Bayesian sparse polynomial chaos expansion for global sensitivity analysis
Texte intégral
Figure

Documents relatifs
RESUME : Cet article propose une histoire « quantitative » de la pensée économique en France à travers l’histoire de la structure doctrinale du corps des Professeurs
This magnetic field is associated with the electric current originating from the connecting wires (connected to the current generator at the ground surface), the injection current on
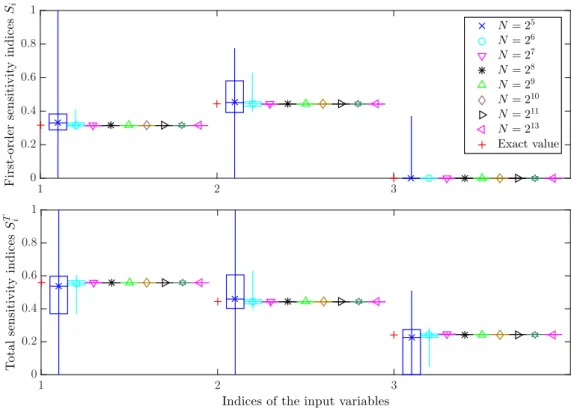
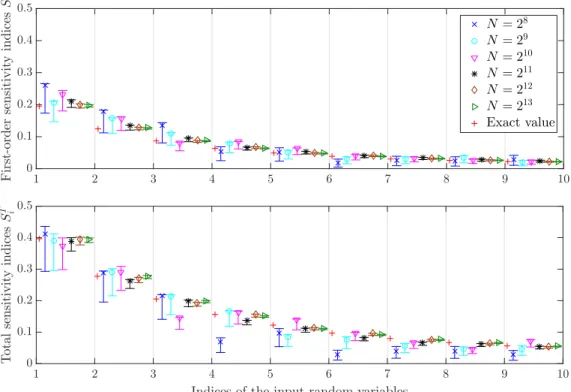
The PSI and the TSI are predicted quite well by the AFVB-PCE model using less number of significant terms in the polynomial basis as compared to the L-PCE model.. The PSI
Polynomial Chaos Expansion for Global Sensitivity Analysis applied to a model of radionuclide migration in randomly heterogeneous
Such assessment is possible using global sensitivity analysis, an approach able to analyze the variance of the output and determine the individual effects of each parameter
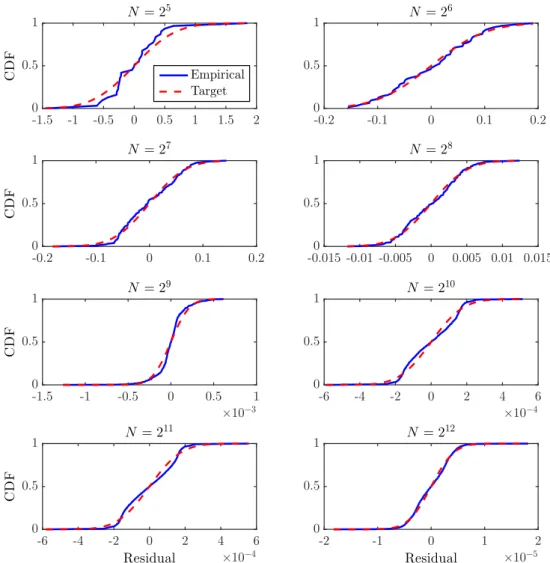
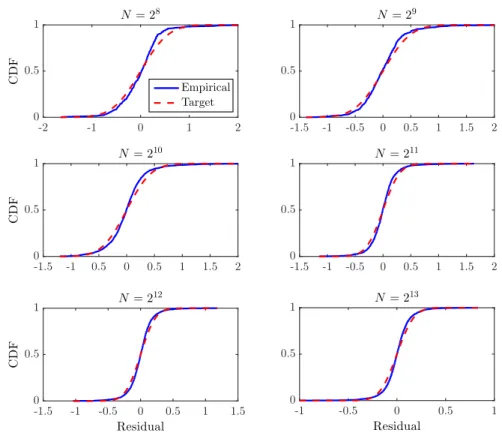
Generally, CDF can be estimated in three ways: (a) analytical calculation (b) standard MC sim- ulation (c) meta-model MC simulation –i.e., genera- tion of an experimental design of
In the following, the adaptive weight behavior of the adaptive algorithm (15), called non-negative LMS, is studied in the mean and mean-square senses for a time-invariant step size
Un large panel de gènes codant pour des protéines, de potentiels lincARN nouvellement prédits, mais aussi un nombre important d’éléments inter- géniques tels que des
