Small-World Networks: Is there a mismatch between theory and practice?
Texte intégral
Figure

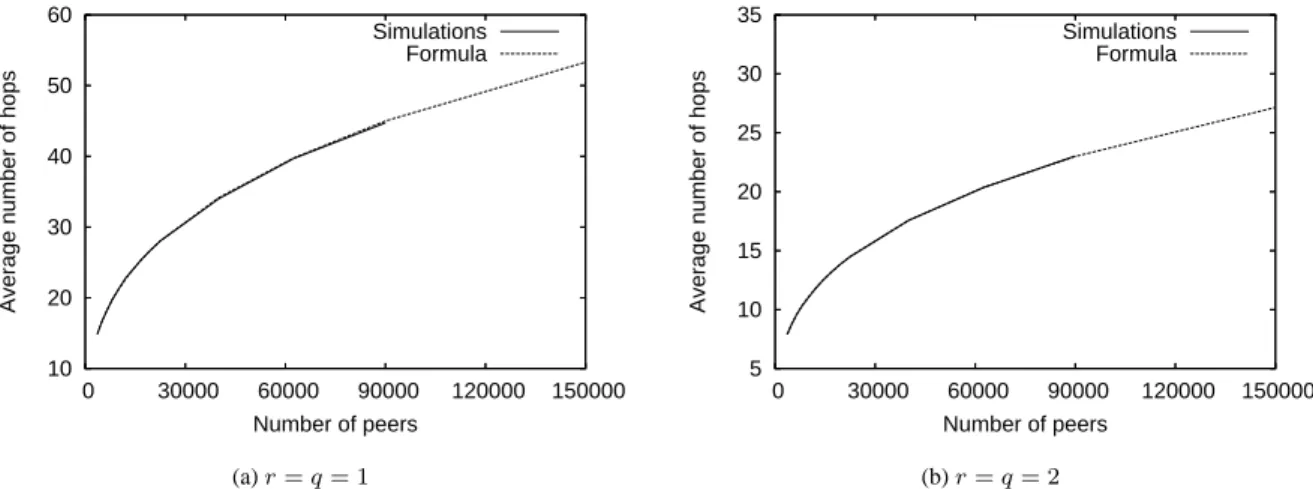
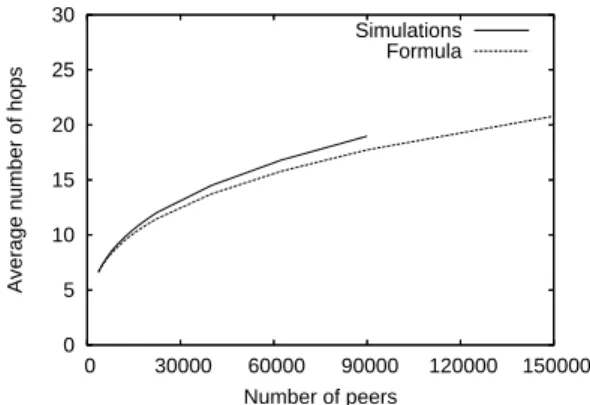
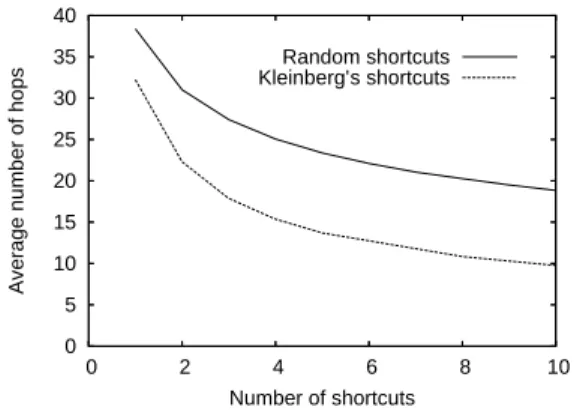

Documents relatifs
Two important properties that should be targeted as much as possible when designing content dispatching algorithm are: (i) the peers should be equally popular with the overall
This paper presents different strategies for constructing peer-to-peer networks for a music recommender application based on
The tree overlay is maintained as balanced as possible (i.e. its diameter is minimized) and each peer has an upper limit on the number of overlay neighbors it may have.. The
Such malicious behaviors have led to the proposition of malicious-resilient overlay systems (e.g., [2, 3, 4]). In all these systems, it is assumed that at any time, and anywhere in
In fact, GR is a localized routing scheme since packet forwarding decision is achieved by using only information about the position of nodes in the vicinity and the position of
The insights gained by the large-scale analysis of health- related data can have an enormous impact in public health and medical research, but access to such personal and sensitive
Repair operation. Figure 3 shows the pseudo-code of the maintenance phase. Periodically each node contacts all the nodes in all its views for checking if they are still alive. If a
The influence of Ni addition on hydrogenating properties of TiMg based ternary alloys prepared by high energy ball milling, oral presentation, 12-14 th , September 2016, University
