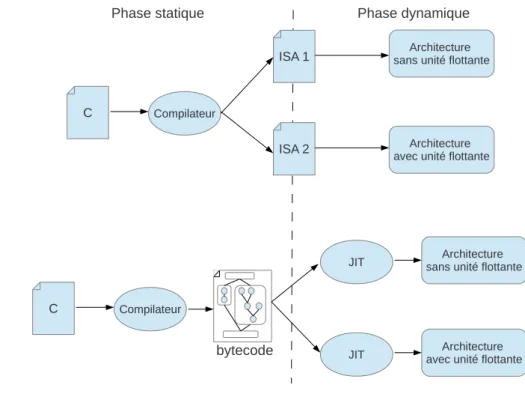
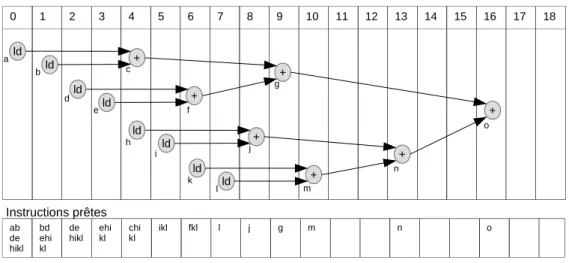
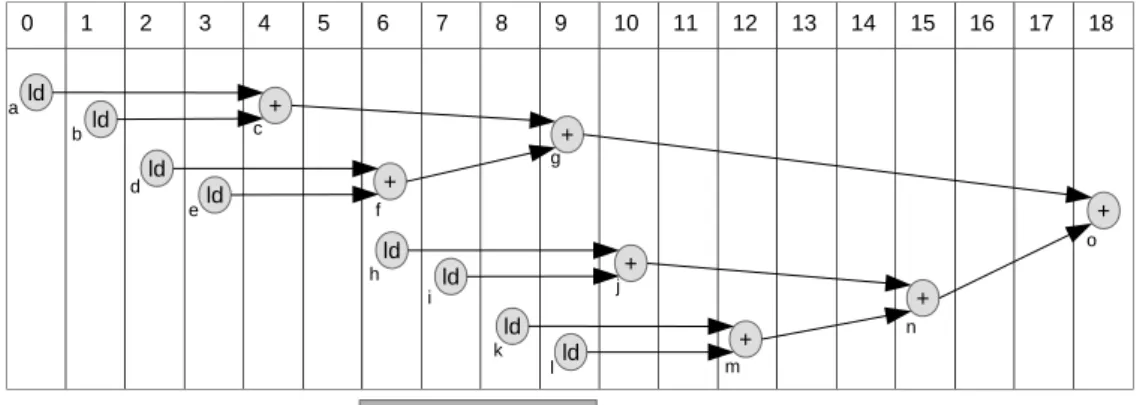
HyBrid-JIT : plateforme de compilation JIT assistée par du matériel spécialisé
Texte intégral
Figure


![Figure 8 : Organisation d’un processeur superscalaire selon l’approche de Tomasulo [19]](https://thumb-eu.123doks.com/thumbv2/123doknet/5551658.132850/15.892.161.743.110.612/figure-organisation-processeur-superscalaire-l-approche-tomasulo.webp)
Outline
Documents relatifs
The performance of each line feeding mode is measured as a periodic total cost that includes preparation, picking for the assembly, transportation and storage
In the in-between states, we are then proving two simulation diagrams at once: each of these states is related both to the Anchor (in dashed lines), and to a corresponding state
Proposition 3 The optimal objective value of the max-abs problem is the smallest B such that the corresponding graph G has a perfect matching This statement will be used in Section 5
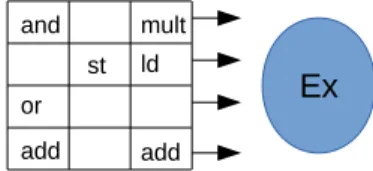
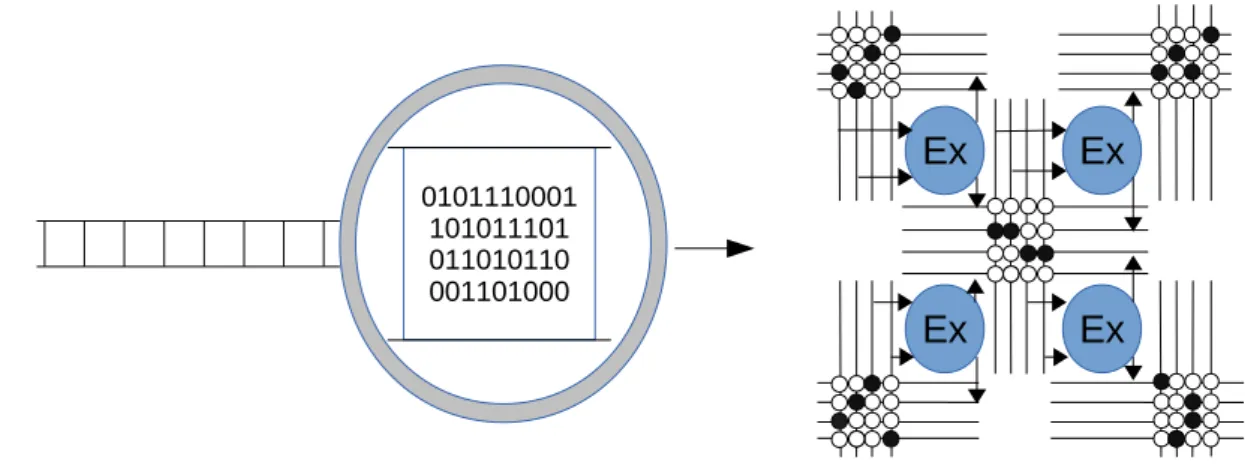
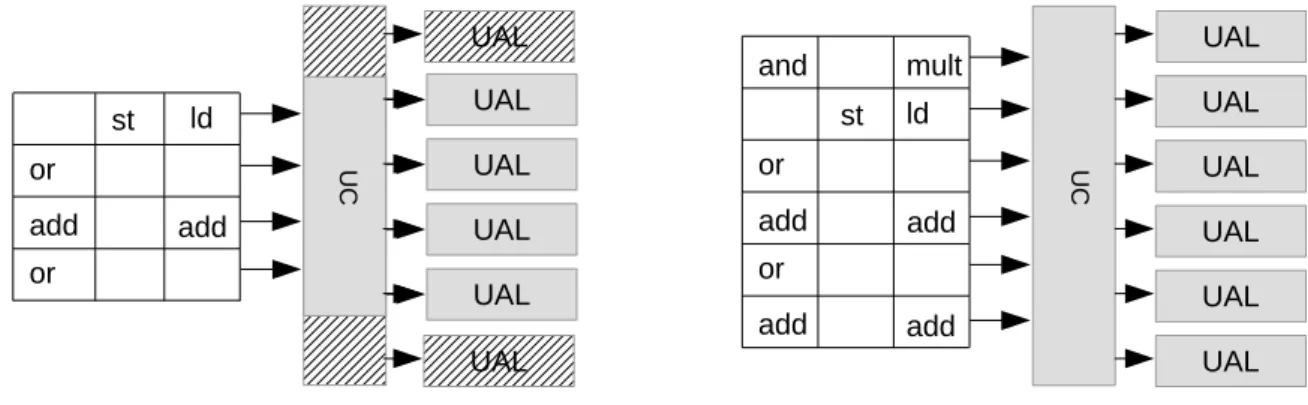
Notre approche repose sur une chaîne de compilation JIT matérielle/logicielle : les optimisations basiques sont résolues de manière lo- gicielle tandis qu’un accélérateur
Pour chaque échantillon, une quantité entre un demi-litre et un litre est prélevé dans des flacons stériles après avoir nettoyé le pis de la chamelle avec une compresse à usage
Finding 1: companies adopting lean manufacturing don’t show an additional contribution to efficiency (unit cost of manufacturing) and throughput time by
The initial coding of our data re flects these deductive categories (activities x dimensions), which were used as a tentative list of activities in which distant collaboration may
On the contrary, when the référence is linked to a point defined in the discourse and which is not concomitant with the time of speaking, the eyegaze is briefly eut off from
