Difficulté du résultant et des grands déterminants
Texte intégral
Figure
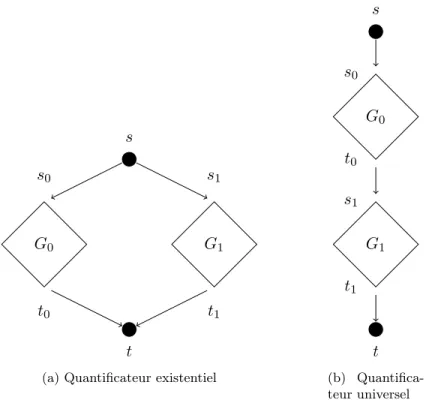
Documents relatifs
Du fait que le déterminant d’une famille de n vecteurs de K n est une forme n-linéaire alternée, les propriétés suivantes sur les rangées (i.e. les lignes et les colonnes)
On applique ce résultat avec =1 pour le (ii) et B égale à la matrice nulle pour le (iii). Les propriétés précédentes traduisent le fait que la transposition est une
[r]
diffeo avc vois de In – app : pas de ss gpe arbitrmt ptt de GLn. b/
Paris Descartes Mathématiques et calcul Calcul de déterminants 1/20.. 1
Si on permute 2 vecteurs de la famille, le déterminant est.. multiplié
Accéder à l'écran de calcul, puis dans les options (OPTN), sélectionner le menu matrice (touche F2), et choisir Trn (F4) Saisir ensuite Mat A (F1). Problème pouvant
Définir la dimension de la matrice A, ici, 2x2.Valider par entrer Saisir les éléments de la matrice et utiliser les flèches ou la touche entrer pour valider. Procéder de même
