Blockchain Abstract Data Type
Texte intégral
Figure
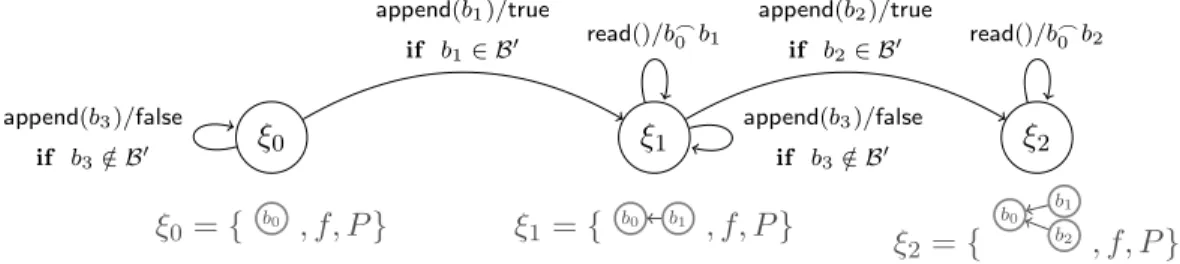
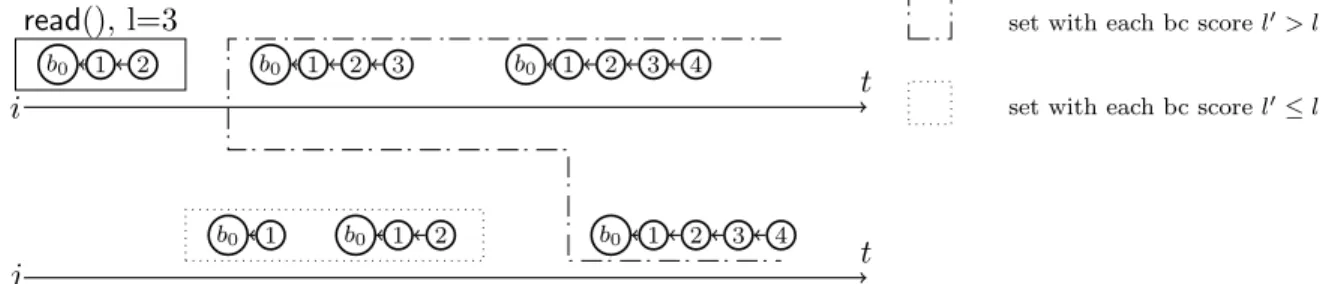
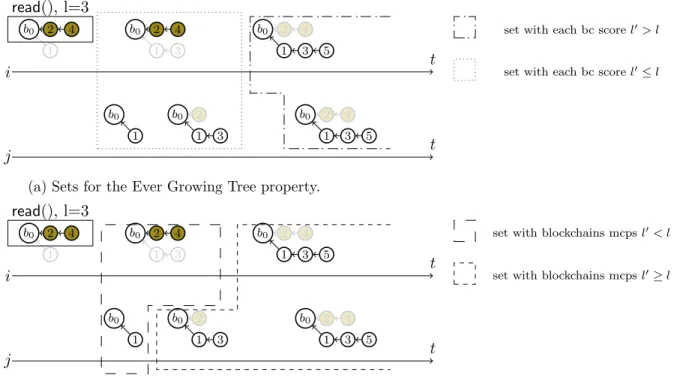
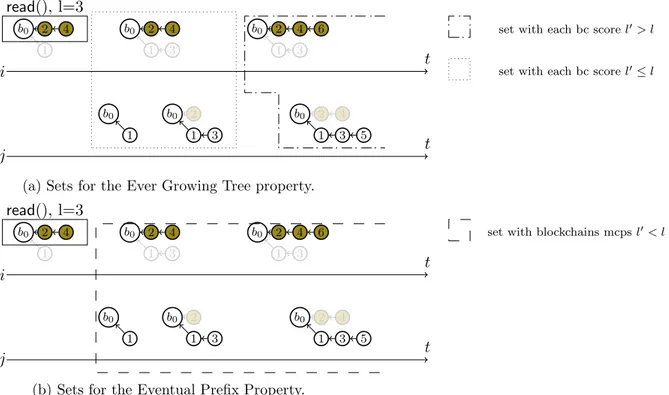

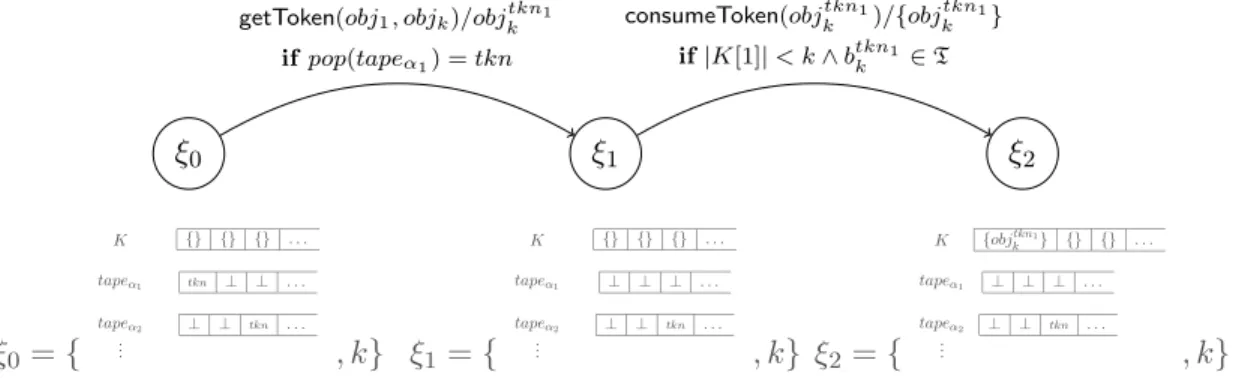
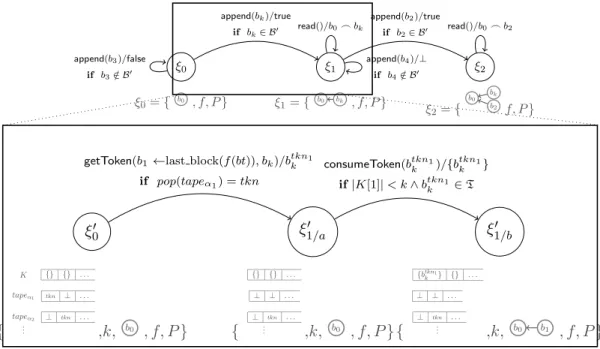
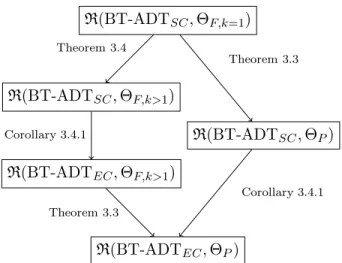


Documents relatifs
This paper focuses on the quality control of the Southern Ocean data from the Pacific sector which consisted of 29 cruises of which 17 were included in a previous synthesis
The proposed integrated index reflects the consistent (ideal) GDP structure inherent in the post-industrial economy, while the deviation of the values in the real
It is compared to logistic regression fitted by maximum likelihood (ignoring unlabeled data) and logistic regression with all labels known.. The former shows what has been gained
Finally, the seven amino acid extrahelical 3¢- ¯ap pocket mutant Fen1 (LQTKFSR) showed a similar altered cleavage pattern to the Fen1 (LTFR) mutant and with the
This is an important observation, because as (2) implies the Principal Principle, it gives us a hint how to construct in the sections below the extension Rédei and Gyenis re- quire
La modélisation par le modèle neuro-flou pour la relation pluie-débit à l’échelle journalière est prometteuse, et les résultats de simulation obtenus sur le sous
Azerbaijan; Conselho Nacional de Desenvolvimento Cient´ıfico e Tecnol´ogico (CNPq), Universidade Federal do Rio Grande do Sul (UFRGS), Financiadora de Estudos e Projetos (Finep)
Pfanzagl gave in [Pfa88, Pfa90] a proof of strong consistency of asymptotic max- imum likelihood estimators for nonparametric “concave models” with respect to the.. 1 The
