A mathematical approach to unsupervised learning in recurrent neural networks
Texte intégral
Figure
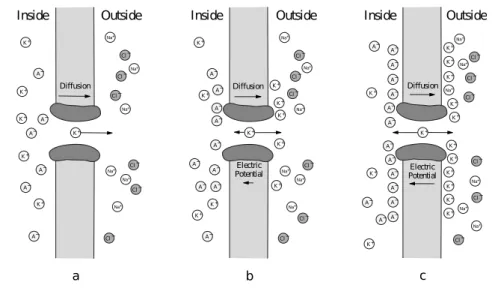
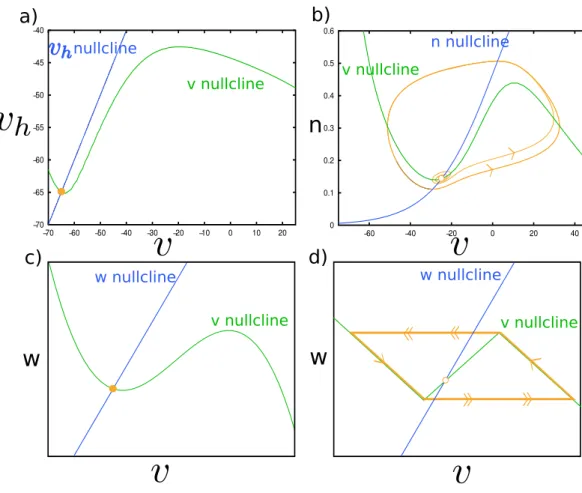
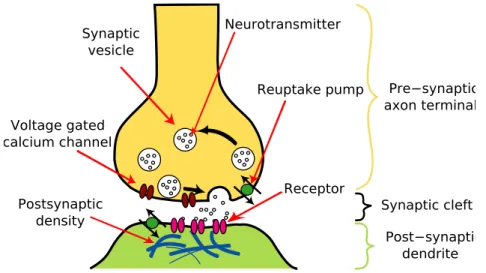
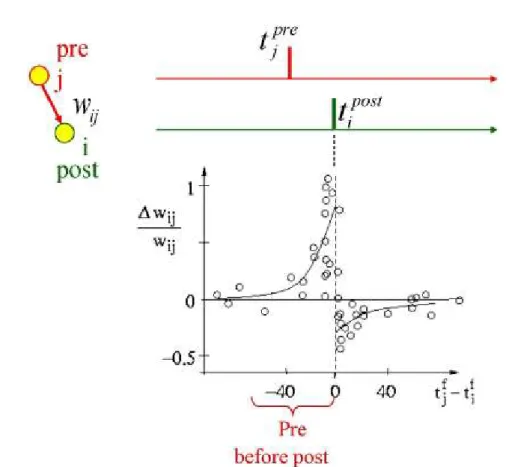
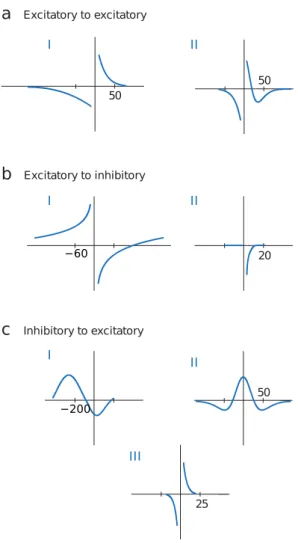
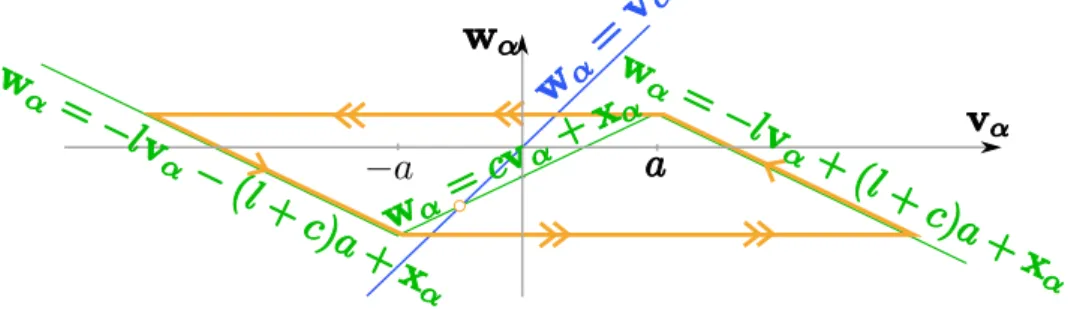
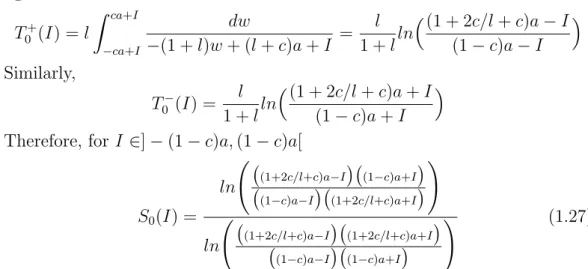
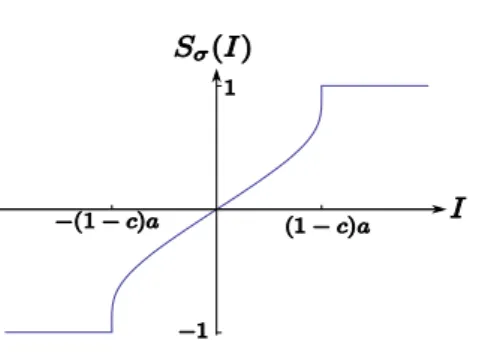
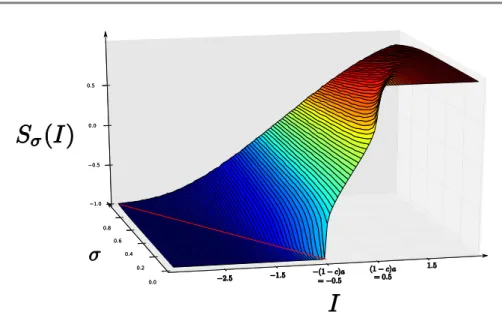
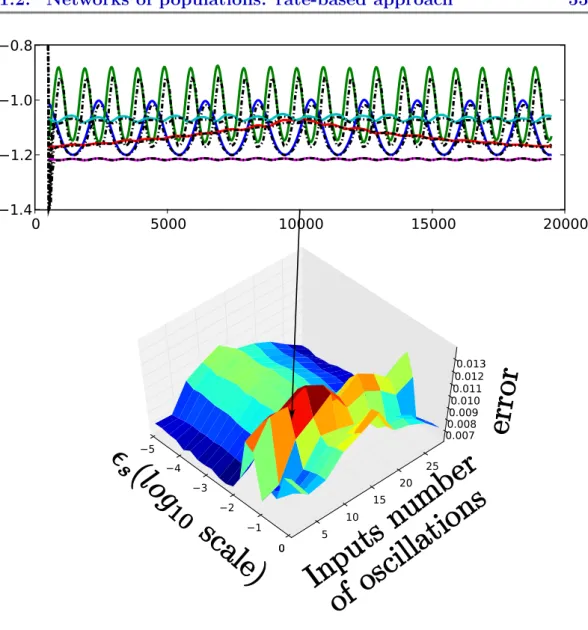
Documents relatifs
The deep neural network with an input layer, a set of hidden layers and an output layer can be used for further considerations.. As standard ReLu activation function is used for all
The percentages of misclassified examples, presented in Tables 7 8, showed that even with a much smaller training dataset, with four or five base models the architecture
[r]
The fact that the students in Gershon’s project are making sense of science – and note that the word itself is used in the essay without much elaboration or critical scrutiny –
An important remark is that achieving a logit equilibrium implies that at a given game stage, radio devices are able to build logit best responses in order to face the other
De la même manière qu’un comportement donné peut être envisagé sous l’angle exclusif du rapport à soi ou également comme ayant un impact sur autrui, un
Within- and across-speaker phoneme discriminability errors (lower is better) on the LibriSpeech dev and test sets for CPC features obtained with the CPC2 model, or the same model
During this 1906 visit, Rinpoche’s father met the 8 th Khachoed Rinpoche, Drupwang Lungtok Tenzin Palzangpo of Khachoedpalri monastery in West Sikkim, and from
