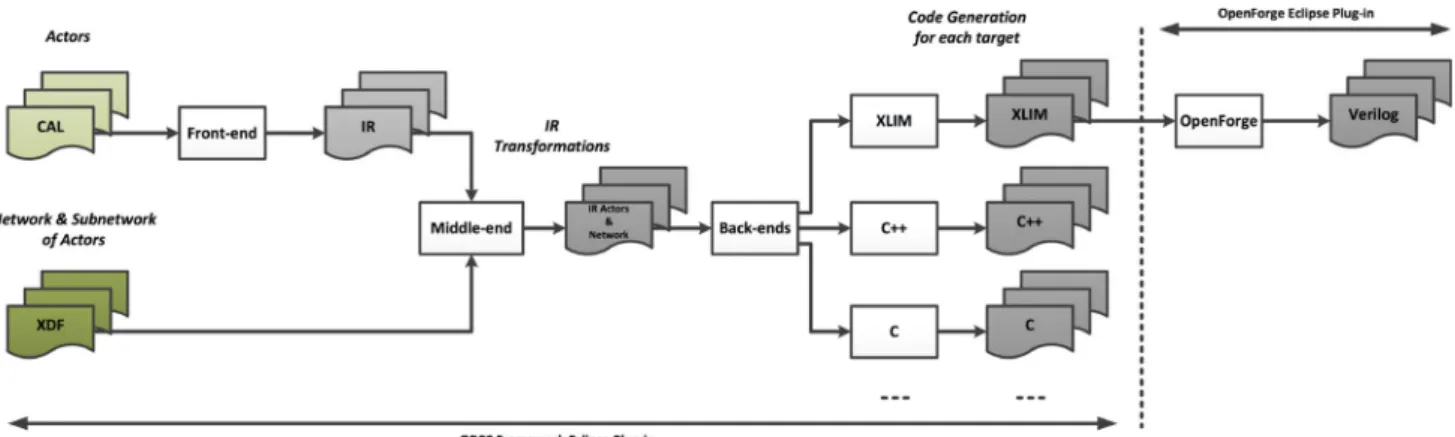
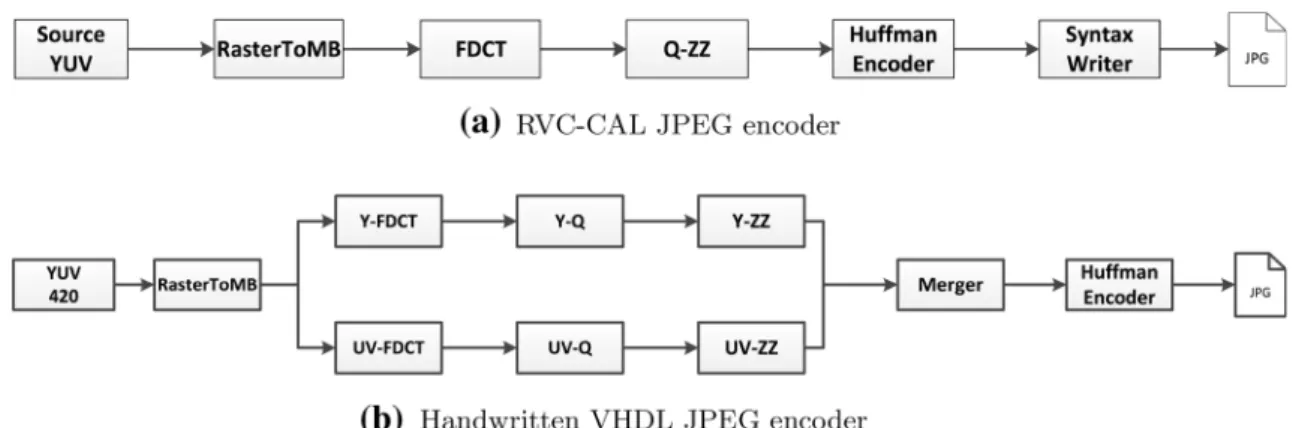
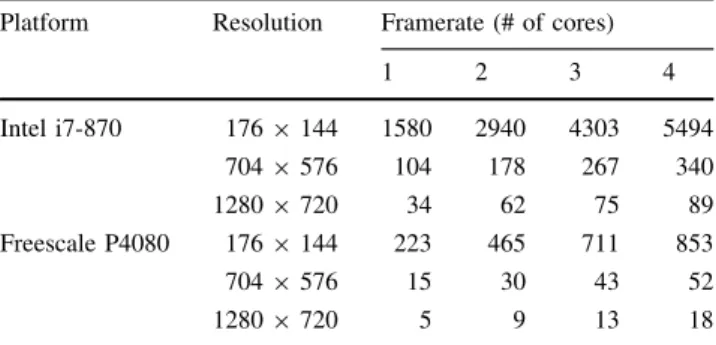
High-level dataflow design of signal processing systems for reconfigurable and multicore heterogeneous platforms
12
0
0
Texte intégral
Figure

Documents relatifs
