3D Object-Oriented Learning: An End-to-end Transformation-Disentangled 3D Representation
Texte intégral
Figure
![Figure 1: Figure 2 of [1]. We use our formulation of Hierarchical Transformation of Coordinate Frames’](https://thumb-eu.123doks.com/thumbv2/123doknet/13802554.441213/4.918.147.763.282.747/figure-figure-use-formulation-hierarchical-transformation-coordinate-frames.webp)
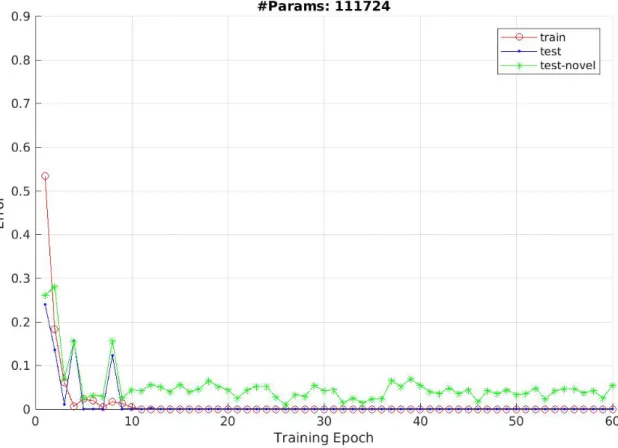
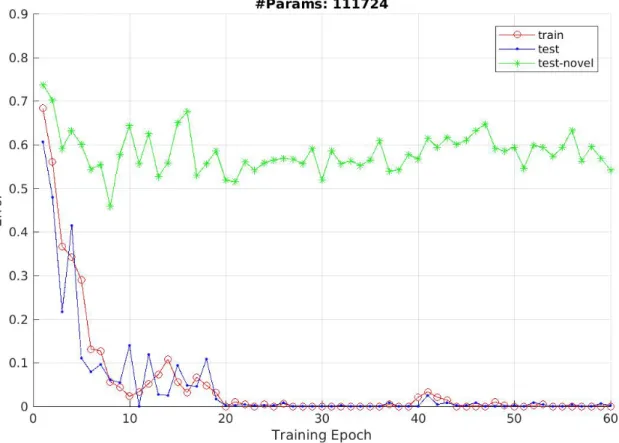
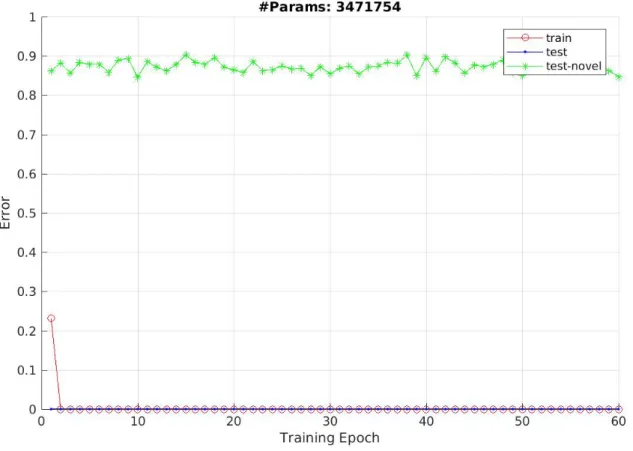
Documents relatifs
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
Despite their differences, all the studies that suggest a structural difference between the two types of DOs are built on the claim that in a neutral or unmarked word
The actual recognition is based on learning from examples: we represent all the images of a training set with respect to the vocabulary estimating the degree of similarity between
We decided to evaluate the performance of object classi- fication on LiDAR urban data with the use of the PointNet network. We then assume that each 3D points cloud contains one
● [ 5] PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation.
Composite laminate design is prone to complex optimization approaches (see [21]) because of the number and the mathematical diversity of parameters that can be changed: the material
The Equation class has several associations: an object belonging to one of the types derived from problem which is the problem of which the equation is a component, a Time scheme
Starting from a clean definition of what is a documentary database, we defined what is a subdatabase, the single type of our algebra and their operands which fit to
