Publisher’s version / Version de l'éditeur:
Vous avez des questions? Nous pouvons vous aider. Pour communiquer directement avec un auteur, consultez la
première page de la revue dans laquelle son article a été publié afin de trouver ses coordonnées. Si vous n’arrivez pas à les repérer, communiquez avec nous à [email protected].
Questions? Contact the NRC Publications Archive team at
[email protected]. If you wish to email the authors directly, please see the first page of the publication for their contact information.
https://publications-cnrc.canada.ca/fra/droits
L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB.
29th Annual Newfoundland Electrical and Computer Engineering Conference,
2020-11-19
READ THESE TERMS AND CONDITIONS CAREFULLY BEFORE USING THIS WEBSITE.
https://nrc-publications.canada.ca/eng/copyright
NRC Publications Archive Record / Notice des Archives des publications du CNRC :
https://nrc-publications.canada.ca/eng/view/object/?id=dca26c86-da58-4e64-bcb0-1b7c11545683
https://publications-cnrc.canada.ca/fra/voir/objet/?id=dca26c86-da58-4e64-bcb0-1b7c11545683
NRC Publications Archive
Archives des publications du CNRC
This publication could be one of several versions: author’s original, accepted manuscript or the publisher’s version. / La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur.
Access and use of this website and the material on it are subject to the Terms and Conditions set forth at
A reinforcement learning approach to route selection for ice-class
vessels
A reinforcement learning approach to route selection
for ice-class vessels
Trung Tien Tran1, Thomas Browne1 2, Dennis Peters1 and Brian Veitch1 1Faculty of Engineering and Applied Science
Memorial University of Newfoundland, St. John’s, Canada
Email:[email protected], [email protected], [email protected], [email protected]
2Ocean, Coastal, and River Engineering Research Centre
National Research Council of Canada, St. John's, Canada
Abstract— Identifying an optimal route for a vessel navigating
through ice-covered waters is a challenging problem. Route selection requires consideration of vessel safety, economics, and maritime regulations. Vessels navigating in the Arctic must follow the operational criteria imposed by the Polar Operational Limit Assessment Risk Indexing System (POLARIS), recently introduced by the International Maritime Organization. This research investigates a framework to find an optimal route for different ice-class vessels using reinforcement learning. The system defines a Markov Decision Process and uses Q-learning to explore an environment generated from a Canadian Ice Service ice chart. Reward functions are formulated to achieve operational objectives, such as minimizing the distance travelled and the duration of the voyage, while adhering to POLARIS criteria. The experimental results show that reinforcement learning provides a means to identify an optimal route for ice-class vessels.
Keywords—Reinforcement learning, POLARIS, path planning
I. INTRODUCTION
The International Maritime Organization’s (IMO) Polar Code addresses the design and operational aspects of vessels operating in polar regions [1]. Through the Polar Code, the IMO provides the Polar Operational Limit Assessment Risk Indexing System (POLARIS) as a risk-based methodology to assess the operational limitations of vessels navigating in sea ice [2]. POLARIS imposes operational criteria as a function of the vessel’s ice-class and the ice regime. When navigating in Arctic waters, a route must be selected that adheres to the POLARIS operational criteria while optimizing operational objectives of the voyage.
Reinforcement learning is an approach to solving pathfinding problems with many conflicting goals. Many new multi-objective reinforcement algorithms have been developed to address current limitations in general pathfinding problems [3]-[5]. These theoretical approaches have not been applied to real-world problems. While there have been studies that focus on applications using the current algorithms to find optimal routes with practical constraints for ships, they only investigate in the context of open water with obstacles [6], [7]. Recent studies have investigated vessels navigating through ice [8], [9], but none incorporate the POLARIS methodology.
This research deals with the pathfinding problem for vessels operating in ice. The purpose of this research is to explore a reinforcement learning framework to identify an optimal route for ice-class vessels, which follows the POLARIS guidelines.
The main contribution is introducing a conceptual model of an end-to-end solution for pathfinding problems for vessels operating in ice.
Section II reviews the related works of POLARIS and reinforcement learning. Section III introduces the proposed framework to explore the optimal route for the ice-class vessels. Section IV contains the experiments to calibrate the parameters and demonstrate an application to a realistic situation. Section V discusses the experimental results. Section VI is the conclusion with future work.
II. RELATED WORK
A. POLARIS and operational constraints in Arctic waters A key objective of maritime regulations is governance of the design, construction, and operation of ships to ensure safety, environmental protection, and maritime security. At the international level, the International Maritime Organization (IMO), an agency of the United Nations, develops and adopts regulations. Additional regulations may be adopted at the regional level, such as those specific to the European Union and between Canada and the United States. National administrations may impose additional regulations. It is at the national level that IMO member nations transpose regulations into national laws. These laws are enforced through flag state and port/coastal state jurisdictions.
The Polar Code [1] was adopted by the IMO and entered into force in 2017. The code addresses design and operational aspects of ships operating in polar waters that are not sufficiently covered by the International Conventions for the Safety of Life at Sea (SOLAS) and for the Prevention of Pollution from Ships (MARPOL) [10], [11]. The Polar Code includes provisions for hazards encountered in polar regions, such as sea ice, ice accretion, cold temperatures, extended periods of darkness, remoteness, emergency response, and environmental sensitivities.
The Polar Code provides the Polar Operational Limit Risk Indexing System (POLARIS) as a methodology to assess the operational limitations of vessels navigating in ice [2]. POLARIS imposes operational criteria, or constraints, on vessels navigating in ice, enforced by individual Arctic nations. The POLARIS methodology was developed based, in part, on the Canadian Arctic Ice Regime Shipping System (AIRSS) and the Russian Ice Certificate. In the Canadian Arctic, AIRSS and a third system, the Zone Date System, predate POLARIS and
are still used in certain scenarios to constrain the operation of ships in ice [12].
POLARIS is a risk-based methodology used to support both voyage planning and real-time decision-making. The risk of a vessel incurring structural damage due to sea ice is evaluated based on vessel ice-class (i.e. structural capacities) and the ice regime. PC1 has the highest ice capability. Risk Index Values (RIVs) are assigned to each ice type for a given ice-class, ranging from -8 to +3 [1]. Note that an ice regime is typically comprised of multiple ice types. A resultant Risk Index Outcome (RIO) is determined by the summation of the RIVs for each ice type present in the ice regime multiplied by the corresponding concentration of that ice type (expressed in tenths), as presented in Equation 1.
RIO = (C1 x RIV1) + (C2 x RIV2) + … + (Cn x RIVn) (1)
where C1 … Cn = concentration (in tenths) of each ice type
within the ice regimes; and RIV1…RIVn = the corresponding
RIVs for each ice type.
The calculated RIO values correspond to the operational criteria for the vessel, as presented in Table I. A vessel subject to ‘elevated operational risk’ must reduce speed and consider additional watch-keeping and ice breaker escort. A vessel subject to ‘operation subject to special consideration’ requires further speed reduction, course alteration, or other special measures. Note that vessels below ice-class PC7 and non-ice-class vessels receive more restrictive operational constraints. Under Canadian jurisdiction, for a vessel with an RIO corresponding to ‘operation subject to special consideration’, course alteration is mandatory [12].
Recommended safe speed limits for elevated operational risk are provided in the POLARIS guidelines and presented in Table II.
The intent of POLARIS is that a high ice class vessel navigating through severe ice conditions while adhering to the operational criteria has the same perceived risk level as a
non-ice-strengthened vessel operating in open water [13]. While RIO values can be seen as a proxy for the risk of structural damage, POLARIS considers only the likelihood of structural damage and does not consider the resulting consequences, should an accident occur. Browne et al. [14] propose an augmentation to the POLARIS methodology to capture a more holistic risk perspective, one that includes life-safety and environmental consequences that can result from a vessel incurring ice damage.
The risk of structural damage corresponding to RIO values has been questioned. Kujala et al. [15] argue that there remains significant uncertainty in estimated ice loads for different ship-ice interaction scenarios. There is also the risk that a low ship- ice-class vessel could receive a positive RIO when trace amounts of multi-year ice are present. The presence of multi-year ice features pose a significant risk to low ice-class vessels.
Despite the critiques, a validation study by Kujala et al. [15] concluded that POLARIS provides a reasonable indication of the likelihood of a vessel incurring ice damage. Full-scale ice-induced hull loads and ice concentrations were recorded on two separate voyages: the SA Agulhas II in Antarctica and the MT Uikku in the Kara Sea in the Russian Arctic. The optimal ice class to allow safe navigation was evaluated using POLARIS and then evaluated based on the required hull strength to mitigate the risk of structural damage. For both scenarios, POLARIS identified the same optimal ice class as a first principles structural analysis.
For the purpose of this study, the POLARIS methodology is used to model operational speed constraints for different ice-class vessels. Recommended speed reductions for vessels in ice conditions with -10 ≤ RIO < 0 correspond to those presented in Table II. The selection of an alternate route, i.e. a “no-go” decision, is required for all scenarios with RIO < -10. Demonstrating the ability to use reinforcement learning to model the regulatory framework for Arctic ships provides a means to assess the impact that new and proposed regulations might have on the operational objectives of the Arctic shipping industry.
B. Reinforcement learning
Reinforcement learning is a process in which an agent interacts with an environment. The agent learns how to make the best decision to solve a specific problem in the environment. This learning process repeats many times so that the agent can reinforce what it learns and eventually identify an optimal solution for the problem. The reinforcement learning framework involves a policy, a reward signal, and a value function. The policy guides the agent on how to act in a situation. After taking action, the agent receives a reward signal. The value of this signal illustrates how good or bad this action is at this time. The value function is an indicator of long-term rewards. At a time, the value function accumulates all the expected future rewards from this step. Both immediate rewards and long-term rewards are essential in the reinforcement learning system [16].
Problems like the path finding scenarios at issue here can be represented as Markov Decision Processes (MDPs). An MDP comprises a finite set of states S, another finite set of actions A, a state transition probability matrix P, a reward function R, and a discount factor γ. The outcome of solving the MDP is an
TABLE I. OPERATIONAL CRITERIA IMPOSED BY POLARIS[2]
RIO Ice class
PC1 – PC7 Below PC7 and non-ice class RIO ≥ 0 Normal operation Normal operation -10 ≤ RIO < 0 Elevated operational
risk Operation subject to special consideration RIO < -10 Operation subject to
special consideration
TABLE II. SAFE SPEED LIMITS FOR ELEVATED RISK OPERATIONS [2]
Ice class Safe speed limit
PC1 11 knots PC2 8 knots PC3 – PC5 5 knots Below PC5 3 knots
optimal policy that maps which action should be taken at a certain state [16].
C. Multi-objective reinforcement learning with Q-learning Q-learning is a common algorithm in reinforcement learning, introduced by Watkin and Dayan [17]. This algorithm is based on the action value function Q(s,a), where the update rule follows Equation 2.
Q(s,a) ← Q(s,a) + α[r + γmaxa’Q(s’,a’) - Q(s,a)] (2)
where: α is the learning rate r is the reward value
s and a are the current state and action, respectively s’ and a’ are the next state and action, respectively In a single objective problem, the reward r is a number, reflecting how the action affects the goal. On the other hand, in the multi-objective optimization, r is an n-element vector, where n is the number of objectives [18]. The agent chooses an action by comparing the reward values of all possible actions, and picks the highest one (referred to as a greedy policy). While it is easy to execute it on the single-objective problem, it is more complicated for multi-objectives with vector comparisons.
The simplest way to execute comparison operations is the scalarization approach [3]. All elements of the vector are scalarized into one score by a linear or nonlinear function. The chosen action has the highest score. This approach is easy to implement, but the disadvantage is that it requires a fair tuning scalarization process [3], [4]. The second approach is using Q-learning based on Pareto dominance [5], [19]. This solution does not need a scalarized score. It compares two vectors directly using a definition of Pareto dominance [19]. However, when the number of objectives increases, almost all actions become Pareto optimal by definition, leading action choices to be random. Another approach in this area is Voting Q-learning [4]. It compares the corresponding pairs of two vectors and uses the social voting theory to determine the winner. Voting Q-learning is more effective than Pareto Q-learning [4]. In this research, we use a scalarized multiple objective reinforcement learning method [3], because it is easy to control the behaviour of agents by a reward function. This approach is similar to Range Voting Q-learning, as introduced in [4].
III. THE MAIN FRAMEWORK
A. Overall
The system proposed here identifies the optimal route for a vessel navigating in ice. The system has two stages: identifying the route and a violation check, as shown in Fig. 1. The input is the vessel’s assigned ice-class and a discretized grid of a sea ice chart, and the output is the optimal route. The first stage explores the environment by reinforcement learning and comes up with an optimal route. The agent is assumed to go through all areas, including the land and any restricted ice regimes. Though these scenarios never happen in the real world, this assumption helps train the agent to avoid making serious mistakes. Fig. 2 shows the general reinforcement learning model of stage 1. The second stage checks the validity of the route, i.e. if the resulting route contains any predefined violation, it is rejected. Three different ice-class vessels are investigated: Polar Class 3 (PC3), Polar Class 7 (PC7), and Finnish-Swedish ice class IC (IC). PC3 is the
most ice capable ice-class while IC is the least. Each vessel is a different agent in the model. The vessels adhere to the POLARIS operational criteria detailed in Section II.
B. MDP description and Q-learning algorithm
State representation: Each state in the MDP is represented by the location of the agent in the ice chart, s = (x, y), where x, y are the two-dimensional coordinates of the agent in the map.
Action representation: A ship operation is a complex system with many factors that influence decision-making. For the illustration of this conceptual model, only two factors are considered: direction and speed. The agent has four options: north, south, east, or west, while there are two speed choices: normal speed and low (safe) speed. The fixed setpoint of normal speed used in this illustration case is 10 knots, while the values of low speed follow Table II. Therefore, the action set has a combined total of eight.
Reward function: This design is the most crucial part of our investigation. The reward functions influence the route selection and the compliance of the vessel to POLARIS. Every time the agent takes action, it receives a tuple of rewards: [distance, time]. The reward function returns a score, which is the sum of these two elements in the tuple. The distance reward is arbitrarily set to -1 for every move, time reward is k*(-1/speed). The rewards are negative to encourage the agent to finish the voyage in the shortest distance and as soon as possible. The parameter k is a calibration factor used to balance the two objectives. Besides the primary reward function, we also design the penalty applied to agents if there is any violation, e.g. the agent hits land or the operation does not meet the POLARIS guidelines. Specifically, the agent will get a penalty tuple
Fig. 1. The main framework
Fig. 2. Reinforcement learning model (inset images modified from [20] and [21])
[-1000, -1000] or score -2000 if it violates any operational rule. The operational violation conditions are defined below:
IF RIO < -10
IF (ice-class is PC3 - PC7) AND ( -10 ≤ RIO < 0) AND (speed = normal speed)
IF (ice-class is IC) AND (RIO < 0)
The scalarized multiple objective Q-learning is described in Algorithm 1.
IV. EXPERIMENT
Two experiments are completed for this study. The first is a calibration in which the framework is used to find an optimal route in a simple 10x10 grid environment. The second experiment tests how the system works in a realistic environment. This environment is generated from an ice chart published by the Canadian Ice Service.
A. Calibration with 10x10 grid environment
In the first experiment, each agent (PC3, PC7, and IC) explores the 10x10 grid environment (Fig. 3) to identify the
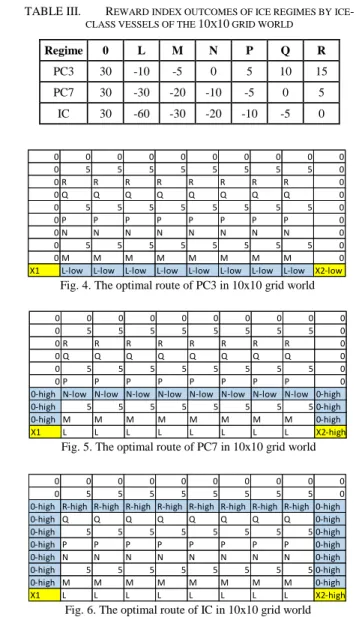
optimal route between X1 and X2. Each cell is marked by a number or a character. X1 and X2 are the origin and destination points, respectively. Zero (0), X1, and X2 are open water areas, five (5) represents land, and the remaining characters represent different ice regimes. The calculated RIO values of each ice regime for each vessel are shown in Table III.
Each agent executes 1000 episodes. Each episode starts at X1, and terminates when the agent reaches the destination X2, or the number of actions hits the limit of 100,000 actions. This limit helps the algorithm stop in case of an infinite loop. The two hyperparameters of Q-learning - the learning rate and discount factor - are set to 1.0. The parameter k in the reward function is tuned manually. In this experiment, k = 3.
Epsilon-greedy is used to trade off the exploration and exploitation of the agent. In every step, a random number is generated in the range [0, 1]. If this number is smaller than epsilon, the action is randomized. Otherwise, the agent greedily chooses the action with the highest score. The value of epsilon is large and gradually reduced to 0.0 in the first half of training
Fig. 3. 10x10 grid world of an ice chart
Fig. 4. The optimal route of PC3 in 10x10 grid world
0 0 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5 0 0 R R R R R R R R 0 0 Q Q Q Q Q Q Q Q 0 0 5 5 5 5 5 5 5 5 0 0 P P P P P P P P 0 0 N N N N N N N N 0 0 5 5 5 5 5 5 5 5 0 0 M M M M M M M M 0
X1 L-low L-low L-low L-low L-low L-low L-low L-low X2-low
Fig. 5. The optimal route of PC7 in 10x10 grid world
0 0 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5 0 0 R R R R R R R R 0 0 Q Q Q Q Q Q Q Q 0 0 5 5 5 5 5 5 5 5 0 0 P P P P P P P P 0
0-high N-low N-low N-low N-low N-low N-low N-low N-low 0-high
0-high 5 5 5 5 5 5 5 5 0-high
0-high M M M M M M M M 0-high
X1 L L L L L L L L X2-high
Fig. 6. The optimal route of IC in 10x10 grid world
0 0 0 0 0 0 0 0 0 0
0 5 5 5 5 5 5 5 5 0
0-high R-high R-high R-high R-high R-high R-high R-high R-high 0-high
0-high Q Q Q Q Q Q Q Q 0-high 0-high 5 5 5 5 5 5 5 5 0-high 0-high P P P P P P P P 0-high 0-high N N N N N N N N 0-high 0-high 5 5 5 5 5 5 5 5 0-high 0-high M M M M M M M M 0-high X1 L L L L L L L L X2-high Algorithm 1 [3]
Initialize Q(s,a,o) arbitrarily
for each episode t do
Initialize state s
repeat
Choose action a from state s using policy derived from Q-values (using ε-greedy and scalarization technique) Take action a, and observe next state s’ and reward r(s,a)
for each objective o do
Q(s,a,o) ← Q(s,a,o)+ α[r(s,a,o) + γmaxa’Q(s’,a’,o) -
Q(s,a,o)]
end for
s ← s’
until s is terminal end for
TABLE III. REWARD INDEX OUTCOMES OF ICE REGIMES BY ICE
-CLASS VESSELS OF THE 10X10 GRID WORLD
Regime 0 L M N P Q R
PC3 30 -10 -5 0 5 10 15 PC7 30 -30 -20 -10 -5 0 5
to prioritize for exploration. Epsilon is set to 0 in the second half of training to prioritize exploitation This technique is presented in [4].
The optimal route identified for each agent is presented in Fig. 4, Fig. 5, and Fig. 6.
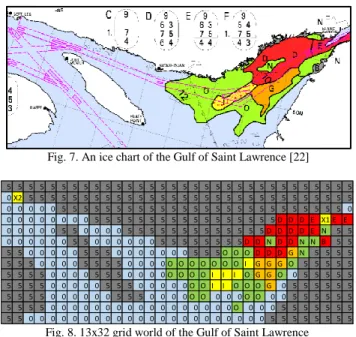
B. Demonstration with ice chart
In the second experiment, the calibrated framework is tested with a CIS ice chart for the Gulf of Saint Lawrence (Fig. 7). The ice chart is discretized to a 32x13 grid environment (Fig. 8). The agents depart from Blanc Sablon (upper right corner of the grid) and travel west to the arrival port in Sept Iles. The same three vessel classes (PC3, PC7, and IC) are investigated. The calculated RIO values for the three classes are presented in Table IV. The results for PC3 and PC7 are shown in Fig. 9 and Fig. 10, respectively. There is no acceptable route found for IC in this environment. These results are discussed further in Section V.
V. DISCUSSION
This study illustrates and investigates the use of reinforcement learning to identify an optimal route for different ice-class vessels navigating in ice while subjected to operational objectives and the POLARIS operational criteria. In the first experiment, the routes are represented by markers “high” or “low”. These markers also indicate the speed setpoint of the agent at that location. The results of pathfinding for PC3, PC7, and IC are in Fig. 4, Fig. 5, and Fig. 6, respectively. The agent PC3 chooses to go straight slowly from X1 to X2 via ice regimes “L”. PC7 decides to travel a bit farther to the north then crosses
the regime “N”. IC takes a long trip following the open water areas and the regimes “R”. All of these routes comply with the requirement of POLARIS. All of these results reflect the expected behaviours of three ice-class vessels. Among the three categories, the PC3 tends to choose the shortest route because it has the highest operational capability in ice. The IC agent has to choose the longest route. Due to its lower ice class design, it is not capable of operating in the more severe ice regimes, compared to PC3 and PC7.
The second experiment is an illustration of a practical application to plan a route through ice-covered water. While the Polar Code and POLARIS are not a requirement for vessels operating in the Gulf of Saint Lawrence, the sub-Arctic region provides a case study to demonstrate application of the framework. The results of PC3 and PC7 are similar to the suggested route of the authority, depicted by the dotted line in Fig. 7. Both vessels choose high speed for the duration of the voyage because their RIO values are positive. The difference between PC3 and PC7 is insignificant. Both of them choose the shortest routes. There is no acceptable route found for IC because around the departure port are “E”, “N”, “B” regimes, which correspond to negative RIO values for IC. These results might be enhanced by increasing the resolution of the grid world.
VI. CONCLUSION AND FUTURE WORK
This paper proposes a reinforcement learning framework using Q learning to identify the optimal route for ships in ice under POLARIS constraints. The results show that the framework works as expected with strict compliance of POLARIS. The operational objectives and regulatory constraints used in this study are a simplified representation of a complex problem, however the results demonstrate that reinforcement learning can support voyage planning for ships in ice. The use of a reinforcement-learning framework could also benefit emergency response in Arctic regions with uncertain departure and arrival points. In the future, there are some ways to improve this work. Firstly, industry consultation could
Fig. 7. An ice chart of the Gulf of Saint Lawrence [22]
Fig. 8. 13x32 grid world of the Gulf of Saint Lawrence 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 0 X2 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 0 0 0 0 0 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 D D D E X1 E E 0 0 0 0 0 5 5 0 0 0 0 5 5 5 5 5 5 5 5 5 5 5 5 5 D D D D E N 5 5 0 0 0 0 0 0 5 5 0 0 0 0 0 0 5 5 5 5 5 5 5 5 D D N D D N N B 5 5 5 5 0 0 0 0 0 5 5 5 0 0 0 0 0 0 0 5 5 5 O O O D D D G N 5 5 5 5 5 5 5 0 0 0 0 5 5 5 5 0 0 0 0 O O O O O O O I G G G O 5 5 5 5 5 5 5 5 5 0 0 0 0 5 5 5 0 0 0 0 O O O O I I I O G G O 0 5 5 5 5 5 5 5 5 5 0 0 0 0 0 5 5 5 0 0 0 0 0 O O I I O O O G 0 5 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 5 5 5 0 0 0 0 O O 0 0 0 O O 0 0 5 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 O 0 0 0 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5
Fig. 9. The optimal route of PC3 in the Gulf of Saint Lawrence 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 0 X2- 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 00- 0- 0- 0- 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 0 0 0 0 00- 0- 0- 0- 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 D D D E-X1 E E 0 0 0 0 0 5 50- 0- 0- 0- 5 5 5 5 5 5 5 5 5 5 5 5 5 D D D D E-N 5 5 0 0 0 0 0 0 5 5 0 00- 0- 0- 0- 5 5 5 5 5 5 5 5 D D N D D N- N-B 5 5 5 5 0 0 0 0 0 5 5 5 0 0 00- 0- 0- 0- 5 5 5 O O O D D D G- N- 5 5 5 5 5 5 5 0 0 0 0 5 5 5 5 0 0 0 0 O O- O- O- O- O- O- I- G- G- G- O- 5 5 5 5 5 5 5 5 5 0 0 0 0 5 5 5 0 0 0 0 O O O O I I I O G G O 0 5 5 5 5 5 5 5 5 5 0 0 0 0 0 5 5 5 0 0 0 0 0 O O I I O O O G 0 5 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 5 5 5 0 0 0 0 O O 0 0 0 O O 0 0 5 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 O 0 0 0 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5
Fig. 10. The optimal route of PC7 in the Gulf of Saint Lawrence 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 0 X2- 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 00- 0- 0- 0- 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 0 0 0 0 00- 0- 0- 0- 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 D D D E X1 E E 0 0 0 0 0 5 50- 0- 0- 0 5 5 5 5 5 5 5 5 5 5 5 5 5 D D DD- E- N- 5 5 0 0 0 0 0 0 5 5 00- 0- 0- 0- 0- 5 5 5 5 5 5 5 5D- D- N- D- D- N-N B 5 5 5 5 0 0 0 0 0 5 5 5 0 0 00- 0- 0- 0 5 5 5 O O O-D D D G N 5 5 5 5 5 5 5 0 0 0 0 5 5 5 5 0 0 0 0O- O- O- O- O- O- O- I- G G G O 5 5 5 5 5 5 5 5 5 0 0 0 0 5 5 5 0 0 0 0 O O O O I I I O G G O 0 5 5 5 5 5 5 5 5 5 0 0 0 0 0 5 5 5 0 0 0 0 0 O O I I O O O G 0 5 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 5 5 5 0 0 0 0 O O 0 0 0 O O 0 0 5 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 O 0 0 0 5 5 5 5 5 5 5 5 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 5 5 5 5 5 5 5
TABLE IV. REWARD INDEX OUTCOMES OF ICE REGIMES BY ICE
-CLASS VESSELS OF THE GULF OF SAINT LAWRENCE
Regime 0 B D E G I N O
PC3 30 20 21 21 23 23 29 29 PC7 30 -4 0 0 6 14 26 28 IC 30 -34 -27 -27 -15 -5 23 25
provide insight into additional operational ship objectives, such as fuel consumption and risk mitigation, and the weighting or prioritization of the associated reward functions. Secondly, the Q-learning algorithm has a limitation with a huge state space and evaluating the model with a function approximation approach would be worthwhile. Thirdly, the only regulatory instrument incorporated in this model is the POLARIS methodology. Future work might consider additional regulatory constraints.
ACKNOWLEGDMENT
The authors acknowledge with gratitude the financial support of the NSERC-Husky Energy Industrial Research Chair in Safety at Sea.
REFERENCES
[1] IMO, “International code for ships operating in polar waters (polar code),” International Maritime Agency London, England, Tech. Rep., 2014.
[2] M. S. Committee et al., “Guidance on methodologies for assessing operational capabilities and limitations in ice,” Tech. Rep. MSC. 1/Circ.1519, International Maritime Organization, London, Tech. Rep., 2016.
[3] K. Van Moffaert, M. M. Drugan, and A. Nowe, “Scalarized multiobjectivereinforcement learning: Novel design techniques,” in 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL). IEEE, 2013, pp. 191–199.
[4] B. Tozer, T. Mazzuchi, and S. Sarkani, “Many-objective stochastic path finding using reinforcement learning,” Expert Systems with Applications, vol. 72, pp. 371–382, 2017.
[5] K. Van Moffaert and A. Now´e, “Multi-objective reinforcement learning using sets of pareto dominating policies,” The Journal of Machine Learning Research, vol. 15, no. 1, pp. 3483–3512, 2014.
[6] C. Chen, X.-Q. Chen, F. Ma, X.-J. Zeng, and J. Wang, “A knowledgefree path planning approach for smart ships based on reinforcement learning,” Ocean Engineering, vol. 189, p. 106299, 2019.
[7] M. Etemad, N. Zare, M. Sarvmaili, A. Soares, B. B. Machado, and S. Matwin, “Using deep reinforcement learning methods for autonomous vessels in 2d environments,” in Canadian Conference on Artificial Intelligence. Springer, 2020, pp. 220–231.
[8] V. Lehtola, J. Montewka, F. Goerlandt, R. Guinness, and M. Lensu, “Finding safe and efficient shipping routes in ice-covered waters: a
framework and a model,” Cold regions science and technology, vol.165, p. 102795, 2019.
[9] P. Krata and J. Szlapczynska, “Ship weather routing optimization with dynamic constraints based on reliable synchronous roll prediction,” Ocean Engineering, vol. 150, pp. 124–137, 2018.
[10] IMO, “Solas: International convention for the safety of life at sea, 1974: resolutions of the 1997 solas conference relating to bulk carrier safety,” International Maritime Organization, Tech. Rep., 1999.
[11] IMO , “Marpol consolidated edition 2011: Articles, protocols, annexes and unified interpretations of the international convention for the prevention of pollution from ships, 1973, as modified by the 1978 and 1997 protocols,” International Maritime Organization, Tech. Rep., 2011. [12] TC, “Guidelines for assessing ice operational risk,” TP 15383E. Transport
Canada, Tech. Rep., 2019.
[13] J. Bond, R. Hindley, A. Kendrick, J. K¨am¨ar¨ainen, L. Kuulila et al., “Evaluating risk and determining operational limitations for ships in ice,” in OTC Arctic Technology Conference. Offshore Technology Conference, 2018.
[14] T. Browne, R. Taylor, B. Veitch, P. Kujala, F. Khan, and D. Smith, “A framework for integrating life-safety and environmental consequences into conventional arctic shipping risk models,” Applied Sciences, vol. 10, no. 8, p. 2937, 2020.
[15] P. Kujala, J. K¨am¨ar¨ainen, and M. Suominen, “Validation of the new risk based design approaches (polaris) for arctic and antarctic operations,” in Proceedings of the International Conference on Port and Ocean Engineering Under Arctic Conditions, 2019.
[16] R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press, 2018.
[17] C. J. Watkins and P. Dayan, “Q-learning,” Machine learning, vol. 8, no.3-4, pp. 279–292, 1992.
[18] B. Viswanathan, V. Aggarwal, and K. Nair, “Multiple criteria markov decision processes,” TIMS Studies in the management sciences, vol. 6, pp. 263–272, 1977.
[19] Y. Censor, “Pareto optimality in multiobjective problems,” Applied Mathematics and Optimization, vol. 4, no. 1, pp. 41–59, 1977.
[20] “Anchor-handling tug/supply vessels.” [Online]. Available: https://ral.ca/designs/anchor-handling-tug-supply-vessels/
[21] “Sea ice,” Sep 2020. [Online]. Available: https://en.wikipedia.org/wiki/Sea_ ice.
[22] F. Gouvernment of Canada and Oceans, “Canadian coast guard - marinfo - ice recommended routes,” Jun 2020. [Online]. Available: https://www.marinfo.gc.ca/en/glaces/RouteGlaces.php?route=carte_c
![TABLE II. S AFE SPEED LIMITS FOR ELEVATED RISK OPERATIONS [2]](https://thumb-eu.123doks.com/thumbv2/123doknet/13976939.454073/3.918.74.443.104.401/table-ii-afe-speed-limits-elevated-risk-operations.webp)
![Fig. 2. Reinforcement learning model (inset images modified from [20]](https://thumb-eu.123doks.com/thumbv2/123doknet/13976939.454073/4.918.499.813.81.487/fig-reinforcement-learning-model-inset-images-modified-from.webp)