Collective Debate
BYAN YUAN
B.A. PHILOSOPHY
GEORGETOWN UNIVERSITY, 20II
SUBMITTED TO THE DEPARTMENT OF MEDIA ARTS AND SCIENCES IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF
MASTER OF SCIENCE IN MEDIA ARTS AND SCIENCES AT THE
MASSACHUSETTS INSTITUTE OF TECHNOLOGY JUNE 2018
@2oi8 - Massachusetts Institute of Technology. All rights reserved.
Signature redacted
Signature of Author:Program in Media Arts and Sciences
May, 2018
Signature redacted
Certified by:Deb Roy
Associate Professor, Program in Media Arts and Sciences
Accepted by: MASSACHUSETTS INSTITUTE OF TECHNOLOGY
JUN 27 2018
LIBRARIES
/4 Thesis SupervisorSignature
redacted---Tod Machover Academic Head, Program in Media Arts and SciencesMiTLibraries
77 Massachusetts Avenue Cambridge, MA 02139 http://Iibraries.mit.edu/ask
DISCLAIMER NOTICE
The pagination in this thesis reflects how it was delivered to the
Institute Archives and Special Collections.
The Table of Contents does not accurately represent the
page numbering.
Collective Debate
by
An Yuan
Submitted to The Department of Media Arts and Sciences on May 24, zo18
in partial fulfillment of the requirements for the degree of Master of Science in Media Arts and Sciences
ABSTRACT
Participating in online debate can expose people to diverse viewpoints, and thereby reduce polariza-tion of opinion over controversial issues. However a lot of online debate is hostile and further dividing -we need tools that facilitate meaningful back and forth discussion. For my thesis work I created such a tool in the form of an artificial agent that engages users in debate over controversial issues.
By engaging in debates with many users, the agent will start to gain insight into things like: what kinds of arguments do people find persuasive? Or, what can we predict about a person's argumentative behavior from their moral sense? Or, what is the characteristic debate path for someone who becomes persuaded to change his mind completely? The agent will then use what it has learned to help users on either side of an issue better understand each other by exposing them to compelling arguments from both sides.
To identify these arguments, the agent develops a model of the user that predicts which arguments the user will like. I measure the agent's performance given different models of the user. I then evaluate the performance of each model against the random agent, which does not attempt to model the user.
Thesis Supervisor: Deb Roy
Collective Debate
Ann Yuan
Submitted to the Program in Media Arts and Sciences, School of Architecture and
Plan-ning, on May
iz,2oi8 in partial fulfillment of the requirements for the degree of Master of
Science in Media Arts and Sciences at the Massachusetts Institute of Technology.
Signature redacted
Thesis Reader:
Fernanda Vidgas, Ph.D.
Research Scientist
Google Brain
Collective Debate
Ann Yuan
Submitted to the Program in Media Arts and Sciences, School of Architecture and Plan-ning, on May iz, zo18 in partial fulfillment of the requirements for the degree of Master of Science in Media Arts and Sciences at the Massachusetts Institute of Technology.
Signature redacted
Thesis Reader:
Iyad Rahwan, Ph.D.
Associate Professor of Media Arts and Sciences MIT Media Lab
Acknowledgments
Firstly I want to thank my advisor, Professor Deb Roy, for his invaluable mentorship over the last two years. From the beginning Deb has given me the freedom and support to learn and explore, for which I will always be tremendously grateful.
Thank you to my readers, Professor Iyad Rahwan and Dr. Fernanda Viegas, for their guidance over the last year. Their feedback and comments have improved the work immeasurably, and I am honored to have had their support.
Thank you to everyone at the Media Lab and especially to everyone in the Laboratory for Social Ma-chines and Cortico family for being consistently ridiculously helpful, for being my first and best friends in a new city, and for inspiring me to be better. Special thanks to Soroush Vosoughi and Sam Carliles for always being willing to sit with me to help me understand a technical concept I was struggling with, or to talk through the details of a new feature, or just to reassure me that I was on the right track. Our conversations kept me sane!
Contents
o
INTRODUCTION Io.1 Related Work: Psychological Foundations . . . . 4 o.2 Related Work: Formal Argumentation Theory . . . . 5 0.3 Related Work: Argument Mapping Tools . . . . 9
1
COLLECTIVE DEBATE I31.1 Seeding The Tool . . . . 14 1.2 The Experience . . . . 15
2 THE EXPERIMENT 20
2.1 T he A gents . . . . 21 2.2 The Reward Models . . . . 25
3 How USERS CHANGED
26
3-1 O verall R esults . . . . 27
3.2 Did The Experiments Have An Effect? . . . . 28
3-3 Did the moral cohorts respond differently? . . . . 38
4 MORAL MATRICES 47
4.1 The Self-Organizing Map . . . . 49
5 WHY Do PEOPLE CHANGE THEIR MINDS? 57
5.1 A Survey of Significant Chains . . . . 58
6 HOW THE AGENTS BEHAVED 65
6.1 Evaluating the Agents . . . . 66
6.z Agent Design versus Performance . . . .. 75 6.3 What Can We Learn From the Agents? . . . . 76
7 CONCLUSION 83
APPENDIX A APPENDIX 87
Listing of figures
The agreement / confidence space. Araucaria screenshot. . . . . Argumentation taxonomy. . . . Arguman screenshot. . . . . Kialo screenshot .. . . . . Hierarchical tree vs. forest. . . . .
1.1 Moral matrix text. . . . .
I.z Answering the central claim. . . . .
1-3
Reacting to a counterargument. . . . .1.4 Selecting a counterargument. . . . .
1.5 Submitting a new argument. . . . .
1.6 Reevaluating the central claim. . . . . 3.1 Where users fall. . . . .
3.2 Average agreement (pre
|
post debate): o.8z3.3 Average agreement (pre post debate): O.23 3.4 Average agreement (pre post debate): o.831
3.5 Average agreement (pre post debate): o.831
3.6 Average agreement (pre
|
post debate): o.8z3.7 Average agreement (pre
I
post debate): o.8z3.8 Average agreement (pre post debate): o.831
3.9 Where conservative users fall. . . . .
3.10 Average agreement (pre post debate): 0.90 3.11 Average agreement (pre post debate): o.19
3.12 Average agreement (pre
I
post debate): 0.72 3.13 Average agreement (pre|
post debate): o.zo3-14 Average agreement (pre
I
post debate): 0.793.15 Average agreement (pre
I
post debate): o.z64.1 Feature maps. . . . . 4.2 SOM colored by users' opinion of the centra
4.3 SOM with landmarks. . . . .
4.4 Training the SOM. . . . .
4.5 SOM visualized as a histogram. . . . .
. . . . 16 . . . . 17 . . . . . . . . 17 . . . . 18 . . . . . . . . . . 19 . . . . . . . . 19 . . . . 17 0.79 . . . . 34 0.27 . . . . 35 o.8z . . . . 36 o.82 . . . .. . 36 0.79 . . . . 37 0.77 . . . .. 37 0-78 . . . . 38 . . . . .. .. 39 o.86 . . . . 42 0-37 . . . . . .. .. . . . .. . .. . 43 o.67 . . . . 44 0.20 . . . . 44 0.78 . . . . 45 0.34 . . .. . . .. . . . . .. .. . 45 . . . . 50 1 claim . . . . 51 . . . . . . . . 52 . . . . 53 . . . . . . 54
4.6 SOM visualized as a histogram, colored by agreement with the central claim.
2 3 4 5 6 . 5 . 7 . 8 . 10 . 10 . 12 55
5.1 Supportive chain i.. . . . . 59
5.z Supportive chain z. . . . . 61
5-3 Opposing chain i. . . . 62
5.4 Opposing chain 2. . . . . 62
6.1 Argument histogram. . . . . 67
6.2 Success matrix for opposing arguments. . . . . 71
0
Introduction
Public opinion in America is divided over political and social issues. More and more, we get our news from online media platforms such as social networks which show us content confirming our preexist-ing beliefs'. Nicholas Negroponte prophesied this state of affairs in his book Bepreexist-ing Digital, where he
imagined a "Daily Me" -an alternative to traditional newspapers that would serve people highly per-sonalized digests of information designed to please them9. Since the 1995 publication of Being Digital, this fantasy has evolved along a familiar course. The first efforts towards building a personalized news-paper were marked by optimism for how the technology could improve our lives. Then the technology became pervasive and people started using it in ways that the original creators could never have imag-ined, sometimes with nasty results. A societal reckoning ensues.
Cass Sunstein, a legal scholar and former White House administrator, has been a vocal critic of over-personalized media diets". Sunstein argues that our Daily Me's shelter us from ideas that challenge our own, thereby exacerbating polarization in a harmful feedback cycle. He demonstrated how this can happen in a series of experiments where he asked groups of people with similar views to discuss an issue amongst themselves. Sunstein found that people emerged from such discussions with more extreme views than they started with -for example, a group of people who started out opposed to same-sex mar-riage left the discussion even more opposed to same-sex marmar-riage. This is because when people discuss an issue with others who share their opinion, they learn more reasons to hold that opinion. Sunstein argues that a version of this effect happens every time people log into their social media accounts.
People have wised up to this phenomenon. There is mounting public support for the idea that social networks should be held accountable for their role in creating the toxic media environment that we cur-rently inhabit. In fact, executives from several major social networks including Facebook and Twitter have recently been called to testify before Congress regarding the threat of coordinated misinformation campaigns on their platforms.
However, social networks also present an opportunity to alleviate polarization by exposing users to diverse viewpoints. Social networks have troves of data from activity on their platforms, which fuel rich models of user behavior. Instead of using these models to figure out what content users will like, platforms could optimize for other objectives, such as finding content that will cause users to appreciate views that are opposed to their own.
For my thesis I created such a platform: Collective Debate (collectivedebate.mit.edu). Collective De-bate is a website where users engage in deDe-bate with an artificial agent over a controversial issue. Upon arriving at the site, the user first completes a questionnaire that measures their moral sense. Then the user is presented with a controversial claim: that differences in professional outcomes between men and women are primarily the products of socialization and bias. The user indicates how strongly they agree or disagree with this claim on a scale of o (strongly disagree) to i (strongly agree). The agent assumes the opposite position, and then engages the user in a debate. Both parties choose from a library of approxi-mately izo arguments supporting and opposing the original claim. After the debate, the user is asked to
reevaluate their position with respect to the original claim.
To measure how much a user has changed their mind, I compare their valuations of the claim before and after the debate. A move in the direction opposite to their original position is considered a positive outcome. More precisely, I compute a score for each debate by subtracting the user's post-debate val-uation of the central claim from their pre-debate valval-uation. For example, if a user strongly agrees with the central claim before the debate, let's say by indicating their agreement to be o.9 out of i, but after the debate changes their agreement to be o.6 out of i, indicating only slight agreement, the final score for their debate would be +0.3, which is a positive outcome. I shall refer to this as a debate's moderating score.
If the user disagrees with the central claim before the debate (their pre-debate valuation of the claim was less than o.5), then I calculate the moderating score for their debate by subtracting their pre-debate valuation from their post-debate valuation. For example, if a user indicates their agreement with the central claim to be o.1 out of i before the debate, but after the debate changes their agreement to be
0.4 out of 1, the moderating score for their debate would also be +0.3. This way positive moderating
scores always indicate that the user has changed their mind after the debate, as opposed to holding their original position more strongly.
In the first phase of my experiment, the agent made arguments randomly. I used the data collected in this phase to create models that predict the chance of a user changing their mind after the debate, given a path of arguments. To use the terminology just introduced, I created models that predict the moder-ating score of each debate. I then designed a new set of argumentative agents that optimize for having debates with high moderating scores. These agents use the models developed from the first phase to inform their argument choices. In the second phase of my experiment, I measured the performance of these new agents against the random control in terms of moderating scores. Two of the new agents turned out to have larger moderating scores than the control, which means they were more effective at getting users to change their minds.
o.1
RELATED WORK: PSYCHOLOGICAL FOUNDATIONSCollective Debate takes inspiration from several lines of research in psychology and artificial intelli-gence. The first is psychologist Jonathan Haidt's moral foundations theory. In his book The Righteous
Mind, Haidt suggests that political differences stem from differences in how much importance we
as-sign to certain moral features when assessing right and wrong'. Haidt identifies five features that to-gether constitute our moral sense: compassion, fairness, loyalty, respect for authority, and preservation of sanctity. How a person weights these features determines their "moral matrix". According to Haidt, liberals and conservatives have characteristic moral matrices. For example, when liberals try to decide whether an action is right, they care a lot about whether people were harmed, but care very little about whether some standard of decency was violated. Conservatives, on the other hand, weight all five moral features equally. Haidt developed a questionnaire that can be used to measure someone's moral matrix. Users fill out this questionnaire when they arrive at Collective Debate. This data is used to build a user profile that helps the agent decide which arguments to make in the debate.
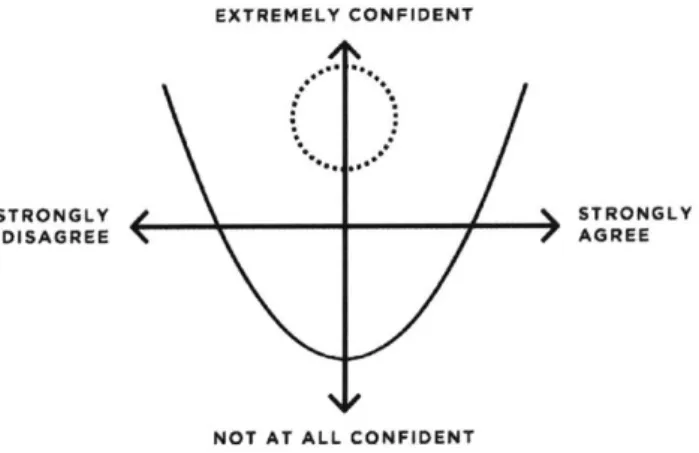
I also took inspiration from Dan Ariely's studies of persuasion in my experimental design. In his ex-periments Ariely asks people to indicate their level of agreement with a controversial moral claim, as well as their confidence in their position'. Ariely has found that while in general people's confidence in their position grows with the intensity of their agreement or disagreement, certain people hold moder-ate positions but are also highly confident about them. Further, he has found that these people play a crucial role in helping groups of people with conflicting views reach a consensus.
Ariely suggests that if someone is both moderate and confident in their position on an issue, that means they believe there are good reasons to both support and oppose it. In other words, they're able to see both sides. This struck me as a fitting optimization goal for Collective Debate: to help people appreciate both sides of the debate over sex differences versus professional outcomes.
EXTREMELY CONFIDENT
STRONGLY STRONGLY
DISAGREE AGREE
NOT AT ALL CONFIDENT
Figure i: This shows the space of agreement and confidence on which users' positions lie.
In the graph above, the curved line shows where users generally tend to fall: the stronger their opinion,
the more confident they are. The dotted circle indicates the region of confident moderation. This is
ideally where users would end up after the debate. Thus, the interface measures both users' agreement
with various arguments, and their level of confidence in their position.
Ultimately I decided to only optimize for changing users' agreement levels because I could not
af-ford to label debates in which a user became more moderate but also less confident as unsuccessful
-
I
did not have enough data. Nevertheless, the measurements I collected on both dimensions paint an
in-teresting picture of the psychology of persuasion, and I will review them throughout this document.
Perhaps the way to frame my optimization goal, then, is to help people question their own views on the
debate over sex differences versus professional outcomes. I interpret any movement the user makes after
the debate along the agreement dimension in the direction opposite to their original position,
regard-less of the direction of change in their confidence, as evidence that this questioning has occurred. This
is perhaps a weaker goal than helping people appreciate both sides of the debate, but I believe it is a step
in that direction.
0.2 RELATED WORK: FORMAL ARGUMENTATION THEORY
Collective Debate is heavily inspired by the field of formal argumentation
-
born out of a
1995paper
in which the logician Phan Minh Dung proposed a graphical framework for representing arguments
as nodes that are connected if one argument attacks the otherI. Dung's original framework has since
been extended in innumerable ways to accommodate more exotic taxonomies of arguments and inter-argument relationships. Researchers have hoped to use these frameworks to teach machines how to reason, and have even used them to build persuasion machines. The idea is that if we knew how to for-mally represent the belief structure behind different positions, we would be able to algorithmically in-fer what one needs to hear to be persuaded to see the other side.
Research in formal argumentation has traditionally proceeded along two tracks. The first is con-cerned with exploring the behavior of arguments as a formal system. These researchers treat arguments as symbolic structures to be manipulated like any other mathematical object, taking for granted the highly nontrivial translation step between naturally occurring discourse and symbolic representation. These researchers have studied how to efficiently compute logically consistent subsets of arguments given a graph of argument nodes and attack edges6, modeled argumentative dialogues as games and analyzed the computational complexity of finding ideal strategies7, and otherwise demonstrated the mathematical richness of the formal framework that Dung first laid out.
On the other hand, there are researchers who study naturally occurring arguments and try to fit them into formal models. The challenge with this approach is that where arguments occur naturally, like in online discussion forums, it can be hard even to know where one argument ends and another begins. Thus these researchers have devised new discussion tools like Araucaria that solicit arguments through rigid templates -for example, by asking users to instantiate premises and conclusions based on a predefined reasoning scheme2"4'3. For example, to make the argument that someone's contribu-tion should be disregarded because they lack authority on the topic under debate, one might instan-tiate an Argument From Authority, which in turn might instaninstan-tiate a Modus Ponens argument. This means the system must have prior knowledge of a significant number of reasoning schemes. The sys-tem must also understand how arguments formally relate to each other -so if this argument from au-thority is accepted, then the argument it attacks would be automatically rejected. Tools like Araucaria enable researchers to gather highly structured insights into how people reason about an issue. For ex-ample, Araucaria may tell you that a user disagrees with an argument's premise while agreeing with its conclusion, or that the user challenges whether a conclusion follows from a premise. To uncover such
nuance from online discussion forums would require highly sophisticated natural language processing, arguably beyond the reach of current methods.
7 Kraec Mia 11 0/7i77n iindr/r qof obiabpIiIty. aml 7
File /home/ mjs/ eclipse/ irc/ araucaria/ etc/ probability.ami read successfully.
Figure 2: This is a screenshot from Araucaria.
The challenge in creating a tool like Araucaria is defining an ontology of argumentation that cap-tures patterns in how we reason while remaining navigable to users. Below is a proposed taxonomy of argumentation'7:
file idif YIew labels Schemes AraucarlaO Help
I L .
Standard
r
Toulmin _ Wigmore The claim"Probability is the only correct representation for reasoning under uncertainty"
The claim is supported by
several distinct lines of
argument:
+1 Uncertainty must be
represented by some well-behaved measure
-2 We often cannot measure uncertainty, but still must act (Keynes)
+3 Medical and many everyday examples
+1 Measures that do not satisfy the probability axioms will be "incoherent*
+2 *Dutch book* and related arguments (Lindley et al) -3 Claim that all non-probabilistic formalisms are incoherent is overstated +4 "Natural" Delta arguments +4 Existence of "qualitative probability" theory
+1 Non-probabilistic methods are imprecise and therefore cannot work well
-2 There is a significant body of empirical evidence that they do (e.g. medicine)
-3 Theory is a stronger ggida --- ---.
PrsckeelResew"n AW.m AVOWNS"
from Prededa Ressarng Corqen
Agersedumgns
Agmnm~~stwW cashs4.Ru PomnsmVOaues Mp eritkowm F"as
E~pttO9ton
FWWRng Enlles
(Madusshi awn
Fg lt txn arguet
sCm" ein n.,Ruie"M CqMwe
soNAemner
F
7 1e7:ThsisDuga
propased Aalum' nyofArgumenftatISMIt's clear that such taxonomies can quickly become unwieldy. Increasing the resolution of the ontology enables a tool to faithfully represent argumentative patterns, but at the cost of being unnavigable. Per-haps this is why tools like Araucaria have not caught on -most online discussion still takes place within tools like Reddit that support free-form text entry.
With Collective Debate, I set out to design a compromise between the free-form online discussion forums that we are familiar with, and the arcane systems developed by the formal argumentation re-search community. Collective Debate is built around the most fundamental idea of formal
argumen-tation theory: that debates can be represented in terms of arguments and attack relations between
ar-guments. However the platform is more flexible than tools like Araucaria because it treats arguments as atomic. That is, Collective Debate does not attempt to formally represent the structure within an
argument such as its premises and conclusion. While the arguments are structurally simpler, they are imbued with social and moral metadata: Collective Debate tracks the performance of each argument on different users against their moral profiles.
Collective Debate provides a (mostly) fixed set of arguments out of which users and agents may con-struct their debates. On Collective Debate each debate has eight steps, and at each step the agent or user can make one of approximately 6o arguments. Thus each user is likely to have an entirely unique de-bate on the platform. Yet each unique dede-bate can be described in terms of arguments. Arguments are rather high-level units, especially compared to words -the typical units of natural language processing. Each argument represents a complete thought regarding the central claim. This makes it possible to mine the usage data on Collective Debate for insights regarding how people reason about their posi-tions, moving us closer to our goal of understanding why people believe what they believe, and what it would take to change someone's mind. By contrast, naturally occurring debates on sites like Reddit are completely unstructured. One can extract patterns in word usage from such data, but it is signifi-cantly more difficult to move up the abstraction ladder to uncover higher-level patterns that concern how people reason about their positions.
0.3 RELATED WORK: ARGUMENT MAPPING TOOLS
Finally, Collective Debate is inspired by existing debate mapping tools like Kialo (kialo.com) and Ar-guman (arAr-guman.org), which allow users to define arguments through free-form text entry, and whose notion of argumentative structure is restricted to attack edges between argument nodes. In these tools, users add nodes to a tree of arguments that support or oppose some root claim. Users can choose to directly support or oppose the root claim, or to target an argument elsewhere in the tree.
argaxnan Am it
a veaA diet lathe mosetvesny vable 0 4-rn nwV.-4 4-dbo am" NMW 00PUMMIOMMW -P-, TM-00M.9 fwlaf ~A"911 ftWW4dM.Wv# M -I fWdkW MWAO -4-. w rn.4d.W I fFyt" t. 24-N" Wuwmiydp**M *" so OWN"P v----lo &Wa AL4in~r -~ -U. WW."MvftwManpMa, Mv1MMW. do 00 Pamawk OWA.P . ftMWkQPM SONW.
Figure 4: This is a screenshot from Arguman.
DISCUSSION TOPOLOGY
at
/9
Figure 5: This is a screenshot from Kialo.
The problem with these tools is that it's not clear how a user would go about trying to absorb the gist
Uwe" vAku WPAMP ,am, M"'. NdWOA MMM Woeftw'. bv.WW Th-d- 400 0 .bpo- Vs"% O'know*ft
of a debate by navigating an argument tree. Trees can become extremely dense, and the interface does
not make it obvious which arguments the user should pay attention to
Another problem with this approach is that arguments don't fit neatly into trees. A response to one argument can often respond to several other arguments as well. Also, it's difficult to defend one hierar-chization over another. For example, consider this argument chain:
The
Central
Clair - CC: The White House lied about the crowd sizes at the inauguration.A
(oppose CC): Trump claimed he saw a crowd that looked like a million and a half people that wentall the way to the Washington Monument
B (support CC): Photos clearly show a larger crowd in 2009 compared to 2017
C (oppose CC): Spicer claimed that photographs of the inaugural proceedings were framed to
mini-mize the crowd size.
In Kialo, this chain might be represented by one of two trees:
1CC +--
A
<-B +-C 2.CC -- C B AThese trees give rise to very different interpretations of the status of the debate. Suppose we further attack argument A with argument D:
D (support CC): Trump had a low vantage point and that's why he perceived more people at the
inau-guration.
The trees are thus modified:
i. CC +- A <- (D and B (- C)
Under (i), even if D's attack is unsuccessful (because of some further argument E that undermines D), we would still have to prove that B is unsuccessful in order to accept A. However given the second or-dering, if D is unsuccessful, it appears that we have to reject B, since argument A is now unopposed and it challenges argument B. Even though Kialo and Arguman do not enforce these semantics, different orderings have a qualitative effect on our interpretation of the status of a debate, and these effects accu-mulate over the span of a tree.
Collective Debate attempts to address these issues by presenting arguments in a conversational in-terface. Rather than seeing the entire graph of arguments all at once, users see one argument at a time: they are presented with the central claim, then asked to provide a counterargument, then shown a re-sponse, etc. This means that users see only the parts of the debate most relevant to them. Also, instead of forcing arguments into a hierarchical tree, Collective Debate represents arguments more as a forest of trees (each with a height of one) through which a debate can more freely move.
(a) A hierarchical tree structure. (b) A forest of trees.
Figure 6: Nodes represent arguments and edges are drawn between arguments and their attackers.
On the left is a simplified sketch of the kind of hierarchical tree structure seen in debates on Arguman. On the right is a forest of trees, which shows how arguments are represented in Collective Debate. Ar-guments on one side support the central claim, while arAr-guments on the other side oppose it. An argu-ment from one side can attack any arguargu-ment from the other side.
1
Collective Debate
EVERY DEBATE that takes place on Collective Debate revolves around the same central claim:
Differences in professional outcomes between men and women are primarily the products of socialization and bias.
I built the first prototype of Collective Debate over the summer of 207, around the time that James
Damore released his infamous diversity memo (firedfortruth.com) at Google. Damore was a software engineer at Google who was frustrated with the company's diversity policy. Damore argued that Google's
bias alone, whereas Damore believes that differences in natural aptitude / interests also play a role. Damore was eventually fired. I chose to center Collective Debate around this issue because it is polit-ical but not straightforwardly so. In general, liberals disagree with Damore while conservatives agree with him, but upon closer inspection the dividing line isn't so clear -people seem also to be divided according to their scientific leanings, moral outlooks, etc. Most importantly it was clear that this issue provoked strong reactions in people, so I thought it should be easy to find users who would feel suffi-ciently strongly about the issue to use my tool.
1.1 SEEDING THE TOOL
Another reason I had for choosing the James Damore controversy as the central debate topic is that a large number of high-quality op-eds had been written on both sides of the issue, which I felt would make it easy to find arguments with which to seed the tool. The Heterodox Academy compiled a list (heterodoxacademy.org) of the pieces that they felt best represented the spectrum of opinions on the issue, and I mined each one for arguments.
I tried to find arguments that were self-contained, so that it would be possible for users to mix and match them in novel ways. Sometimes this was just a matter of changing the language, for example changing the argument "That doesn't make sense because X" to "The idea that men and women have different brains doesn't make sense because X". Other times this meant splitting an argument up into several subarguments so they would be more composable, for example splitting the argument "Men and women have different brains because X and Y" into "Men and women have different brains be-cause X" and "Men and women have different brains bebe-cause Y". At the end of this process, I ended up with sixty-eight supportive arguments and sixty-two opposing arguments.
I also seeded the attack graph between the arguments by manually evaluating pairs of supportive and opposing arguments and determining whether one responded to the other. It would have been diffi-cult to evaluate each pair, so I only considered whether each argument directly supported or opposed the central claim, and relied on my understanding of the argument space to create edges between argu-ments that I knew attacked one another. This meant reading through the arguargu-ments and creating edges
when new connections occurred to me, and repeating until most arguments had at least a few attackers. Obviously this process is not guaranteed to uncover all the potential attack edges between argu-ments. Therefore I added noise to the logic for surfacing argument choices for the user so that in ad-dition to seeing directly responsive arguments, the user would also see arguments that were not yet con-nected to the target argument in the attack graph. For example, if the user supports the central claim and it's their turn to make an argument against the agent, they are presented with a list of every sup-portive argument in the platform's library to choose from. Arguments that the platform knows directly
respond to the agent's last argument are more likely to appear earlier in the list, but every argument is included somewhere in the list. This way, a user might scroll down to an argument that the platform did not recognize as being responsive to the agent's argument, but that the user believes to be a perfect response. By discovering and reinforcing new paths, users gradually augment the attack graph.
1.2 THE EXPERIENCE
1.2.1
A
TEST OF MORAL FOUNDATIONSCollective Debate is a website available at collectivedebate.mit.edu. The site does not require login. When a user arrives on the site, they are first asked to complete a questionnaire that assesses their moral
WELCOME.
COLLECTIVE DEBATE Isatool
that tries to engage users in
constructive debate.
First, we'd like to get to know you a
little better. Please answer these
questions, and then we can start
the debate. +
These questions were devised by Jonathan Haidt and his team for YburhMrala.org - a site that collects data on moral sense.
QNestions / feedbacs
When you decide whether something is right or wrong, to what extent are the following considerations relevant to your thinking?
Whether or not someone suffered emotionally
Whether or not some people were treated differently than others
Whether or not someone's action showed love for his or her country
Whether or not someone showed a lack of respect for authority
Whether or not someone violated standards of purity and decency
Figure 1.1: This is the landing page for the site.
1.2.2 THE DEBATE
Once the user completes the moral matrix questionnaire, they can start the debate. The first step is for
the user to indicate their feeling toward the central claim of the debate, which is the following:
Differences in professional outcomes between men and women are primarily the products of
socialization and bias.
The user moves a slider to indicate how strongly they agree with this claim (from "strongly disagree"
to "strongly agree"), and how confident they are in their position (from "not at all confident" to
"ex-tremely confident").
THE CLAIM
In computer science, differences in professional outcomes between men and women are primarily the result of
socialization and bias.
I MODERATELY DISAGREE with this argument.
I am VERY CONFIDENT in my position.
Extrmely cont dent
dtrogly Strongly
disagree .sg'ae
Not at all coinfianet
The orange line sho.s ow user whtle morel matrices matched yourt tend to feel about this argument.
Figure
1.2:
The user indicates their feeling toward the central claim of the debate.After the user has declared their support for or opposition to the central claim, the debate proceeds
with the artificial agent assuming the opposite position. The artificial agent presents counterarguments
to the user's position on the left, while the user registers their reaction to these counterarguments on the
right:
* COUNTERPOINT
Gender identity is a social construct -it's incoherent to assume men and women have different innate
interests.
YOUR REACTION
Extremely confident
Strongly Strongly
dsagree agree
Not at all confioent
The orange line shows how users whose moral matrices matched yours tend to feel about this argument.
Figure
1-3:
The user indicates their feeling toward the agent's arguments.The user can also select a response to the artificial agent's counterpoints from a menu of options:
4
COUNTERPOINT 0 RESPONSESGender identity is a social construct -it's incoherent
to assume men and women have different innate Gender identity is a social construct, gender is not. Men and women do
interests. have different innate interests due to having different biology though
the differences are small.
2.-Most psychologists believe that prenatal and early postnatal exposure to hormones such as testosterone and other androgens affect psychology. In humans, testosterone is elevated in males from about weeks eight to 24 of gestation and also during early postnatal development.
co-2.
Blank slate gender feminism is advocacy rather than science: no gender feminist has ever been able to give a coherent answer to the
1'
If the user does not see an option they like, they can submit a new argument:
NEW ARGUMENT
Your submission won't be immediately available, but it will improve our argument selection in future versions of this tool.
Explain yout argument
hele-IOURCR (OPTIONAL)
l, UI, nht
Urter text to dnlay hs
Figure 1.5: The user submits a new argument.
Out of approximately 5,5oo debates completed, fifty-eight arguments were submitted through this
form, of which I added twenty-three to the tool.
The user and the agent go back and forth like this for eight steps. Finally, the user is asked to
reevalu-ate their position on the central claim:
PLEASE REEVALUATE THIS CLAIM:
In computer science, differences in professional outcomes between men and women are primarily the result of socialization and bias.
I SLIGHTLY AGREE wIth this argument.
I am SOMEWHAT CONPIDENT in my posto
Ext01141-y Confidant
ta 'nn. costae t
No, At all c-ld S
Figure 1.6: The user reevaluates their position on the central claim.
As explained in the introduction, I obtain a moderating score for each debate by comparing users'
valu-ations of the central claim before and after the debate.
2
The Experiment
THE EXPERIMENTAL QUESTION of my thesis is the following: What would it take to get someone to change their mind on the issue of sex differences and professional outcomes?
In order to answer this question, I collected data on the paths that users took through the argument tree on Collective Debate, and attempted to determine what is special about the paths with positive moderating scores. These are the paths that led users to either become more moderate in their posi-tion (e.g. to go from "strongly agree" to "moderately agree"), or to change their mind on the issue com-pletely.
which argument to make by randomly sampling from the set of arguments that respond to the user's previous argument. The data gathered by the random agent serves as the experimental control. With this data, I built a series of predictive models of user behavior: how users will react to different argu-ments, which counterarguments they are likely to pose, and which paths through the argument tree are likely to lead users to change their mind. In the next phase of data-collection, I began to randomly assign users to debate one of several agents that decide which argument to make with input from these predictive models.
2.1 THE AGENTS
I tested four different agents in total. The agents are each trained to optimize for producing debates with high moderating scores.
The debate itself is modeled as a Markov decision process (MDP) in which the agent (decision-maker) must choose which argument to make given observations of a user's state of mind. More for-mally, the MDP mapping is as follows:
Actions: When it's the agent's turn in the debate, it must choose which argument (action) to make.
Reward: The reward signal comes from the user's re-evaluation of the central claim at the end of the
debate. If the user re-evaluates the central claim to become less extreme compared to his original position (e.g. goes from "strongly agree" to "moderately agree" or from "strongly disagree" to "slightly agree"), that produces a high moderating score, which equates to a positive reward.
State: The state is the user's evaluation of all the arguments available in Collective Debate (what I
re-ferred to above as the user's "state of mind").
Transition
dynarnics:
Whenever the user hears a new argument from the agent, that argument and theuser's evaluation of it are added to the state.
There are many other approaches to solving MDP's. Classical approaches such as value iteration en-tail considering every potential path from every potential action, given a model of how to update state
and compute rewards. The problem with such analytical approaches is that they can quickly become computationally unwieldly. In my case, it would be difficult to precisely model the state transition dy-namics because the state space is infinite (users' reactions to arguments are real-valued between o and i). In addition, the number of potential paths to evaluate grows exponentially with the number of steps in the debate.
Given these considerations, I decided to take a more numerical approach to solving the MDP. At each turn, the agents in Collective Debate solve the MDP by performing a Monte Carlo search over po-tential paths through the argument tree and selecting the argument that tends to have the best results. For example, in one iteration the agent might consider the possibility of selecting argument A. The agent simulates how the debate would unfold starting from argument A by predicting which counter-argument B the user will pose to A, then itself responding to B, and so on until a complete debate path has been constructed. The agent then computes the reward for this path by passing it and the user's moral matrix to a classifier that predicts whether the user will become more moderate. The agent makes note of this outcome for argument A, and repeats the process many more times, making different argu-ment choices with each iteration, all the while accumulating data on how each choice tends to perform. Finally, the agent selects the argument with the best average performance across simulations.
This approach to solving MDP's is modelled after the Partially Observable Monte Carlo Planning (POMCP) algorithm". The details of my implementation are as follows:
function simulate(node, history, depth) { if(depth > maxDepth) return 0
if(node.isLeaf) { expand(node)
return rollout(node) }
let action = argmax(ucb(node), node.getResponsiveOptionso)
let { observation, reward, reaction } = generator(action, history) let newHistory = history.concat({ observation, reaction })
node.numberOfVisits++ action.numberOfVisits++
action.value += (totalReward - action.value) / action.numberOfVisits
return totalReward
}
function ucb(node) { return function(action) {
return c * sqrt(log(node.numberOfVisits) / action.numberOfVisits)
} } function expand(node) { agentArguments.forEach((arg) => { child = node.addChild(arg) userArguments.forEach((userArg) => { child.addChild(userArg) })
function rollout(node, history, depth) {
if(depth > maxDepth) return 0
let action = randomSample(node.getResponsiveOptionso)
let { observation, reward, reaction } = generator(action, history)
let newHistory = history.concat({ observation, reaction })
return reward + discount * rollout(observation, newHistory, depth + 1)
}
function generator(action, history) {
return getUserReactionAndReward(action, history)
}
-Am-At each turn, the agent considers approximately thirty argument choices (there are approximately sixty arguments supporting and opposing the central claim in the entire argument library, but only a subset of them will be responsive to any given preceding argument). The agent runs z,ooo simulations be-fore selecting an argument. The exploration parameter c in the ucb function is set to Z, and the
discount
parameter is set to o.5. The maxDepth is set to 8, which is the maximum length of a debate. In con-structing the simulated path in the rollout, the agent chooses arguments randomly (from within the set of responsive arguments), and uses a predictive model to generate the users' reactions and counter-arguments. The reward is determined at the end of each simulation by passing the complete path to a classifier. The reward is +i if the classifier determines that the path will lead the user to become more moderate, and -i if the classifier determines that the path will lead the user to become more extreme.
The four agents differ in the models they use to predict the users' reactions, counterarguments, and final reward. I developed two models for predicting the users' reactions and counterarguments:
Reaction model
A:
Samples from the distribution of reactions / counterarguments constructed fromobservations of past users whose moral matrices align with the current user.
Reaction model
B:
Samples from the distribution of reactions / counterarguments constructed fromobservations of all past users.
I also developed two models for predicting the final reward (whether the user will become more moder-ate):
Reward model
A:
Feeds the debate path and the users' moral matrix through a logistic regressionclas-sifier.
Reward model
B:
Feeds the debate path and the users' moral matrix through a random forest classifier.The four agents employ every possible combination of these models:
Agent I: Uses reaction model A and reward model A.
Agent
3: Uses reaction model A and reward model B.Agent 4:
Uses reaction model B and reward model B.There is also a control agent (agent o) that simply randomly samples from the set of responsive argu-ments at every turn. Once the agents were deployed, they were not retrained based on new data.
z.z THE REWARD MODELS
The features for both reward models included the user's moral matrix, and their valuations of every argument in the agent's arsenal. For arguments that the user did not encounter, I used the mean valua-tion across all users. I did not include features to describe the order in which arguments were encoun-tered.
For the logistic regression classifier, I trained a built-in model available through Scikit Learn, with an inverse regularization strength of ioo. The model was able to predict with 65% accuracy whether paths in a test dataset led the user to become more extreme or more moderate. For the random forest classifier, I again used a built-in model available through Scikit Learn, with ioo estimators, a maximum depth of zo, and a minimum sample split of z. This model achieved a prediction accuracy of 67%.
3
How Users Changed
TO RECAP, MY RESEARCH AIM is to better understand how people justify their opinions, and what it
would take to change their minds. In order to answer these questions, I needed to observe people dis-cussing their opinions. Rather than mine arguments from messy, naturally occurring discussions, I cre-ated an argumentative platform -Collective Debate -wherein people debate a topic using arguments designed to have certain desirable properties. Each argument in Collective Debate makes a distinct point, whereas arguments in online debates often repeat each other. Arguments in Collective Debate are also composable and self-contained, whereas those extracted from online debates can lack crucial context.
From November 2017 to March zo18, I collected approximately i2,ooo responses to the moral matrix
questionnaire, and approximately
5,5oo
completed debates. 4,000 of these were collected before Febru-ary ioth, which is when I deployed the experimental agents. The remaining debates were randomly assigned to one of the agents.Again, the central claim of every debate on my platform is the following:
Differences in professional outcomes between men and women are primarily the products of socialization and bias.
3.1 OVERALL R.ESULTS
The visualizations below show the performance of the control condition:
4(000
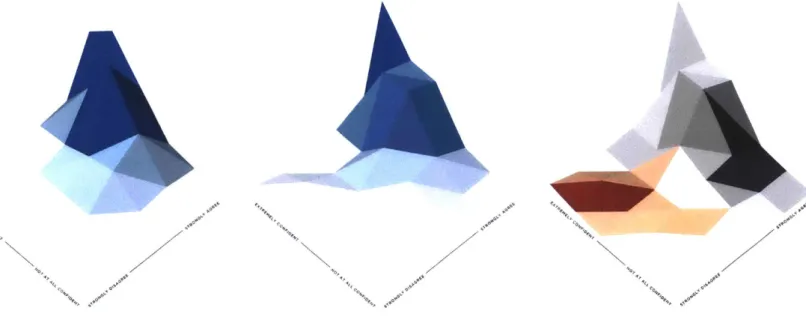
Figure 3.i: These histograms show where users are distributed in the agreement / confidence space.
In the histograms above, the axis on the left represents the confidence space. The closer users are to the upper left boundary, the more confident they are in their position, and the closer they are to the lower right boundary, the less confident they are. The axis on the right represents the agreement space. The closer users are to the upper right boundary, the more they agree with the central claim, and the closer
Height reflects density. The first histogram shows where users lie before the debate, the second his-togram shows where users lie after the debate. In the first two hishis-tograms saturation also reflects den-sity: the darker the blue, the denser the distribution. The second and third histograms show the same distribution, but the third histogram is colored to reflect the difference between the first two distribu-tions. Orange indicates that a region grew after the debate, gray indicates that a region shrank. Each triangular facet is colored according to the average value across its three points. Interactive versions of these visualizations are available at collectivedebate.mit.edu/results/distribution.
In general, I will be showing histograms segmented by the initial position of the user, whether sup-portive or opposing. For opposing users, I will flip the agreement axis. This way the most extreme users are always represented in the upper corner of the distribution. The qualitative sign of a successful set of debates is that the final histogram shows a prevalence of orange facets in the center (which indicates an increased number of moderates), and a prevalence of gray facets in the upper corner (which indicates a decreased number of users with extreme views).
While some users in the control condition do become more moderate after the debate (the facets in the middle of the third histogram above are orange), it's apparent that users also move towards the extremes (the facets in the strong agreement / disagreement regions are also orange). Approximately
13% of users either become more moderate or change their minds completely, while approximately iz%
of users become more extreme. This is the baseline against which I will compare the performance of the experimental agents.
3.2 DID THE EXPERIMENTS HAVE AN EFFECT?
To determine whether any of the experiments had an effect, I will regress the initially supportive users' post-debate agreement levels against the experimental condition to which they were assigned, and their initial agreement levels:
Supportive Coefficient P-value
Supportive Coefficient P-value EC [T.i] -0.0090
o.6z
EC [T.2] -o.oz8 o.n EC [T-3]
-0-045 *0.003 EC [T.4]
-0.041 *0.020 Before 0.75 *0.00The astericks (*) denote valuea that are statistically significant (< 0.05).
The four experimental conditions plus the control condition were dummy-encoded into four binary variables: T.i through T.4 above. The control condition is the reference category against which the
other experimental conditions are measured.
It looks like one's pre-debate agreement level (labelled "Before" in the table above) has a statistically significant correlation with his final agreement level. The results also indicate that each of the experi-mental conditions had a negative correlation with users' final agreement levels compared to the control (which means they are associated with the users becoming more moderate). The coefficients for
experi-mental conditions 3 and 4 were statistically significant.
Here is the same analysis for initially opposing users:
Opposing Coefficient P-value
Intercept 0.14 *0.00 EC [T.i] 0.040
0.36
EC [T.z] 0.034 0-43 EC [T-3] 0.0022 0.95 EC [T.4]
-0.020 o.67 Before 0-54 *0.00These results indicate that though the experimental conditions 1-3 had a positive effect on users' final agreement levels compared to the control (which means they are associated with the user becoming more moderate), the effect was not statistically significant for any condition.
Now I shall consider the effects of each experimental condition in more detail, starting by comparing the agreement / confidence levels among initially supportive users before versus after the debate. Users' agreement / confidence levels range from o ("strongly disagree" / "not at all confident") to i ("strongly agree" / "extremely confident").
Agreement (Before / After)
0.83/0.82 0.83/0.82 o.82 / 0.79 o.82 / 0.77 0.83 / 0.78 o.82 / 0.79
Confidence (Before / After)
0.75
/
0.76 0.75/
0.77 0.72 / 0.73 0.73/
0-74 0.74/
0.77 0.74/
0-75Here are the average levels among initially opposing users:
Opposing Agreement (Before / After) Confidence (Before / After)
Control 0.23
/
0.25 0.33/
0-45Agent i 0.21
/
o.29 0.34/
0-43Agent z 0.22 / o.29 0.39 / 0-54
Agent 3 0.25 / O.28 0.32 / 0.44
Agent 4 O.25
/
O.25 0.35/
0.48Total 0.23
/
0.27 0.34/
0-47These tables show that the average agreement levels among initially supportive and initially opposing Supportive Control Agent i Agent 2 Agent 3 Agent 4 Total
users before the debate are approximately equidistant from o.5 ("moderately agree" and "moderately disagree", respectively). However it is interesting that the initially supportive users are much more con-fident in their position (0.74, or "very concon-fident") than the initially opposing users (0.33, or "not very confident"). This discrepancy in confidence levels did not appear to translate into greater suggestibility: both initially supportive and initially opposing users changed their agreement level by approximately the same amount after the debate. In both cases, and for all agents, users generally became more moder-ate after the debmoder-ate.
To determine the statistical significance of this finding, I shall conduct paired t-tests on users' agree-ment / confidence levels before versus after the debate. The paired t-test determines whether a treat-ment had an effect on the population by comparing snapshots of the population before and after the treatment. In my case, the first set of observations is a users' agreement / confidence level before the de-bate, and the second set of observations is their agreement / confidence level after the debate. Here are the p-values from those tests conducted on initially supportive users:
Supportive Agreement Confidence
Control 0.46 0.27 Agent i 0.15 *0.010 Agent z *0.013 O.22 Agent 3 *7.20e-o6 0.51 Agent 4 *0.0014 *o.oo62 Overall *I.I3e-09 *0.00078
Here are the results from the same analysis conducted on initially opposing users:
Opposing Agreement Confidence
Control 0.39 *4.24e-05
Opposing Agreement Confidence
Agent z o.o8o *6.57e-o6
Agent 3 0.29 * 3.o9e-o8
Agent 4 o.88 *6.i5e-06
Overall *0.0041 *4.89e-24
The results from the t-tests indicate that for several agents, the difference between users' before and after agreement / confidence levels is statistically significant. Among initially supportive users, the dif-ferences between the before and after agreement levels for users assigned to agents z through 4 were statistically significant, and the differences between the before and after confidence levels for those as-signed to agents i and 4 were statistically significant. Among initially opposing users, the difference between the before and after agreement levels for users assigned to agent i was statistically significant, and the differences between the before and after confidence levels were statistically significant for every experimental condition. These results echo the findings from the regression analysis conducted earlier. Of course if the users in the different experimental conditions were different to begin with, then we cannot readily attribute the users' becoming more moderate to the activities of the agents. To rule this out, I must confirm that users did not significantly differ in their pre-debate agreement / confidence levels, which is what one would expect if a sufficient number of users were indeed randomly assigned to the different agents. I shall confirm this by conducting an ANOVA test on the mean pre-debate agree-ment / confidence levels of users in the different experiagree-mental conditions. The ANOVA test detects differences between groups.
Pre-debate Supportive Opposing
Agreement (F value / P value) 0.43 / 0-79 o.6z / o.64 Confidence (F value / P value) 1.59 / o.i8 2.70 / *0.042
Indeed, the results indicate that the differences between the groups' mean agreement levels prior to the debate are not statistically significant. However it looks like their mean confidence levels for initially opposing users are significantly different, perhaps in part owing to the much smaller sample size of such users. This means I must be very careful when interpreting the agents' effects on initially opposing users' confidence levels.
If the earlier analysis purporting to demonstrate the effect of certain agents on users' post-debate agreement / confidence levels is sound, then one should expect an ANOVA test of the mean agreement / confidence levels of users post-debate to yield statistically significant differences.
Post-debate Supportive Opposing
Agreement (F value / P value) 2.87 / *0.017 0.31 / o.87 Confidence (F value / P value) 2.67 / *0.031 1.96 / o.10
Indeed, for initially supportive users, the differences between the experimental groups' post-debate agreement and confidence levels are statistically significant. This suggests that for those users, the ex-perimental group to which one is assigned matters in determining whether and to what extent he will change his mind about the central claim after the debate. This is not true of initially opposing users.
According to the preceding analysis of mean agreement levels before versus after the debate, users in every experimental group became more moderate after the debate. But this is not the whole story. The means do not tell us whether all users shifted to become more moderate, or whether there is actually a cohort of users who become more extreme after the debate but whose activity is overshadowed by the users who become more moderate, or something in between. Therefore I shall consider the distribu-tions across the agreement / confidence space for a more granular look at the effects of each experiment.
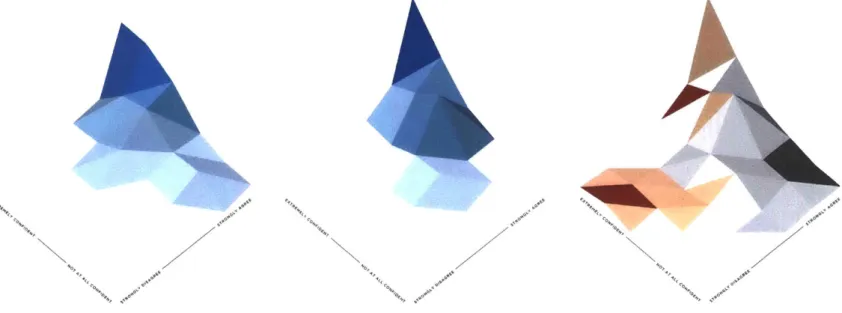
Here are the before and after distributions for all initially supportive users (the third column is the after distribution colored by distance from the before distribution):
A 7
140
,1V
4,
Figure 3.2: Average agreement (pre
I
post debate): o.82 0.79Initially supportive users' agreement levels went from o.82 before the debate to 0.79 after the debate, for a moderating score of +o.o3. Again, the distributions in the first two columns are colored by den-sity: darker blue means higher density. For distributions in the third column, orange facets reflect in-creased distribution after the debate (darker orange means larger increase), while black facets reflect decreased distribution (blacker means larger decrease). Orange facets in the upper corner indicate that users became more extreme, while orange facets in the middle and along the lower edge indicate that users became more moderate.
Here are the distributions for initially opposing users (the agreement axis is flipped for easier com-parison):
A
44 44 4, 4 4-44% 'A 44~ 'N A' "I \ A'LNFigure 3-3: Average agreement (pre
I
post debate): 0.23 1 0.27The moderating score for this set of debates is +0.04. It's clear from the preceding sets of histograms that the modest moderating effects for both initially supportive and opposing users are the result of averaging the movements of significant numbers of users becoming more moderate as well as more extreme after the debate. In the remainder of this chapter, I will attempt to demonstrate that whether a user becomes more moderate as opposed to more extreme appears to be at least in part a function of the experimental condition to which they were assigned, and their moral cohort.
So let us now take a closer look at the different experimental conditions. I will focus on the initially supportive users because, as mentioned, the experimental conditions did not have a statistically signif-icant impact on initially opposing users. Here are the distributions for initially supportive users in the control condition:
K
XX
. AM
-4
4.
'p
Figure 3.4: Average agreement (pre I post debate): o.83 I o.82
The moderating score for these debates is +0.01. While the average agreement level barely changed after the debate, there was nevertheless some movement towards both the middle and the extremes, perhaps cancelling each other out.
Here are the distributions for initially supportive users assigned to agent i: L -44 4-4 -4 '-44' -4 'p
Figure 3.5: Average agreement (pre
I
post debate):o.83
1 o.82The moderating score for these debates is also +o.oi. Consistent with the results from the paired t-test, it appears that these users did not change their positions much after the debate.
'-4-4
Here are the distributions for initially supportive users assigned to agent z:
4e
'0
.4.
Figure 3.6: Average agreement (pre
I
post debate): o.8z 0.79The moderating score for these debates is +0.03. It looks like agent z managed to decrease the average agreement level without causing too many users to become more extreme, as indicated by the lack of orange facets in the upper corner of the distribution.
Here are the distributions for initially supportive users assigned to agent 3:
#4
Figure 3-7: Average agreement (pre
I
post debate): o.82| O.774.1
4.h
The moderating score for these debates is +0.05. It appears that this is primarily due to users becoming