Power Spectral Clustering
Texte intégral
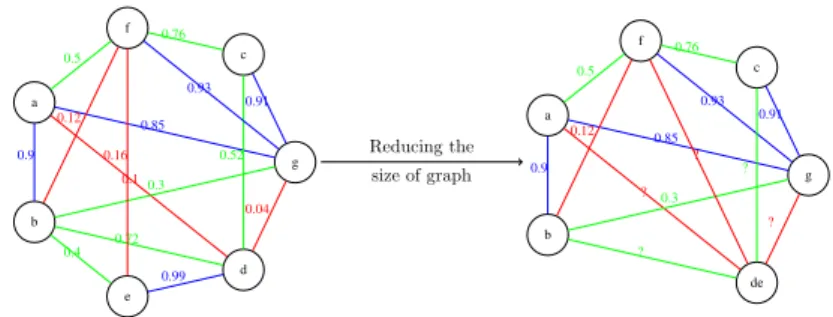
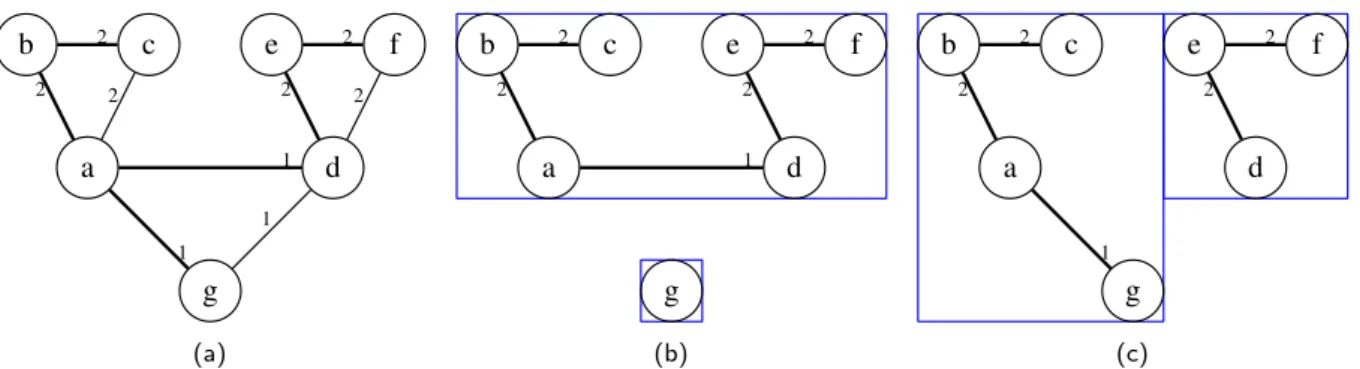
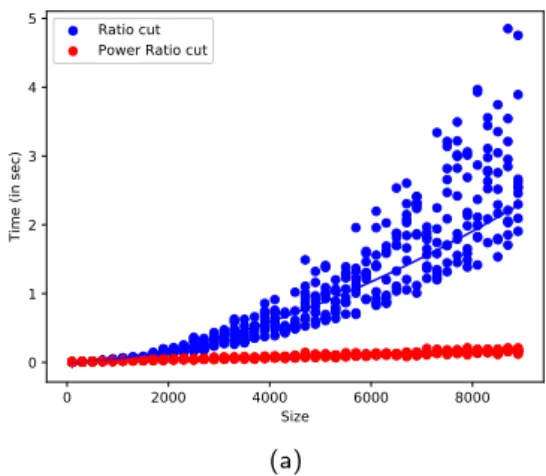
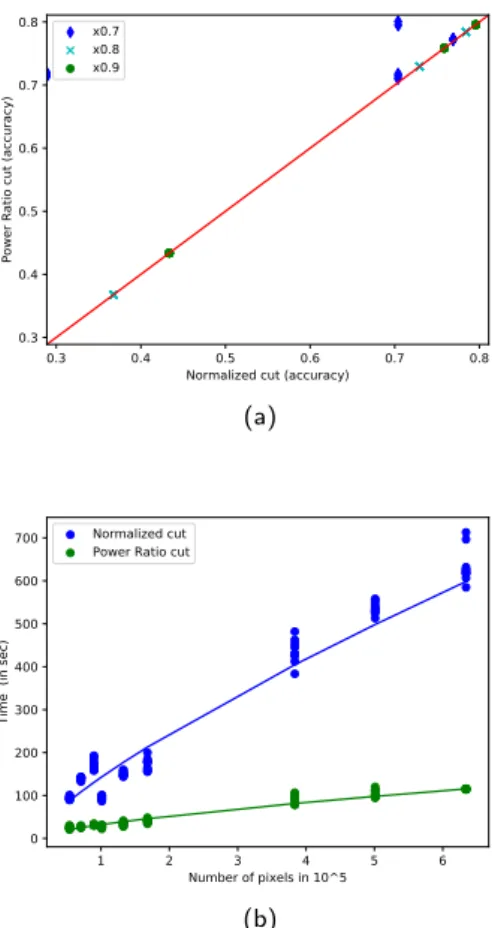
Figure
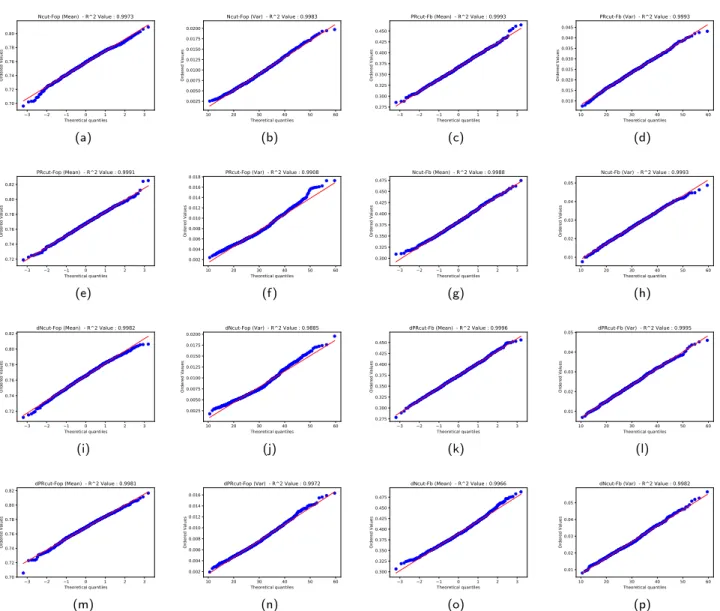
![Fig. 9 (a) Shows the precision-recall curves of the measure F b as defined in [31]. (b) Shows the precision-recall curves of the measure F op as defined in [31]](https://thumb-eu.123doks.com/thumbv2/123doknet/14430631.515112/14.892.75.803.544.1010/shows-precision-recall-measure-defined-precision-measure-defined.webp)

Documents relatifs
In our study, the renal outcome was poorly predictable, whereas some patients presented with only mild proteinuria and stable eGFR during an overall median follow-up of 3 years,
Antibiotics delivery by oral gavage twice a day or in drinking water induces in contrast a robust and consistent depletion of mouse fecal bacteria, as soon as 4 days of treatment,
يرحتلا ةروثلل نيئجلالا لبق نم مدقملا يلاملا معدلا ديازت دقل ةهبج تماق امدعب ةصاخ ةير لاوملأا ةيابج اهتمهم يلازم قيدص فارشإ تحت سنوتب اهل ةدعاق
This is also consistent with predictions from fluid-dynamic models for time required to generate a zoned phonolite magma chamber with the dimensions of the Laacher See system (Tait
ﺧﺎﺗﻤﺔ اﻟﻔﺼﻞ : ﻤن ﺨﻼل دراﺴﺔ ﻓﻌﺎﻝﻴﺔ اﻝﺴﻴﺎﺴﺔ اﻝﻨﻘدﻴﺔ وﻗدرة ﺘﺄﺜﻴرﻫﺎ ﻋﻠﻰ ﻨظم اﻝﺼرف ﻓﻲ اﻝﺠزاﺌر وذﻝك ﻓﻲ ﻤﻌﺎﻝﺠﺔ اﻹﺨﺘﻼﻻت اﻻﻗﺘﺼﺎدﻴﺔ ،ﺒﺎﻹﻀﺎﻓﺔ إﻝﻰ ﺘﻔﺎﻋل ﺒﻴن
A personalized video record of the design process used in building a column is associated on the videodisc with the computer graphics study of the column's
Also at Department of Physics, California State University, Sacramento; United States of America. Also at Department of Physics, King’s College London, London;
Després [4] has shown that it is mandatory to use impedance type transmission conditions in the coupling of sub-domains in order to obtain convergence of non- overlapping
