Automatic Estimation of Transcription Accuracy and Difficulty
5
0
0
Texte intégral
(2)
Figure
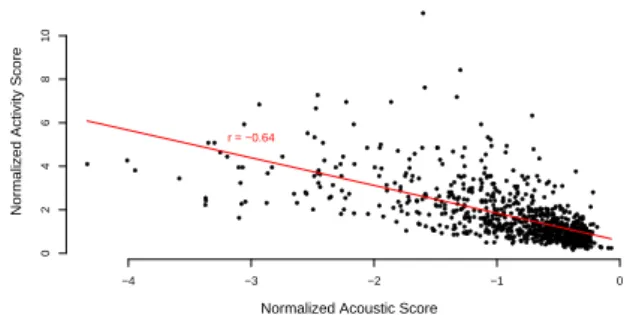
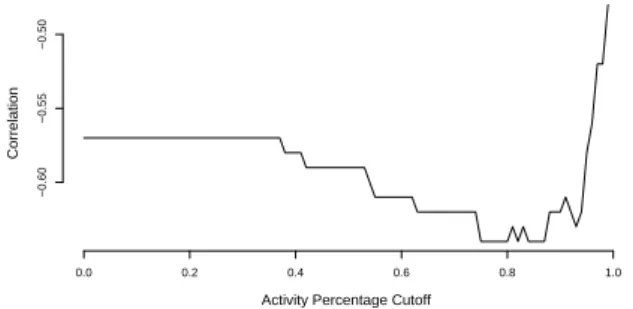
Documents relatifs
Experimental results on the TED-LIUM corpus show that the proposed adaptation technique can be effectively integrated into DNN and TDNN setups at different levels and provide
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
These results show that acoustic and labial features contain comp]ementary information and that the performance of an acoustic speaker recognition system can be
This new method is specifically designed to lower the complexity of the modeling phase, compared to classical techniques, as well as to decrease the required amount of learning
Copyright and moral rights for the publications made accessible in the public portal are retained by the authors and/or other copyright owners and it is a condition of
Acoustic Model Merging Using Acoustic Models from Multilingual Speakers for Automatic Speech Recognition.. Tien Ping Tan, Laurent Besacier,
d(Ψ src , Ψ tgt ) = hΨ src , Ψ tgt i (8) In the context of voice casting, the advantage of the multi-label scoring is double : first, the multi-label scoring can be used to
The article presents a method for adapting a GMM-based acoustic-articulatory inversion model trained on a reference speaker to another speaker. The goal is to
