A Speed-Up Technique for Distributed Shortest Paths Computation
Texte intégral
Figure
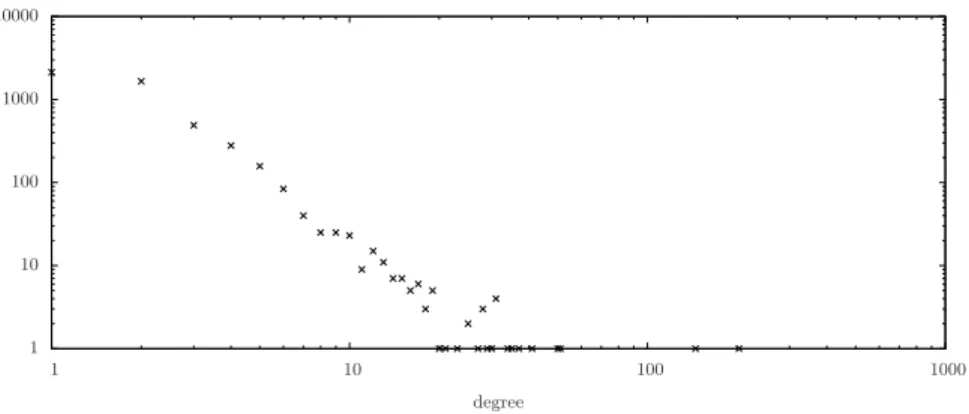
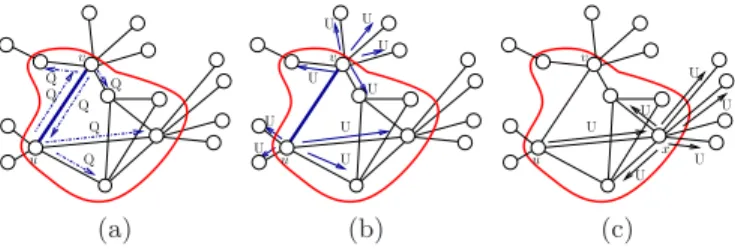
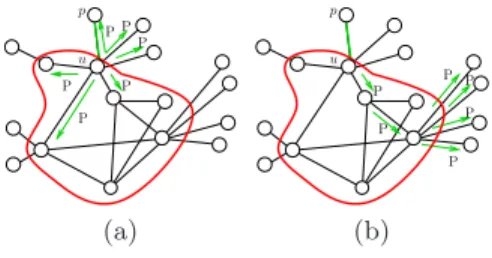
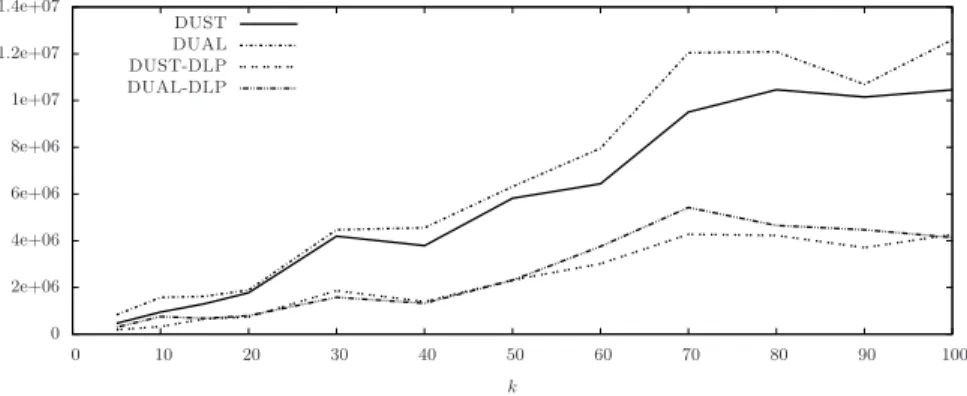
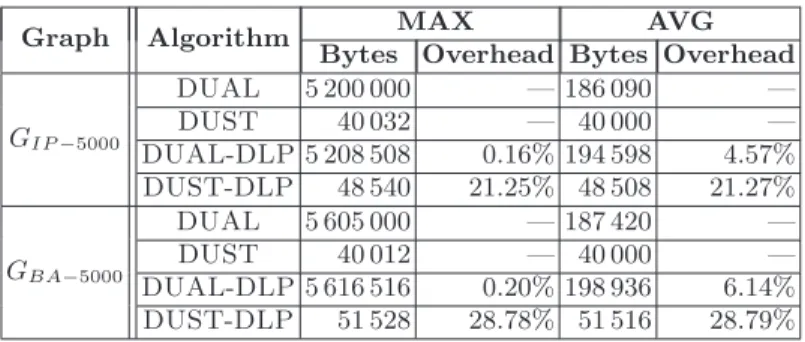
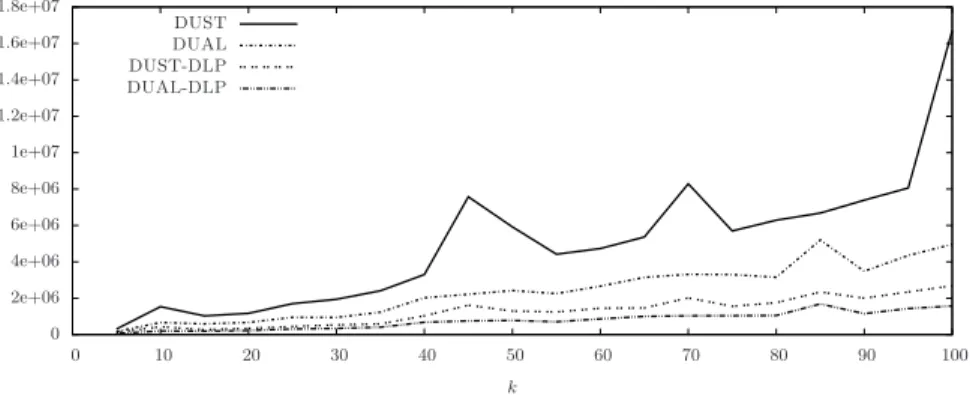
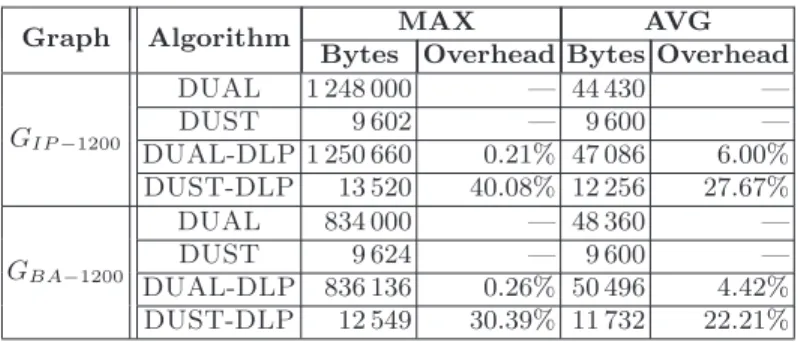
Documents relatifs
Let a transaction be initiated on one of the nodes, which changes the state of the data located in the database on the network nodes Participants in a transaction are
In this paper, we propose a distributed version of Fischer’s ap- proximation algorithm that computes a minimum weight spanning tree of de- gree at most b∆ ∗ + ⌈log b n⌉, for
We distributed a questionnaire which contained a set of questions divided into three axes: the quality of beverages and liquids consumed, promotion and advertising for the
Orchestrations et séparation des préoccupations Les orchestrations se présentent comme un ensemble de mécanismes pour la construction d’un nouveau service dit composite dans
Beide Länder weisen einen geringen Versorgungsgrad bei ausserhäuslichen Dienstleistungen für Kinder im Alter von bis drei Jahren auf, sind geprägt durch eine geringe
Pour simuler les gains de l’assureur pour un assuré choisi au hasard, tu vas utiliser le logiciel PyBlock disponible à cette adresse?. Tu auras en outre besoin des
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
An alternative approach to distributed optimization has been proposed in [8], [9], where the nodes exchange a small set of constraints at each iteration, and converge to a consensus
