Compositional Simulation in Perception and
Cognition
by
Max Harmon Siegel
B.S., University of Minnesota (2010)
Submitted to the Department of Brain and Cognitive Sciences
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
@
Massachusetts Institute of Technology 2018. All rights reserved.
Signature redacted
A uthor ...
...
Department of Brain and Cognitive Sciences
,7'eptember 21, 2018
Signature redacted
C ertified by ...
...
Joshua B. Tenenbaum
Professor
Thesis Supervisor
Signature redacted
Accepted by(
....
...
...
Matthew A. Wilso
Direct r o
raduate Education for Brain and Cognitive Sciences
MASSACHU8ETTS INS TE OF TEIHNOWGY
MAY
36,2019
LIBRARIFS
Compositional Simulation in Perception and Cognition
by
Max Harmon Siegel
Submitted to the Department of Brain and Cognitive Sciences on September 21, 2018, in partial fulfillment of the
requirements for the degree of Doctor of Philosophy
Abstract
Despite rapid recent progress in machine perception and models of biological per-ception, fundamental questions remain open. In particular, the paradigm underlying these advances, pattern recognition, requires large amounts of training data and strug-gles to generalize to situations outside the domain of training. In this thesis, I focus on a broad class of perceptual concepts - those that are generated by the composition of multiple causal processes, in this case certain physical interactions - that human use essentially and effortlessly in making sense of the world, but for which any spe-cific instance is extremely rare in our experience. Pattern recognition, or any strongly learning-based approach, might then be an inappropriate way to understand people's perceptual inferences. I propose an alternative approach, compositional simulation, that can in principle account for these inferences, and I show in practice that it pro-vides both qualitative and quantitative explanatory value for several experimental settings.
Consider a box and a number of marbles in the box, and imagine trying to guess how many there are based on the sound produced when the box is shaken. I demon-strate that human observers are quite good at this task, even for subtle numerical differences. Compositional simulation hypothesizes that people succeed by leveraging internal causal models: they simulate the physical collisions that would result from shaking the box (in a particular way), and what those collisions would sound like, for different numbers of marbles. They then compare their simulated sounds with the sound they heard. Crucially these simulation models can generalize to a wide range of percepts, even those never before experienced, by exploiting the compositional struc-ture of the causal processes being modeled, in terms of objects and their interactions, and physical dynamics and auditory events. Because the motion of the box is a key ingredient in physical simulation, I hypothesize that people can take cues to motion into account in our task; I give evidence that people do.
I also consider the domain of unfamiliar objects covered by cloth. a similar
mech-anism should enable successful recognition even for unfamiliar covered objects (like airplanes). I show that people can succeed in the recognition task, even when the shape of the object is very different when covered.
Finally, I show how compositional simulation provides a way to "glue together" the data received by perception (images and sounds) with the contents of cognition (objects). I apply compositional simulation to two cognitive domains: children's intu-itive exploration (obtaining quantitative prediction of exploration time), and causal inference from audiovisual information.
Thesis Supervisor: Joshua B. Tenenbaum Title: Professor
Acknowledgments
I am unusually lucky to have, in addition to my advisor, two unofficial advisors.
I am grateful, first, to my advisor, Josh Tenenbaum. It's difficult to finitely enumerate the reasons why, so I'll just say what I least expected to learn: that it's okay and important to take oneself seriously, although I don't think he said any of this explicitly. This manifests in basically everything - if you have a model for something, take it seriously and try to figure out if it's right. If you believe something, see it through. Don't let yourself off with the excuse that things are preliminary. Basically, have the audacity to consider seriously your own hypotheses.
I'm also grateful to Laura Schulz. She designs the best experiments for the ques-tions she's interested in. She always finds the simplest way to ask a question; you wonder how anyone could answer her questions differently, but that's the point - she finds a way to make her points obvious. I'm glad and grateful that she found a place in her lab for me.
I'm grateful to Josh McDermott. He combines deep technical knowledge, practical scientific intuition, and an open mind and a vision for the future of hearing. I thank him for his support, and for also welcoming me into his lab.
I'm grateful for the friends that I've made in Cambridge, both inside the three labs I've been a part of, and otherwise.
Contents
1 Introduction 17
1.1 Perception as pattern recognition . . . . 18
1.2 Perception as explanation . . . . 19
2 Physical Inference for Object Perception in Complex Auditory Scenes 23 2.1 Introduction . . . . 24 2.2 Experiment 1 . . . . 28 2.2.1 Materials . . . . 28 2.2.2 Procedure . . . . 28 2.2.3 Participants . . . . 29
2.2.4 Results and Discussion . . . . 30
2.3 Experiment 2 . . . . 31
2.3.1 Materials . . . . 31
2.3.2 Procedure . . . . 32
2.3.3 Participants . . . . 32
2.3.4 Results and Discussion . . . . 32
2.4 Experiment 3 . . . . 34
2.4.1 Materials . . . . 35
2.4.2 Procedure . . . . 35
2.4.3 Participants . . . . 35
2.4.4 Results and Discussion . . . . 35
3 Perceiving Fully Occluded Objects via Physical Simulation 3.1 Introduction . . . . 3.2 Experiments . . . . 3.2.1 Participants . . . . 3.2.2 Stimuli . . . . 3.2.3 Procedure . . . .. 3.2.4 Results . . . .. 3.3 Models . . . . 3.3.1 Physics-based analysis-by-synthesis . . . . 3.3.2 Deep convolutional network . . . . 3.3.3 Results . . . .
3.4 Discussion . . . .
4 Intuitive psychophysics: Children's exploratory play tracks the discriminability of alternative hypotheses
4.1 Introduction . . . .. . . . . 4.2 Experiment 1 4.2.1 Method 4.2.2 Materials 4.2.3 Procedure 4.2.4 Results . 4.3 Experiment 2 . 4.3.1 Results . 4.4 Experiment 3 . 4.4.1 Results . 4.5 Experiment 4 . 4.5.1 Results . 4.6 Joint Analysis . 4.7 Discussion . . . . quantitatively 51 51 55 55 57 57 59 61 61 62 62 63 63 66 67 39 39 43 43 43 44 44 45 45 48 48 48
5 What happened? Reconstructing the past through vision and sound
69
5.1 Introduction . . . .
5.2 Experimental paradigm . . . . 5.3 Model .... ... ...
5.3.1 Hypothetical simulation model . . . .
5.3.2 Heuristic model . . . ..
5.3.3 Stimulus selection . . . . 5.4 Experiment 1(a): Prediction (vision) . . . .
5.4.1 M ethods . . . . 5.4.2 Results and discussion . . . .
5.5 Experiment 1(b): Inference (vision) . . . . 5.5.1 M ethods . . . .
5.5.2 Results and discussion . . . .
5.6 Experiment 2(a): Prediction (vision and sound)
5.6.1 M ethods . . . .
5.6.2 Results and discussion . . . .
5.7 Experiment 2(b): Inference (vision and sound) 5.7.1 M ethods . . . .
5.7.2 Results and discussion . . . .
5.8 Experiment 3: Inference with occlusion . . . . 5.8.1 M ethods . . . .
5.8.2 Results and discussion . . . .
5.9 General discussion
6 Conclusion
6.1 O pen Q uestions . . . .
6.1.1 What is the relationship between pattern recognition and per-ception as explanation? . . . .
6.1.2 How do the various senses of compositionality relate? . . . . .
. . . . 69 . . . . 70 . . . . 71 . . . . 74 . . . . 76 . . . . 76 . . . . 77 . . . . 77 . . . . 79 . . . . 80 . . . . 80 . . . . 80 . . . . 82 . . . . 82 . . . . 82 . . . . 83 . . . . 83 . . . . 84 . . . . 85 . . . . 85 . . . . 86 86 89 90 90 90
6.1.3 How is perception (as explanation) so fast? . . . . 91
6.1.4 Can we understand other senses in this way? . . . . 92 6.1.5 How do we acquire these simulators? . . . . 92
List of Figures
1-1 A horse covered by a zebra-texture cloth. Presumably no one viewing
this figure has seen such a visual concept, but we have no trouble interpreting it . . . . 20
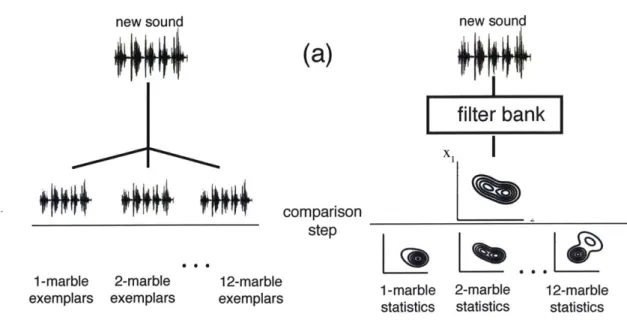
2-1 Schematic of models for recognizing marble numerosity from sound. We depict (a) pattern recognition models, which recognize sounds by comparing to a library of exemplars; and (b) causal models, which do so by generating potential matches and comparing. . . . . 25
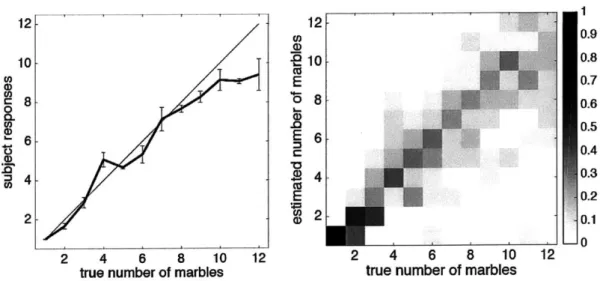
2-2 Mean (+- SEM) participant responses and confusion matrix for the
auditory numerosity task, for participants from general subject pool. . 29
2-3 Mean (+- SEM) participant responses and confusion matrix for the
auditory numerosity task, for a separate set of experienced listeners. Note that the undershoot seen in Figure 2-2 has disappeared . . . . . 30
2-4 We made recordings of boxes shaken with three different motions. Par-ticipants estimated numerosity while listening to both real and syn-thetic sounds; we display the group mean for each condition. Errorbars
are + - SEM . . . . 33
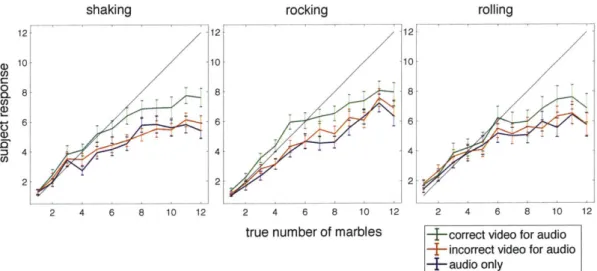
2-5 Mean number estimates (+- standard errors) for the three motion types and stimulus conditions in Experiment 3. . . . . 36
2-6 Summed squared error (SSE) between individual participant's number estimates and ground truth numbers averaged across the range of 1-12 marbles and all three box motions, for three different stimulus con-ditions from Experiment 3. Each dot is one participant. Audio with correct video is consistently more accurate than audio only (left panel), or audio with incorrect video (right panel). . . . . 37
3-1 Two objects occluded by cloths. . . . . 41
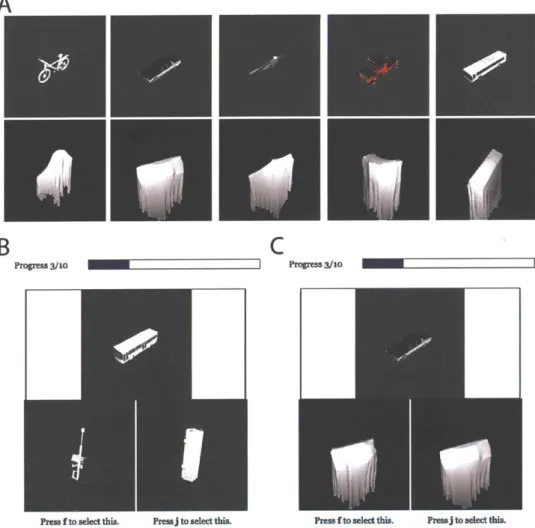
3-2 (A) Pairs of images of meshes and simulation results after rotating
the mesh randomly and draping a cloth over it. (B) Screenshot of an example trial in the unoccluded experiment. (C) Screenshot of an example trial in the occluded experiment . . . . . 42
3-3 (A) Average performace of the participants in the two experiments.
(B) Performance of the subjects divided by whether the distractor is of the same or different category as the study item. Error bars indicate standard error of the mean. . . . . 45 3-4 (Left) Average performance of the physics-based analysis-by-synthesis
model on the unoccluded and occluded stimuli sets, and the breakdown of its performance by the tyep of the distractor category. Error bars indicate standard error of the mean. (Right) Average performance of the pre-trained network on the unoccluded and occluded stimuli sets, and the breakdown of its performance by the type of the distractor category. Dashed line shows the chance-level performance . . . . 46
4-1 Schematic of task in Experiments 1-4. Placement of contrasts repre-sents relative discriminability. Contrasts were presented in a random-ized order within each experiment. . . . . 56
4-2 Children's proportional exploration time as a function of the nega-tive discriminability of each contrast across Experiments 1-4, showing bootstrapped 95% confidence intervals. . . . . 64
4-3 Children's accuracy on each trial of Experiments 1-4, as a function of
(negative) discriminability. . . . . 65
5-1 Prediction task: Experiment 1(a) and 2(a) . . . . 71
5-2 Inference task: Experiment lb and 2b . . . . 72
5-3 Inference task with occlusion: Experiment 3 . . . . 73
5-4 Summary of results for an illustrative selection of cases (please zoom). These cases were chosen to illustrate how auditory information may improve performance (world 1-4), make no difference (world 5-7), or decrease performance (world 8). Row 1: Stimuli in the inference task. The star indicates through which hole the ball was dropped. Row 2: Densities showing participants' predictions in Experiment 1(a) of where the ball would land if it was dropped in hole 1 (red), hole 2 (green), or hole 3 (blue). The colored circles at the bottom show for each hole where the ball would land according to the ground truth physics model. Row 3: Predicted densities generated by the hypothetical simulation model. Row 4: Inferences in Experiment 1(b) about which hole the ball was dropped in. Thick outlines indicate the correct response. Error bars indicate bootstrapped 95% confidence intervals. The white circles show the predictions of the hypothetical simulation model. Rows 5-7: Analog to rows 2-4 for Experiment 2 in which participants also heard the ball dropping. The hypothetical simulation model shown in row 6 (densities) and row 7 (white circles) integrates both vision and sound. Row 8: Stimuli in the inference task with occlusion. Row 9: Inferences in Experiment 3 in which the final ball position was occluded. Note: Error bars in all figures indicate bootstrapped 95% confidence intervals. 78 5-5 Relationship between the hypothetical simulation model and partici-pants' judgments of where the ball will land. . . . . 79
5-6 Experiment 1(b): Scatter plots showing how well the different mod-els can account for participants' inferences about where the ball was dropped. Gray circles indicate the correct holes. . . . . 81 5-7 Experiment 2(b): Scatter plots showing how well the different models
account for participants' inferences about where the ball was dropped. Gray circles indicate the correct holes. . . . . 84
5-8 Accuracy in (a) predictive task as measured by the root mean squared error between judged and actual position of the ball (lower values in-dicate better accuracy), and (b) inference task as measured by the averaged percentage assigned to the correct hole . . . . 85
List of Tables
4.1 Contrasts used across Experiments 1-4, ordered from most discrim-inable to least discrimdiscrim-inable. Trial order was counterbalanced, as was the order of introduction of the tubes of marbles, and the actual hidden contents of the box (e.g., whether 1 or 7 marbles were hidden inside on the 7 vs. 1 trial) except in Experiment 3, per features of the design.
A.1 Experiment 1 results of linear
tion exploration time, Models
A.2 Experiment 2 results of linear tion exploration time, Models
A.3 Experiment 3 results of linear
tion exploration time, Models A.4 Experiment 4 results of linear
mixed effects models predicting
propor-1-4. . . . . . mixed effects 1-4. . . . . . mixed effects 1-4. . . . . . mixed effects
.m.. ...
. ....
..
models predicting
models predicting
models predicting propor-tion explorapropor-tion time, Models 1-4. . . . .
A.5 Joint analysis from Experiments 1-4 results of linear mixed effects
mod-els predicting proportion exploration time, Modmod-els 1-4. . . . . 58 94 94 94 95 95
Chapter 1
Introduction
We live in a time when we regularly hear that machine learning algorithms learn like humans, or at least achieve human-level performance. And indeed, there has been tremendous progress in traditionally intractable problems in perception
[36]
[77], and other tasks [50] [65] which are amenable to pattern recognition solutions.
Less common are critiques of machine learning, but those that are most prominent
-generally from psychologists and cognitive scientists - outline various ways in which artificial intelligence is nothing like human intelligence [46] [38]. I will describe a class of phenomena, ironically originating in perception, that is difficult to explain even conceptually (let alone implement) using the modern machine learning synthesis, and that offers challenges that differ from most commonly cited weaknesses of machine learning.
These phenomena similarly challenge perceptual theories in psychology and neu-roscience. I was initially interested in them because of surprise: I "wasn't supposed" to be able to interpret them according to my understanding of mainstream theory. But I had experienced percepts for which I was fairly confident in my judgments, and turned out to be mostly right (in the sense that those percepts ended up being mostly veridical).
The work I will describe therefore provides challenges for theory of neuroscience and psychology, as well as for the practice of artificial intelligence. I will also argue for a theory, which I term "compositional simulation", which provides conceptual
groundwork for understanding my work, as well as implementations of such a theory in several example domains. For each domain (interpolating between perception and cognition), I compare model predictions with human behavior.
1.1
Perception as pattern recognition
Perception, in particular vision, has always confounded researchers [471 interested in human and artificial intelligence. Unlike other intelligent behaviors, perception is (usually) effortless, unconscious, and cognitively impenetrable, to the degree that it is cited as a standard example when describing cognitive modularity [23] [22]. Moreover, it is quick and clearly exists across species (perhaps suggesting relative simplicity of function). It therefore surprised and disturbed scientists and engineers that it proved to be much more difficult to understand perception than had been expected. Marr
[47] describes the experience of early computer vision researchers:
The first great revelation was that the problems are difficult. Of course, these days this fact is a commonplace. But in the 1960s almost no one realized that machine vision was difficult
[...I
The common and almost despairing feeling of the early investigators like B.K.P. Horn and T.O. Binford was that practically anything could happen in an image and furthermore that practically everything did.
The early-to-middle history of computational vision fostered a diversity of per-ceptual tasks and approaches [69] (e.g. the top-down geometry-recovering program of Roberts [58], and the Retinex algorithm of Land [39]), but in recent decades, re-searchers seeking to add rigor and systematicity to the field introduced standardized tasks, data sets [21][40][20][70], and benchmarks. The field also increasingly focused on one targeted task, object recognition. This focus, while fruitful in that it led to advances in object recognition, had the effect of diminishing other visual tasks and
approaches. In 2012, this homogenized field was unexpectedly disrupted by a small team of neural network researchers [36].
The emergence of neural networks as a means of solving perceptual problems led to their use in numerous other tasks, at times seeming (to some) to provide a general means of "solving intelligence" [6] [53], with caveats that seem to be only due to insufficient computational ability. The principles underlying the success of such methods seemed easy to state and achieve: very large amounts of data, very large amounts of computation, and a relatively simple optimization method [41].
These methods are well suited to situations that satisfy these desiderata. When evaluating them as accounts of biological perception, however, one runs into trouble
- it's difficult to say much, if anything, about the computational and optimization resources present in real brains. But the third principle - very large data sets - is amenable to analysis. My thesis concerns the perception and recognition of concepts for which there is presumably very little data in one's past: recognition of the number of marbles in a box from the sound of shaking the box - and concepts which one has probably never experienced before: a horse covered in a zebra-textured cloth
(Figure 1-1), for example.
1.2
Perception as explanation
These are examples of what I call compositional percepts; I call the process of per-ceiving such cases perception as explanation. Their name is chosen because they may be viewed as the results of composing physical processes: rigid body physics and acoustics in the marble case, cloth physics and visual rendering in the other. I pro-pose that we perceive such perceptual concepts by performing internal simulations of these processes (setting latent variables to each possible value for those that we care about and marginalizing the rest), and comparing the results with the concept to be explained. This mechanism should, in principle, allow one to solve this kind of problem. I call this process of perception of compositional percepts compositional simulation. My thesis examines the case for compositional simulation in two domains,
-
~h~bFigure 1-1: A horse covered by a zebra-texture cloth. Presumably no one viewing this figure has seen such a visual concept, but we have no trouble interpreting it.
the perception of marbles sounds and of cloth-draped objects.
When developing compositional simulation as an account of perception as expla-nation, it became clear that the mental capacities that seemed necessary (and in light of the experiments I present, plausible) to account for these kinds of percepts could also engage higher level cognition. In the latter chapters of this thesis, I inves-tigate how compositional simulation might support children's exploratory behavior; and how it might support audiovisual causal inference.
The zebra-cloth horse example is difficult to study because the causal analysis of
its appearance involves computational difficulty (in the cloth simulation and in the graphics engine and explanation). A simpler case is the marble number task. I begin
Chapter 2
Physical Inference for Object
Perception in Complex Auditory
Scenes
i
Perception is often modeled as a pattern recognition process, with data-driven mech-anisms that learn the statistics of experience without regard for the causal processes underlying the data we perceive. But perception also involves casual inference, and indeed physical inference. We introduce a novel task paradigm that allows us to study the mechanisms of physical causal inference at work in auditory perception and joint visual-auditory scene understanding. We call this task the "box-shaking game"; peo-ple have to figure out what is in a cardboard box, in particular how many objects of a certain type are in the box, just by listening to the sounds of the box being shaken. We present three experiments showing that even naive observers readily perform this task, that they do so using information beyond the statistics of sound textures (po-tentially involving representations of events and dynamics), and that they benefit from cross-modal visual data that reveals the box motion but that provides no direct information about the box contents. The results suggest that listeners have an inter-nal causal model of object interactions and use it to infer the physical events giving rise to sound.
2.1
Introduction
The goal of perception is to infer, from sensory input, properties of the latent scene. Perceptual inference is a difficult task, in part because scene elements can appear with seemingly arbitrary variations in different contexts. This variability is not ar-bitrary, however. Perceptual scenes are generated by causal processes in the world
- processes that respect and express physical laws. Mechanisms of perception ex-ploit these physical regularities, and they do so using essentially one of two broad approaches (illustrated in Figure 2-1).
Pattern recognition models attempt to infer scene properties by generalizing
in a statistical way from previously encountered perceptual data. They might inter-pret new sense inputs according to their similarity to previous data for which the scene properties were known, or according to how well new inputs reflect statistical regularities that in previous data were correlated with scene properties of interest. These models are primarily data-driven, and require little or no knoweldge about the nature of the process that generated the data.
Causal models, in contrast, attempt to represent in some approximate way
the causal processes in the world that generate sense data [13, 31], and how these causal processes depend on properties of the underlying physical scene. They typically interpret new sensory inputs by a process of "analysis by synthesis" or simulation: That is, they search for and evaluate hypotheses about the latent scene properties that would produce sense data similar to the data observed, under the hypothesized causal model of how the world works. A good match between the simulated sense data and the actual sensory inputs suggests that the latent scene properties hypothesized might correspond to some degree to the true state of the world.
Recently, progress has been made in both biological [77, 48] and machine percep-tion [36, 51], in part due to technical advances for neural networks and other types of pattern recognition models. While these systems are impressive, they also have real limitations. To achieve good performance, pattern recognition models can require large amounts of labeled training data, and they need training data that is strongly
new sound
4 *I4
UM4*iwm
(a)
new soundfilter
bank
xI
comparison step 1-marble 2-marble exemplars exemplars 12-marbleexemplars 1-marble 2-marble
statistics statistics
X M - -M W - -M - M - - - m
M M -M -M -M M - -M M.
(b)
n marbles placed in box
new sound
0I
simulate shaking||111
1-marble
2-marble simulations simulations comparison stepFigure 2-1: Schematic of models for recognizing marble numerosity from sound. We depict (a) pattern recognition models, which recognize sounds by comparing to a library of exemplars; and (b) causal models, which do so by generating potential matches and comparing.
12-marble statistics
representative of the test set (the task they will perform). They do not easily gen-eralize outside of their training setting. These drawbacks are direct consequences of the data-driven nature of the pattern recognition approach - the costs paid for the simplicity of not having to grapple with the world's causal structure.
Causal models need not suffer from these limitations, although they have other, complementary limitations; they may be more difficult to build and more computa-tionally intensive to work with. But because causal models describe the data gen-eration process (as opposed to the effects of that process, the data), causal models can successfully interpret data generated from familiar processes operating under unfamiliar conditions, supporting inferences even when we have had essentially no experience with similar input. Such strong generalization often occurs because causal models can be composed to capture the way natural outcomes unfold in a complex physical world. The composition of two causal processes may yield effects that are quite different from either process's typical outputs on its own, which would thus be hard to match to anything in memory, but could be interpretable immediately by a causal modeling approach.
As an illustration of the distinction between causal and pattern recognition models of perception, and of the possible practical advantages of a causal approach in gen-eralizing to unfamiliar situations, consider the following perceptual task: Identifying the nature and number of objects in a cardboard box, from the sounds generated by shaking the box. Or consider a particularly constrained version of this task: Between
1 and 12 typical marbles are placed in a typical shoebox, and the task is to
iden-tify how many marbles are in the box from shaking it rapidly up and down. As we describe below, we have studied this task and several variants in detail, and found that people are quite good at making these judgments, even without much practice. Even young children, it appears, can make these discriminations, and with reasonably calibrated confidences [64].
How would an agent solve this task using a pattern recognition approach? One could collect examples of sounds, for each candidate number of marbles in the box, then train a model to discriminate each number class from every other class, or to
regress the number onto some statistical features of the shaking sounds. The model might show good performance for each of the trained number classes, but it would likely need large training sets for numbers in the range 1-12 to be predicted, and additional training in order to generalize to other numbers well outside its training set, to generalize to different kinds of boxes or objects, or different box shaking motions.
Solving this task with a causal model proceeds quite differently. An agent might in some approximate way simulate the physical dynamics and physical object inter-actions as the box is shaken up and down, causing the objects to move and to hit the box's walls and each other. These collisons are the events that give rise to observed sounds, and they will occur with frequencies, timings and intensities that vary as a function of the latent scene property in question - the number of marbles in the box
- as well as other physical nuisance variables such as the specific ways the box is shaken (the specific pattern of forces applied to the system). A mental simulation could be used to imagine example sounds that would come from shaking the box in a particular way with a given number of marbles in it, and these simulated sounds could then be compared with the actual observed sounds to determine the most likely number of marbles in the box (based on whichever set of simulations best matches the observations). Some learning from experience might be required to build this sim-ulation capacity, but once built, the causal model might be able to handle additional numbers of marbles, different kinds of objects or different patterns of box shaking without additional training because it can naturally take as input variations in these latent scene properties.
In this work, we attempt to study which sort of approach is used by the human perceptual system in this domain: pattern recognition or causal modeling? We per-formed three experiments based on the above marble task. The marble numerosity task is attractive for a few reasons. First, the task, while natural, is unusual. The prevalence of fine-grained auditory numerosity tasks in the environment seems low, at least when compared with most tasks studied in perception. Therefore, good per-formance might require more than past experience with similar situations. Second,
we have reason to believe that the task should be solvable with a causal model that is available to human perception. Recent work suggests that human intuitive physics provides a reasonable approximation to rigid body mechanics [51. The sounds we will consider are produced when marbles hit other marbles and the box. If people can relate sounds to collisions, then they might be able to apply their intuitive physics to solve the perceptual task. Finally, it is easy to construct variations on the task with physically different box motions or bringing in visual cues to the box's motion, which lets us study the role of physical causal models in multisensory perception while raising new challenges for pure pattern-recognition approaches.
2.2
Experiment 1
We first investigated human performance on the basic auditory numerosity task de-scribed above. We recorded five exemplars of the sounds of different numbers of marbles being shaken in a box, with numbers ranging between one and twelve, and asked subjects to estimate the number of marbles in each clip (presented in a random order). We were interested in how humans would perform without training, so we did not provide any feedback during the experiment.
2.2.1
Materials
We used standard glass marbles and a shoe box. To create stimuli, we set up a microphone in a soundproof booth and recorded marbles being shaken in the box, with an natural up-and-down shaking motion. To control for loudness (which is an obvious cue to numerosity), we normalized each recording by RMS (root mean square) power.
2.2.2
Procedure
The experimenter briefly described the task to each participant, saying that they would hear recordings of marbles being shaken in a box, and providing a mimed
1 12 12-cn 0.9 15 10 - 0.8 0d E 0.7 8. 8- - 0.6 -D 0.5 - E 6-' 0.4 0.3 CO E -0.2 2 2 .0.1 _0 2 4 6 8 10 12 2 4 6 8 10 12
true number of marbles true number of marbles
Figure 2-2: Mean (+- SEM) participant responses and confusion matrix for the au-ditory numerosity task, for participants from general subject pool.
demonstration of the shaking style. Subjects were asked to report, after each trial, their estimate of the number of marbles for that trial. Subjects recorded their response
by typing a number into a computer. The order of recordings (and hence numbers of
marbles) was randomized.
Pilot testing suggested that there were learning effects over the course of the experiment (potentially due to uncertainty about the particulars of the box and the marbles). Therefore, before participants began the testing portion of the experiment (i.e. began entering their responses), we played, in a random order, one recording of each number of marbles.
2.2.3
Participants
We recruited 21 adult participants from a university mailing list as well as 3 graduate students studying human audition (who were thus highly motivated to perform well).
12 12 0.9 10 10 0.8 E 0.7 88- 0.6 M 0.5 6 .E 6
e6
0.4 4 4 0.3 E 0.2 2 2 .0.1 _0 2 4 6 8 10 12 2 4 6 8 10 12true number of marbles true number of marbles
Figure 2-3: Mean (+- SEM) participant responses and confusion matrix for the
au-ditory numerosity task, for a separate set of experienced listeners. Note that the undershoot seen in Figure 2-2 has disappeared
2.2.4 Results and Discussion
Figure 2-2 displays the mean estimate given by participants as a function of the true
number of marbles; the error bars show the standard error of the mean. Participants' responses were highly correlated with the true number of responses (r = 0.98; p <
2.7 x 10-9).
Despite participants' apparent sensitivity to auditory numerosity, the responses show a clear undershoot. To test whether this bias is inherent to the task, we recruited three additional experienced psychophysical observers from a university hearing lab. Figure 2-3 displays their performance; like our first group, the experienced listeners are highly correlated with the true number (r = 0.96; p < 4.97 x 10-8). Unlike our first group, the estimates of the experienced listeners are relatively well calibrated.
We conclude that people can perform the auditory numerosity task: mean number estimates were highly correlated with the true number (and therefore easy to cali-brate), and highly motivated listeners exhibited judgments that were approximately correct in absolute terms. These results are consistent with the causal models hy-pothesis, and in our subsequent experiments we tried to more definitively test this
2.3
Experiment 2
We see two ways in which pattern recognition models might be able to account for people's success in Experiment 1. It mght be that people have had significant experi-ence with different (known) numbers of marbles being shaken in boxes. Alternatively, there might be some set of generic auditory features that are useful for judging nu-merosity. People might have made use of relatively few experiences with labeled data,
by noting some relationship between numerosity and these features.
We address these issues by modifying Experiment 1 in two ways. First, we pre-sented sounds with produced by moving the box in three different ways: shaking, rocking, and rolling. One motivation for this was to present more varied stimuli. Although we can't estimate the extent of people's experience with marbles in boxes, increasing the stimulus variability should increase the amount of experience neces-sary to solve the task with pattern recognition methods. In addition, while we can't directly rule out the existence of features that are informative for numerosity es-timation, accurate number estimation for stimuli that have very different low-level statistics might make it more likely that such statistics do not underlie listeners' judgments. Second, we also presented participants with synthetic 'texture' stimuli matched to the natural sounds along a large set of sound statistics [49]. The resulting sounds match many acoustic properties of the marble recordings, but because they are generated from statistical acoustic constraints rather than causal constraints, they typically do not evoke a clear physical interpretation. If marble number estimation is based on stored representations of the acoustic properties associated with different numbers of marbles, listeners should perform similarly with the synthetic textures. If, in contrast, listeners depend on an inference of the causal process that generates the marbles sounds, performance with the textures should be substantially worse.
2.3.1
Materials
We chose two additional motions that produce sounds that differ from the original "shaking" motion and from each other; see Figure 3 for a visualization. We recorded
marble sounds as in Experiment 1. Synthetic textures were generated from statistics measured from the marble recordings, using a procedure that successfully replicates the sound of many natural textures such as the sound of rain, fire, or swarms of insects
[491.
The statistics that were matched were those of the full McDermott and Simoncelli texture model: Marble recordings were represented in a three-stage audi-tory model (cochlear filtering, envelope extraction and compression, and modulation filtering), and marginal moments and cross-channel correlations were measured from the last two stages.2.3.2
Procedure
The experiment consisted of 3 motions x 2 real/synthetic conditions x 12 numbers of marbles x 5 exemplars = 360 trials, presented in a randomized order. The procedure was as in Experiment 1, except that the experimenter told subjects that some of the sounds were artificial, asking them to nevertheless answer as best they could. Also, participants were not played 'warmup' sounds before beginning the experiment.
2.3.3
Participants
We recruited nine more adult participants from the university subject pool. All participants reported normal hearing.
2.3.4
Results and Discussion
Figure 2-4 presents the results, coding motion type by color. In the Recorded Sounds condition, as in Experiment 1, subjects' judgments were highly correlated with the true number of marbles (shaking: r = 0.94, p < 4.5x10-6; rocking: r = 0.97, p < 3.9 x
10-8; rolling: r = .95, p < 1.5 x 10-6. However, it is apparent that number estimates
from the Synthetic Texture stimuli varied much less with the true number. A three-factor (true number, sound type, motion) repeated-measures ANOVA accordingly revealed a highly significant interaction between number and sound type, F(11, 8) =
recorded sounds
sound textures
12 10 8 6 4 2 2 4 6 8 10 12true number of marbles
"shaking"
"rocking"
2 4 6 8 10 12
"rolling"
Figure 2-4: We made recordings of boxes shaken with three different motions. Par-ticipants estimated numerosity while listening to both real and synthetic sounds; we display the group mean for each condition. Errorbars are +- SEM.
12 10 F CD U) C, 0 CL, CI) a) (D 8 6 4 2
17.31, p < 2.2 x 10-15. This result suggests that standard sound texture features do not account for auditory numerosity perception.
The results are consistent with the notion that listeners use a causal model when estimating number from sound. Experiment 2 included three different motions, which might have impaired a listener using a pattern recognition model, but not one using a causal model. Listeners were able to estimate number to some extent from all three motions. And statistically matched synthetic sounds, which might not have impaired a pattern recognition system, greatly altered participants' judgments.
2.4
Experiment 3
The box-shaking sounds that we study are generated as a function of a number of latent variables: number of marbles, box trajectory, and so on. Even with a correct causal model, estimating number from sound alone is plausibly difficult because these variables are all unobserved. One signature of inference in a causal model might thus be that listeners would be aided if some of these latent variables were made accessible. Critically, this might be the case even for variables that do not on their own provide information about the number of marbles in the box.
As an additional test of causal inference, we thus investigated whether providing listeners with visual information about the box motion would improve number esti-mation. We compared performance for audio recordings alone (as in Experiments 1 and 2) with that when listeners viewed a video of the box motion while concurrently listening to the audio. Any effect of visual information seemed likely to be particu-larly diagnostic in this case given that no information about number was evident in the video (because the box was opaque). Our hypothesis was that viewing the motion of the box while listening would improve listeners' number estimation performance, relative to their performance with audio alone. In addition, we predicted that show-ing an "incorrect" video (i.e., showshow-ing a motion different than that used to produce the audio recording) would not improve estimates and potentially even hurt.
2.4.1
Materials
To avoid introducing unwanted visual cues (beyond the motion of the box), we gen-erated artificial videos of box motion. We used an OptiTrack V120 motion tracking system to record the precise motion of a box while it was shaken. We used the same motions and marbles as in Experiment 2, but re-recorded the marble sounds while tracking each box motion trajectory. After collecting motion data, we synthesized appropriate videos using the Blender physics engine.
2.4.2
Procedure
The procedure was the same as that of Experiment 2, except that the condition using sound textures was supplanted by a condition in which the audio recordings were accompanied by the corresponding synthetic video. In a third condition, the audio was accompanied by a video in which the box motion differed from that used to produce the audio. The videos in this incorrect video condition had a categorically different motion type (one of the two other motions from the set of shaking, rocking, and rolling) on two-thirds of the trials, and the correct motion type but from a different audio recording exemplar on the remaining third of trials.
2.4.3
Participants
Fourteen more participants, all with self-reported normal hearing, were recruited from the subject pool.
2.4.4
Results and Discussion
Average number estimates from each condition of Experiment 3 are plotted in Fig-ure 2-5. Unlike FigFig-ure 2-4, different colors code for viewing condition rather than motion type. The number estimates when listeners concurrently viewed the correct video were closer to the true number (less undershoot) than when listeners had access only to the audio. Moreover this benefit appeared specific to when the video matched
shaking T T T 4 1 1 2 4 6 8 10 12 rocking 12- 10-8 6 4 2 2 4 6 8 10 12
true number of marbles
12 10 8 6 4 2 rolling -T 2 4 6 8 10 12
- correct video for audio - incorrect video for audio
-+-audio only
Figure 2-5: Mean number estimates (+- standard errors) and stimulus conditions in Experiment 3.
for the three motion types
the audio. To quantify these effects, we computed the aggregate summed squared error (SSE) over each viewing condition of the experiment. This error was signifi-cantly lower for the correct video condition than for the audio-only condition for each of the three motion types (p < .01 for each motion, paired t-tests). By contrast, no
such advantage occurred for the incorrect video (p > .05 in all cases, paired t-tests). Figure 2-6 plots the error in each condition averaged across motion types, for each participant. Participants' SSEs were consistently lower in the correct video condition relative to audio alone or with the incorrect video.
Our data thus show that an auditory number estimation task, participants take auxiliary visual information about causally relevant latent variables (the box motion) into account when making judgments. As predicted, this information is helpful when
accurate.
2.5
Discussion
Causal models offer a number of theoretical advantages for perception over pattern recognition models. First, to the extent that they can accurately capture the physical causal processes that produce perceptual data, they can optimally interpret
percep-12 10 8 6 4 2 4) C, C 0 Q_ W) Q
4000 0 0 3000- (32000-C 1000 1000 2000 3000 4000 1000 2000 3000 4000
SSE in Audio Only Condition SSE in Incorrect Video Condition
Figure 2-6: Summed squared error (SSE) between individual participant's number estimates and ground truth numbers averaged across the range of 1-12 marbles and all three box motions, for three different stimulus conditions from Experiment 3. Each dot is one participant. Audio with correct video is consistently more accurate than audio only (left panel), or audio with incorrect video (right panel).
tual data even in complex, novel situations that an observer may not have previ-ously encountered or had extensive experience with. Second, these models can mod-ulate their inferences based on different physical contexts, such as different modes of box-shaking. And third, without any additional training, they can seamlessly inte-grate auxiliary information relevant to the physical scene interpretation of perceptual events, such as the precise visual motion generated by shaking a box in a particular way, in order to improve inference. However, these theoretical advantages do not imply that human perceptual systems actually use such models, particularly given that inference can be challenging algorithmically. The purpose of our experiments was to explore whether human perception indeed draws on physical causal models in one domain where the relevant causal models seemed plausibly available to naive observers. In three experiments with our box-shaking number estimation task, we found results consistent with the use of causal physical models to guide perception, and that illustrate the three advantages described above that are expected for causal models.
In Experiment 1, when asked to report the number of marbles that they heard, naive observers performed reasonably (in either absolute terms or via a correlation metric) when listeners heard actual recorded audio generated by shaking a box up and down, or with one of several different types of motion in Experiment 2. In Experiment
2, we also found evidence that a set of generic non-causal or non-physical perceptual
representations (the texture statistics of [49, 481) do not support task performance, in that number estimation for statistically matched synthetic sounds was poor. These synthetic sounds resembled the actual recordings in many respects but generally did not produce a sense of the physical interactions generating the marble sounds, which would be expected to impair causal inference.
Finally, in Experiment 3, we directly tested whether access to auxiliary causal knowledge -the gross motion of the box, as conveyed by video -can influence human judgments. We found that concurrent video improved number estimates provided it matched the audio recording in question, even though the video on its own contained no information about the number of marbles. These observations are consistent with the notion that a causal model underlies the perception of these kinds of object sounds.
Going forward we would like to develop more precise computational models of the perceptual capacities studied here. We are currently exploring causal generative models drawing on physical simulation, as in the intuitive physics work of [5]. We plan to construct a computational model embodying physical causal inference (as outlined in the introduction) for direct comparison with human judgments, as well as comparison with state-of-the-art pattern recognition models.
Chapter 3
Perceiving Fully Occluded Objects
via Physical Simulation
I
Conventional theories of visual object recognition treat objects effectively as abstract, arbitrary patterns of image features. They do not explicitly represent objects as phys-ical entities in the world, with physphys-ical properties such as three-dimensional shape, mass, stiffness, elasticity, surface friction, and so on. However, for many purposes, an object's physical existence is central to our ability to recognize it and think about it. This is certainly true for recognition via haptic perception, i.e., perceiving objects
by touch, but even in the visual domain an object's physical properties may directly
determine how it looks and thereby how we recognize it. Here we show how a phys-ical object representation can allow the solution of visual problems, like perceiving an object under a cloth, that are otherwise difficult to accomplish without extensive experience, and we provide behavioral and computational evidence that people can use such a representation.
3.1
Introduction
Object perception is notoriously difficult, in part because the appearance of an object can vary in almost any way. The problem has been studied in neuroscience, cognitive
psychology, and artificial intelligence, leading to a loose consensus that object per-ception can be solved by the brain (or a computer) learning to "untangle" or become "invariant to" sources of variation in the image [15, 41]. On this account, sensory input is repeatedly transformed, ideally leading to a (biological or artificial) neural code that is diagnostic for a particular object regardless of variation in the image [57]. We study an alternative solution to the object perception problem, which is en-abled by a different representation for objects and a different attitude towards varia-tion. The basic idea is to model the causal processes that lead to an observed image, explaining and reproducing image variation rather than attempting to ignore it. More specifically, we take an object to be represented (at least in part) by a set of phys-ical attributes necessary for supporting physphys-ical interaction and image generation. We posit that objects are represented, at a minimum, by attributes including three-dimensional geometry; rigidity; mechanical material properties; and optical material properties.
Consider the covered objects displayed in Figure 3-1. Both objects are completely occluded, but it is easy to say which of them might be a chair. These images were generated by using a physics simulator to drop a simulated cloth onto two separate
3D models (one a chair), then using a rendering engine to produce images from the
resulting scene.
This describes a process for generating the image, but the same process can also be used to interpret an image. When asked which image has a chair in it, we can simulate dropping cloths onto a chair mesh, and compare the rendered results with each candidate (this is an intuitive sketch of a procedure; it can be made precise with Bayes' theorem, which specifies how to turn a forward model into an inverse model. See also [5]).
There are several notable differences between the latter approach (which we will call analysis-by-synthesis) and the "consensus" approach (which we will call the in-variant features approach). First and most notably, inin-variant features approaches must learn each kind of scene transformation independently. We explained above how knowledge about chairs and cloths can be combined, in the analysis-by-synthesis
Figure 3-1: Two objects occluded by cloths.
approach, to recognize a chair underneath a cloth. By contrast, invariant features approaches cannot directly leverage existing knowledge to recognize the compound object. They must be trained, separately, to discount the cloth in order to recog-nize the chair2. Second, while invariant features approaches are mostly agnostic to the kinds of image transformations that might exist, analysis-by-synthesis implicitly handles a wide variety of transformations without being explicitly trained or taught to do so.
Analysis-by-synthesis in vision has a long history [81, 71], and has recently seen increased attention [37, 80, 17]. Our work focuses primarily on two less-studied as-pects: First, while most work in object perception studies unoccluded or partially occluded objects, we are interested in objects that are fully occluded, so that the only perceptible effect of the object is on its occluder. Said another way, perceiving objects through cloths requires an observer to do without most or all of the visual information that one normally uses. Second, unlike most previous work, we are inter-ested primarily in how the object representation enables this kind of perception. If objects are represented geometrically in a way that can interact with physics, then the procedure outlined above shows how to solve the cloth task without more training.
Aj
A
B
C
Progress 3/10 Progress 3/10
Press fto select this. PressJ to select this. Press f to select this. Pressjto seect this.
Figure 3-2: (A) Pairs of images of meshes and simulation results after rotating the mesh randomly and draping a cloth over it. (B) Screenshot of an example trial in the unoccluded experiment. (C) Screenshot of an example trial in the occluded experiment.
The object-under-cloth task is most interesting in the case of novel cloth-object pairs (such as an airplane under a cloth). We predict that both people and analysis-by-synthesis models will perform well on this task, but invariant features models will not without further training.
We ran a large scale study to assess how well people can perform the object-under-cloth task. After describing the task and the results of the study, we will evaluate the performance of each of the candidate models, and discuss the implications of our
3.2
Experiments
We performed two experiments where participants needed to generalize from a single view of 3D object shown at a canonical view to either a novel view of that object (Experiment 1) or to a fully occluded image of that object again at a novel view (Experiment 2).
3.2.1
Participants
58 participants were recruited from Amazon's crowdsourcing web-service Mechanical
Turk. The experiment took about 20 minutes to complete. Each participant was paid $1.50.
3.2.2
Stimuli
The stimuli were generated using a subset of the meshes from the ShapeNet [10] database using Blender [7], a 3D modeling and rendering program. The meshes we used represented objects from five different categories: guns, cars/buses, bicycles, laptops and pillows.
We rendered each mesh in three ways: (1) unoccluded, with texture, and from a canonical viewpoint, (2) unoccluded, without texture, and at a random viewing angle, and (3) fully occluded with a cloth draped over it, and with the mesh randomly rotated.
For (2) and (3), the rotation was sampled from the full sphere with a slight preference around the canonical viewpoint - viewpoint of (1). More specifically, a rotation angle of 35' of the canonical viewpoint on all three axes was 1.5 more
likely than the rest of the sphere. For (3), we simulated a cotton-like cloth draped over the rotated mesh for a total of 100 simulation steps, and obtained a rendering of the very last step of the simulation.
We used a total of 197 meshes to generate 100 five-tuples of one study item of unoccluded object rendered at a canonical viewpoint with texture, and four test items consisting of two unoccluded objects without texture each rendered after randomly
rotating the meshes, and two objects rendered after randomly rotating each and then occluding with a cloth. The unoccluded study items were never seen twice, but the test items were repeated multiple times, each at a different rotation or viewing angle. On 57 of the 100 tuples, the distractors were of the same category, and 43 of the 100 tuples, the distractors were of different category. Example pairs of unoccluded study items and occluded test items are shown in Figure 3-2a.
3.2.3
Procedure
Both experiments were match-to-sample tasks where both the study and the test items were presented simultaneously and all stayed on the screen until the participants responded. In Experiment 1 (N = 27), the study item was an unoccluded image of
an object from a canonical viewpoint; the test items were images of two unoccluded objects after randomly rotating each. Participants had to choose which of the test items contained the study item (Figure 3-2b).
In Experiment 2 (N = 31), the study item was also an unoccluded image of an
object; but the test items were images of two objects rotated randomly and occluded with a cloth. Again, participants had to choose which of the test images contained the study item (Figure 3-2b).
In each of the experiments, participants completed 10 practice trials before moving onto 90 experimental trials. Participants were provided with their running average performance at every 5th trial throughout the experiment.
3.2.4
Results
Results of the experiments are shown in Figure 3-3a. Participants performance on Experiment 1 (with the unoccluded test items) were high overall (93%).
Participants performance was surprisingly high in Experiment 2 with the occluded test items at 80% (Figure 3-3a), and as expected, their performance was lower when compared to Experiment 1.
0.8
0.6
O.0.2
0
Figure 3-3: (A) Average performace of the participants in the two experiments. (B) Performance of the subjects divided by whether the distractor is of the same or different category as the study item. Error bars indicate standard error of the mean.
different category) introduced a much stronger decline in performance in Experiment 2 than in Experiment 1 (Figure 3-3b).
3.3
Models
We considered two models as potential accounts of our subject's performance: a physics-based analysis-by-synthesis model, and a model derived from features learned
by a deep convolutional neural network trained to classify millions of unoccluded
images.
3.3.1
Physics-based analysis-by-synthesis
We developed a Bayesian computational model that uses knowledge of the causal pro-cesses underlying image formation to interpret new images. Aspects of (synthetic) image formation may be divided into two categories: physics-based object factors (e.g., 3D shape, mass, friction, soft-body dynamics, soft-body and rigid-body interac-tion); and graphics (e.g. rotation and lighting direction). When each of these factors