Knowledge Discovery from Symbolic Data and the SODAS Software
Texte intégral
Figure

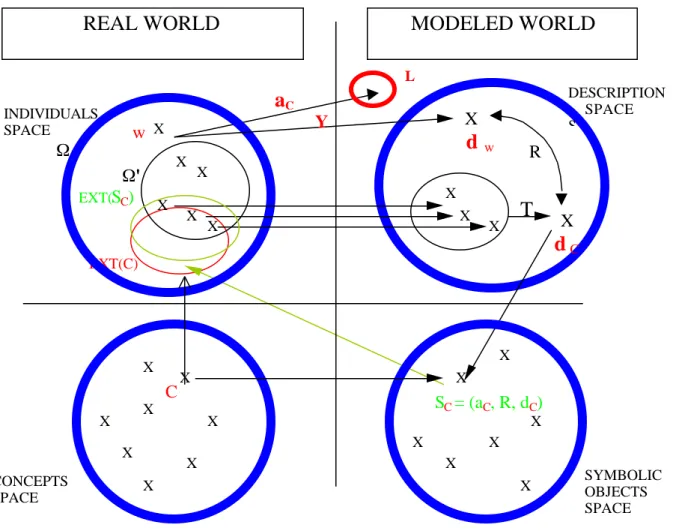
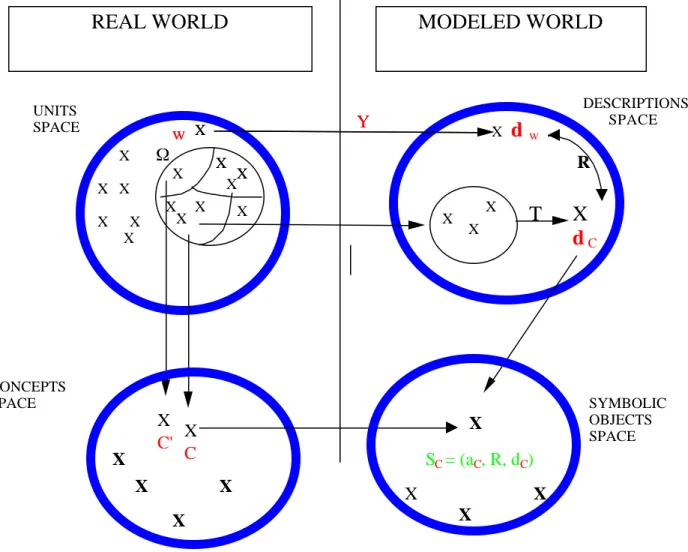
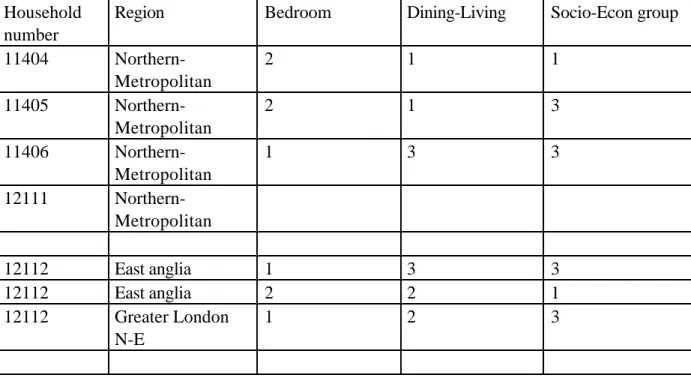
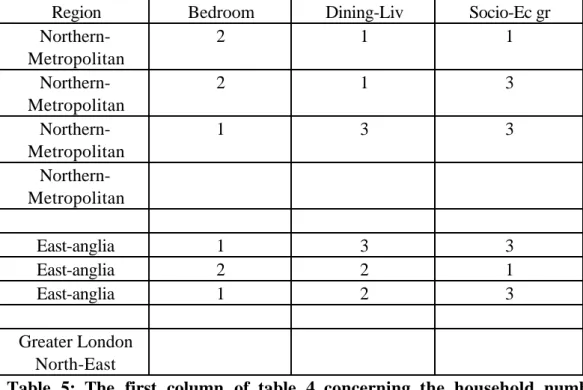
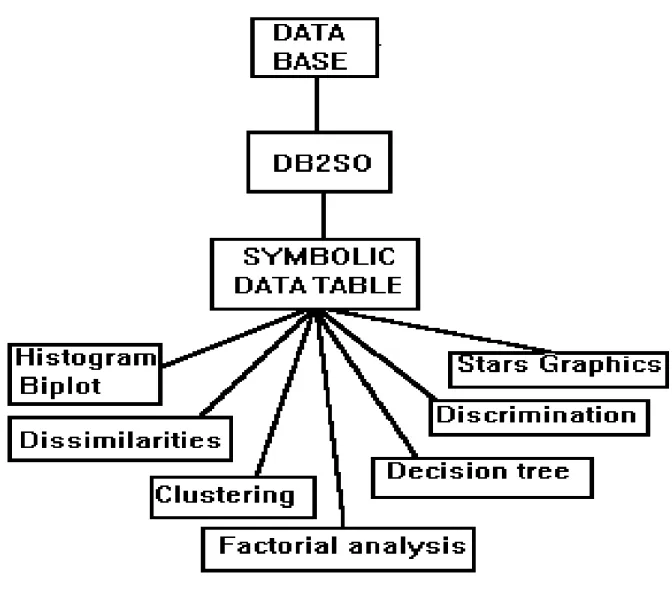
Documents relatifs
Over the past two decades, Data-Intensive Analysis (also called Big Data Analytics) has emerged not only as a basis for the Fourth Paradigm [8] of engineering and
Abstract The MIXMOD ( MIX ture MOD eling) program fits mixture models to a given data set for the purposes of density estimation, clustering or discriminant analysis.. A large
However, it seems to be little awareness, among researchers using artificial neural networks in catal- ysis, of the difference among the symbolic nature of the knowledge obtained
Each instance of the data used in analysis represents one sensitivity test and con- tains the following features: pathogen that is isolated during the bacterial identifica-
In this work we focus on an interactive clustering task (a standard high-level analytic task in Exploratory Data Analysis) and define an MD brush which enables the
