MÉMOIRE PRÉSENTÉ À
L'ÉCOLE DE TECHNOLOGIE SUPÉRIEURE
COMME EXIGENCE PARTIELLE À L'OBTENTION DE LA
MAÎTRISE EN GÉNIE DE LA PRODUCTION AUTOMATISÉE
M.Ing.
PAR
MATHIAS MAHOUSONZOU ADANKON
OPTIMISATION DE RESSOURCES POUR LA SÉLECTION DE MODELE DES SVM
M. Mohamed Cheriet, directeur de mémoire
Département de génie de la production automatisée à l'École de technologie supérieure
M. Richard Lepage, président du jury
Département de génie de la production automatisée à l'École de technologie supérieure
M. Alain Biem, examinateur externe
IBM at Watson Research Center, N.Y, USA
IL A FAIT L'OBJET D'UNE SOUTENANCE DEVANT JURY ET PUBLIC LE 5 AOÛT 2005
Mathias Mahouzonsou Adankon SOMMAIRE
La sélection de modèle, optimisation des hyper-paramètres, est une étape très importante pour garantir une forte performance aux SVM. Cette sélection est souvent réalisée par la minimisation d'un estimé de l'erreur en généralisation basé sur les bornes du "leave-one-out" comme le "radius-margin bound" et sur certaines mesures de performance comme GACV(Generalized Approximate Cross Validation), l'erreur empirique, etc. Ces méthodes de sélection de modèle automatique nécessitent l'inversion de la matrice de Gram-Schmidt ou la résolution d'un problème d'optimisation quadratique supplémentaire, ce qui est très coûteux en temps de calcul et en mémoire lorsque la taille de l'ensemble d'apprentissage devient importante.
Dans ce mémoire, nous proposons une méthode rapide basée sur une approximation du gradient de l'erreur empirique avec une technique d'apprentissage incrémentai; ce qui réduit les ressources requises en tennes de temps de calcul et d'espace mémoire. Avec l'approximation du gradient, nous n'avons pas besoin d'inverser la matrice de Gram-Schmidt avant de calculer le gradient de l'erreur empirique. L'apprentissage incrémentai, quant à lui, permet d'optimiser de façon parallèle les paramètres et les hyper-paramètres de la machine, afin de réduire le temps de calcul. Notre méthode testée sur des bases de données synthétiques et réelles a produit des résultats probants confirmant notre approche. En outre, nous avons noté que le gain de temps s'accroît lorsque la taille de l'ensemble d'apprentissage devient large, ce qui rend notre méthode intéressante dans le cas des applications réelles.
Nous avons aussi développé une nouvelle expression pour les SVM avec la formulation de la marge molle «soft margin» Ll, ce qui permet d'inclure 1 'hyper-paramètre C dans les paramètres du noyau. Ainsi, nous pouvons résoudre le problème de la différentiation de C et dans certains cas réduire le nombre des hyper-paramètres dans la sélection de modèle.
Mathias Mahouzonsou Adankon ABSTRACT
Tuning SVM hyperparameters is an important step for achieving a high-perfmmance learning machine. This is usually done by minimizing an estimate of generalization error based on the bounds of the leave-one-out (loo) as radius-margin bound and on the perfotmance measure as GACV, empirical error, etc. These usual automatic methods used to tune the hyperparameters require an inversion of the Gram-Schmidt matrix or a resolution of an extra quadratic programming problem. In the case of a large dataset these methods require the addition of huge amounts of memory and a long CPU time to the already significant resources used in the SVM training.
In this dissertation, we propose a fast method based on an approximation of the gradient of the empirical error along with incrementai learning, which reduces the resources required both in terms of processing time and of storage space. With the gradient approximation, we do not need to invert the Gram-Schmidt matrix for computing the gradient of the empirical error. The incrementai learning makes it possible to optimize both the parameters of the SVM and the hyperparameters and to drastically save on computing time. We tested our method on many benchmarks which have produced promising results confirming our approach. Furthermore, we notice that the gain time increases when the dataset is large.
We also develop a new expression for SVM with Ll soft-margin formulation that makes it possible to include the hyper-parameter C in the kemel parameters. Then, we can resolve the problem of C differentiation and in certain cases reduce the number of the hyperparameters for model selection.
J'adresse toute ma reconnaissance au PCBF-ACDI, pour le soutien financier, sans lequel ce travail n'aurait pu être réalisé.
Je tiens à remercier mon directeur de recherche, M. Mohamed Cheriet, professeur à l'École de Technologie Supérieure, pour son suivi, pour son soutien et pour ses vifs encouragements tout au long de ce mémoire de maîtrise.
Je remercie également M. Alain Biem, chercheur Senior chez IBM à Watson pour s'être intéressé à mon travail et avoir accepté de faire partie de mon jury. Aussi, ma gratitude à M. Richard Lepage, professeur à l'École de Technologie Supérieure, qui a accepté de présider ce jury.
Un grand merci à tous les membres du Laboratoire d'Imagerie, de la Vision et de l'Intelligence Artificielle pour leur sympathie et leur gentillesse.
Enfin, je dédie ce travail à Pascaline et à toute ma famille pour leur soutien et leur encouragement. Que ces lignes leur témoignent toute ma reconnaissance.
SOMMAIRE ... .i
ABSTRACT ... ii
REMERCIEMENTS ... iii
TABLE DES MATIÈRES ... .iv
LISTE DES TABLEAUX ... vii
LISTE DES FIGURES ... viii
LISTE DES ABRÉVIATIONS ET DES SIGLES ... x
INTRODUCTION ... 1
CHAPITRE 1 CLASSIFIEURS
À NOYAUX ET SVM ... 5
1.1 Introduction ... 5
1.2 Méthodes des noyaux ... 6
1.2.1 Principe et Théorème de Mercer ... 6
1.2.2 Propriétés des noyaux ... 7
1.2.3 Exemples des noyaux ... 8
1.3 Description de certains algorithmes utilisant la méthode des noyaux ... 11
1.3.1 Kemel PCA ... 11
1.3.2 Kemel Fisher discriminant ... l3 1.3.3 L'Analyse discriminante généralisée (GDA) ... 14
1.3.4 Feature Vectors Selection (FVS) ... 17
1.3.5 Relevance Vector Machine (RVM) ... 19
1.4 Principe et Modélisation des SVM ... 21
1.4.1 Risque structurel et dimension VC ... 21
1.4.2 Principe des SVM: maximisation de la marge de séparation ... 24
1.4.3 SVM linéaire et séparable ... 26
1.4.4 SVM linéaire et marge molle (cas non séparable) ... 28
1.4.5 SVM non linéaire: "astuce du noyau" («kernel trick») ... 31
1.5 Algorithmes d'apprentissage des SVM ... 32
1.5.1 Méthode de décomposition ... 32
1.5.2 Algorithme de Joachims : méthode de décomposition améliorée ... 34
1.5.3 Optimisation séquentielle minimale : SMO ... 35
1.6 Classification multi-classe avec les SVM ... 37
1.6.1 Approche un-contre-tous ... 37
1.6.2 Approche un-contre-un ... 38
2.1 Introduction ... 40
2.2 Technique de la validation croisée ... 40
2.2.1 Théorie de la validation croisée ... 40
2.2.2 Validation croisée généralisée approchée (GACV) ... .41
2.3 Bomes de "leave-one-out" pour les SVM ... .42
2.3.1 Nombre de vecteurs de support ... .42
2.3.2 Bome de Jaakkola-Haussler ... .43
2.3.3 Bome de Opper-Winter ... 43
2.3.4 Bome de Joachims ... 44
2.3.5 Borne basée sur l'écartement des vecteurs de support ... 44
2.3.6 Borne "Rayon-Marge" ... 45
2.4 Erreur empirique ... 46
2.5 Conclusion ... , ... 50
CHAPITRE 3 STRATÉGIES D'OPTIMISATION DES RESSOURCES ... 51
3.1 Introduction ... , ... 51
3.2 Approximation du gradient de l'erreur empirique ... 51
3.3 Optimisation des paramètres avec l'apprentissage incrémental.. ... 61
3.3.1 Rappel des techniques d'apprentissage incrémental.. ... 61
3.3.2 Jumelage de l'apprentissage incrémentai avec la sélection de modèle ... 63
3.4 Analyse de l'espace mémoire et de la complexité ... 68
3.4.1 Espace mémoire ... 69
3.4.2 Coût de calcul ... 69
3.5 Conclusion ... 75
CHAPITRE 4 NOUVELLE FORMULATION DU SVM-Ll.. ... 76
4.1 Introduction ... 76
4.2 Description de la nouvelle formulation ... 76
4.3 Équation de l'hyperplan de séparation avec la nouvelle formulation ... 79
4.4 Propriétés de k(x;.xj) = Ck(xi.xj) ... 80
4.5 Avantages de cette nouvelle formulation pour la sélection de modèle ... 83
4.6 Conclusion ... 83
CHAPITRE 5 EXPÉRIMENTATIONS ET DISCUSSIONS ... 85
5.1 Introduction ... 85
5.2 Perfonnance de nos stratégies dans la sélection de modèle ... 85
5.2.1 Données artificielles ... 85
5.2.2 Benchmark UCI ... 86
5.2.3 Base de données MNIST ... 88
5.3 Analyse des propriétés de nos stratégies ... 90
5.3.1 Impact de l'approximation du gradient.. ... 90
5.3.2 Impact de l'apprentissage incrémental.. ... 92
5.5 Conclusion ... 99 CONCLUSION GÉNÉRALE ... . 1 00 ANNEXES:
1. Détails du calcul du coût d'apprentissage ... 102 2. Calcul détaillé du coût d'estimation du gradient approché ... 104 3. Calcul détaillé du coût d'estimation du gradient total ... 106 4. Comparaison des taux d'erreur par problème bidasse entre la nouvelle et
1' ancienne formulation ... 108 BIBLIOGRAPHIE ... ... 110
Page
Tableau I Fonctions de couplage ... 39 Tableau II Description des bases provenant de UCI utilisées ... 86 Tableau III Taux d'erreur en test trouvés par différents algorithmes de
sélection de modèies ... 87 Tableau IV Résultats obtenus avec MNIST en utilisant les différents
Couplages ... 89 Tableau V Résultats obtenus avec la nouvelle formulation sur les cinq bases
de UCI en comparaison avec les résultats testés en section 5.2.2 ... 97 Tableau VI Tableau donnant le nombre d'éléments mal classés en test (bidasse)
Page
Figure 1 Représentation d'un exemple de problème bi-classe ... 5
Figure 2 Résultat de la projection des données de l'exemple de la fig.l.. ... 6
Figure 3 Variation du noyau polynomial. ... 9
Figure 4 Variation du noyau gaussien ... 10
Figure 5 Phénomènes de sous-apprentissage et de sur-apprentissage ... 22
Figure 6 Dimension VC de l'ensemble des fonctions linéaires de R2 ... .23
Figure 7 Représentation de l'hyperplan et des vecteurs de support ... 25
Figure 8 Algorithme de décomposition pour l'apprentissage des SVMs (extraite de [24]) ... 34
Figure 9 Variation de la probabilité estimée en fonction de la sortie du SVM ... 48
Figure 10 Sélection de modèle basée sur l'erreur empirique ... .49
Figure 11 Représentation des données du problème XOR ... 55
Figure 12 Variation de l'erreur empirique E et de l'erreur de test en vali-dation au cours de l'optimisation des paramètres du noyau avec les données synthétiques du problème XOR représentées sur la figure 11-a ... 57
Figure 13 Variation de l'erreur empirique E et de l'erreur de test en vali-dation au cours de l'optimisation des paramètres du noyau avec les données synthétiques du problème XOR représentées sur la figure 11-b .. ... 58
Figure 14 Variation de l'en·eur empirique E et de l'erreur de test en vali-dation au cours de l'optimisation des paramètres du noyau avec les données de la base UCI désignée par Thyroïde ... 60
Figure 15 Variation du taux de bonne classification sur 1 'ensemble de test en fonction de la taille de l'ensemble d'apprentissage ... 64
Figure 16 Algorithme d'apprentissage jumelé avec l'optimisation du noyau ... 65
avec la sélection de modèle ... 66 Figure 18 Comportement de la taille de L1S en fonction de la norme du
gradient. ... 67 Figure 19 Comparaison entre le temps de calcul requis en fonction de la
taille de l'ensemble d'apprentissage (Gradient total vs Gradient
approximé) ... 90 Figure 20 Variation du taux de réduction du temps de calcul en fonction
de la taille de l'ensemble d'apprentissage (Gradient total vs
Gradient approximé) ... 91 Figure 21 Comparaison entre le temps de calcul requis en fonction de la
taille de 1 'ensemble d'apprentissage (Apprentissage
incrémen-tai vs Apprentissage normal) ... 92 Figure 22 Variation du taux de réduction du temps de calcul en fonction
de la taille de l'ensemble d'apprentissage (Apprentissage
incré-mentai vs Apprentissage normal) ... 93 Figure 23 Comparaison entre le temps de calcul requis en fonction de la
taille de l'ensemble d'apprentissage ... 94 Figure 24 Variation du taux de réduction du temps de calcul en fonction
de la taille de l'ensemble d'apprentissage ... 94 Figure 25 Courbes montrant l'impact de la taille initiale de S ... 95
SVM RBF KMOD MLP KPCA KFD LDA GDA FVS RVM
y
vc
hR(a)
1!. N w b ac
Machine à Vecteur de Support Noyau à base radiale
Kemel with Moderate Decreasing Perceptron multi-couche
Analyse en Composantes Principales non linéaire Discriminant de Fisher non linéaire
Analyse discriminante linéaire Analyse discriminante non linéaire
Vecteurs sélectionnés dans l'espace augmenté Relevance vector machine
paramètre du noyau RBF, inverse de la variance Vapnik-Chemovenkis
Dimension VC Risque réel Risque empirique Marge d'un hyperplan
Espace de réels de dimension d
vecteur d'entrée d'indice i
étiquette du vecteur d'entrée d'indice i nombre d'exemples d'apprentissage nombre d'exemples de validation
vecteur orthogonal à l'hyperplan optimal paramètre de biais de l'hyperplan optimal
ensemble des multiplicateurs de lagrange, paramètres du SVM paramètre de compromis dans le SVM
W(a) Nvs sign(x) SMO LOO GACV QP KKT D
R
e
Huer
MNIST PCBF ACDI lagrangien dual du SVM nombre de vecteurs de supportfonction signe, retournant le signe de 1 'argument x
optimisation par minimisation séquentielle Leave-One-Out
Erreur de validation croisée généralisée Quadratique Problem
Karush-Kun-Tuc ker
diamètre de la boule englobant les points d'apprentissage rayon de la boule englobant les points d'apprentissage Erreur empirique associée à l'observation X;
Probabilité a posteriori de l'observation X;
vecteur des hyper-paramètres matrice de Gram-schmidt modifiée University of California, Irvine Modified NIST database
Programme Canadien de Bourses de la Francophonie Agence Canadienne de Développement International
La reconnaissance de formes dont le but consiste à associer une étiquette (une classe) à une donnée qui peut se présenter sous forme d'une image ou d'un signal, est un axe fort important du domaine de l'intelligence artificielle, qui trouve application dans beaucoup de systèmes comme les interfaces visuelles, l'analyse de données, la bioinfom1atique, le multimédia, etc. Plusieurs méthodes ont été développées dans ce domaine, en particulier les réseaux de neurones avec le perceptron multicouche (MLP). Les réseaux de neurones ont fait 1' objet de nombreuses recherches et ont donné des résultats impressionnants comme moyen de prédiction. Et depuis longtemps, les perceptrons multicouches ont été utilisés avec succès pour résoudre de nombreux problèmes de classification. Mais, de plus en plus, avec la diversité des applications de reconnaissance de formes, plusieurs problèmes non linéaires faisant intervenir la classification sont rendus complexes. Ainsi, depuis quelques années, pour contourner la complexité des fonctions de décision construites pour les problèmes non linéaires, les recherches ont donné naissance à de nouvelles méthodes de classification basées sur les noyaux (kemel methods) qui s'avèrent plus robustes et plus simples que d'autres méthodes telles que les couches cachées introduites dans les réseaux de neurones.
La méthode des noyaux est une technique récente en reconnaissance de formes. Elle consiste à projeter les données qui sont initialement non séparables dans un autre espace de dimension plus élevée où elles peuvent le devenir. Les classifieurs utilisant la méthode des noyaux, contrairement aux classifieurs traditionnels, construisent la fonction de décision dans un nouvel espace autre que 1' espace des caractéristiques d'entrée; ce qui permet de réduire la complexité de la fonction de décision tout en gardant une bonne performance du classifieur. Les machines à vecteurs de suppot1, issues des travaux de Vapnik, utilisent cette technique des noyaux qui permet de traiter linéairement dans le nouvel espace les problèmes préalablement non linéaires.
Les machines à vecteurs de support constituent une famille de classifieurs basés sur le principe du risque structurel qui leur confère un fort pouvoir de généralisation. La minimisation du risque structurel permet d'éviter le phénomène de sur-apprentissage des données à la convergence du processus d'apprentissage des machines de classification. Ainsi, le risque structurel permet de garantir une estimation moins biaisée du risque réel. Cependant, le choix des hyper-paramètres (les paramètres du noyaux et la valeur de pénalisation des variables d'écarts) définissant l'architecture d'une SVM affecte de façon significative sa performance. Alors, il faut utiliser une bonne stratégie de sélection pour optimiser les valeurs des hyper-paramètres d'une SVM afin d'espérer une bonne performance.
Plusieurs travaux de sélection de modèle pour les machines à vecteurs de support ont été effectués. En 2001, Chapelle et al. [l] ont proposé pour la première fois une méthode automatique pour sélectionner les hyper-paramètres d'un SVM en se basant sur des bornes de l'erreur en généralisation dérivée de LOO (Leave-one-out). Il s'agit de la dimension VC donnant la borne «rayon-marge» (radius-margin) et celle mesurant l'écartement des vecteurs de support (span bound). Mais ces méthodes développées pour réaliser 1 'ajustement automatique des paramètres nécessitent l'inversion de la matrice de Gram-Schmidt des vecteurs de support et la résolution d'un problème d'optimisation quadratique additionnel, ce qui requiert un temps de calcul important et un espace mémoire non négligeable. En 2003, Kai-Min et al. [4] utilisent le même critère "radius-margin" pour optimiser automatiquement les hyper-paramètres sans inverser la matrice de Gram- Schmidt dans Je calcul du gradient, mais ils ne pouvaient pas se passer de la résolution du problème QP additionnel.
Récemment, un nouveau critère de sélection de modèle pour les SVM appelé l'erreur empirique a été développé par Ayat et al. [5, 6]. Cette méthode minimise l'erreur de généralisation à travers un ensemble de validation. Ce critère est une fonction linéaire
l'apprentissage du SVM. De plus, nous avons la dérivabilité de la fonction coût qui permet de quantifier l'erreur empirique. Cependant, l'apprentissage des machines
à
vecteurs de support demande d'importantes ressources en temps et en stockage au fur et à mesure que la base d'apprentissage devient large. Alors, cette procédure de sélection de modèle automatique, malgré qu'elle soit plus rapide et simple en complexité que les autres critères, reste coûteuse en temps de calcul et en espace mémoire pour de grandes bases de données.Dans le cadre de ce mémoire de maîtrise, nous nous sommes donnés pour objectif 1 'optimisation des ressources au cours de la procédure de sélection de modèle en utilisant l'erreur empirique compte tenue des vertus de ce critère. L'optimisation des ressources vise
à
réduire le temps de calcul du CPU et 1 'espace de stockage mémoire afin de faciliter l'intégration de la sélection de modèle dans des applications réelles avec moins de coût. Ainsi, pour arriver à nos fins, nous proposons :• une approximation du gradient de 1' erreur empirique, ce qui nous permet de déterminer le gradient sans inverser la matrice de Gram-Schmidt, réduisant ainsi la complexité du calcul du gradient.
• une stratégie d'apprentissage incrémentai des SVM, technique qui permet de faire évoluer parallèlement la procédure d'optimisation des paramètres du modèle et l'apprentissage dans une technique de jumelage.
Par ailleurs, nous nous sommes intéressés à l'optimisation du paramètre Cau même titre que les autres hyper-paramètres.
Le chapitre 1 présente le concept et les classifieurs utilisant la technique des noyaux et particulièrement les machines à vecteurs de support.
Le chapitre 2 est consacré à l'état de l'art sur la sélection de modèle pour les machines à vecteurs de support.
Le chapitre 3 décrit les différentes stratégies que nous avons développées pour l'optimisation des ressources dans la sélection de modèle des machines à vecteurs de support.
En chapitre 4, nous présentons une nouvelle formulation du SVM-Ll, ce qui permet d'inclure le paramètre C dans le choix des paramètres du noyau pour la sélection de modèle.
Le chapitre 5 présente les expériences effectuées dans le cadre de ce projet, les résultats obtenus et les analyses relatives.
CLASSIFIEURS À NOYAUX ET
SVM1.1 Introduction
Pour éviter la complexité de la fonction de décision au cours de 1' apprentissage, il est souvent intéressant de projeter les données dans un autre espace de caractéristiques de dimension plus élevée. Dans ce nouvel espace de représentation, les données qui étaient difficilement séparables peuvent le devenir avec une fonction de décision moins complexe. Comme exemple, considérons deux classes de données représentées par deux cercles concentriques de rayon respectif 1 et 0,5, voir figure 5 [7].
0 8.
c ,, ' . .
l
Ofi:
i
.o e. • •
. i
~----'---'--~
...~_
.. _____._._c_~--~--'---'----_j
.: .oe -at. -G: .(1: o J:· o.: co or.: tFigure 1 Représentation d'un exemple de problème bi-classe
Les données sont représentées par des vecteurs en dimension 2, réalisons une projection de ces données en dimension 3 par l'application définie ci-après:
fjJ:
R2
--7R3
(x
1,x
2) 1--t(x~, x~,
..fix
1x
2 )Le résultat de cette transformation appliquée à toutes les données représentées sur la figure 1 est donné en figure 2. Nous pouvons noter que pour séparer les deux classes de données dans ce nouvel espace il suffit d'utiliser une fonction linéaire (un plan) adéquate, ce qui n'était pas possible dans l'espace initial de dimension 2. La précédente technique utilisée pour obtenir une séparation linéaire est l'idée principale de la méthode des noyaux.
"~.
'·
···
...
.....
··
.. ~-'.-;:· .
.. ·
..
·.
··
..
·
Figure 2 Résultat de la projection des données de l'exemple de la figure 1
1.2
Méthodes des noyaux
1.2.1
Principe et Théorème de Mercer
La méthode des noyaux [8, 9] consiste à projeter les données de l'espace Rd dans un autre espace de dimension plus élevée où les données qui étaient non linéairement séparables peuvent le devenir. Désignons par F le nouvel espace, la fonction de projection
fjJ :
Rd
--7F
est une transformation non linéaire, qui est évaluée implicitement. En réalité, on définit une fonctionk :
Rd
XRd
--7R
aveck(x, y)= f/J(x).ÇJ(y)
pour réaliser la projection. La fonction k ainsi définie est appelée noyau et elle représente le produit scalaire dans l'espace F.En considérant l'exemple de la section 1.1, la fonction noyau vaut
Pour définir l'existence d'une fonction noyau, on se sert souvent du théorème de Mercer [10] qui s'énonce comme suit:
Soit une fonction symétrique
k : X
XX
--7R
avecX
CRd ,
il existe une fonctionf/J
telle quek(x, Y)
=
f/J(x).f/J(y)
si et seulement si pour toute fonctionf
élément de l'ensemble des fonctions définies surX,
telle que:fx
f(x)
2dx
existe on aJ
k(x, y)f(x)f(y)dxdy
2
0
xxx
La positivité de l'intégrale permet de définir l'existence du noyau, qui est un produit scalaire dans un espace de Hilbert.
1.2.2
Propriétés des noyaux
Commutativité
Soient x et y deux éléments de l'espace XC
Rd,
la fonction noyau étant symétrique, nous avons la commutativité :Inégalité de Cauchy-Schwartz
Considérons toujours x et y deux éléments de
X
C Rd , nous avons :Par conséquent :
[ k(x, y)
r::;;
k(x, x).k(y, y)
Combinaison de noyaux
Soient k1 et k2 deux noyaux définis de
X
XX, X
C Rd , dansR .
Les fonctionssuivantes sont aussi des noyaux :
1.
k(x,y)=k
1(x,y)+k
2(x,y)
2.
k(x,y)=akJx,y)
avec aER+
3.
k(x,y)=k
1(x,y).k
2(x,y)
4.
k(x, y)= exp(kJx, y))
5.
k(x, y)= p(k
1(x, y))
avecp:
R
~R
une fonction polynomiale à coefficients positifs.1.2.3
Exemples de noyaux
Noyau polynomial
La fonction noyau polynomial de degré n est définie par :
k(x,y)=(ax.y+bY
avec(a,b)E
R
2fortes valeurs de noyau. En figure 3, nous montrons la variation du noyau
k(x, y)= (x. y+
1)
3 en fonction de différents vecteursy
E[0, 20]x[O, 20]
associés' x=
(10 10)
a ' . r; :<1C,;l~:~~p~~:~~;~-}~
IJ 0Figure 3 Variation du noyau polynomial
La dimension du nouvel espace F, lorsqu'on utilise le noyau polynomial de degré n pour projeter les données de 1' espace X vers F, vaut :
d. lill F = - ' - - - -(n+dimX -1)!
11 !(di
rn
X -1)!Noyau gaussien
Le noyau gaussien est dérivé de la fonction RBF. Il dépend de la distance euclidienne entre les deux vecteurs dans l'espace de départ. Il est défini par l'expression ci-après:
k(x,y)=exp(
llx-/11\
avec ŒER
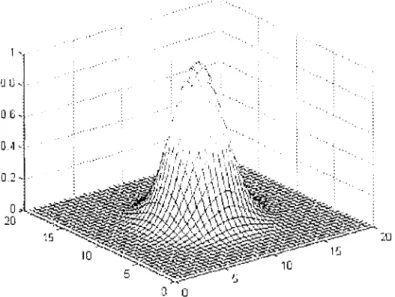
Par cette expression, nous notons que la valeur du noyau, contrairement au noyau polynomial, est indépendante de la direction. La figure 4 montre la variation du noyau gaussien avec
a
=3
en dimension 2, pour différents vecteursy
E[0,
20]
X[0,
20]
associésàx=(lO,lO).
Le noyau gaussien est le plus utilisé dans les applications. La dimension de Fest infinie pour ce noyau. , • ' .· .. ·· ... ·. Uù ' . . ... ··' . . \ 0 G 0 0
Figure 4 Variation du noyau gaussien
Autres noyaux
Nous pouvons aussi citer comme fonctions noyaux :
- le noyau linéaire pour caractériser l'absence de projection dans un autre espace
- le noyau Laplacien
k(x,y)=exp(
llx-yll)
c
- le noyau sigmoïdal qui ne vérifie pas le théorème de Mercer
k(x, y)
=
tanh(ax.y
+
b)
- le noyau inverse multiquadratique
- le noyau KMOD [11]
k(x,
y) =
J
exp(
r: ) -
1]
l
llx-
Yli
+o-
21.3 Description de certains algorithmes utilisant la méthode des noyaux
1.3.1 Kernel PCA
Le KPCA [12, 13] est la généralisation de l'Analyse en Composantes Principales. L'idée de base est la réduction de la dimension de l'espace des caractéristiques en ne retenant que les composantes de forte variance qualifiées de principales.
Soit un ensemble d'observations centrées Xi E
Rd
des vecteurs lignes aveci
=
1, ... ,
f; les composantes principales sont déterminées par les valeurs propres À >0et les vecteurs propres v non nuls de l'équation (1.2).
où C désigne la matrice de covariance des observations :
1
C Tc
=-"'"'
/} L...J
x.x.
l l {, i=l (1.3) Ainsi : (1.4) Et on en déduit alors que tous les vecteurs v avecA
-=t0
sont des éléments du sous-espace générés par les observations Xi .En considérant l'espace augmenté pour le KPCA, la relation 1.4 s'écrit:
1
cÀ
v= Cv=-
L
(q)(x).v)çb(x)
e
i=l(1.5) Nous avons aussi la même conclusion, les vecteurs v avec À -::f:.
0
sont des combinaisonslinéaires des éléments de l'espace augmenté.
c
v= l:ajq)(x)
(1.6)j=l
En multipliant l'équation 1.5 par
çb(xs)
avecs
=
1, ... ,il
et en la combinant avec l'équation 1.6, nous avons :pour tout
s
=
1, ... ,
.e.
Si on désigne par K, la matrice carrée formée par le noyau des observations, les
il
équations obtenues de 1.7 s'écrivent de façon matricielle:(1.8)
Les solutions de l' équation précédente sont les mêmes que celles de l'équation ci-après:
f}.,a =Ka
(1.9)L'analyse en composantes principales dans l'espace augmenté permet ainsi de déterminer les vecteurs v de projection de l'équation 1.6 en résolvant l'équation 1.9. Et pour une observation x donnée, la projection suivant une composante principale
l
dans l'espace F est déterminée par :c
(
vk<I>(x)
=La~
(<I>(x1
).<P(x))=La~
k(x1, x)
(1.10)j=l j=l
1.3.2 Kernel Fisher discriminant
L'idée de base de "Kernel Fisher discriminant" [14, 15] est de résoudre le problème de la discrimination linéaire suivant la théorie de Fisher dans l'espace augmenté F.
En effet le principe de Fisher est de trouver la direction de projection des données pour une meilleure séparabilité des classes. Les critères utilisés sont :
maximiser la distance entre les moyennes des classes minimiser la variance à l'intérieur des classes.
Le but revient alors à déterminer les vecteurs
ro
de projection qui maximisent le coefficient de Rayleigh :"r
où S8 = (m2 -m1)(m2 -m1
Y
et Sw = L L(x; -mk)(x; -mkYk=l.2 i=l
avec mk la moyenne et nk le nombre d'observations dans une classe.
Par similarité, la relation (1.11) devient (1.12) dans l'espace Fen remplaçant les xi par
1
f/J(x;) et co par la combinaison des éléments de F, c'est-à-dire
m
=L
a;f/J(x;).où J(a)
=
dMa a1 Na M=
(m2 -m1)(m2 -m1) 1 et N=
L
Kk(I -Uk)K~ k=l.2 i=lavec mk =_!:__Kk.(1,1, ...
,1Y
et Uk =matrice carré nkxnk d'élémentségauxàllnk.nk
(1.12)
Les vecteurs a qui maximisent J(a) sont les vecteurs propres de la matrice N1 M qui ont de fortes valeurs propres associées.
La projection des données se fait par la relation :
1 1
m.<l>(x)= Ia;(<P(x;).<P(x))
=
Ia;k(xi'x) (1.13)i=l i=l
Le KFD est utilisé pour les problèmes de deux classes. Pour plusieurs classes, on utilise l'analyse discriminante généralisée.
1.3.3
L'Analyse discriminante généralisée (GDA)
a eu beaucoup de succès dans les problèmes de classification. Mais en ce qui concerne les problèmes non linéaires, la LDA n'est pas efficace. Cette limite1 de la LDA fut franchie par l'approche des noyaux, puisque dans le « feature espace »2 les données qui n'étaient pas linéairement séparables peuvent le devenir. Cette nouvelle approche de discrimination a été développée par Baudat et al. dans [16].
L'analyse discriminante linéaire part de la connaissance de la partition en classes des individus d'une population et cherche les combinaisons linéaires des variables décrivant les individus, qui conduisent à la meilleure discrimination entre les classes. L'idée de base est de créer une méthode pour choisir parmi les combinaisons linéaires des variables celle qui maximise l'homogénéité de chaque classe. Une fois cette combinaison choisie, on procède à la projection des données sur les axes qui sont les plus discriminants suivant la variance inter-classe.
Soit un problème de c classes, et désignons par nk le nombre d'observations contenues
c
dans la classe k=l, ... ,c avec /!,
=
l:>zk
le nombre total d'observations.k=l
Dans l'espace augmenté F, avec des données centrées, la matrice de covariance est notée par:
(1.14)
où xiJ désigne le }ème observation de la kème classe.
Notons B la matrice de covariance des moyennes des classes dans l'espace F, représentant 1 'inertie inter-classe.
- 1 /Il
où (,bk = -
L
(,IJ(xkJ) représente la valeur moyenne de la kème classe.nk J=t
(1.15)
La combinaison linéaire discriminante, qui permet de minimiser les variances intra-classe tout en maximisant les variances inter-intra-classes, est constituée des vecteurs propres v solutions de l'équation:
ÀCv
=Bv
( 1.16)Les fortes valeurs propres de l'équation 1.16 sont celles qui maximisent l'équation 1.17 :
(1.17) Puisque les vecteurs propres v sont des combinaisons linéaires des éléments de F, il existe des coefficients
apq (p=l, ...
,c et q=l, ...
,np)
tels quec nP
v=
LLapqtft(xpq)
p=l q=!
Ce qui petmet d'en déduire que l'équation 1.17 est équivalente
à
l'égalité ci-après: A= a1KWKadKKo:
(1.18)
(1.19) où W = (Wk) k=t .... ,c est une matrice bloc diagonale avec Wk une matrice nk x nk dont
tous les termes sont égaux à 11 nk .
Connaissant les valeurs de a vérifiant 1.19, une donnée de test
z
est projetée en utilisant1
'expression suivante :c /If!
v.f/J(z)
=II
apqk(xpq,
z)
(1.20)p=! q=!
Une approche du GDA séquentielle a été développée par Fahed et al.[17] dans le but de contourner les problèmes de calcul matriciel survenus lorsque la taille de l'ensemble d'apprentissage devient très importante.
1.3.4 Feature Vectors Selection (FVS)
La méthode des FVS développée par Baudat et Anouar dans [7] et [18] consiste à sélectionner des vecteurs de l'espace des caractéristiques F qui seront les représentants de tous les autres vecteurs. En réalité, on essaie de créer un sous-espace représentatif de F. Les vecteurs formant ce sous-espace notéS sont sélectionnés à partir d'une approche géométrique et ils permettent de capturer la structure géométtique des données d'apprentissage dans l'espace F.
Soit L le nombre de vecteurs sélectionnés X5
=
{x5l'x52 , ... ,x5J .
L'ensembleS doit avoir la capacité d'être un système générateur des données de F. Ainsi, tout vecteurçb(x;)
=
f/Ji de F peut s'écrire sous la forme d'une combinaison linéaire des vecteurssélectionnés, l'estimé de çt>i peut alors s'écrire:
rA
=
çt>s.a,
(1.21)où
çb
5= (
çb5 " çb52 , .•• ,çb
5L) est la matrice des vecteurs sélectionnés dans F et( 1 2 L )t l ff' · ai = ai , ai , ... ,ai es coe 1c1ents.
On parle d'estimé parce que pour avoir l'égalité, il faut que le nombre de vecteurs formant S soit supérieur ou égal à la dimension de l'ensemble des données dans F; or, la dimension de F est infinie dans certains cas.
L'estimé </Ji se rapproche de </Ji si le ratio ci-après tend vers zéro.
(1.22)
Pour déterminer les coefficients a; qui permettent de minimiser
Ji ,
on pose les dérivées partielles deJi
par rapport à a; égales à 0, ce qui conduit à la relation suivante :K tK -1K.
min
J.
=
1 _ s, ss s,1 kii
(1.23)
kSISI kszs1 kSLSi kSii
kSiS2 kszsz kSLS2 kS2i
avec Kss = et KSi=
ks!SL kS2SL kSLSL ksu
Le but consiste donc à déterminer l'ensembleS des vecteurs sélectionnés qui minimisent (1.23) pourtoutes les observations. Ce qui conduit à:
(1.24)
La condition ex primée par 1 'équation 1.2 4 est réalisée 1 orsque (
~
(K,/
K:.: _, K
''
J
J
est maximal, d'où la relation 1.24 est équivalente à :L'algorithme de sélection des vecteurs de S proposé dans [7, 18] est un processus itératif qui a pour but de former l'ensemble S avec critère de maximisation de la
fonction objective 15
=(I(Ks/Kss-'Ks;JJ·
Il s'agit d'un problème d'optimisation\·E.X k .
. , ll
séquentielle.
Les vecteurs sélectionnés définissent le sous-espace S de F qui représente le mieux la structure de toutes les données d'apprentissage. On procède à la projection de toutes les observations x; dans le sous-espace S par une transformation linéaire :
(1.26)
Et pour les tâches de prédiction, Baudat et al.[7, 18] proposent d'utiliser une fonction de régression linéaire :
- rA pr
Y;
=z;.
+
(1.27)où les paramètres A et
p
sont déterminés en minimisant la somme des canés des écarts résiduels.1.3.5 Relevance Vector Machine (RVM)
Le RVM est un modèle constitué de somme de fonctions noyau comme le SVM, mais basé sur un traitement bayésien [19, 20]. Soit un problème bi-classe où les observations sont {(x1,t1), ... ,(xC>tc)} avec X;ERd et t;E{ü,l}. Le RVM utilise une combinaison linéaire de fonction noyaux définie comme suit :
{
y(x, w)
=
L
w;k(x, X;)+ w0i=l
En utilisant la fonction logistique o-(y) = 1/(1
+
e-.v) avec une distribution de Bernoulli pour la probabilité conditionnelle P(t 1 x) , la vraisemblance sui vante peut s' éciire :( t 1-t
P(t 1 w)
=TI
o-{y(x,, w)}' [ 1- o-{y(x,,w)}] '
r=l
(1.29)
Les poids w coefficients des fonctions noyaux (équation 1.28) sont estimés par une loi gaussienne de moyenne nulle mais avec différentes valeurs de déviation, comme le montre l'équation 1.30:
(
P(w/ a)=
TI
N(wJO,a,-1) J=O(1.30)
L'utilisation de l'approximation basée sur la méthode de Laplace permet de déterminer les valeurs des poids w, qui maximisent la probabilitéP(w/t,a). La procédure itérative d'approximation de Laplace est décrite ci-après en deux points:
1. En fonction des valeurs courantes de
a,
déterminer les valeurs des poids wMP les plus probables par la maximisation de P(wlt,a).Puisque p(wlt,a)ocP(tlw)p(wla), alors il suffit de trouver les poids w qm maximisent :
( 1
log{ P(t 1 w)p(wl a)}= ~]t; log Y;+ (1-t;) log(1-
y;)]
--wAw~~
2
(1.31)Y'".V'".log p(w 1 t, a) 1 wMP =-(<PT B<l> +A) (1.32)
où
B = diag(/3
0,/3
1, •••,flc)
avec/3;
=0"{
y(x;)} [
1-0"{
y(x)}J
et <P=
[ç&(x!),çb(x:), ... ,çb(x()rDe la relation 1.32 et du fait que V' 11• log p( w 1 t, a) 1 w MP
=
0, nous pouvons écrire :(1.33) et
(1.34)
2. En utilisant les valeurs de
I
et wMP, les hyper-paramètresa;
sont mis à jour en utilisant la formule suivante :new Yi
a
i = - -iWMP
(1.35)
1.4
Principe et Modélisation des SVM
1.4.1
Risque structurel et dimension VC
Le but de l'apprentissage est d'estimer l'application
f:
x; 1--7 Y; la mieux adaptée à la classification ou à la régression en tenant compte des observations d'apprentissage. Souvent, on cherche la fonction qui permet de minimiser uniquement l'erreur d'apprentissage appelée le risque empirique.1 ( 1
Mais la minimisation de 1.36 ne garantit pas toujours le risque minimum qui désigne l'erreur en test [21]. Considérons l'exemple illustré en figure 5 où nous avons représenté trois fonctions de décision pour un problème bi-classe.
Le modèle linéaire est en situation de sous-apprentissage tandis que le modèle de haut degré est en situation de sur-apprentissage, car 1' objet x lors de la classification sera mal classé. Un compromis entre ces deux modèles est la fonction de degré intermédiaire représentée.
Pour éviter de choisir les fonctions de décision issues de sur-apprentissage, Vapnik [21, 22] introduit la notion du risque structurel dont la minimisation conjointe avec le risque empirique permet de sélectionner dans 1 'espace des fonctions H, une fonction de décision qui minimise l'erreur en généralisation. Le risque structurel est donc une mesure de la complexité de la fonction affectant sa capacité de généralisation en test.
x
x
x
x
x
x
x
x
0 Objet x 0 0 0 0 0 0 0 0 0 0 0 0Figure 5 Phénomènes de sous-apprentissage et de sur-apprentissage
Ainsi, l'estimation de la fonction
f
ayant un fort pouvoir de généralisation dépend du risque empirique et du risque structurel. Mais, contrairement au risque empirique, lerisque structurel est difficile à quantifier, d'où la nécessité de l'utilisation de la notion de dimension VC (Vapnik-Chervonenkis).
Dans [23, 24], Vapnik et Chervonenkis définissent la dimension VC pour un ensemble de fonctions comme suit: la dimension VC d'un ensemble de fonctions Q(z,a),
a
E A où A désigne 1 'ensemble des paramètres, est le nombre maximal h de vecteursz1, ... ,
z
11 qui peuvent être séparés en deux classes selon toutes les 2" possibilités en
utilisant l'ensemble de fonctions.
Par exemple, considérons l'espace des données XE R2 et l'ensemble des fonctions linéaires de R2, une droite ne peut diviser au plus 3 points selon toutes les possibilités
de bi-classe. Lorsqu'on a 4 points, une droite est incapable de faire la séparation selon toutes les possibilités de classification binaire (voir figure 6).
1 1 1 1 1 1 1 1 1 , ' , ... ' l.o' ,'1 .... , ' ' 1 ' , 1 ,v ... ' , 1 ' , 1 -~ • Zz \ ',, __ 1', 1 1 1
• z1
•
•
Figure 6 : Dimension VC de l'ensemble des fonctions linéaire de R2
:la dimension VC est égale à 3. Pour 4 points, il n'est pas possible de séparer les éléments
z2, z4 par une droite des éléments z1, z
Connaissant la dimension VC, le vrai risque (1 'erreur en généralisation) R peut être mesuré sur l'ensemble d'apprentissage [25]. Ainsi, on a avec la probabilité 1-77
R(a)sR (a)+ .!(hloa2f. +1-loa77)
emp f. o /z o 4 (1.37)
On notera que si la taille de l'ensemble d'apprentissage est très large et la dimension VC est finie, le terme de pénalisation exprimant le risque structurel devient négligeable. Ainsi, nous avons une très bonne généralisation en minimisant uniquement le risque empmque.
1.4.2 Principe des SVM : maximisation de la marge de séparation
Supposons que les données d'apprentissage {(xpy1 ), ••• ,(xc,Yc)} avecx;ERd et
Y; E { -1, 1} sont linéairement séparables par 1 'hyperplan :
w.x+b=O (1.38)
L'hyperplan (w* .x)+ b = 0 avec lw!= 1 qui permet de classifier tous les vecteurs d'apprentissage comme suit :
y={+ 1 Sl
-1 si
(w* .x)+ b :2: ~ (w*.x)+b
s
~ est appelé «~-margin separating hyperplane».Cet hyperplan particulier permet d'énoncer le théorème [25] ci-après:
(1.39)
Si l'ensemble des observations d'apprentissage X appartient au cercle de rayon R, alors h la dimension VC de 1' ensemble des fonctions de « ~ -margin separating hyperplane» est bornée par :
(1.40)
Ainsi lorsque 1.1 est bien choisi, on arrive à avoir h
s
d + 1.On définit alors l'hyperplan optimal comme le « 1.1-margin separating hyperplane» avec
.1
=1/lw*/.
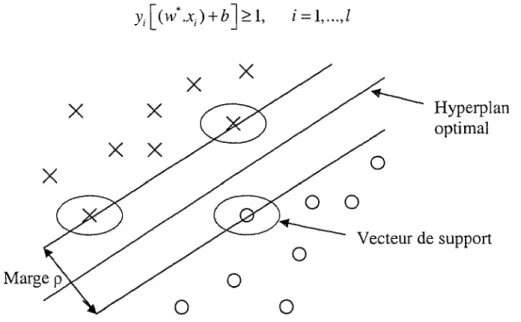
Ainsi pour minimiser la dimension VC, il faut que sa borne supérieure soitminimale. Avec d fixe, dimension de l'espace des observations, il faut choisir l'hyperplan qui maximise la marge 1.1 et nous avons donc une séparation sans etTeur avec la distance de l'observation la plus proche de l'hyperplan maximale (voir figure 16). L'équation 1.39 devient alors:
(1.41)
x
x
x
x
.,._____ Hyperplan optimalx
x
0
Vecteur de support0
0
0
Figure 7 Représentation de l'hyperplan et des vecteurs de support
Maximiser la marge p (la plus petite distance entre les deux classes et l'hyperplan) est équivalent à maximiser la somme des distances par rapport à l'hyperplan.
min w.x. +b p = ---:':'-'-' -::--xi/yi =1 JJwJJ max w.xi +b 2 xi/yi
=-
1 JJwJJ=H
(1.42)Par conséquent, l'hyperplan optimal défini par (co0,b0) est celui qui satisfait la condition
(1.41) et qui minimise G(w)
=
llwll
2
lorsque les données sont linéairement séparables. 2
1.4.3 SVM linéaire et séparable
Pour construire l'hyperplan séparable dans le cas où les données sont linéairement séparables, on résout le problème d'optimisation ci-après:
. . . 1
M1mm1ser G(w,b) = -(w.w)
2 (1.43)
avec les l contraintes d'inégalités: yi[(xi.w)+b]~1, i = 1, ... ,/
Le lagrangien du problème 1.43 est donné par :
1 [
L(w,b,a) =-w.w- :Lai {yi [ (xi.w) +b ]-1} 2 i=l
(1.44)
où ai sont les multiplicateurs de Lagrange, ai ~ 0.
La résolution de ce problème d'optimisation, après avoir introduit les multiplicateurs de Lagrange, est équivalente à déterminer les valeurs de w, de b et de ai qui vérifient :
aL(w,b,a)
=
Oaw
aL(w,b,a) =O
ab
a;{Y;[(xïw)+b]-1}=0 avec i=1, ...
,e
(1.45)
(1.46)
(1.47) (1.48)
( w=
Laiyix,
i=l ( "'av=O ~ i=l'"''
(1.49) (1.50)En considérant 1 'équation 1.4 7, nous pouvons dire que lorsque les données ne sont pas sur la marge, c'est-à-dire
yi[(xi.w)+b]-1>0,
les multiplicateurs de Lagrange correspondants sont nuls. Ainsi, seules les données se trouvant sur la marge, c'est-à-dire celles qui saturent la condition 1.48, ont des multiplicateurs non nuls et par conséquent définissent la valeur de w selon 1.49. On les appelle vecteurs de support.En remplaçant les résultats 1.49 et 1.50 dans l'équation 1.44, on obtient un problème d'optimisation quadratique:
( 1 (
W(a) =
Iai -
1
L apjyiy/xi.x)
i=l ~ i.j=l
Maximiser ( 1.51)
(
sous les contraintes
Lai yi
= 0 etai
~ 0, i = 1, ... , Ci=l
La résolution de ce problème quadratique dont les inconnues sont les ai permet de déterminer l'équation de l'hyperplan optimal:
avec
(
Wo =
I
ai
0yi xi
i=l
où
ai
0sont les solutions de 1.51
et
(1.52)
(1.54)
où x· (1) est un vecteur de support de la classe positive et x· ( -1) de la classe négative.
1.4.4 SVM linéaire et marge molle (cas non séparable)
Dans la section précédente, nous avons supposé que les données sont parfaitement linéairement séparables. Mais si cela n'est pas le cas, il faut relaxer les inégalités décrites par 1.41 en introduisant des variables d'écatt Çi ~ 0. Les contraintes d'optimisation deviennent alors :
i = 1, ... ,f (1.55)
Les variables d'écart permettent de quantifier la mauvaise position des données. Il faut alors aussi minimiser LÇi ou
Iç/·
dans la fonction objective déterminant l'hyperplan, afin de minimiser l'erreur globale. Ainsi, nous avons deux types de problèmes d'optimisation pour le cas non séparable :Norme 1:
Minimiser G(w,b,Ç)
=~(w.w)+CIÇi
2 i=l
(1.56)
avecles2Z contraintesd'inégalités: yi[(xi.w)+b]~l-Çi' Çi~O,
i =
l, ... ,f où C est une valeur positive donnée pour pénaliser les variables d'écarts.Minimiser G(w,b,Ç) = _!_(w.w) + c f Ç/
2 i=l
(1.57)
avec les 2l contraintes d'inégalités : Y; [(x; .w)
+
b] ~ 1-Ç;,
~ ~ 0, i=1, ...,e
où C est une valeur positive donnée pour pénaliser les variables d'écarts.Dans la plupart du temps, la norme 1 est utilisée pour définir le problème des SVM pour la marge molle, c'est-à-dire avec des données qui peuvent se trouver dans la marge ou être mal classées. Dans ce qui suit, nous décrivons en bref la résolution du problème d'optimisation avec la norme 1.
Le Lagrangien du problème 1.56 s'écrit:
où Œ; ~ 0 et À; ~ 0 sont les multiplicateurs de Lagrange.
En appliquant les théorèmes de différentiation, nous avons : dL(w,b,Ç,a,À) =O dw dL(w,b,Ç,a,À) =O
ab
dL(w,b,Ç,a,À)=
0 a~a;{Y;[(x;.w)+b]-l+Ç;}=O avec i=1, ... ,f
Ç;
~ 0 et À; ~ 0 aveci
=
1, ... , f (1.59) (1.60) ( 1.61) (1.62) (1.63) (1.65)À partir des équations 1.59 et 1.60, on retrouve les égalités 1.49 et 1.500 De plus les équations découlant de 1.61 permettent d'écrire:
C-a; -À;= 0 avec i = 1,000,/!
Ainsi, on a: À;= C-a;, \ii= 1,000' e
Or À; ~0
Donc C-a; ~0, \ii=l,ooo,e
D'où:
0:;; a;:;; C, Vi= 1,000'
e
L'équation 1.65 combinée avec 1.66 permet d'écrire: Ç;(a;-C)=O pour
i=1,ooo,e
(1066)
(1.67)
( 1.68)
Et nous pouvons alors en déduire de 1.68 que pour toutes les données de variables d'écart non nulles, a;= C 0 Ainsi, les données qui sont mal classées au-delà de la marge
ou sont dans la marge ont des multiplicateurs
a;
= C 0De même, avec l'équation 1.62, nous avons la même conclusion que celle obtenue dans la section précédente, c'est-à-dire que les données qui sont bien classées en dehors de la marge, Y; [(x; ow)
+
b] -1+
~>
0, ont des multiplicateursa;
= 0 0En somme, les conditions KKT permettent de regrouper les données d'apprentissage en trois ensembles :
1 'ensemble des données bien classées hors de la marge,
a;
= 0 0l'ensemble des données mal classées selon la marge, ~- = C 0
En remplaçant les divers résultats obtenus précédemment dans l'équation 1.58, on obtient le même problème d'optimisation quadratique que dans le cas séparable, mais avec des contraintes différentes :
Maximiser c 1 ( W(a) = " a - - " aa v L.... y (x.x ) 1 ? L.... 1 ) - 1 J 1 J i=l - i,j=l c
Sous les contraintes
I
a;
Y;=
0 et 0 ~a; ~ C,i
=
1, ... ,!!.i=l
(1.69)
Et la résolution de ce problème fournit les coefficients
a;
0pour définir le paramètre
(
w0
=
Ia;
0Y;X; l'équation de l'hyperplan.i=l
1.4.5
SVM non linéaire: "astuce du noyau" («kernel trick»)
Généralement, en reconnaissance de formes, nous n'avons pas souvent des problèmes linéaires. Ainsi, pour étendre l'utilisation des machines à vecteurs de support, on a introduit la technique de l'espace augmenté. Cette technique repose sur l'application de la méthode des noyaux appelée "astuce du noyau".
Puisque dans les formules de construction des SVM, seul intervient le produit scalaire de deux points, on peut donc utiliser toute fonction noyau k(x, y) respectant les conditions de Mercer afin de garantir la semi-positivité de la matrice de la fonction objective. Ainsi le problème quadratique à résoudre devient :
Maximiser (1.70)
(
Et pour toute observation
z
de test, nous avons la fonction de décision qui s'écrit:g(x)
~
sign (t.
y,a,k(x,, z)+
bJ
(1.71) 1.5 Algorithmes d'apprentissage des SVM1.5.1 Méthode de décomposition
L'apprentissage d'une machine à vecteurs de support revient à résoudre un problème d'optimisation quadratique. Mais lorsque la taille de l'ensemble d'apprentissage devient très importante, les algorithmes classiques de résolution de problème QP sont inefficaces. Nous avons alors besoin de techniques spécifiques. Ainsi, la méthode de décomposition proposée par Osuna et al.[26] permet de faire l'apprentissage des SVMs lorsque la taille de l'ensemble d'apprentissage est grande.
De façon matricielle, le problème QP se pose comme suit:
sous les contraintes : max A W(A) = Arl-.!_Ar DA
2
ATY=O
A-Cl:::;O -A:::;o (1.72)Les conditions de KKT d'optimalité démontrées dans la section précédente permettent d'écrire les conditions nécessaires et suffisantes:
O<a;<C si yJ(x;)=1 a;=C si yJ(x;):::; 1 (1.73) a;=O si yJ(x;) ~ 1 avec ( f(x;) =
L
y jajk(x;, x)+ b (1.74) j=lDonc, si les valeurs des composantes de A satisfont aux conditions 1.73, nous avons résolu le problème 1. 72.
La stratégie de décomposition consiste à partitionner l'ensemble d'apprentissage en deux sous-ensembles B et N, où B est appelé l'ensemble actif. Ainsi, on décompose aussi le vecteur A en deux vecteurs AB et AN . On forme alors un sous problème QP dont la variable est le vecteur AB et on garde fixe le vecteur AN .
max Au
sous les contraintes :
T T
ABYB
+
ANYN = 0 AB -c1:::;o-A
8:s;O
(1.75)
Puisque les termes A~ 1 et A~DNNAN sont constants par rapport au sous-problème et que la fonction est symétrique, le problème 1.75 peut encore s'écrire :
La technique pour optimiser le problème 1.72 est d'optimiser itérativement les sous-problèmes 1. 76 et à chaque itération de remplacer un élément de l'ensemble B par un élément deN qui viole l'une des conditions de KKT (1.73). La figure suivante montre l'algorithme présenté dans [26].
1. Choisir arbitrairement les éléments de la base d'apprentissage pour former l'ensemble B et le reste pour former 1 'ensemble N.
2. Résoudre le sous problème défini par les variables de AB
3. Tant qu'il existe jE N tel que :
*
aj=O et yjf(x)<l*
aj=C et yjf(xj)>l*
O<aj<C et yjf(x)i=lRemplacer n'importe quel élément i E B
par 1 'élément
j
trouvé et résoudre le nouveau sous-problème.Figure 8 Algorithme de décomposition pour l'apprentissage des SVMs (extraite de [26])
1.5.2 Algorithme de Joachims : méthode de décomposition améliorée
La méthode de décomposition proposée par Osuna et a1.[26] permet de résoudre le problème de large base de données. L'algorithme converge après un nombre fini d'itérations, mais il requiert un temps CPU important. Et c'est pour réduire ce temps de calcul que Joachims[27] a développé SVM1ight qui est une technique basée sur la
L'algorithme de Joachims diffère de celui d'Osuna et al. par la sélection des q éléments de l'ensemble actif B. Pour accélérer la convergence, Joachims propose d'utiliser une stratégie basée sur la méthode de Zoutendijk[28]. L'idée est de trouver la direction admissible d pour la descente de gradient et de former à partir de cette direction l'ensemble B. La détermination de d revient à résoudre un autre problème d'optimisation avec des contraintes :
min V(d)
=
g(dnl dd
/d=O
di ;::: 0 pour
i :
ai=
0sous les contraintes : di :::; 0 pour
i :
ai=
C (1.77) -1:::; d:::; 1i{
di : di i= 0}i
=
qLa résolution de ce précédent problème d'optimisation permet de trouver le vecteur d,
avec q composantes non nulles, qui permet de garantir la convergence rapide du problème 1.72 à partir de la résolution du sous-problème 1.76. Les indices des q
composantes non nulles sont ceux utilisés pour former l'ensemble actif B.
1.5.3
Optimisation séquentielle minimale : SMO
Le SMO développé par Platt[29] est une variante de la technique de décomposition où l'ensemble actif est formé de deux éléments. Ainsi, à chaque itération on résout un problème d'optimisation à deux variables qui se fait de façon algébrique: deux multiplicateurs o.i sont sélectionnés à partir des heuristiques et on procède à leurs mises à jour en fixant les autres valeurs de
o..
Désignons par a1 et a2 les deux multiplicateurs de Lagrange à mettre à jour. En
considérant les contraintes linéaires du problème, on détermine des bornes suivantes pour 1 'élément a2 à déterminer :
(1.78) Avec
Les homes Let H ainsi déterminées permettent de réévaluer la valeur de a2 après avoir
appliqué la formule suivante, découlant de la maximisation de la fonction W( a1 ,a2) :
(1.79)
Et la réévaluation de la valeur de a2 se fait en utilisant l'équation 1.80
""''
{
~.
si
a~e\V;:::H
a2 = a2
si
L<a~ew< H
(1.80)L
si
a;ew:::::; L
Après avoir déterminé a2, le calcul de a1 est effectué en utilisant la contrainte linéaire
Le SMO, comme proposé par Platt dans [29], est une procédure très lente. Et ceci dépend surtout des heuristiques utilisées pour sélectionner les deux multiplicateurs à mettre à jour. Dans [30], Keerthi et al ont proposé une technique de sélection des deux multiplicateurs qui permet une rapide convergence de l'algorithme.
1.6
Classitïcation multi-classe avec les SVM
Les machines à vecteurs de support traitent habituellement des problèmes bi-classes. Cependant, il existe des techniques de combinaison pour résoudre des problèmes classes. Deux types d'approches sont souvent utilisés pour réaliser des classifieurs multi-classes à base des SVMs :
1' approche un-contre-un 1' approche un-contre-tous
1.6.1
Approche un-contre-tous
L'idée est de construire autant de SVMs que de classes où chaque SVM permet de séparer une classe de toutes les autres. Ainsi, pour un problème à c classes, il faut entraîner c SVMs qui seront ensuite couplés pour prendre des décisions lors du test. Le couplage naïf qui consiste à attribuer à une observation la classe dont la sortie du SVM est positive, n'est pas satisfaisant. Car pour certaines observations ambiguës, plusieurs sorties peuvent être positives.
Pour réaliser un bon couplage, il est recommandé de nonnaliser la sortie des SVMs ou de les convertir en mesure de probabilités. Ainsi, un exemple est associé à la classe du SVM ayant la plus forte valeur de sortie normalisée ou de probabilité.
1.6.2 Approche un-contre-un
Cette démarche requiert la construction de c( c -1) 1 2 SVMs pour un problème de c
classes. Chaque SVM permet de traiter un problème bi-classe formé des données d'un couple (m;,
m)
de classes. En test, chaque sortie des SVM convertie en probabilité, foumit pour un exemple x donné :(1.82)
La règle de décision est alors donnée par:
arg max
P;
!:;";i:;";c
(1.83) avec
(1.84)
où cr désigne la fonction de couplage.
Plusieurs types de couplage sont rapportés dans la littérature {Hastie, 1998 #17;Wu, 2004 #16;Moreira, 1998 #1;Hsu, 2002 #2;Wu, 2004 #16}, mais il demeure toujours un vif débat sur le modèle de couplage le plus efficace. Dans [33], les fonctions de couplage du tableau I sont rapportées, avec différents commentaires.
Cette dernière approche est le plus souvent utilisée à cause des problèmes de ressources que requiert l'approche "un-contre-tous". Car pour l'apprentissage des SVM dans 1' approche "un-contre-tous", il faut utiliser toute la base de données de toutes les classes.
Tableau 1 Fonctions de couplage Fonctions Expressions
a(x)~{lo
si
x~O.S PW1 sinon PW2 a(x) =x 1 a(x) = PW3 1 +exp[ -12(x-0.5)]a(x)~{lx
si
x~O.S PW4 sinon{x
si
x;::::o.s PW5 a(x) = 0 sinon 1. 7 ConclusionDans ce chapitre, nous avons présenté la méthode des noyaux et la description sommaire de certains algorithmes de classification utilisant cette méthode. Enfin, nous avons exposé les machines à vecteurs de support, depuis leur genèse basée sur la minimisation du risque structurel quantifié par la dimension VC.
Le chapitre suivant, nous présentera les diverses techniques développées pour améliorer la performance des SVM, en faisant une bonne sélection de modèle.





![Figure 8 Algorithme de décomposition pour l'apprentissage des SVMs (extraite de [26])](https://thumb-eu.123doks.com/thumbv2/123doknet/7494320.224696/47.880.226.701.308.647/figure-algorithme-décomposition-apprentissage-svms-extraite.webp)
![Tableau 1 Fonctions de couplage Fonctions Expressions a(x)~{lo si x~O.S PW1 sinon PW2 a(x) =x a(x) = 1 PW3 1 +exp[ -12(x-0.5)] a(x)~{lx si x~O.S PW4 sinon {x si x;::::o.s PW5 a(x) = 0 sinon 1](https://thumb-eu.123doks.com/thumbv2/123doknet/7494320.224696/52.879.274.713.273.648/tableau-fonctions-couplage-fonctions-expressions-pw-pw-pw.webp)

