Un formalisme pour la traçabilité des transformations
Texte intégral
Figure
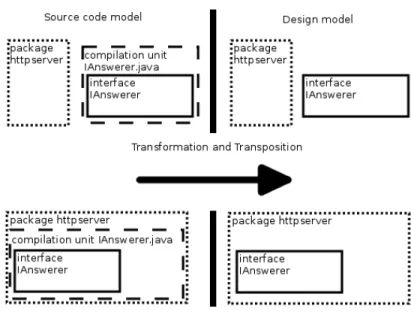
![Figure 1: excerpt of original source code [le Answerer.java]](https://thumb-eu.123doks.com/thumbv2/123doknet/8144008.273406/21.918.201.730.223.1026/figure-excerpt-original-source-code-le-answerer-java.webp)

Outline
Documents relatifs
creux sa juste scientificité. Reconnaître l’incomplétude de ce savoir, c’est s’ouvrir à la requête d’un autre type de savoir, d’une logique supérieure capable de
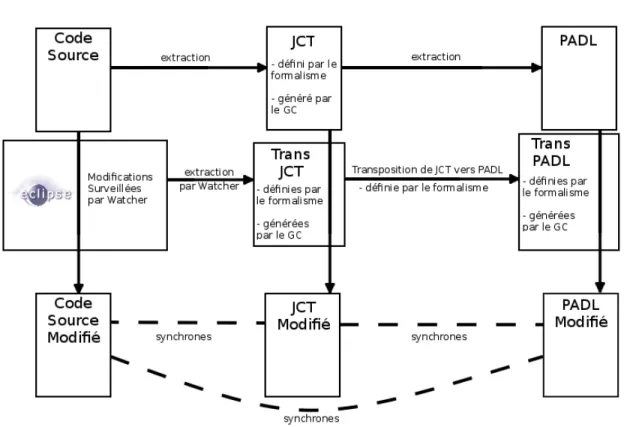
Dans cette optique, nous proposons dans cet article un framework de traçabilité dédié aux langages de transformation impératifs et permettant de générer un modèle de trace des
Chaque atome d’oxygène se lie avec une paire d’électron cédée par le carbone qui du fait de la charge de l’ion en comporterait trois paires d’où l’absence de doublets
mination de la probabilité w aux fonctions propres de l’équation de probabilité [2, (57)], peuvent être interprétés dans le language de la théorie ondula- toire
Nous avons vu que la fonction d’onde ϕ(x) et sa transform´ ee de Fourier ˜ ϕ(p) offrent deux mani` eres de pr´ esenter la mˆ eme information sur l’´ etat quantique
CHIMIE Fiche Mémoire N°1 - Transformations rapides,
In this framework, we claim that a learning algorithm aiming at achieving good prediction performances on a data stream subject to concept drifts must combine several properties:
Concernant les formalismes qui sont des restrictions de DEVS, même si techniquement ils possèdent leur propre méta-modèle, celui-ci est un dérivé de celui de DEVS
