A Detailed Analysis of the KDD CUP 99 Data Set
Texte intégral
Figure
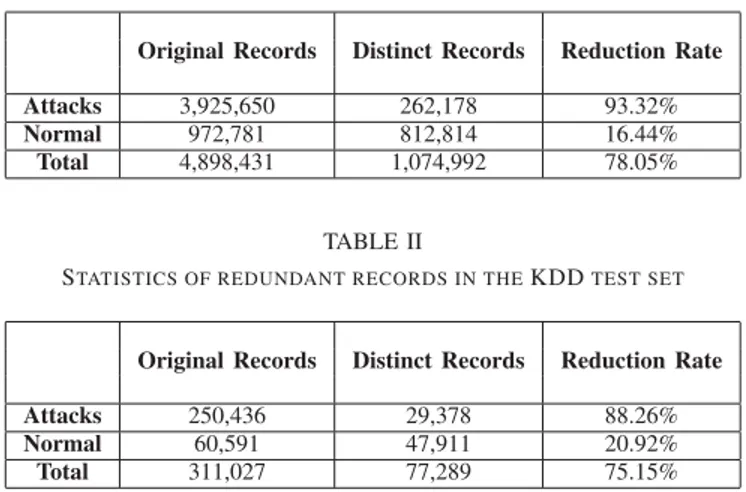
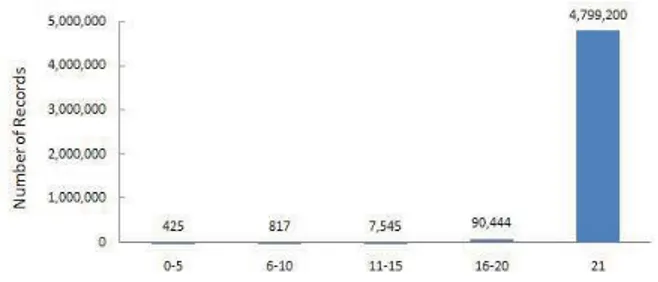
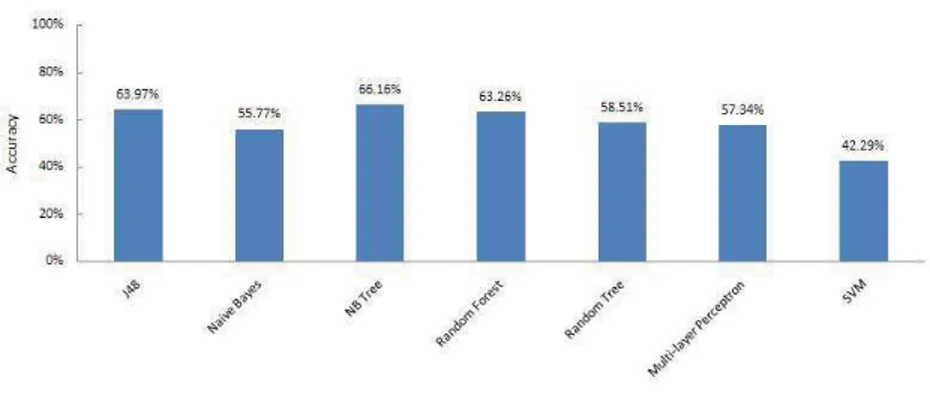
Documents relatifs
A travers cette étude, plusieurs microstructures et courbes de dureté ont été présentées, où nous avons montré les conditions des traitements thermomécaniques qui permettent
Stream clustering algorithms are typ- ically able to detect new clusters in real-time, and are thus good candidates for detecting the network attacks discussed in Section
Within the framework of mobility data analysis, there are several issues ranging from data enrichment, characterization of transportation supply and demand, prediction of short and
kernel function, number of neighbors L in the adjacency matrix, number of wavelet scales S, wavelet coefficients used in feature extraction for a given scale s (we are using only
Notes and details on the origin of the documents available for free download in this document database for the sustainable development of developing countries:.. The origin and
Our method allows the classification of brain tissues in healthy subjects, as well as the identification of atypical and thus potentially pathological tissues in the brain of newly
In the case of moderately high Froude / Reynolds numbers, the big buoyancy-driven structure opens the tip of the flame which is virtually pushed outside the computational domain
To provide a quantitative overview of decision-making abilities in obesity, we have conducted a systematic review and meta-analysis of studies comparing IGT
