SPREPI: Selective Prediction and REplay for predicated Instructions
Texte intégral
Figure
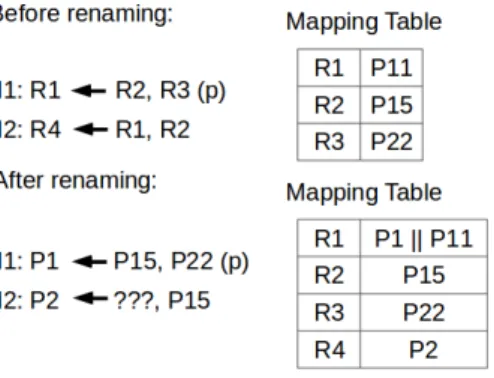







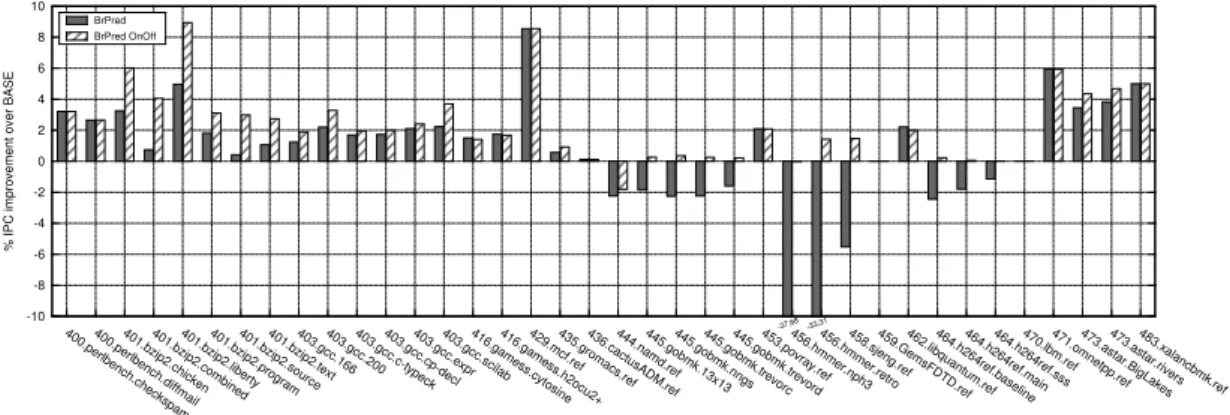
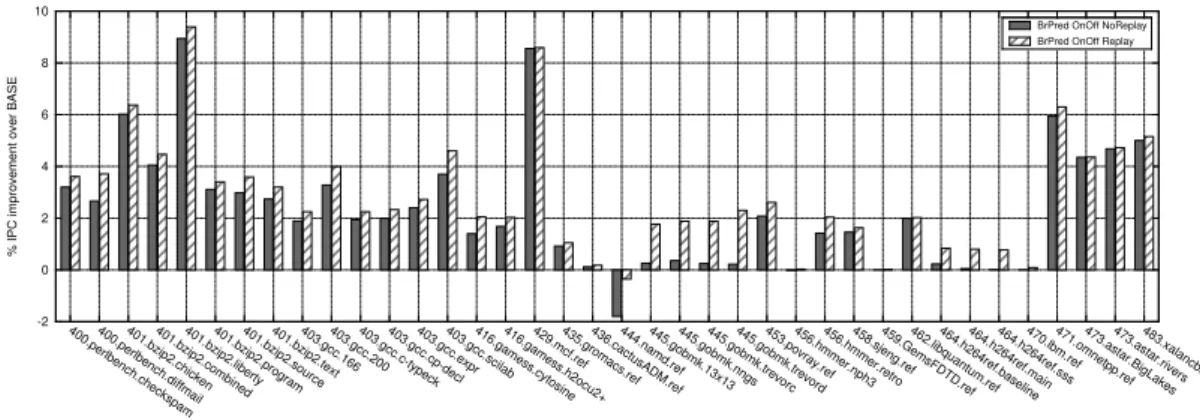
Documents relatifs
– EN 60335-1 : 10 (Household and Similar Electrical Appliances – Safety) – EN 60335-2-41 : 10 (Particular Requirements for Pumps)2.
Jonathan Wheatley, “Democratization in Georgia since 2003: Revolution or Repackaging?” (Paper presented at the Third International Workshop for Young Scholars, Slavic Research
RENUNCIA DE RESPONSABILIDAD: Cooper Lighting Solutions no asume ninguna responsabilidad por daños o pérdidas de ningún tipo que puedan derivarse de la instalación, manipulación o
Si la bomba va a extraer líquido desde un nivel que está por debajo de la boca de aspiración, hay que instalar una válvula de pie/de retención en el extremo de la tubería
GARANTIE LIMITÉE DE 5 ANS 1.Meubles South ShoreMC garantit à l'acheteur original, pour une période de 5 ans à partir de la date d'achat, toutes les composantes des meubles contre
15 Insert the drawer bottom into the grooves located on panels V and W Insérez le fond de tiroir dans les 2 rainures des panneaux V et W.
This warranty does not cover, and Graco shall not be liable for general wear and tear, or any malfunction, damage or wear caused by faulty installation, misapplication,
WARNING – Assemble product according to manufacturer’s instructions for ANY use mode – co-sleeper as well as the bassinet, cot or play yard modes.. WARNING – DO NOT use
