Parallel Implementation of Interval Matrix Multiplication
Texte intégral
Figure

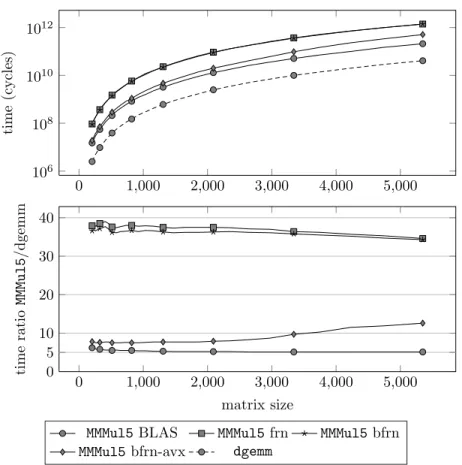
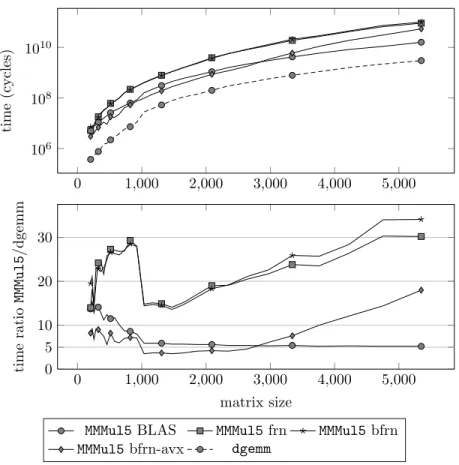

Documents relatifs
Nos préoccupations sur la science et l’homme sont les raisons principales qui nous poussé à choisir cet axe de travail scientifique et faire découvrir des
More precisely, we provide sharp conditions on the network architecture and the sample under which the error on the parameters defining the network scales linearly with
stéroïdes sexuels et des marqueurs du remodelage osseux chez une population d’hommes marocains âgés de plus de 50 ans, de décrire les variations de la SHBG
Nos résultats sont en partie en accord avec la modélisation de la santé mentale des étudiants allemands, ainsi on trouve que le stress est corrélé positivement
Dans le quatrième chapitre, nous avons étudié les propriétés structurales, électroniques, optiques des composés binaires ZnO, ZnS, CdO ,CdS, et CdTe en utilisant la méthode
We study the practical effects of five different metrics: the maximum number of nonzeros assigned to a processor (MaxNnz) which defines the load balance; the total communication
These metrics include the maximum number of nonzeros assigned to a proces- sor (MaxNnz), the total communication volume (TotVol), the maximum send volume of a processor (MaxSV),
