CL1 Manual
Texte intégral
Figure
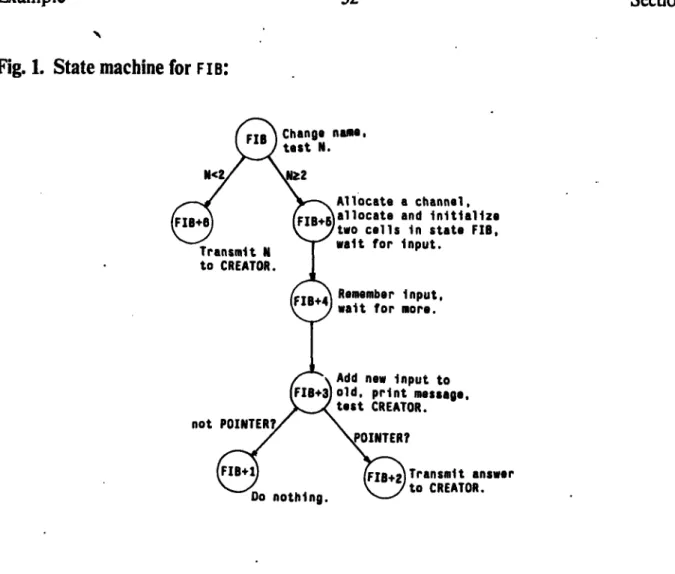
Documents relatifs
Another noteworthy result tied to associativity is that systems generated by a single connective are always polynomially as efficient as any system generated by two or more
We propose ODARyT Tool, a web application which provides a mechanism to browse and edit an ontology, edit and query an annotation database of resources composing a corporate memory..
This simple building of the Arrhenius law is in fact related to the Bose-Einstein distribution, assuming that energy quanta are inherently im- material, permutable between the
(4) Remark 2 We note that, for bounded and continuous functions f, Lemma 1 can also be derived from the classical Crofton formula, well known in integral geometry (see for
We now apply our main result to the computation of orness and andness average values of internal functions and to the computation of idempotency average values of conjunctive
In this study, a focus is made on the analysis of Ntann12 expression in BY-2 cells grown under biotic and abiotic stress conditions, and in tobacco plants during seedling
rDzogs chen in its earliest form sought to place the yogin in direct contact with the true nature of reality by awakening intuitive cognition in what is called a “direct
As said, our general hypothesis is that the creative process of architects can be grounded, at least in part, on the re-contextualization of spatial patterns of properties present
