 1/4 quelle que soit la proportion des électeurs indécis.
2.4
Questions probabilistes
La prise en compte de l’incertitude dans les questions binaires améliore la précision mais ne résout pas le problème d’identification évoqué parManski(1990,1995).Manski(1990, 2004) recommande vivement d’utiliser des questions probabilistes pour identifier P (y = 1|x).
En faisant l’hypothèse que les répondants ont des anticipations rationnelles et qu’ils mi-nimisent une fonction de perte interne (L(y − po|a=1|s0)), il est possible de déterminer la
réponse optimale (po|a=1) d’un partisan du candidat A à une question probabiliste. Selon
la forme de la fonction de perte interne utilisée par le répondant, sa réponse optimale peut être l’espérance ou un quantile particulier de la distribution de la variable binaire y. Dans le cas particulier d’une fonction de perte quadratique, la réponse optimale d’un partisan du candidat A à la question probabiliste est :
po|a=1= argmin E((y − po|a=1)2|s0)
= P (y = 1|s0) = E(y)
Ce résultat implique que les réponses aux sondages probabilistes permettent de construire un estimateur sans biais de P (y = 1|x) lorsque les individus sont rationnels et minimisent une fonction de perte quadratique.
2.5
Décision de participation aux élections
Dans les sections précédentes, nous avions supposé que le taux de participation aux élec-tions est de 100%. Autrement dit, l’abstention n’est pas possible (a = 1). Nous n’avions donc pas besoin de modéliser la décision de participation aux élections. Cependant, dans la plupart des pays, les électeurs potentiels peuvent choisir de participer (a = 1) ou non (a = 0) aux élections. Ainsi, ils ne connaissent pas avec certitude leur comportement de participation (a) au moment du sondage. Dans ce cas, l’estimation des parts de vote des différents candidats passe par la détermination du taux de participation aux élections (P (a = 1|x)).
Pour déterminer le taux de participation aux élections, certains organismes de sondage utilisent les mêmes types de questions que celles décrites dans les sections 2.2, 2.3 et 2.4 (questions binaires, binaires avec incertitude et probabilistes). Les processus par lesquels les enquêtés répondent à ces types de question sont similaires à ceux utilisés dans le cas de la décision de vote. Les résultats des modèles théoriques développés dans les sections 2.2 à 2.4 s’appliquent donc également à la décision de participation au vote (a) tant que cette dernière est indépendante de la décision de vote (y).
D’autres organismes de sondage comme Gallup utilisent le « Likely Voter Model (LVM) » pour estimer la probabilité qu’un électeur donné participe aux élections. La démarche du LVM de Gallup consiste à poser une série de questions aux électeurs potentiels concer-nant leur intérêt pour les prochaines élections, leur comportement de vote passé, leur intention de participer au vote (question binaire) lors des prochaines élections et leurs caractéristiques sociodémographiques2. Des scores (allant de 0 à 7 ) sont alors attribués aux répondants selon leur réponse aux différentes questions. Un répondant a une proba-bilité élevée de participer aux élections lorsque son score est supérieur à une valeur seuil donnée. Une méthode spécifique à Gallup est utilisée pour estimer ce seuil. Une alterna-tive au LVM serait évidemment de demander directement aux enquêtés de donner leur probabilité subjective de participer au vote dans une question probabiliste.
2.6
Effet du biais de négligence de corrélation sur la
réponse au sondage
Les décisions de participation et de vote peuvent être dépendantes dans certaines situa-tions lorsque le taux de participation aux élecsitua-tions n’est pas de 100%. Par exemple, les institutions politiques peuvent réduire le coût de participation des partisans de certains partis politiques en facilitant leur inscription sur les listes électorales (Morton,2006). Les taux de participation à l’élection seraient donc différents d’un groupe d’individus à un autre. La corrélation entre les décisions de participation et de vote peut aussi provenir du coût psychologique de voter pour un mauvais candidat (Degan,2006;Degan et Merlo, 2011). En effet, ce coût psychologique est quasiment nul pour les électeurs extrémistes (qui connaissent avec certitude leur candidat préféré) mais non négligeable pour les électeurs modérés (qui ne connaissent pas avec certitude leur candidat préféré) ; ce qui entraîne une
corrélation négative entre les préférences électorales et les coûts psychologiques de vote des individus (Degan, 2006; Degan et Merlo, 2011).
L’existence d’une corrélation entre les décisions de participation et de vote devrait affecter les réponses données par un individu rationnel aux questions de sondage concernant les anticipations sur le résultat de l’élection (Types de question IV, V et IV du tableau 1.1). En effet, pour répondre à ces types de questions, un individu rationnel doit prendre en compte la distribution conjointe de probabilité des décisions de participation et de vote dans la population. Notez que la probabilité conjointe de participer aux élections et de voter pour un candidat donné dépend de la covariance entre les décisions de vote et de participation aux élections : P (y = 1, a = 1) = E(ay) = cov(a, y) + E(a) · E(y).
Chapitre 3
Expérience
3.1
Présentation du dispositif expérimental
Jusqu’à présent, nous avons fait l’hypothèse que les agents sont parfaitement rationnels. Mais, une abondante littérature suggère que les individus ont plutôt une rationalité li-mitée (incluant le biais de négligence de corrélation). Dans cette section, nous relâchons l’hypothèse de rationalité en utilisant une approche expérimentale. Nous proposons un dispositif expérimental pour mesurer l’effet du biais de négligence de corrélation sur les anticipations révélées par les individus dans les sondages pré-électoraux. Ce dispositif nous permettra également de comparer les pouvoirs prédictifs des différents formats de question.
La décision de vote est présentée comme un problème de choix individuel de consomma-tion dans l’expérience. Cet environnement particulier nous permet d’exclure les comporte-ments stratégiques ainsi que les effets de facteurs psychologiques susceptibles d’influencer le comportement de vote (ex : obligation moral de participer aux élections). Au cours de l’expérience, les participants jouent successivement le rôle d’enquêté (dans le cadre d’un sondage) puis celui de preneur de décision. Nous pouvons donc observer à la fois les anti-cipations des individus et leur comportement subséquent. L’écart entre les antianti-cipations des individus et leur comportement subséquent est une mesure du pouvoir prédictif du format de question utilisé pour révéler ces anticipations.
Dans l’expérience, les sujets ont le choix entre deux options (A et B). Ils peuvent également décider de ne pas faire de choix. Le choix de l’une des options est couteux. Le coût résultant du choix peut être élevé (cH) ou faible (cL). Le gain net du participant est la différence
entre la valeur de l’option choisie et le coût résultant du choix. Les participants qui décident de ne pas faire de choix reçoivent un montant alternatif (outside option).
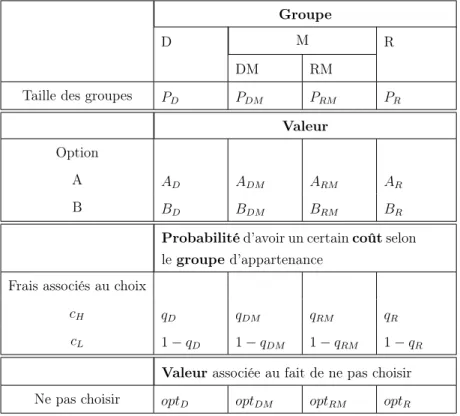
Il y a au total quatre types de personnes dans la population : D, DM, RM et R. Dans l’expérience, nous utilisons une terminologie neutre pour présenter les quatres types de personnes aux participants. Les dénominations D, DM, RM et R sont donc respective-ment remplacées par X, Y1, Y2 et Z. Les quatre types de personnes correspondent aux préférences des électeurs dans les modèles théoriques de vote. Les types D, DM, RM et R peuvent être respectivement associés aux groupes des démocrates, des démocrates mo-dérés, des républicains modérés et des républicains. Les options A et B représentent les deux candidats en liste pour les élections. La décision de “ne pas faire de choix” équivaut à l’abstention dans le contexte électoral. Les différents groupes sont également représentés dans la population. En revanche, la valeur des options et le montant reçu lorsque le sujet ne fait aucun choix varient d’un groupe à un autre.
Les sujets participent à un sondage avant de prendre leur décision. Au cours de la phase de sondage, l’expérimentateur demande aux sujets de prédire la décision de 100 autres personnes. Il leur demande ensuite de prédire leur propre choix futur (intention de choisir ou non l’une des options). Les différents formats de question présentés à la section 1.1 sont utilisés pour recueillir ces prédictions. Au moment de faire leur prédiction, les sujets sont informés sur les proportions des différents types dans la population, les valeurs des deux options et la distribution de probabilité des coûts pour chaque type. Ils connaissent également la valeur de l’option alternative pour chaque type. L’ensemble de ces informa-tions est présenté aux sujets en utilisant le modèle du tableau3.1ci-dessous. Cet ensemble d’information varie selon le traitement. L’expérience comporte quatre traitements. La cor-rélation entre la probabilité de choisir l’option A (préférence électorale) et la probabilité de faire un choix (décision de participation aux élections) varie d’un traitement à un autre. Le détail du plan expérimental et le jeu de données correspondant à chaque traitement sont présentés dans les sections3.2 et3.3.
Table 3.1 – Ensemble d’informations présentés au sujet
Groupe
D M R
DM RM
Taille des groupes PD PDM PRM PR
Valeur Option
A AD ADM ARM AR
B BD BDM BRM BR
Probabilité d’avoir un certain coût selon le groupe d’appartenance
Frais associés au choix
cH qD qDM qRM qR
cL 1 − qD 1 − qDM 1 − qRM 1 − qR
Valeur associée au fait de ne pas choisir
Ne pas choisir optD optDM optRM optR
Notes : Ai(Bi) = Valeur de l’option A(B) pour les membres du groupe i, i =
{D, DM, RM, R} ; qi= probabilité de payer des frais élevés pour les membres du groupe
i ; opti= Valeur associée au fait de ne pas choisir pour les membres du groupe i
3.2
Plan expérimental
L’expérience est réalisée à l’aide du logiciel z-Tree1. Elle comporte 20 tours. Les partici-pants répètent la décision de vote à chaque tour. L’ensemble des paramètres de décision (valeur des options, coûts associés au choix et probabilités de réalisation des coûts) varient selon le tour. Chaque tour comporte 6 étapes :
Etape 1 (Information 1) : les participants sont informés sur l’ensemble des paramètres de décision présentés au tableau 1. Ils ne connaissent pas leur groupe d’appartenance.
Etape 2 (Prédiction 1) : L’expérimentateur demande aux participants de prédire les choix de 100 personnes se trouvant dans la même situation qu’eux. Les questions Q1 et Q2 sont posées sous le format probabiliste et la question Q3 est posée sous le format
binaire. Les participants répondent soit à la question Q1 soit à la question Q2. Le choix de la question probabiliste (Q1 ou Q2) est aléatoire. L’ordre d’affichage des questions probabiliste (Q1/2) et binaire (Q3) est également aléatoire.
Q1a :“Considérez les valeurs des options et les coûts associés au choix selon le groupe présentés dans le tableau ci-dessus. Il y a au total 100 personnes à raison de 25 par groupe (bleu, vert foncé, vert pâle et jaune)2. Quelle est votre prédiction du choix agrégé
de ces 100 personnes ?”
R1a :
— Je pense que ... personnes sur 100 choisiront l’une des options A ou B. — Je pense que ... personnes sur 100 ne choisiront aucune des deux options.
Q1b : Sur les ... personnes qui choisiront l’une des options, selon vous, combien de personnes choisiront chacune des options A et B ?
R1b :
Réponse absolue
— Je pense que ... personnes choisiront l’option A. — Je pense que ... personnes choisiront l’option B. Réponse relative
— Je pense que ...% des personnes choisiront l’option A. — Je pense que ...% des personnes choisiront l’option B.
L’ordre d’affichage des réponses absolue et relative est randomisé au début de l’expérience pour chaque participant mais reste constant durant l’expérience.
Q2 :“Considérez les valeurs des options et les coûts associés au choix selon le groupe présentés dans le tableau ci-dessus. Il y a au total 100 personnes à raison de 25 par groupe (bleu, vert foncé, vert pâle et jaune). Quelle est votre prédiction du choix agrégé de ces 100 personnes ?”
— Je pense que ... personnes sur 100 choisiront l’option A. — Je pense que ... personnes sur 100 choisiront l’option B.
2. Dans l’expérience, les couleurs bleu, vert foncé, vert pâle et jaune correspondent respectivement aux types D, DM, RM et R. L’utilisation des couleurs permet de rester neutre par rapport aux groupes idéologiques
— Je pense que ... personnes sur 100 ne choisiront aucune des deux options.
Q3a :“Considérez les valeurs des options et les coûts associés au choix selon le groupe présentés dans le tableau ci-dessus. Il y a au total 100 personnes à raison de 25 par groupe (bleu, vert foncé, vert pâle et jaune). Quelle est selon vous l’option qui sera choisie le plus souvent ?”
— Je pense que l’option A sera choisie plus souvent que l’option B. — Je pense que l’option B sera choisie plus souvent que l’option A.
Q3b :Même question que Q3a
— Je pense que l’option A sera choisie plus souvent que l’option B. — Je pense que l’option B sera choisie plus souvent que l’option A. — Je ne sais pas.
(Les participants qui choisissent “Je ne sais pas” sont invités à donner une direction) Si vous n’êtes pas sûr de l’option qui sera choisie le plus souvent, veuillez s’il vous plait indiquer l’option vers laquelle vous penchez le plus.
— Je pense que l’option A sera probablement choisie plus souvent que l’option B. — Je pense que l’option B sera probablement choisie plus souvent que l’option A.
Etape 3 (Information 2) : L’ordinateur choisi aléatoirement le groupe auquel chaque participant appartient. Les participants sont informés de leur groupe d’appartenance. Les participants appartenant aux groupes bleu et jaune n’ont plus d’incertitude sur la valeur des options contrairement aux participants du groupe vert. Pour ces derniers l’incertitude est réduite mais pas complètement résolue. Il ne savent pas s’ils appartiennent au groupe vert foncé ou au groupe vert pâle. Aucun participant ne connait avec certitude le niveau de coût qui se réalisera.
Etape 4 (Prédiction 2) : L’expérimentateur demande aux participants de donner leur propre intention de choix. La même question est posée en utilisant le format binaire (Q4a) et le format binaire avec incertitude (Q4b).
Q4a :“Supposez que vous décidiez de choisir l’une des options. Laquelle des deux options choisirez-vous” ?