Ministère de l'Enseignement Supérieur et de la Recherche Scientifique
UNIVERSITÉ FERHAT ABBAS - SETIF1
FACULTÉ DE TECHNOLOGIE
SE
È
TH
Présentée au Département d’Electronique
Pour l’obtention du diplôme de
DOCTORAT
Domaine : Sciences et Technologie
Filière :
Electronique
Option :Traitement de signal
Par
NOUIOUA Imen
ME
È
TH
Développement et Implémentation d’Algorithmes de
Tatouage Numérique des Données Multimédia
Soutenue le 04/07/2019devant le Jury:
FERHAT-HAMIDA
Abdelhak Professeur Univ. Ferhat Abbas Sétif 1 Président
AMARDJIA Nourredine Professeur Univ. Ferhat Abbas Sétif 1 Directeur de thèse
BOUGHEZEL Saad Professeur Univ. Ferhat Abbas Sétif 1 Examinateur
Acknowledgments
List of figures
List of tables
List of acronyms
General introduction ... 1
Chapter 1: Digital watermarking - An overview ... 5
1.1. introduction ... 6 1.2. History ... 6 1.3. Applications ... 7 1.3.1. Copyright protection ... 7 1.3.2. Broadcast monitoring ... 7 1.3.3. Transaction Tracking ... 7 1.3.4. Content Authentication ... 8 1.3.5. Copy Control ... 9
1.4. properties of watermarking systems ... 9
1.4.1. Imperceptibility (transparency or fidelity) ... 9
1.4.2. Robustness ... 10
1.4.3. Capacity ... 11
1.4.4. Security ... 11
1.5. Basic watermarking scheme ... 12
1.5.1. Watermark embedding system ... 12
1.5.1.1. Embedding domain ... 13
1.5.1.2. Embedding techniques ... 14
1.5.3. Watermark recovery system... 19
1.5.3.1. Blind watermarking ... 20
1.5.3.2. Semi-blind watermarking ... 20
1.5.3.3. Non- blind watermarking ... 20
1.6. Classifications of watermarking techniques ... 20
1.7. Performance evaluation of image and video watermarking algorithms ... 22
1.7.1. Imperceptibility performance ... 22
1.7.2. Robust performance ... 23
1.8. Conclusion ... 23
Chapter 2: Video watermarking
... 242.1. Introduction ... 25
2.2. video concept ... 25
2.2.1. Video structure ... 25
2.2.2. Video proprieties ... 26
2.2.3. Video Coding ... 27
2.3. Specific challenges in video watermarking ... 27
2.3.1. The robustness ... 28
2.3.1.1. image processing attacks ... 28
2.3.1.2. temporal synchronizations attacks ... 28
2.3.1.3. Video compression attacks ... 28
2.3.2. The imperceptibility ... 30
2.3.3. The complexity ... 30
2.4. Video watermarking techniques ... 30
2.4.2.2. Watermark embedding during the compression. ... 32
2.4.2.3. Watermark embedding after the compression. ... 32
2.4.3. Integration of the Temporal Dimension ... 33
2.4.3.1. Video content regarded as a three-dimensional signal. ... 33
2.4.3.2. considering the properties of the Human Visual System (HVS) ... 34
2.5. Conclusion ... 34
Chapter 3: A robust video watermarking technique using spatiotemporal
Just Noticeable Distortion profile
... 353.1. Introduction ... 36
3.2. 2D-Disrect cosines transform ... 36
3.3. Spatiotemporal Just Noticeable Distortion (JND) Profile ... 37
3.3.1. Base Distortion Threshold ... 38
3.3.2. The spatiotemporal CSF Model ... 39
3.3.3. Luminance adaptation ... 40
3.3.4. Contrast masking ... 41
3.4. The proposed watermarking scheme ... 42
3.4.1. Watermark embedding process ... 42
3.4.2. watermark extraction process ... 43
3.5. Experimental results ... 45
3.5.1. The choice of static quantization step size Q ... 45
3.5.2. Imperceptibility tests ... 46
3.5.3. Robustness tests ... 48
3.5.3.1. Image processing attacks ... 48
3.5.3.2. Temporal synchronization attacks ... 50
Chapter 4: A novel blind and robust video watermarking technique in fast
motion frames based on SVD and MR SVD
………534.1. introduction ... 54
4.2. Singular Value Decomposition ... 56
4.3. Multiresolution Singular Value Decomposition (MR SVD) ... 56
4.3.1. 1-D Multiresolution Singular Value Decomposition ... 57
4.3.2. 2-D Multiresolution Singular Value Decomposition ... 58
4.4. Proposed method ... 58
4.4.1. Fast motion frames extraction for embedding (FMFE) ... 60
4.4.2. Watermark preprocessing ... 62
4.4.3. Watermark embedding process ... 62
4.4.4. Watermark extraction process ... 63
4.5. Results and Discussion ... 64
4.5.1. Parameter setting ... 64
4.5.2. Imperceptibility tests ... 65
4.5.3. Robustness tests ... 67
4.5.4. Comparison with some previously reported algorithms ... 72
4.5.5. Complexity of the proposed algorithm ... 74
4.6. Conclusion……… …………75
General conclusion and future work
... 76First of all, I would like to express my sincere gratitude to my advisor
Prof. Nourredine AMARDJIA for the continuous support he gave me
throughout my PhD. studies and related research, for his patience, motivation,
and immense knowledge. His guidance helped me during all the time of my
research and also during the writing of this thesis. I could not have imagined
having a better advisor and mentor for my PhD. studies.
Besides my advisor, I would like to thank Prof. Abdelhak FERHAT
HAMIDA for his support, advices and for accepting to be the president of the
jury.
I also want to express my deep gratitude to Prof. Saad BOUGUZEL and
to Prof. Abdesselam HOCINI for taking the time and effort to read and examine
my thesis.
Last but not the least, I would like to thank my family: my parents, my
husband ,my brothers and sister for supporting me spiritually throughout the
writing of this thesis and my life in general.
Figure 1.1 Example of a unique identification code printed in the background of a text
document………...………...8
Figure 1.2 Left is the original, right is the tampered image [21]………..9
Figure 1.3 Dependencies between basics propreties of digital watermarking...…………...11
Figure 1.4 Basic model of a digital watermarking system………...…..13
Figure 1.5 A generic model of a spread spectrum watermark embedding mechanism……..17
Figure 1.6 Illustration of dither modulation of the scalar host signal x, using a quantiser step size of∆, and d(0) = −∆/4……...………..18
Figure 1.7 Dither Modulation recover system………...………18
Figure 1.8 Classificationsof watermarking techniques………...21
Figure 2.1 Video structure………...………..……26
Figure 2.2 Digital video resoltion and applications[44]……….27
Figure 2.3 Temporal Frame Averaging (TFA): Similar video frames carrying uncorrelated watermarks are averaged to produce unwatermarked content (b) Temporal Frame swapping (TFS): two frames are swapped (c) Temporal Frame dropping (TFD): one frame is dropped……….29
Figure 2.4 Frame by frame video watermarking (a) the same watermark is embedded in each video frame with additive technique, (b) A different watermarks are embedded in each video frame with additive technique………..…31
Figure 2.5 Architecture for uncompressed-domain watermarking algorithms……….32
Figure 2.6 Generic diagram of embedding watermark during the compression………..33
Figure 3.4 Watermark embedding process………...…….44
Figure 3.5 Watermark extraction process……..………44
Figure 3.6 Binary image used as watermark………..46
Figure 3.7 Watermarked video frames from ‘foreman’ video sequences………...46
Figure 3.8 The PSNR and MSSIM of watermarked “foreman” video sequences…………..47
Figure 3.9 Robustness versus JPEG compression……….48
Figure 4.1 Original video frame Foreman image and its 1-level MR-SVD………59
Figure 4.2 Proposed video watermarking technique: (a) embedding process and (b) recover process………59
Figure 4.3 Average motion energy in (a) Foreman, (b) Football and (c) Akiyo videos……...61
Figure 4.4 Video sequences used for testing. (a) Foreman, (b) Akiyo, (c) Football….……….65
Figure 4.5 MSSIM of watermarked video for different quantization step Q, (b) NC of extracted watermark with JPEG compression attack for different quantization step………..65
Figure 4.6 Original and watermarked frames (a) frame 228 of Foreman (b) frame 16 of Akiyo (c) frame 128 of Football………66
Figure 4.7 NC and BER values of the extracted watermarks under the JPEG compression attack………..67
Figure 4.8 Comparison of experimental results between the proposed technique and other schemes under frame averaging attack, frame dropping attack and JPEG compression attack……….74
Table 1.1 Digital watermarking properties versus applications……….…………...12
PSNR, MSSIM, NC and BER for different quantization step Q……….45
Robustness versus adding a noise………...49
Robustness versus Filtering………...50
Robustness versus temporal frame synchronization………...…51
Robustness versus video compression………...………51
Table 4. 1 The PSNR and MSSIM of the watermarked videos………...67
Table 4. 2 Extracted watermark (with NC and BER) under image processing attack……..68
Table 4. 3 Extracted watermark (with NC and BER) under frame dropping attack………69
Table 4. 4 Extracted watermark (with NC and BER) under frame averaging attack……..70
Table 4. 5 Extracted watermark (with NC and BER) under frame swapping attack………70
Table 4. 6 Extracted watermark (with NC and BER) under video compression attack….71 Table 4. 7 Extracted watermark (with NC and BER) under image processing attacks with Stirmark benchmark………...72
AVC Advanced Video Coding
BER Bit Error Rate
CIF Common Intermediate Format
DCT Discrete Cosine Transform
DFT Discrete Fourier Transform
DWT Discrete Wavelet transform
FA Frame Averaging
FD Frame dropping
FR Frame Rate
FMFE Fast Motion Frame Extraction
FS Frame swapping
GIF Graphics Interchange Format
HEVC High Efficiency Video Coding
HVS Human Visual System
JPEG Joint Photographic Experts Group
JND Just Noticeable Distortion
LSB Least Significant Bit
MC Motion Compensation
ME Motion Estimation
MMMV Mean Magnitudes of Motion Vectors
MPEG Moving Picture Experts
MR-SVD Multiresolution Singular Value Decomposition
MSE Mean Square Error
MSSIM Mean Structure Similarity Index Measure
NC Normalized coefficient
NTSC National Television System Committee
PAL PSNR
Phase Alternation Line Peak Signal to Noise Ratio
QCIF Quart de Common Intermediate Format
QIM Quantization Index Modulation
ST-JND Spatiotemporal Just Noticeable Distortion
SVD Singular Value Decomposition
1
General introduction
General context
In the recent years, the fabulous growth of the internet technology and the expansion of powerful computing devices have not only boosted the multimedia electronic commerce up but also incited artists to share and promote their work online. This obviously implied a massive presence on the web of digital multimedia data such as audio, image and video. However, with the spread out and ease of use of powerful multimedia dedicated processing tools these data can be downloaded, easily modified, illicitly appropriated and then largely redistributed or commercialized on the internet. Protecting intellectual property rights of owners has then become a major concern. Consequently, a solution to this problem is provided by digital watermarking, which consist of embedding a message named “watermark” into multimedia elements that can be detected or extracted later without changing the original content of the digital media [1]. However, to develop efficient watermarking schemas, two important properties have to be taken into account [2 ,3 ]: (1 ) Imperceptibility : for an invisible watermarking scheme there must be no discernible difference between the original and the watermarked contents , (2) Robustness : the embedded watermark should be able to survive, to some extent, intentional and unintentional content manipulations.
A secure digital watermarking technique comprises two procedures: an embedding procedure and an extraction procedure. The embedding procedure consists of inserting in the host multimedia content (usually called the cover) a watermark which is a digital signature that holds copyright information exclusively limited to the owner. Subsequently, by means of the given secret keys, the extraction procedure permits solely to the owner or to an authorized recipient of the digital content to retrieve the watermark from the watermarked content [2].
2
Digital watermarking can be done either in the spatial domain or in a transform domain. A spatial domain technique works directly on pixels: the watermark is embedded by usually modifying directly the pixels values such as least significant bits (LSBs) [4], whereas a transform domain technique embeds the watermark by adjusting the transform domain coefficients. Popular transforms that have been frequently used are the Discrete Cosine Transform (DCT) [5], the Discrete Wavelet Transform (DWT) [6], the Discrete Fourier Transform (DFT) [4] and the Singular Value Decomposition (SVD) [7, 8]. Many combinations between these transforms have also been investigated in the literature to accomplish better results [9, 10]. Compared to spatial domain techniques, transform domain ones have shown to achieve better robustness and imperceptibility [9]. Furthermore, the extracting process can be blind, semi-blind or non-blind. In a blind watermarking scheme, neither the original cover nor the embedded watermarks are required for detection but just the secret keys [2, 7, 11]. In a semi-blind watermarking scheme, only some information from the original cover and the secret keys are needed [2, 12]. A non-blind watermarking scheme requires the original cover, the original watermark and the secret keys [2, 9]. This makes the blind watermarking schemes the most challenging ones to develop.
Initially, digital watermarking has been mainly studied for still images but in recent few years a considerable number of techniques dealing with video watermarking have been considered. However, one must say that video watermarking algorithms are more difficult to develop than those operating on images. This is essentially due to the temporal dimension which necessitates some specific requirements [13]: (1) The robustness of the watermark should not only deal with common image processing attacks such as noise adding, JPEG compression, etc., but also with video processing attacks such as MPEG compression and frame synchronization attacks. (2) The imperceptibility in video watermarking is more difficult to achieve due to motion of objects in video sequences, so the temporal dimension should be taken into account in order to avoid distortion between frames. (3) The complexity of the watermarking scheme should be low because of the significant number of frames to be processed in a video signal.
Given that a digital video sequence is considered basically as a collection of sequential images [14], many of the image watermarking techniques that are present in the literature were extended to video [6, 9, 15, 16], as they embed the watermark in all frames of the video sequences without taking the temporal dimension into account. Thus, these algorithms are
3
robust to frame dropping and frame swapping, but in return they are time consuming and also affect the perceptibly of the video quality.
Contributions
To overcome the problem in frame-by-frame embedding techniques, we should not neglect the temporal dimension of a video to make the schema more performing. Therefore, in this thesis we will propose two video watermarking techniques in the uncompressed domain:
A robust video watermarking using spatiotemporal just noticeable distortion: In this work, we will present a robust video watermarking scheme based on Spatiotemporal Just Noticeable Distortion (ST-JND) in the DCT domain. ST-JND, which refers to the maximum distortion threshold that the HVS cannot perceive, is employed in order to obtain a trade-off between watermark robustness and imperceptibility. The watermark sequence is embedded and detected using a quantization index modulation (QIM) algorithm with adaptive (dynamic) step size that is calculated using the ST-JND. By this way, we will consider the temporal dimension of video sequences.
A Novel Blind and Robust Video Watermarking Technique in fast motion frame using SVD in MRSVD domain: In this second work, we will propose a novel and efficient digital video watermarking technique based on the Singular Value Decomposition performed in the Multiresolution Singular Value Decomposition domain. The proposed method chooses only the fast motion frames in each shot of the video to host the watermark. In doing so, the number of frames to be processed is consequently reduced and a better quality of the watermarked video is ensured since the human visual system cannot notice the variations in fast moving regions.
Chapters’ organization
The remaining parts of this thesis are organized as follows:
Chapter 1 provides an overview of digital watermarking by including the historical aspect and also its applications and properties. Moreover, it explains the basic scheme of a watermarking system and gives a summary of the classification of different watermarking schemas.
4
Chapter 2 exhibits a specific overview of video watermarking by giving a fundamental view on video signal. Furthermore, it talks about specific challenges that we have to take into account in video watermarking. It also provides the reader by a global view of the scientific production in video watermarking.
Chapter 3 presents a robust video watermarking using spatiotemporal just noticeable distortion, which is a representation of the spatial and temporal human visual system. By this way, we overcome the problem in frame-by-frame watermarking technique, which ignores the temporal characteristic of a video. We get then a more efficient watermarking scheme.
Chapter 4 exposes a novel video watermarking scheme in fast motion frames using Singular Value Decomposition in the Multi Resolution Singular Value. As in chapter 3, to solve the problem of a frame-by-frame watermarking technique, the proposed method chooses only the fast motion frames in each shot to host the watermark. By doing so, the number of frames to be processed is therefore reduced and a better quality of the watermarked video is ensured since the human visual system cannot notice the variations in fast moving regions.
Chapter 1: Digital watermarking –
an overview
This chapter aims to provide an overview of digital watermarking. Section 1.2 reviews the historical aspect. Section 1.3 discusses several applications in which digital watermarking are already being used. Section 1.4 lists important properties for watermarking. Section 1.5 gives the basic framework of a digital watermarking system. Section 1.6 illustrates different aspects used in watermarking classification. Finally, Section 1.7 describes how a digital watermarking algorithm can be evaluated.
6
1.1. Introduction
With the rapid development of the Internet, digital documents such as pictures, video and music became more available to users with high quality and low cost, which lead to the problem of unauthorized copying and redistribution through the network. Therefore, owners and creators of digital products are searching for reliable solutions to protect the copyright of their digital contents against piracy and malicious manipulation. In the late 1990, digital Watermarking has been established as an effective solution to these concerns by embedding a message named “watermark” into multimedia elements that can be detected or extracted later without changing the original content of digital media [17, 18].
In this chapter, we intend to provide an overview of digital watermarking. First, we will review the historical aspect of digital watermarking, give some of its applications and provide its important properties. We will then explain the basic scheme of a watermarking system. After that, we will give an overview on the classification of the different watermarking techniques and finally we will speak about the performance evaluation of a watermarking algorithm.
1.2. History
Paper watermarks appeared in the art of papermaking about 1282, in Italy.This has played a major role in the evolution of the papermaking industry. The competition between professionals and the quantity of paper processed made it difficult to keep track of the paper source. The introduction of watermarks was a perfect method to eliminate any possibility of confusion. By the eighteenth century, the technique spread in Europe and America and was basically used to indicate the brand or manufacturer of the paper. Watermarks later served as an indication of paper format, quality, strength and also for dating and identification.
Other interests for watermarks, such as bank notes or stamps, show that the technique is a straightforward and quite secure mean for identification since it is still used nowadays. From paper watermarks to digital watermarks, the gap narrowed. The latest term deals with identification of digital documents instead of paper. The first research papers on watermarking of digital images were published by Tanaka et al. in
7
1990 and later by Tirkel et al. in 1993. Around 1995, the interest in the digital watermarking started to increase and the subject began to stimulate the intensification of research activities [1].
1.3. Applications
Watermarking can be used in a wide variety of applications. We can cite copyright protection, broadcast monitoring, transaction tracking, authentication, copy control …etc [19].
1.3.1. Copyright protection
Historically, copyright protection is the first targeted application for digital watermarking. The data owner can embed a watermark representing the copyright information in his data. This watermark can prove the ownership if an illegal copy is found. Muzak’s original interest in watermarking was to distinguish between theirs and similar recordings. The most ambitious form of such an application, which has received much attention in the watermarking literature, is the use of watermarks to actually prove ownership in a court of law. In 1996, Craver et al. pointed out that there is an inherent problem in using watermarks for proof of ownership. Specifically, with many watermarking methods, it is possible for adversaries to make it appear as though all distributed copies of a Work contain their watermarks, even though those marks were never actually embedded [19,20].
1.3.2. Broadcast monitoring
Broadcast monitoring is the process of tracking activities on broadcasting channels in compliance with intellectual rights and other broadcasting laws. By embedding watermarks in commercial advertisements an automated monitoring system can verify whether or not advertisements are broadcasted as contracted [1,19].
1.3.3. Transaction tracking
In transaction tracking or fingerprinting, a unique watermark is embedded into each copy of a work. Typically, the watermark identifies the legal recipient of the
8
copy and can be used to trace the source of illegally redistributed content. One common alternative to watermarking is to use visible marks. For example, highly sensitive business documents, such as business plans, are sometimes printed on backgrounds containing large gray digits (see fig. 1.1), with a different number for each copy. Records are then kept about who has which copy. These marks are often referred to as “watermarks” [1,19].
Figure 1.1 Example of a unique identification code printed in the background of a text document.
1.3.4. Content Authentication
The purpose of content authentication is to verify the integrity of the test data and detect any possible manipulation (i.e. tamper detection) as in fig. 1.2. This is done by embedding fragile or semi fragile watermarks. When the data is corrupted, the watermark will also be changed [21].
9
Figure 1.2 Left is the original image, right is the tampered image [21].
1.3.5. Copy Control
Copy control is essentially subjected to protect digital information from illegal copying. This can be done by using a recording device integrated with a watermark detector which determines whether the data offered to the recorder may be stored or not [22].
1.4. Properties of watermarking systems
We can identify some general properties common to existing watermarking systems.
1.4.1. Imperceptibility (transparency or fidelity)
One of the most important requirements in digital watermarking is the perceptual transparency of the watermark. Generally, the imperceptibility of a watermarking system refers to the perceptual similarity between the original and watermarked versions of the cover (i.e. the watermarks do not create visible artifacts in still images, alter the bit rate of video or introduce audible artifacts in audio signals). For this reason, the most of existing algorithms, in image or video watermarking, take the human visual system HVS into account to perform the embedding of watermarks [1].
According to imperceptivity property, we can find two kind of algorithms in digital watermarking: visible watermarking and invisible watermarking.
10
Visible watermarking: In perceptible or visible watermarking systems, the embedded watermark or logo is visible to human eye without degrading the readability of the digital media as shown in fig. 1.1. In general they are applicable to images and video only. Examples of visible watermarks are logos on TV visibly superimposed on the corner of the video frames [1, 23]. Imperceptible watermarking: In imperceptible watermarking, the
watermarked document and the original one are extremely similar. Generally they are useful for complex applications such as document identification in which watermarked content must appear unchanged compared to the original.
1.4.2. Robustness
Robustness refers to the ability to recover the watermark after transmission of the watermarked host in a noisy channel and a distortion introduced by standard attacks which try to remove the watermark. Depending on the application of a watermarking method, the required robustness must influence the design process. For example, in television broadcast monitoring, the watermarks should be robust to lossy compression, digital-to-analog conversion, lowpass filtering, additive noise and some small amount of horizontal and vertical translation. However, watermarks for this application need not survive rotation, scaling, high-pass filtering, or any of a wide variety of degradations that occur only prior to the embedding of the watermark or after its detection [1].
According to robustness property we can find three classes of digital watermarks dealt in the literature: robust, fragile and semi fragile.
Robust: Robust watermarking is mainly used to sign copyright information of the digital works where the embedded watermark must resist the common edit processing, image processing and lossy compression.
Fragile: Fragile watermarking is largely used to check accuracy authentication as in fig. 1.2, which must be very sensitive to the changes of signal. We can determine whether the data has been tampered or not according to the state of a fragile watermarking [21].
11
Semi fragile: Semi fragile watermarking is capable of tolerating some degree of change to a watermarked image such as the addition of noise from lossy compression. It is primarily used to certificate the integrity and authenticity of image data [24].
1.4.3. Capacity
The capacity or data payload is the maximum number of bits that can be hidden in a given cover Work [1]. Capacity property depends on the purpose of application. Thus different applications may require very different data payloads. For example, in television broadcast, monitoring might need at least 24 bits of information to identify all commercials, whereas in copy protection purposes, a payload of 4 bits is usually sufficient (see table 1.1) [1, 25].
1.4.4. Security
Security property of watermarking schemes may not be always necessary in practice. Cox et al. [1] referred to security as the ability to resist hostile attacks. A hostile attack is any process specifically intended to thwart the watermark’s purpose. The security of a watermark influences the robustness enormously. If a watermark is not secure, it cannot be very robust.
Figure 1.3 Dependencies between basics propreties of digital watermarking. The relation between the basic properties is presented in fig. 1.3. If a watermarking system has better performance in one property, it may be weak in other properties. For example, a very robust watermark can be obtained by large modifications. Consequently, large modifications in the host will be noticeable (i.e.
Capacity
Imperceptibility Robustesse Security
12
low perceptible quality). However, different applications of digital watermarking require different level of such properties. Table 1.1. Presents digital watermarking properties versus applications.
Table 1.1. Digital watermarking properties versus applications.
1.5. Basic watermarking scheme
A basic watermarking scheme is resumed in fig. 1.4. Every watermarking system share the same basic model: a watermark embedding system, transmission over a channel and a watermark recover system (also called watermark extraction system).
1.5.1. Watermark embedding system
The watermark embedding system takes three inputs as shows fig. 1.4: a watermark, a cover data and a secret or public key. This phase can be modeled by the following function:
𝐶𝑊= 𝐸(𝐶, 𝑊, 𝐾) (1.1) Application imperceptibility Robustness capacity Comment
Copy control High High Low Copy control
applications may require just 4 to 8 bits of information [1].
Television broadcast monitoring
High Medium Medium Television broadcast monitoring might require at least 24 bits of information to identify all commercials [1].
Copyright protection
Medium Low High Copyright protection requires from 64 bits [38].
13
where E is the embedding function, C the original cover, W the original watermark and K a secret or public key.
The watermark can be any kind of data: number, text or image. The cover may be in theory any kind of digital document. However, the most appropriate for digital watermarking are images, video and audio. In the embedding process, the watermark is inserted into the content in various methods that we can classify according to the embedding domain (spatial and transform) and the insertion technique (additive and substitution).
1.5.1.1. Embedding domain
1.5.1.1.1. Spatial domainIn the spatial domain, the watermark is embedded by usually modifying directly the pixels values such as the least significant bits (LSBs) method and the patchwork method [2, 4]. These methods are simple and inexpensive in term of computing time. Some spatial domain techniques can be robust to geometric attacks.
1.5.1.1.2. Transform domain
Transform domain techniques embed the watermark by adjusting the transform domain coefficients of the host. Three main steps must be specified: host transformation, watermark embedding, and watermark recovery. Compared to spatial domain techniques, transform domain ones have shown to achieve better robustness and imperceptibility [9].
Figure 1.4 Basic model of a digital watermarking system.
Attacks Original watermark 𝑊 Key 𝐾 Watermarked cover 𝐶𝑤 Watermark embedding system Watermarked attacked cover 𝐶̂𝑤 Noisy Channel l Watermark recover system Key 𝐾 Original cover 𝐶 Original watermark 𝑊 Recovered watermark 𝑊̂
14
Popular transforms that have been frequently used are the Discrete Cosine Transform (DCT), the Discrete Wavelet Transform (DWT) and the Singular Value Decomposition (SVD).
The Discrete Cosine Transform (DCT): The DCT is one of the most popular transforms used in digital image processing and signal processing. Many of the compression techniques are developed in the DCT domain (JPEG, MPEG, MPEG1, and MPEG2) because of its advantage of concentrating the energy of the transformed signal in low frequency range and also its low complexity implementation. For this reasons, many researchers have used the DCT in digital watermarking which provides robustness to JPEG and MPEG compression attacks. Moreover, watermarking in the DCT domain offers the possibility of directly realizing the embedding operator inside a JPEG or MPEG encoder [5, 26, 27].
The Discrete Wavelet Transform (DWT): The DWT has been successfully applied for the new compression standard JPEG-2000. In several recent publications, this technique has been useful to image watermarking because it has excellent spatial localization, and multi-resolution characteristics [6].
The Singular value decomposition (SVD): In recent years, SVD has been proposed as a powerful watermarking technique for copyright protection due to its attractive mathematical features. In chapter 3, we detail the principle of this decomposition [7, 8].
1.5.1.2. Embedding techniques
1.5.1.2.1. Additive watermarkingIn the additive watermarking, the message to be added is not correlated with the host image. The main reason for the popularity of additive watermarking is its simplicity, for which:
𝑌𝑖 = 𝑋𝑖+ 𝛼𝑊𝑖 (1.2)
where 𝑋𝑖 is the i-th component of the original signal, 𝑊𝑖 the i-th sample of the watermark signal, 𝛼 a scaling factor controlling the watermark strength, and 𝑌𝑖 the i-th
15
In the following we will give some examples of additive watermarking schemes. Patchwork [28]:
The patchwork algorithm is one of the earliest watermarking algorithms which appeared in the scientific literature. It is a typical spatial domain, additive algorithm.
The patchwork algorithm can be summarized as follows. The embedding process is achieved by randomly selecting, according to a secret key K, a subset S of image pixels, and then dividing S into two equal subparts 𝑆1 and 𝑆2. Then, pixels belonging to 𝑆1 are increased by a small quantity 𝑑, whereas pixels in𝑆2 are decreased by the
same amount using the following formula:
𝑋𝑤(𝑖, 𝑗) = 𝑋(𝑖, 𝑗) + 𝑑𝑊𝑖(𝑖, 𝑗) (1.3)
where 𝑋(𝑖, 𝑗) is the image pixel at position (𝑖, 𝑗) and 𝑊(𝑖, 𝑗) is a white, pseudo-random signal taking values +1 or -1 with equal probability.
𝑊 = { 1, 𝐼𝑓 𝑋(𝑖, 𝑗) ∈ 𝑆1 −1, 𝐼𝑓 𝑋(𝑖, 𝑗) ∈ 𝑆2 (1.4) by replacing (1.4) in (1.3) we find 𝑋𝑤(𝑖, 𝑗) = { 𝑋(𝑖, 𝑗) + 𝛼, 𝐼𝑓𝑋(𝑖, 𝑗) ∈ 𝑆1 𝑋(𝑖, 𝑗) − 𝛼, 𝐼𝑓𝑋(𝑖, 𝑗) ∈ 𝑆2 (1.5) For a watermarked image, the average difference between pixels in S1 and S2 should approach 2d, conversely for non watermarked image the average difference should be close to zero.
The most significant problem with this scheme is the fragility in the face of synchronization attacks (e.g. geometrical attacks) [29].
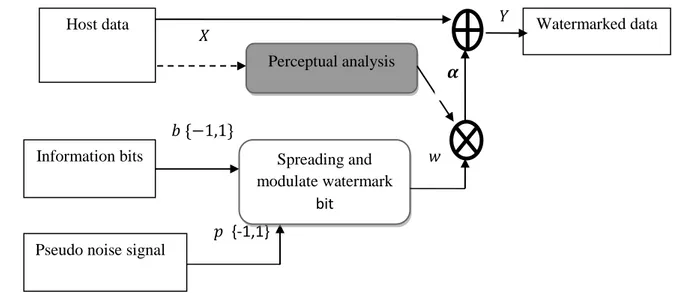
Additive Spread spectrum(SS)[1]:
Cox et al. introduced the concept of Spread Spectrum (SS) watermarking in [30]. The basic idea is to spread one message bit over many samples of the host data. This
16
is done by modulating the host data with a sequence obtained from a pseudo-random generator.
Fig. 1.5 shows a generic model for a spread spectrum watermark embedding system. The SS watermark embedding in the sample domain can be achieved by additive embedding as:
𝑦 𝑖 = 𝑥𝑖 + 𝛼𝑤𝑖 (1.6)
𝑤 𝑖 = 𝑏𝑖∙ 𝑝𝑖 (1.7) where 𝑥 is the vector representation of the M samples of the host data, 𝑏 the vector representation of the spread sequence of size M, 𝛼 a scaling parameter, 𝑝 pseudo-noise sequences with 𝑝𝑖 ∈ {−1,+1}, and 𝑦 the vector representation of the resulting watermarked data of size M.
The embedding can be applied in spatial domain or transform domain using wavelet transform, discrete cosine transform, Fourier transform, or another transform.
In an SS technique, the watermark can be extracted without using the original host, by correlating the watermarked signal 𝑦 with the same pseudo-random sequence 𝑝 used in the embedding. However, the recovery of watermark is more robust if the original host is available at the decoder [31].
The SS watermarking scheme is robust to signal processing operations (such as lossy compression, filtering, etc.) and common geometric transformations (such as cropping, scaling, translation, and rotation). On the other hand, a major drawback of SS watermarking methods is their low embedding capacity due to the spreading of a single bit in larger cover sample in order to achieve higher robustness and security [32].
1.5.1.2.2. Substitute watermarking
Substitute watermarking is based on the substitution of some proprieties of the host in order to embed the watermark. The most popular substitute method is the Quantization Index Modulation (QIM) method [29].
17
Figure 1.5 A generic model of a spread spectrum watermark embedding mechanism.
Quantization index modulation (QIM)[33]:
To overcome the problem in additive spread spectrum watermarking technique Chen and Wornell proposed a new class of embedding methods, termed Quantization Index Modulation (QIM). QIM is accomplished by modulating a signal with the embedded information. Then, the Quantization is performed using the associated quantizer.
One of the QIM techniques presented in [33] is the dither modulation (DM). The basic DM algorithm quantizes the feature vector 𝑥 using a quantizer 𝑞 chosen from a family of quantizes based on the message bit 𝑤 to be embedded. The watermarked featured vector 𝑦 is then obtained by:
𝑦 = 𝑠(𝑥; 𝑤) = 𝑞(𝑥 + 𝑑(𝑤)) − 𝑑(𝑤) (1.8) where q (.) is a quantization function with the step Δ defined as :
𝑞(𝑥) = 𝑟𝑜𝑢𝑛𝑑 (𝑥
∆) ∆ (1.9) d(w) is a dither value corresponding to the bit of w
𝑑(1) = { 𝑑(0) + ∆ 2⁄ , 𝑑(0) < 0 𝑑(0) − ∆ 2⁄ , 𝑑(0) ≥ 0 (1.10) 𝑋 𝑌 Watermarked data Information bits 𝑏 {−1,1} 𝑝 {-1,1} Spreading and modulate watermark bit 𝑤 Perceptual analysis 𝜶 Host data
18
Fig. 1.6 illustrates how a scalar host signal 𝑥 can be dither modulated to embed either 𝑤 = 0 or 𝑤 = 1. We simply choose 𝑑(0) = −∆/4 and 𝑑(1) = +∆/4
Figure 1.6 Illustration of dither modulation of the scalar host signal x, using a quantiser step size of∆, d(0) = −∆/4 , and 𝑑(1) = +∆.
To determine the embedded message bit 𝑊̃ at the decoder, the watermarked signal 𝑦 is requantized using the same family of quantizer as presented in fig. 1.7. Then, the minimum distance decoder is performed as:
𝑊̃ = 𝑎𝑟𝑔𝑚𝑖𝑛𝑤∈{0.1}|𝑦 − 𝑠(𝑦; 𝑤)| (1.11)
QIM achieves provably a high embedding capacity with low -complexity realizations . Furthermore , the extraction procedure in QIM is blind which makes it suitable for robust watermarking.
Figure 1.7 Dither Modulation recover system.
1.5.2. Transmission over a noisy channel
After the embedding of the watermark, the watermarked document CW is
broadcast in a lossy channel (i.e. undergoes a series of manipulations or
∆
+∆/4 −∆/4 𝑊̃ The minimum distance decoder 𝑦 𝑞(. ) 𝑑(0) 𝑑(1) 𝑠(𝑦; 0) 𝑠(𝑦; 1) 𝑞(. )19
modifications). Stefan et al. [2] classified the standard distortions or attacks as: Destruction attacks and Synchronization attacks.
1.5.2.1. Destruction attacks
Destruction attacks are groups of distortions which can be considered as additive noise to the data. These are:
Additive and multiplicative noise (Gaussian, uniform, speckle, mosquito). Filtering (median filtering, morphological filtering).
Lossy compression images: JPEG. Video: H.261, H.263, MPEG-2, MPEG-4. Audio: MPEG-2 audio, MP3, MPEG-4 audio, G.723).
Transcoding: (H.263 → MPEG-2, GIF → JPEG).
1.5.2.2. Synchronization attacks
The synchronization attacks are distortion due to the spatial and temporal geometry modifications of the data like:
Local and global affine transforms: translation, rotation, scaling, shearing. Data reduction: cropping, clipping, histogram modification.
1.5.3. Watermark recovery system
Generally, the recovery scheme takes two inputs, the watermarked attacked cover and the key, and in some cases, an additional one such as the watermark or the original cover. It is modeled by the following function:
𝑊̂ = 𝑅(𝐶̂𝑤, 𝐾, … ) (1.12) where R is the recover function, 𝑊̂ is the recover watermark and 𝐶̂𝑤 is the the
watermarked attacked cover
Depending on the information needed to extract the watermark, digital watermarking systems are categorized in three schemes [2]: blind, semi-blind and non-blind.
20
1.5.3.1. Blind watermarking
This kind of system only requires the watermarked data to extract the watermark. For this reason, it is the most challenging one to develop [2, 7, 11, 35].
1.5.3.2. Semi-blind watermarking
It does not use the original data but only the copy of the watermark and answers whether it is present or not [2, 12, 35].
1.5.3.3. Non- blind watermarking
A non-blind watermarking scheme requires the original cover. It can only be used in those applications where the original Work is available (private watermarking applications). Non-blind or Semi-blind can be used for evidence in court to prove ownership, copy control or fingerprinting (where the owner should still have an unwatermarked version of the Work) [2, 9, 19].
1.6. Classifications of watermarking techniques
From the previous sections, we can make a classification of the watermarking techniques. As show fig. 1.8, it is possible to group them according to different criteria [36]:
Type of documents (audio, image and video); Embedding domain (spatial, spectral);
Embedding technique (additive and substitution);
Information needed for extraction (blind, semi-blind and non-blind); Preservation of the original image (invertible and non-invertible) Robustness of watermark (robust, fragile and semi-fragile).
Each class of watermarking technique has a different purpose, but in this thesis, we will focus on the imperceptible and robust video watermarking in the transform domain.
21
Figure 1.8 Classifications of the watermarking techniques.
Imperceptibility Digital watermarking algorithm Host signal Embedding domain Extraction technique Robustness Embedding technique Image Audio Video Blind Semi-Blind Non-Blind visible Imperceptible Robust Semi fragile Fragile Additive Substitute Spatial Transform
22
1.7. Performance evaluation of image and video
watermarking algorithms
1.7.1. Imperceptibility performance
The imperceptibility of the watermark is estimated by measuring the PSNR (Peak Signal to Noise Ratio) and Mean Structure Similarity Index Measure (MSSIM) [37]. The PSNR is calculated as follows:
𝑃𝑆𝑁𝑅 = 10𝑙𝑜𝑔10(
2562
𝑀𝑆𝐸) (1.13) where the Mean Square Error (MSE) between the host luminance Y and the watermarked luminance Y′ is defined as:
𝑀𝑆𝐸 = 1 𝑀 × 𝑁∑ ∑|𝑌(𝑖, 𝑗) −𝑌′(𝑖, 𝑗)|2 𝑁−1 𝑗=0 𝑀−1 𝑖=0 (1.14) with M and N respectively being the height and width of the video frame.
The MSSIM is defined as follows: 𝑀𝑆𝑆𝐼𝑀(𝑌, 𝑌′) = 1
𝑀∑ 𝑆𝑆𝐼𝑀(𝑌𝐽, 𝑌𝑗′) 𝑀
𝑗=1
(1.15) where YJ and Yj′ are the image contents at the j local window, and M is the number of
local windows of the image.
𝑆𝑆𝐼𝑀(𝑌, 𝑌′) = [𝑙(𝑌, 𝑌′)]𝛼 ⋅ [𝑐(𝑌, 𝑌′)]𝛽 ⋅ 𝑠[𝑌, 𝑌′)]𝛾 (1.16) where l, c and s are the luminance comparison, the contrast comparison and the structure comparison functions respectively. α, β and γ are parameters used to adjust the relative importance of the three components.
Generally ,the imperceptibility of a watermarking algorithm will be desirable when the PSNR is greater than 36 dB and the MSSIM close to 1 [1].
23
1.7.2. Robustness performance
The robustness for any watermarking system is a very important requirement. To compare the similarities between the original watermark W and the extracted watermark Ŵ, we use the Normalized Coefficient (NC) and the Bit Error Rate (BER) [34].
The NC and BER are respectively calculated as: 𝑁𝐶(𝑊, 𝑊̂ ) = ∑ ∑𝑊(𝑖, 𝑗)𝑊̂ (𝑖, 𝑗) |𝑊(𝑖, 𝑗)|2 (1.17) 𝐵𝐸𝑅 = 1 𝑃∑|𝑊̂ (𝑗) − 𝑊(𝑗)| 𝑝 𝑗=1 (1.18) where W, Ŵ and P are respectively the original watermark, the extracted watermark and the size of the watermark. The correlation between W and Wˆ is very high when NC is close to 1
1.8. Conclusion
In this chapter, we provided an overview of digital watermarking including its properties, applications and basic scheme. We have also presented a classification of watermarking techniques according to different criteria such as: host signal, imperceptibility, robustness, extraction technique, embedding domain and embedding technique. Each class of watermarking techniques has a different purpose. However, in this thesis, we will focus on the imperceptible and robust video watermarking techniques in the transform domain. Therefore, in the next chapter, we will present a detailed overview of video watermarking with its specific challenges. Then, we will expose the different watermarking techniques intended to video.
Chapter 2: Video watermarking
In this chapter, we aim to provide an overview of digital video watermarking. Sections 2.2 gives fundamental view on video signal concepts. Section 2.3 lists the main requirements that have to be taken up when designing a new video watermarking system. Section 2.4 gives a classification of existing video watermarking. Finally, conclusions are given in section 2.5.
25
2.1. Introduction
Nowadays, online video has become one of the top activities for users. For example, the YouTube web site contains more than 1.9 billion users and every day, users watch over a billion hours of video. Despite this, research in digital video watermarking is still somewhat an unexplored field of research compared to image watermarking [39, 40] and in which the most of existing image watermarking techniques that are present in the literature were extended to video by embedding the watermark in all frames of the video sequences without regard to the temporal structure of the video.
Therefore, in this chapter we will present a specific overview of video watermarking. First, we will give a fundamental view on video signal. Then, we will talk about specific challenges that have to be taken into account in video watermarking and finally, we will provide the reader by a global view of the scientific production in video watermarking.
2.2. video concept
Before discussing the details of video watermarking challenges and techniques, we provide in the following a fundamental view on video.
2.2.1. Video structure
The term video refers to the visual information captured by a camera, and it is usually applied to a time-varying sequence of pictures. A video signal comprises a sequence of frames (i.e. images) that move rapidly in succession with a fixed frame rate (typical frame rates are 30 and 25 frames per second as seen in the various video formats NTSC, PAL, etc.) [41].
As illustrated in fig.2.1, a video can be broken down into a hierarchy of three units: frames, shots, and scenes. A shot is a sequence of frames recorded in a single-camera operation and a scene is a collection of consecutive shots that have semantic similarity in objects, persons, space and time [42].
26
Figure 2.1 Video structure.
2.2.2. Video proprieties
Digital video can be characterized by four different properties: frame rate, frame resolution, pixel depth and bit rate.
Frame rate (FR): is the number of frames captured per second. All analytic profiles providing the illusion of motion necessitate a minimum of 12 frames per second (fps). If the frame rate is lower than the minimum requirement, objects are not detected and tracked effectively. In an NTSC system the frame rate is 29.97 frames per second. For the PAL system, the frame rate is 25 frames per second [41, 43].
Frame resolution: is the number of “pixels” (picture elements) within each picture frame. The more pixels, the sharper the image. As shown in fig. 2.2, there are different video formats, such as CIF(352x288), QCIF (176x144) ITU-R709 (1920x1080) and etch format have different resolution and different application. For example, the format comparable to laptop requires dimensions of around 352 x 288 pixels (CIF) [44].
Pixel depth: Also known as Color depth, is the number of bits used to represent the color of a single pixel in video frame ,whose unit is bits per pixel (bpp) [45]. Bit rate: is the number of bits that are conveyed or processed per unit of time. The
higher the bit rate, the better the quality of the video. As an example, a YouTube video with a resolution of 854x480 has a bit rate range between 500 and 2000 Kbps [39, 41].
Video scene
Shot 1Frame s
27
Figure 2.2 Digital video resoltion and applications [44].
2.2.3. Video Coding
Video coding is an important requirement for most video appliances such as mobile video, digital TV, internet video streaming and video conferencing. It is the process of compressing and decompressing a raw digital video sequence without retaining as much of the originals quality as possible in order to reduce the quantity of data. Video compression is performed by removing the spatial redundancies (i.e. image compression) and temporal redundancies (using motion compensation MC and motion estimation ME). The general video compression block diagram is shown in fig.2.6. The most common video coding are: MPEG (Moving Pictures Expert Group) and H26x [46, 47].
2.3. Specific challenges in video watermarking
One must say that video watermarking algorithms are more difficult to develop than those operating on images. This is essentially due to the temporal dimension, which necessitates some specific requirements. This section points out three major challenges for digital video watermarking [40, 48].
Pixels (W x H)
MHHD laptop TV computer HDTV QCIF CIF ITU-R601 SVGA ITU-R709
1920x1080
640×480 720x480 352x288 176x144
28
2.3.1. The robustness
In video watermarking techniques, the robustness should not only deal with common image processing attacks such as noise adding, JPEG compression, etc., but also must resist to no-hostile video processing attacks.
2.3.1.1. Image processing attacks
Considering a video as a sequence of images, the attacks applied to images can then be applied to the video sequences. The common image processing attacks are destruction attacks and special synchronization attacks (see chapter 1 section 1.5.2.1) However, such applications do not require robustness to spatial synchronization attacks. For example, in the case of broadcast video, watermarks need not survive rotation, scaling or high-pass filtering [1].
2.3.1.2. Temporal synchronizations attacks
Because contents in the consecutive frames of a video are almost identical, it makes the video sequences susceptible to temporal synchronization attacks. Temporal synchronization is the process of changing the temporal structures in watermarked video frames. These transformations include frame averaging (FA), frame swapping (FS) and frame dropping (FD) as shown in fig 2.3. In FA, the value of each pixel in the attacked video is obtained by averaging the pixel values of correlated video frames. However, in FD some frames from a watermarked video sequence are randomly removed and replaced with correspondent in the original video. On the other hand, FS modifies the order of some frames in a watermarked video and may not be perceptible to the human eye [49].
2.3.1.3. Video compression attacks
In order to reduce the storage needs, content owners often encode the video files with a different lossy compression as MPEG-1, MPEG-2, MPEG-4, H.264/AVC and H.265/HEVC. This compression may degrade the perceptual quality of the video because it removes the spatial and temporal redundancy in a video and as a result, removes the watermark even if this is not the primary goal. In case when the
29
watermark is embed directly in a compressed video, users may transcode video (format conversion e.g. MPEG1→H.264), which may also remove the watermark.
(a)
(b)
(c)
Figure 2.3 (a) Temporal Frame Averaging (TFA): Similar video frames carrying uncorrelated watermarks are averaged to produce unwatermarked content;
(b) Temporal Frame swapping (TFS): two frames are swapped; (c) Temporal Frame dropping (TFD): one frame is dropped.
K K+2 K+1 𝑚𝑒𝑎𝑛 ∑ 𝐹𝐾+𝑖 2 𝑖=0
×
30
2.3.2. The imperceptibility
The imperceptibility in video watermarking is more difficult to achieve than in image watermarking. This is due to motion of objects in video sequences, which makes the visibility of the watermark more intense; thus, a fixed watermark added to a moving object will be more perceptible than if the object is static [50]. Therefore, the temporal dimension of video should be taken into account in order to avoid distortion between frames.
2.3.3. The complexity
In image watermarking, embedding and extraction of a watermark requires just a few seconds. However, such a delay is unrealistic in the context of the video because of the significant number of frames to be processed in a video signal (25 frames/s). For this reason, the complexity of the watermarking algorithm should obviously be as low as possible in order to be implemented in real time applications with low cost. One of the most important way of achieving real-time is “Blind watermarking schemes” (i.e. which do not consider the original data) [48].
2.4. Video watermarking techniques
According to Gwenael et al. [48], video watermarking algorithms proposed in the literature can be classified into three main categories: (1) Frame-by-frame; (2) Integration of the Temporal Dimension; (3) Exploiting the Video Compression Format.
2.4.1. Frame-by-frame
Given that a digital video sequence is considered as a collection of sequential images [14], many of the images watermarking techniques that are present in the literature were extended to video. Frame by frame watermarking techniques use two major embedding strategies: (1) embed the same watermark signal into each frame, or (2) embed different (uncorrelated) watermarks into each video frame. The positive of this method is the simple implantation. But in return, such a scheme often suffers
31
from poor robustness performance against various video processing attacks due to large amounts of data and inherent redundancy between frames (i.e. many frames are visually similar to each other) [51]. For example when the watermark to be embedded is not the same for all frames of a video sequence, the hidden data can be desynchronized with a simple operation such as frame dropping or frame averaging. In addition, these techniques are computationally intensive due to the redundancy of the same process to all frame of video. Fig. 2.4 presents the two frame-by-frame embedding strategies using additive embedding technique.
(a) (b)
Figure 2.4 Frame by frame video watermarking: (a) the same watermark is embedded in each video frame with additive technique; (b) different watermarks
are embedded in each video frame with additive technique.
2.4.2. Exploiting the Video Compression Format
In general, a watermark can be inserted into a video signal, (1) before the compression, (2) during the compression process, or (3) after the compression process [52].
2.4.2.1.
Watermark embedding before the compression
The digital watermark is embed in an uncompressed digital video with the intention that the watermark signals remain present after the watermarked videos are compressed using any compression algorithm. The naive frame-by-frame techniques mentioned previously are examples of uncompressed embedding. The main advantage of this technique is that the video data can be compressed with different standards and
Original video frames
Watermaked video Frames Secret key watermark Embeding strenght Original video Frames Watermaked video frames Secret key Temporel watermark Embeding strenght
32
data rates as presented in fig. 2.5, in condition that the embedded watermark has to be robust to the compression. However, it has high computational cost [53].
Figure 2.5 Architecture for uncompressed-domain watermarking algorithms.
2.4.2.2.
Watermark embedding during the compression
In this technique, compression and watermark embedding are combined. The watermark is embedded during an encoded bit stream generated using encoders conforming to MPEG2, MPEG4, H.264…etc. standards. It should be noted that most of these techniques are employed in the discrete cosine transform (DCT) domain as presented in fig. 2.6. In these algorithms, the watermark embedding is usually performed either (1) on motion vector, (2) on VLC Code words, or (3) by modifying the DCT coefficients (see fig. 2.6) [45-56].
These techniques provide a high level of flexibility and therefore result in robust and imperceptible watermarks. However, they are not scalable to a large number of users because each user requires an individual encoding [40, 53].
2.4.2.3.
Watermark embedding after the compression
In order to reduce the storage needs, content owners often re-encode the video files with a different compression ratio or to a different compression format. Embedding the watermark directly in the compressed video stream often allows
real-Uncompressed watermarked video H264 MPEG4 MPEG2 Watermarked video n°1 Watermarked video n° 2 Watermarked video n° N
33
time processing of the video. However, introducing a single change in the compressed domain may make quality preservation an issue in such methods. In addition, this technique is inherently tied to a video compression standard and may not be robust in video format conversion (transcoding) [48].
Figure 2.6 Generic diagram of embedding watermark during the compression.
2.4.3. Integration of the Temporal Dimension
The major problems of frame-by-frame video watermarking techniques are because the new temporal dimension is not satisfactorily taken into account. Solutions to this problem are proposed in the literature by (1) Video content regarded as a three- dimensional signal or (2) considering the properties of the Human Visual System (HVS).
2.4.3.1. Video content regarded as a three-dimensional signal:
Considering video as three-dimensional signals, many 3D transformations such as the 3D Discreet Fourier transform (DFT) [57], the 3D wavelet transform (3D-DWT) [58], and the 3D Discrete Cosine Transform (3D-DCT) [59] can be exploited for video watermarking by embedding the watermark into mid-frequency region to provide good robustness and high imperceptibility. The advantages of these techniques are the high robustness to temporal modification. However, the required computational cost may have reduced the research effort in this direction [48].
Compressed video Original video VLC Watermark embedding DCT Quantization Motion estimation Q-1 IDCT Motion vector Frame Memory Motion compensation
34
2.4.3.2. Considering the properties of the Human Visual System
(HVS)
HVS is considered on one hand to use the temporal dimension in video watermarking. Many researchers have investigated how to reduce the visual impact of embedding a watermark within still images by considering the properties of the Human Visual System (HVS) such as frequency masking, luminance masking and contrast masking. Such studies are easily exported to video by using frame-by-frame techniques. However, these techniques don’t consider the temporal properties of a video. Motion is the most important characteristic in the video, so we must create new conceptual measures that must be designed on this basis for use in a digital video watermark [48].
2.5. Conclusion
In this chapter, we have presented an overview of digital video watermarking and we can sum up that:
Video watermarking has specific challenges that should to be considered Video watermarking schemes are broadly categorized in three classes:
frame-by-frame, integration of the Temporal Dimension and exploiting the Video Compression Format. Each class has its own advantages and disadvantages. In practical application, different watermark classes are selected according to the different applications and the different requirements.
Frame by frame video watermarking is the most one used because it remains relatively simple. However, it neglects the video temporal dimension.
The majority of video watermarking methods apply in an uncompressed domain because they are generally independent of any video coding. Consequently, they are more flexible than compressed domain algorithms. In the next two chapters, we propose two robust and imperceptible video watermarking schemas in the uncompressed domain, in which we will integrate the temporal dimension of video by considering the temporal characteristic of human visual system (HVS).
Chapter
3:
A
robust
video
watermarking
technique
using
Spatiotemporal
Just
Noticeable
Distortion profile
In this chapter, a robust video watermarking scheme based on spatiotemporal just noticeable distortion (ST-JND is proposed). This chapter is organized in five sections. Section 3.2 and Section 3.3 introduce the preliminaries of our scheme. Section 3.4 gives the details of the proposed video watermarking which includes two parts: the watermark embedding and extracting processes. The experimental results concerning the transparency and robustness against various attacks with comparisons are presented in Section 3.5. Finally, conclusions are given in the section 3.6.

![Figure 1.2 Left is the original image, right is the tampered image [21].](https://thumb-eu.123doks.com/thumbv2/123doknet/3409186.98748/21.892.168.778.125.372/figure-left-original-image-right-tampered-image.webp)





![Figure 2.2 Digital video resoltion and applications [44].](https://thumb-eu.123doks.com/thumbv2/123doknet/3409186.98748/39.892.151.696.134.459/figure-digital-video-resoltion-and-applications.webp)

