Defensive strategy models : application and predictive test
96
0
0
Texte intégral
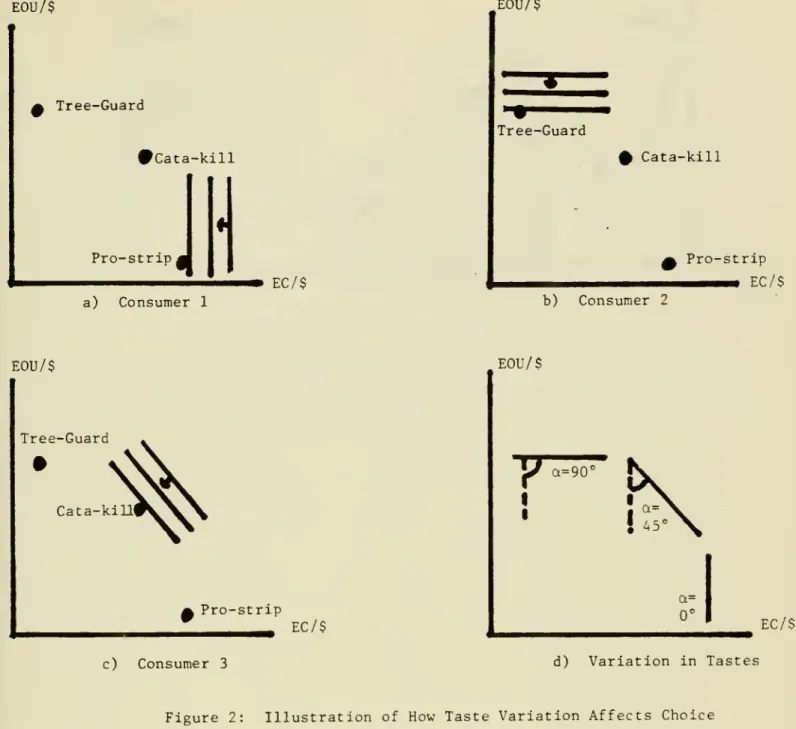
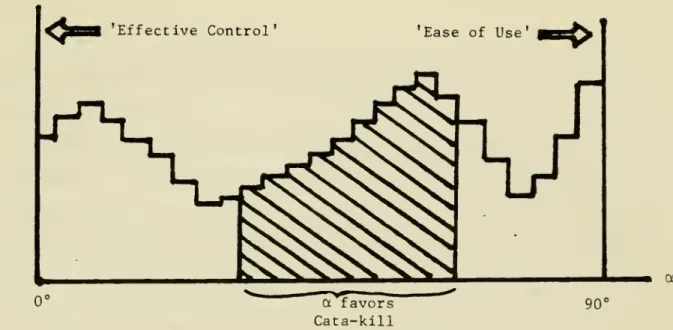
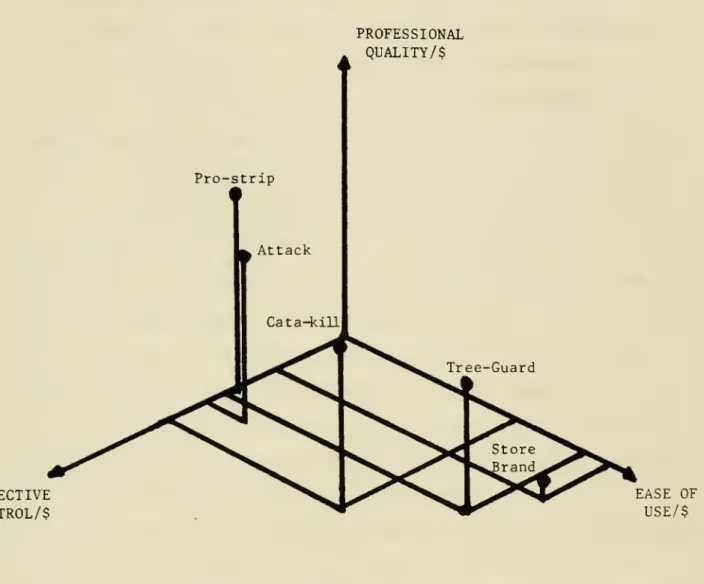
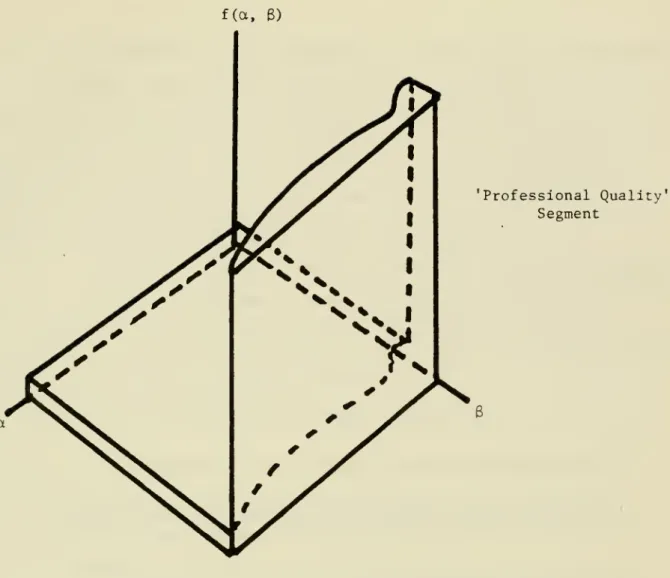
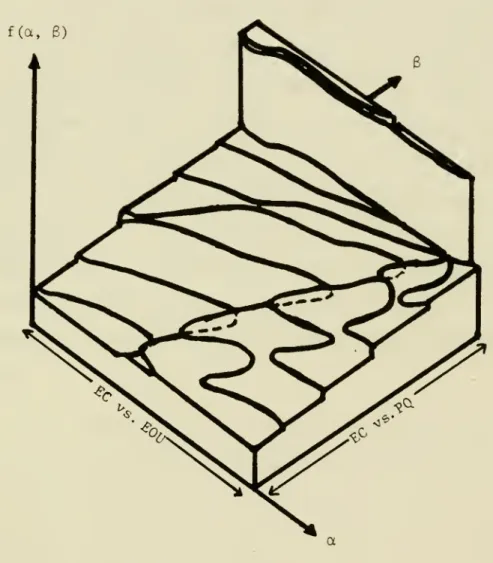
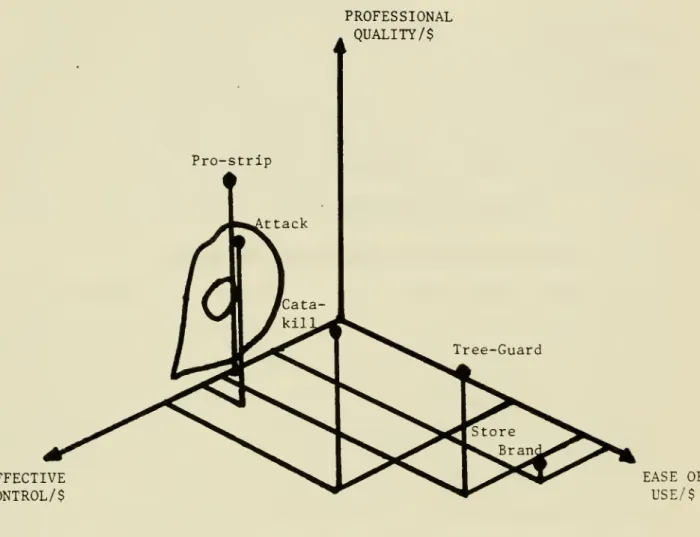
Figure

+4
Documents relatifs