A Categorization and Competitive Analysis of Web-Based Financial Information
Aggregators
By
Gregory C. Harman
Submitted to the
Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the Degree of Master of Engineering in Electrical Engineering and Computer Science
at the Massachusetts Institute of Technology February 16, 2001
Copyright @ 2001 Gregory C. Harman. All rights reserved.
The author hereby grants to M.I.T. permission to reproduce and distribute publicly paper and electronic copies of this thesis
and to grant others the right to do so.
Author
Department of Electrical Engineering and Computer Science February 16, 2001 Certified by Stuart Madnick Thesis Supervisor Accepted by - Arthi-C. Smith
Chairman, Department Committee on Graduate Theses
BARKER
MASSACHUSETTS INSI TUTEOF TECrFhr)jWi-,V JUL I 1 001
A Categorization and Competitive Analysis of Web-Based Financial Information
Aggregators
By
Gregory C. Harman Submitted to the
Department of Electrical Engineering and Computer Science February 16, 2001
In Partial Fulfillment of the Requirements for the Degree of Master of Engineering in Electrical Engineering and Computer Science
Abstract
Web-based aggregators use several business and technology models to operate. The business models are identified as: brokerages, merchants, advertisers, infomediaries, affiliates, and subscription-based services. The technology models are identified as: real-time agents, spiders, and manual information entry. The legality of unauthorized aggregation on the web is currently being decided by the American judicial system in a variety of ongoing cases. A sampling of major web-based financial aggregators is analyzed and the business and technology models being used are identified.
Thesis Supervisor: Stuart Madnick
Title: John Norris Maguire Professor of Information Technology & Leaders for Manufacturing Professor of Management Science
Table of Contents
A b stra c t ... 2 Table of Contents ... 3 T a b le o f F ig u re s ... 6 1 . In tro d u ctio n ... 7 2. Business M odels ... 9 2 .1 C riteria ... 9 2 .1.1 P ro fitab ility ... 10 2.1.2 Partnerships ... 10 2.1.3 Availability of Technology ... 10 2.1.4 Sustainability ... 10 2.1.5 Profitability Potential ... 10 2.1.6 Competition ... 11 2 .2 B ro k erag e ... 1 1 2.2.1 Profitability ... 12 2.2.2 Partnerships ... 12 2.2.3 Availability of Technology ... 12 2.2.4 Sustainability ... 12 2.2.5 Profitability Potential ... 13 2.2.6 Competition ... 132.2.7 Sum m ary of Criteria ... 13
2 .3 A d v ertisers ... 14 2 .3 .1 P ro fitab ility ... 14 2.3.2 Partnerships ... 14 2.3.3 Availability of Technology ... 15 2.3.4 Sustainability ... 15 2.3.5 Profitability Potential ... 15 2.3.6 Competition ... 15
2.3.7 Sum m ary of Criteria ... 15
2.4 Infornediary ... 16 2.4.1 Profitability ... 16 2.4.2 Partnerships ... 17 2.4.3 Availability of Technology ... 17 2.4.4 Sustainability ... 17 2.4.5 Profitability Potential ... 17 2.4.6 Competition ... 17
2.4.7 Sum mary of Criteria ... 18
2 .5 M erch an t ... 18 2.5.1 Profitability ... 18 2.5.2 Partnerships ... 19 2.5.3 Availability of Technology ... 19 2.5.4 Sustainability ... 19 2.5.5 Profitability Potential ... 19 2.5.6 Competition ... 19
2.5.7 Sum m ary of Criteria ... 20
2 .6 A ffiliate ... 2 0 2.6.1 Profitability ... 20 2.6.2 Partnerships ... 21 2.6.3 Availability of Technology ... 21 2.6.4 Sustainability ... 21 2.6.5 Profitability Potential ... 21 2.6.6 Competition ... 21
2.7 Subscription ... 22 2.7.1 Profitability ... 22 2.7.2 Partnerships... 23 2.7.3 A vailability of Technology ... 23 2.7.4 Sustainability ... 23 2.7.5 Profitability Potential... 23 2.7.6 Com petition ... 24
2.7.7 Sum m ary of Criteria ... 24
3. Aggregation Technologies... 25
3 .1 C rite ria ... 2 5 3.1.1 Ease of Im plem entation ... 25
3.1 .2 Durability ... 26
3.1.3 Resistance to Blockage ... 26
3.1.4 Accuracy of Inform ation... 26
3.1.5 Quantity of Inform ation ... 26
3.1.6 Target Friendliness ... 26
3.2 Real-Tim e A gent ... 27
3.2.1 Ease of Im plem entation ... 27
3.2.2 Durability... 27
3.2.3 Resistance to Blockage ... 28
3.2.4 Accuracy of Inform ation... 28
3.2.5 Quantity of Inform ation ... 28
3.2.6 Target Friendliness ... 29
3.2.7 Sum m ary of Criteria ... 29
3.2.8 Real-W orld Exam ples... 30
3 .3 S p id er... 3 1 3.3.1 Ease of Im plem entation ... 33
3.3.2 Durability ... 33
3.3.3 Resistance to Blockage ... 34
3.3.4 Accuracy of Inform ation... 34
3.3.5 Quantity of Inform ation ... 34
3.3.6 Friendliness to Target ... 34
3.3.7 Sum m ary of Criteria ... 35
3.3.8 Real-W orld Exam ples... 35
3.4 M anual Entry ... 37
3.4.1 Ease of Im plem entation ... 38
3.4.2 Durability ... 38
3.4.3 Resistance to Blockage ... 38
3.4.4 Accuracy of Inform ation... 38
3.4.5 Quantity of Inform ation ... 38
3.4.6 Friendliness to Target ... 39
3.4.7 Sum m ary of Criteria ... 39
3.4.8 Real-W orld Exam ples... 39
4. Com m ercial Applications ... 41
4.1 L oan Interest Rates ... 42
4.1.1 Business M odel Usage... 42
4.1.2 Technology M odel Usage ... 43
4.2 Insurance Rates... 44
4.2.1 Business M odel Usage... 44
4.2.2 Technology M odel Usage ... 44
4.3 Investm ent Rates... 45
4.3.1 Business M odel Usage... 45
4.3.2 Technology M odel Usage ... 46
4.4 Consum er Product Inform ation ... 46
4.4.1 Business M odel Usage... 46
4 .5 A irfa re... 4 8
4.5.1 Business M odel Usage... 48
4.5.2 Technology M odel Usage ... 48
4 .6 A u ctio n s ... 4 9 4.6.1 Business M odel Usage... 49
4.6.2 Technology M odel Usage ... 50
4.7 Frequent Flier M iles ... 50
4.7.1 Business M odel Usage ... 50
4.7.2 Technology M odel Usage ... 51
4.8 Account Consolidation ... 52
4.8.1 Business M odel Usage... 52
4.8.2 Technology M odel Usage ... 53
4.9 Auction Consolidation ... 53
4.9.1 Business M odel Usage ... 53
4.9.2 Technology M odel Usage ... 54
5. Legal Issues Surrounding Aggregation... 55
5.1 The Issues ... 55
5.1.1 Ownership of Inform ation ... 55
5.1.2 Copyright Infringem ent ... 55
5.1.3 Im plied Contracts... 56
5.1.4 Advertiser Contracts ... 56
5.2 Solutions ... 56
5.2.1 Four Law s of W eb Robotics ... 56
5.2.2 The Six Com m andm ents for Robot Operators... 58
5.3 Legal Rulings... 59
5.3.1 Ebay v. Bidder's Edge ... 59
5.3.2 N ew s Index v. The Sunday Tim es ... 59
5.3.3 R.I.A .A .v. N apster ... 60
5.3.4 Ticketm aster v. Tickets.com ... 60
5.4 Future D irection... 61
6. Conclusion ... 62
Appendix A : Results of Com pany Categorization Grouped by M odel ... 63
Technology M odels ... 63
Business M odels ... 65
Appendix B: Categorization of M ajor Online Aggregators... 67
Table of Figures
Figure 1 Rating of business models vs. specific criteria... 9
Figure 2 Summary of Broker criteria... 13
Figure 3 Summary of Advertiser criteria... 16
Figure 4 Summary of Infomediary criteria ... 18
Figure 5 Summary of M erchant criteria ... 20
Figure 6 Summary of Affiliate criteria ... 22
Figure 7 Summary of Subscription criteria... 24
Figure 8 Rating of technology models vs. specific criteria... 25
Figure 9 Summary of Real-Time Agent criteria... 30
Figure 10 Example state-set for search discussion. ... 32
Figure 11 Summary of Spider criteria ... 35
Figure 12 Summary of M anual Entry criteria... 39
Figure 13 Current Aggregation M arkets... 42
Figure 14 Loan Interest Rates - Business M odel Usage ... 42
Figure 15 Loan Interest Rates - Technology Usage M odels ... 43
Figure 16 Insurance Rates - Business M odels ... 44
Figure 17 Insurance Rates - Technology M odel Usage ... 44
Figure 18 Investment Rates - Business M odel Usage... 45
Figure 19 Investment Rates - Technology M odel Usage ... 46
Figure 20 Consumer Product Information - Business M odel Usage... 46
Figure 21 Consumer Product Information - Technology M odel Usage... 47
Figure 22 Airfare - Business M odel Usage ... 48
Figure 23 Airfare - Technology M odel Usage ... 48
Figure 24 Auctions - Business M odel Usage ... 49
Figure 25 Auctions - Technology M odel Usage ... 50
Figure 26 Frequent Flier M iles - Business M odel Usage... 50
Figure 27 Frequent Flier M iles - Technology M odel Usage... 51
Figure 28 Account Consolidation - Business M odel Usage... 52
Figure 29 Account Consolidation - Technology M odel Usage... 53
Figure 30 Auction Consolidation - Business M odel Usage ... 53
Figure 31 Auction Consolidation - Technology M odel Usage ... 54
Figure 32 Real-Time Agent Usage ... 63
Figure 33 Spider Usage ... 63
Figure 34 M anual Entry Usage... 64
Figure 35 Brokerage Usage ... 65
Figure 36 Advertiser Usage ... 65
Figure 37 Infomediary Usage ... 65
Figure 38 M erchant Usage... 66
Figure 39 Affiliate Usage ... 66
1. Introduction
The advent of the Internet has created a deluge of information on almost every topic. Since the (commercial) Internet was largely developed under strong capitalism, a great deal of this information deals with commercial enterprises. Much of this
information is related to direct sales, or to the research and ownership of equities relating to these sales. Information about competing companies can be obtained. Some websites, known as aggregators, make a business of compiling this information and presenting the comparisons to their users.
Historically, financial aggregation services were available only to the rich by investment advisers, private bankers, etc.' some mass-marketed software has been available since the advent of personal computers, bringing aggregation abilities to the general public, but this software was difficult to use. Only with the advent of the web has financial aggregation been a viable option for the majority of consumers.
This paper is a critical analysis of those aggregators that compile financial information on the web. It will attempt to define and then analyze the merits of several different business and technological models used by aggregators today. It will also provide an overview of the specific commercial markets in which aggregators are
competing and the current state of the legalities that concern aggregation. Finally, it will contain an appendix listing most of the major financial aggregators in business today, and describing the business and technological models to which they subscribe.
In this paper we will define the term aggregator with the following, taken from
Madnick et al.2:
An aggregator is an entity that transparently collects and analyzes information from different data sources. In the process, the aggregator resolves the semantic and contextual differences in the information.
As the definition suggests, there are two characteristics specific to an aggregator.
I. Transparency -There are two aspects to transparency. First, the data sources cannot differentiate an aggregator from a normal user who is accessing the information. Consequently, data sources cannot deny
access to an aggregator. Second, the aggregator resolves the contextual differences to allow for comparison of equals.
2. Analysis -Instead of simply presenting the data as-is, the aggregator synthesizes value-added information based on post-aggregation analysis.
It is important to note that, under our definition, search engines, such as Lycos and Alta Vista, and personalized Web portals, such as My Netscape or My Yahoo, are not aggregators. Similarly, Web-based malls, category e-store, or community-based Web sites also do not fit under this category. Although these Web sites amass different information, little is done to integrate and analyze that information.
This paper will focus specifically on aggregators that gather and display their information primarily through the World Wide Web, and specifically on those that are concerned with financial information. We will, however, take a loose definition of what information qualifies as "financial." In addition to that information which pertains to the traditional definition: information about markets, equities, interest rates, etc., we will also include information concerning insurance rates, auctions, online relationship aggregation, airfare, and the price of consumer products.
2. Business Models
2.1 Criteria
Every (successful) company makes money. The way in which they do this is referred to as their business model. We will define business model as "a company's value proposition for making money."3 In this section, we will define and discuss different business models that aggregation companies can apply to derive profit from their business.
First, a set of criteria will be established to provide an effective way to evaluate and compare these different business models. Next, several possible business models will be defined and then analyzed, based on the established criteria. These models have been adapted from "Business Models on the Web" by Professor Michael Rappa of NC
.4 State University .
The results of this analysis are summarized below in Figure 1. Note that while this data presents certain models as superior to others in the various criteria that each model is still best-suited for certain markets due to their fundamental differences. These differences are discussed in this section, and the best applications for each model are discussed later in this paper.
Profitability Partnerships Availability Sustainability Profitability Competition
of Potential Technology Brokerage + Advertiser + Infomediary + + Merchant + + + Affiliate + + Subscription
2.1.1 Profitability
The first criterion will be time to profitability. No matter how much initial funding a company receives, it is still a fixed amount that will eventually be used up. The company must eventually turn a profit and support itself. And, ultimately, that is the purpose of operating the company! We must also take into account the start-up cost of the business. The more in-debt a company is and the greater the start-up cost, the longer
it will take to become profitable.
2.1.2 Partnerships
In order to most efficiently tap all of its target markets, a company may require the services of another company that has access to those markets. These partnerships can be a great boon to both companies, but a partnership is not completely under the control of either company; therefore, by entering into a partnership, a company introduces an element of risk. The number of (and difficulty to acquire) required partnerships will be our second criterion.
2.1.3 Availability of Technology
Our third criterion will be the availability of necessary technology. In order to build its product or service, a company will need to use certain technologies.
Technologies able to achieve the given task may not yet be developed sufficiently for commercial application, or may require licensing fees that outweigh the profit to be made
by their application.
2.1.4 Sustainability
The fourth criterion will be sustainability. In order for a company to truly provide value, its business model must be sustainable over a long period of time. With the
current pace of technological innovation, an unsustainable business model may become outdated and no longer work before a company has even turned a profit!
2.1.5 Profitability Potential
The fifth criterion will be profitability potential. A company's business model must be capable of providing an adequate return on the capital investment. Certainly, this
return must be more than that same capital could return in a less risky investment; but since a start-up company is so risky (only 1 in 10 new companies survive to
profitability),5 the return must be that much greater.
2.1.6 Competition
The final criterion will be the level of competition. Every market is of limited size, and several companies will compete to capture as much of the given market as possible.6 In fact, there is generally only room for two or three companies to be successful in any given market.7 In addition, the "first mover advantage" is often
considered to be a benefit for companies. For example, Yahoo, the first major portal has been extremely successful, and is still the top portal site on the web. However, being the first mover certainly does not guarantee success. Juno, for example, was the first
company to offer free email, but Hotmail is by far the leading provider of free email today. In conclusion, the timing of a company's entry to market can be quite important, but being the first is not always a guarantee for success.
2.2 Brokerage
Our first business model is the Brokerage Model. Brokers connect buyers and sellers and facilitate transactions. The business models suggested by the buzzword-abbreviations "B2B" (Business to Business), "B2C" (Business to Consumer), "C2C" (Consumer to Consumer), "B2E" (Business to Enterprise), etc. are Brokers. Rappa lists nearly dozen subcategories of the Brokerage Model. The Buyer Aggregator, Auction Broker, and Search Agent subcategories are especially relevant to the topic of financial information aggregators .
A Buyer Aggregator, such as MySimon.com, allows users to find the best buy on
a particular item regardless of the seller. It scans the major Internet retailers and presents the user with a price comparison. The user can then connect to the dealer that offers them the best value. An Auction Broker, such as AuctionWatch or Bidder's Edge, provides the same service across online auctions instead of online retailers.
2.2.1 Profitability
A Broker provides value in the form of arranged partnerships and acts as a
medium for communication between companies, between consumers, or between companies and consumers. Before it can begin to derive profit from these partnerships, the Broker must first accumulate sufficient quantity of users within its site to provide the best partnerships possible, and to foster a sufficient community to maintain the creation of these relationships. The speed at which these communities can be formed is critical. It is fairly straightforward that a broker cannot bring in revenue until there are users on its site. If the broker cannot bring in revenue before it runs out of funding, then it is out of business.
2.2.2 Partnerships
While brokers are not completely dependent on partnerships to further their business, they can certainly use them to their advantage. In the case of a Buyer
Aggregator, for example, the aggregator may not need to partner with a seller to rate its information, but may find it much easier to do so. If the seller freely provides
information about the its products, then the Buyer Aggregator won't need to use an aggregating agent to retrieve this information. In addition, this partnership will alleviate any possible legal concerns (see later discussion of legal issues).
2.2.3 Availability of Technology
The technology necessary for a brokerage spans the entire range of depth. While some brokers can be little more than electronic storefronts, others, such as automatic aggregators, can push the limits of technological feasibility. In order to retrieve its information, an aggregator may have to employ various forms of spidering technology, which will be discussed later.
2.2.4 Sustainability
Brokers connect buyers and sellers and, as such, are "middle-men." The Brokerage model seems sustainable in the short-run, but as middlemen, Brokers must
continue to provide value or it is conceivable that they could be driven out of the economy leaving only direct relationships between buyers and sellers. Today, Brokers add cost to the supply chain while providing the service of connecting sellers and buyers. Technology could eventually supply this need more readily, forcing the Brokers to find new ways to add value to the supply chain. For example, recent versions of Apple's
MAC OS, discussed later, provide an automatic Buyer Aggregator. 2.2.5 Profitability Potential
A Broker wants to be in the middle of every transaction. This in itself can be
enormous, but a Broker also has the potential to apply other business models as well, creating many sizable sources of income. For example, almost every website, including Brokers, advertise to their users. Many of these advertisements take the form of click-through banners, providing a means for affiliate partnerships and marketing information sales (the Infomediary model).
2.2.6 Competition
There is a great deal of competition for Brokers. Because of the high profitability potential, everyone wants to be in this position. The partnerships that a brokerage has greatly define its worth, and if one broker has an exclusive partnership in a given market, then all competitors will not have access.
2.2.7 Summary of Criteria
Brokers face heavy start-up costs and intense competition. They are in some danger of being replaced by new technology if they do not continue to provide a value that the technology cannot. However, the potential profit for a Broker is enormous. Profitability Partnerships Availability Sustainability Profitability Competition
of Potential
Technology
2.3 Advertisers
The next business model is the Advertising Model. This model follows that of traditional media broadcasting9. The website offers content - usually for free - and thus attracts a large user base. Advertisers then pay for ads viewed by these users. Portals of all types (generalized, personalized, and vertical), incentive sites, and free sites that give a service, such as Internet access or hardware, subscribe to the Advertising Model10.
Yahoo is perhaps the most prominent advertiser, as most of its revenue is derived from advertisement.
2.3.1 Profitability
Advertisers must accumulate a significant user base before they have sufficient hits to attract major clients. Once they have these clients, they must wait for the revenues to trickle in, as the per-view fees are very small. Advertisers are generally completely
internet-based, and so have few physical expenses; most of their initial funding will go to advertisement for themselves. The faster they can attract a large user base, the faster they can bring in significant revenue, which will shorten their time to profitability. Also, the startup costs can differ greatly among different companies, depending on their chosen method of attracting a user base. For example, a free Internet service, such as Free! or NetZero, must support the expenses of an ISP without the immediate reimbursement by the consumers that traditional ISPs enjoy. An alumni website, however, requires very
little cost to maintain -just the production and hosting of the web site, and comes with an instant user base.
2.3.2 Partnerships
Since their sole source of income is advertisements paid for by clients, advertisers are completely dependent upon their partnerships with these clients for profit. Luckily, there is an overwhelming demand for targeted advertisement, which in 1998 had revenues of $2 billion'2 and is growing at 200% per year.'3
2.3.3 Availability of Technology
Advertising requires very little unique technology. Most online advertising takes the form of banner advertisements that are displayed to the side of a screen containing content. The number of page views may be measured with a simple counter. Though the methods of advertising may change with new technology, the need for companies to inform potential customers of their value will not change.
2.3.4 Sustainability
The need for advertisement depends only on the strength of the economy, specifically the number of businesses with products and services to sell. The more businesses there are, the more advertising that will be necessary; the need for advertising for existing businesses will not change. Unfortunately for advertisers, many of them have fallen upon hard times since the NASDAQ crash in early 2000. Very few advertisers are successfully turning a profit, and many analysts think that the future is
dim for all but the largest pure advertisers. 2.3.5 Profitability Potential
High-profile advertisers with many hits to their websites can make a good profit, since the fees are generally based on the number of views an advertisement receives, but ultimately there is a defined limit to the number of advertisements that a site can display. 2.3.6 Competition
Almost every commercial website utilizes advertisement, but companies are willing to advertise in multiple locations. In fact it is to the client company's advantage to do so, so the only limitation is the budget that the company has allocated to
advertising. However, the low barriers to entry (very little startup-cost and easily
available technology) have created a huge number of advertisers. In addition to the pure advertisers, most other online businesses still derive some profit from advertisement. 2.3.7 Summary of Criteria
Advertising businesses are technologically simple to enact, and are likely to be sustainable well into the foreseeable future, dependent on the markets in general.
Competition is heavy because of the low barriers to entry, however these companies may have significant start-up costs to repay on an initially slow income.
Profitability Partnerships Availability Sustainability Profitability Competition
of Potential
Technology
Figure 3 Summary of Advertiser criteria
2.4 Infomediary
The third business model is the Infomediary Model. Infomediaries record data about their customers' browsing and spending habits. This information is then used in
focused marketing campaigns, and often sold to other firms. Sites in which users rate and recommend products, services, and companies, and content-based sites that are free but require registration fall under the Infomediary Model'.
DoubleClick is a well-known Infomediary. Privacy issues surrounding the Infomediary model and focused specifically on DoubleClick have come to light recently. What is and is not acceptable use of the marketing information has come into question. DoubleClick used cookies to track users' online activities, sometimes without the explicit consent of those users.'5 Privacy advocates claim that this is a deceptive practice that invades the privacy of the users. DoubleClick says that it provides an opt-out system that gives fair warning to the users; again, this is criticized by the privacy advocates as being confusing and therefore not providing "genuine informed consent."
2.4.1 Profitability
Before an Infomediary can sell its market data, it must first collect that data. This can be a time-consuming process, as it waits for users to contribute (regardless of
whether or not it is voluntary) their information. Once this information is collected, it may be analyzed to provide more value. An Infomediary does not have significant physical start-up costs, and does not generally spend large amounts on consumer advertising; therefore the start-up costs are relatively low.
2.4.2 Partnerships
If it operates its own site, an Infomediary generally does not require any specific
partnerships beyond the standard buyer/seller relationship that it has with its clients. However, some Infomediaries enable other content-oriented sites to collect consumer data, in which case the partnerships become all-important. Therefore an Infomediary spans the entire range of liability in regard to partnership requirements.
2.4.3 Availability of Technology
Infomediaries must keep track of customer profiles and track their movements on the Internet. This is not particularly difficult from a technological standpoint - users are logged into the website, and their choices are recorded. However, this can result in an enormous mass of information that must be analyzed to be useful. Luckily for the Infomediaries, statistical analysis software is readily available.
2.4.4 Sustainability
Though technologies and markets change, companies always need to know and to re-assess whom their customers are. The technologies utilized by Infomediaries will certainly change, but the basic need for their services will not.
2.4.5 Profitability Potential
Infomediaries derive profit by selling relevant market information to companies. Companies always need this information, but there are only so many companies to go around, so the market for this business model is limited in a similar way to Advertisers. 2.4.6 Competition
There is no shortage of data to collect, but Infomediaries must compete with each other to sell their information to clients as client companies can afford only so much market data. This data can only be as varied as the number of markets available, and additional data simply hones the accuracy of the statistical analysis. There is a point at which more accuracy is not useful, therefore the space is defined by the number of markets, rather than the amount of data available. Competition for these limited spaces is not light.
2.4.7 Summary of Criteria
Infomediaries fill a real need of most other businesses, and this need will not disappear, leaving a very sustainable future. The profit can come slowly, but the start-up costs are also relatively small.
Profitability Partnerships Availability Sustainability Profitability Competition
of Potential
Technology
Figure 4 Summary of Infomediary criteria
2.5 Merchant
Our next business model is the Merchant Model. Merchants on the Internet function just as offline merchants, or "brick-and-mortar" companies, do. Many larger retailers have online presences, but Internet-only businesses, "e-tailers," also compete with them. Merchants in every offline market have moved to compete online, and new exclusively online companies have sprung up to compete with them. Perhaps the most notable competition has been between the online bookseller Amazon.com and its "brick-and-mortar" counterpart, Barnes and Noble, which has an online presence at bn.com. 2.5.1 Profitability
A merchant sells a product, and therefore makes a profit on each sale
immediately, regardless of the size of that profit. However, a merchant has significant startup costs to address. In addition to the costs of building and maintaining a web site, selling a physical product requires either a warehouse or manufacturer, and distribution must also be taken into account. This very significant distribution cost is one that is not incurred by Infomediaries or Advertisers. This cost includes supply chain expenses and extra customer service staff.16 Since merchants must rely on customers to find them, advertising costs are also quite significant.
2.5.2 Partnerships
A Merchant may advertise, create an affiliate program, or provide content to draw
customers, but, just like the traditional offline merchant, its primary method of doing business is to sell products directly to consumers. In general, the only partnerships a merchant, either online or off, is likely to have are those with their distributors and manufacturers, although some merchants may benefit from working together to present product packages to their customers.
2.5.3 Availability of Technology
Merchants have fairly straightforward technical operations from a purchase standpoint. Customers select items, which are stored in a "shopping cart," and are then "checked out" by placing a charge on the customer's credit card. However, once the order is placed, the items must be appropriately retrieved and shipped to them from the company's warehouse. This process can be an operational nightmare, and has been the weak spot for many companies following this model. For example, one of the biggest problems for Amazon.com is its product distribution, and it is considering outsourcing the entire operation.'7
2.5.4 Sustainability
The role of a Merchant, selling goods and services to consumers, is quite stable. As long as currency exists, people will need to exchange their currency for goods and
services.
2.5.5 Profitability Potential
The profitability potential of a merchant online is similar to that of an offline merchant, with the added advantage of having direct access to a non-localized customer base. However, distribution costs can eat into profits, as can the increased amount of advertising necessary.
2.5.6 Competition
Online merchants must compete with each other to provide the lowest prices and the greatest values, as do their offline counterparts. Online, these merchants compete
against every other merchant in their market segment regardless of location, as location no longer separates markets. In addition, the entry costs can be lower for an online merchant than for a standard "bricks-and-mortar" merchant, and as a result many upstart online-only merchants have sprung up to compete as well.
2.5.7 Summary of Criteria
Merchants have significant start-up costs, but also have a significant revenue stream. They supply their own products, and therefore do not rely upon partnerships with other companies out of their direct supply chain. The profitability potential is large, and the need that merchants fill is not likely to disappear. Because of these positive traits, there is extremely heavy competition among merchants.
Profitability Partnerships Availability Sustainabiity Profitability Competition
of Potential
Technology
Figure 5 Summary of Merchant criteria
2.6 Affiliate
Next, we have the Affiliate Model. Similar to the Advertising Model, Affiliates derive their income through advertisements, generally in the form of banners. Affiliates, however, do not get paid simply because one of their banners are viewed. If a user connects to a client site through a banner and makes a purchase, the affiliate receives a percentage of the sale. Affiliation has been especially successful in the online
pornography industry.'8 This industry was one of the first to successfully adopt an
Affiliate model and its example was followed by the more mainstream websites, such as Amazon.com and Bn.com.
2.6.1 Profitability
Affiliates take in profit on each referral starting with the first one, however these incremental profits are quite small. An affiliate has no physical start-up costs, and may only need a moderate amount of advertising, since it makes the same profit-per-referral regardless of volume.
2.6.2 Partnerships
By definition, Affiliates are dependent on having companies with whom to
affiliate. An Affiliate's entire business proposition is based around partnerships. 2.6.3 Availability of Technology
Affiliates require similar technology to advertisers. Banner advertisements are displayed on the page, with a link pointing to the advertiser. These links contain information identifying the affiliate so that they can be credited for the referral. 2.6.4 Sustainability
Affiliates are also middlemen. The service they provide is the referral of customers to sellers. In this sense, they are similar to Brokers. The difference lies primarily in the method of referral. An affiliate could be said to provide a passive referral, whereas a Broker provides an active one. That is, while a Broker provides a marketplace for transactions to occur, an Affiliate gathers buyers and brings them to a marketplace provided by a seller.
2.6.5 Profitability Potential
Affiliates extract a small percentage of the profits from any referred purchase. While affiliates have much lower operating costs, not selling an actual product, they also make far less from each transaction than the merchants with which they are affiliated. For example, affiliates of Amazon.com, which runs the largest affiliate network on the Internet, earn between 5% and 15% of the revenues on an item that they sell. This leaves
85%-95% of that revenue for Amazon.com.
2.6.6 Competition
The merchant sites that partner with Affiliates want to receive as many referrals as possible, so there is no competition among Affiliates to obtain these affiliate
2.6.7 Summary of Criteria
Affiliates must rely heavily on partnerships with other companies. Their lifetime may be limited, and the profitability potential during this lifetime seems to be meager compared with other business models. However, an affiliate site is technologically simple to enable, and competition is very light. Profits will be seen relatively soon. Because the profit per transaction is so slow, an affiliate needs a significant volume. This is a case of quantity over quality of transactions.
Profitability Partnerships Availability Sustainability Profitability Competition
of Potential
Technology
Figure 6 Summary of Affiliate criteria
2.7 Subscription
The final model we will examine is the Subscription Model. Traditional print magazines follow the Subscription Model; customers pay a fee to view content. The fee can be paid per time period, or per byte viewed. This concept has not proved successful on the Internet for traditional news content - users simply will not pay for it, since so
many free sources are available - but there are other forms of information for which this
model can work. Many major print publications have online versions, for example, Hoover's Online. Games have also proven to be very attractive content.
2.7.1 Profitability
A Subscription service sells content to viewers. It needs a significant user base in
order to derive profit since generating the content has a fixed cost, regardless of the size of the user base. Once this fixed cost is covered, however, any additional customers are pure profit. Similar to an Advertiser, there are no significant physical expenses involved,
2.7.2 Partnerships
A basic Subscription service does not require any partnerships to operate their
business, as it simply creates and sells content. Of course it can outsource part of the content generation, and all businesses need to advertise, but this is certainly not a requirement of the basic model.
2.7.3 Availability of Technology
Subscriptions require a site to record user accounts in a database and to allow the content to be viewed only by owners of those accounts. Issues such as a browser's back button and bookmarks must be addressed, both to protect the site from unauthorized views and to enable the customer access to his purchased content.
2.7.4 Sustainability
The value of providing content to people will not change with technology; only the means of providing that content will change. To illustrate, we can examine the changing methods for managing stocks. Traditionally, stock information was obtained through daily newspapers, and more up-to-date information, as well as transactions, was available from a broker. With the advent of the Internet, this information became
available from a desktop PC. Obtaining this information was now far easier than before, and a greater variety of this information was available. Today, this information is all available on the wireless web. In this case, three major methods of information
acquisition via different technologies have been used in the past 10 years, but the value of stock information has remained unchanged.
2.7.5 Profitability Potential
A Subscription service has the profitability advantage of frequent repeat
customers, as content can be updated, as in a daily newspaper or monthly magazine. Repeat customers have no acquisition cost, unlike new customers. However, the customer base is limited to the number of people who fall into the target segment, and that is generally a fixed number. Heavy advertisement is required to expand that target segment.'9
2.7.6 Competition
Subscription services must compete for their market segments exactly as standard print publications do. There are only so many readers in a given market, and while these customers may subscribe to multiple subscriptions, there is a limit to the amount of information they can use. With the added ease of publication, these sites must compete not only with print publications, and other similar sites, but also with a growing number of free sites that provide similar information. On the other hand, subscription services tend to be targeted toward a niche consumer group, and since this consumer group will generally be limited, a significant number of competitors cannot be sustained.
2.7.7 Summary of Criteria
A Subscription model business provides a service that will be indefinitely in
demand. It does so with relatively simple technology and independence from outside partnerships. The major drawback is stiff competition due to a limited market. Profitability Partnerships Availability Sustainabiity Profitability Competition
of Potential
Technology
3. Aggregation Technologies
3.1 Criteria
In this section, we will discuss the different technologies that drive web-based financial aggregators. First, a set of criteria will be established to provide an effective way to evaluate and compare these different technologies. Then several general categories of technologies will be established and further broken down into specific technology models. Each of these models will be defined and then evaluated by the rating criteria previously established. Current implementations, both commercial and non-profit, will be discussed in detail.
The results of this analysis are summarized below in Figure 8. Note that while this data presents certain models as superior to others in the various criteria that each model is still best suited for certain applications due to their fundamental differences. These differences are discussed in this section, and the best applications for each model
are discussed later in this paper.
Ease of Durability Resistance Accuracy of Quantity of Target Implementation to Information Information Friendliness
Blockage Real-Time Agent Spider + Manual Entry
Figure 8 Rating of technology models vs. specific criteria
3.1.1 Ease of Implementation
The first criterion will be the ease of implementation for the technology. In this age of accelerated obsolescence, it is crucial that a technology be quickly applied. Time-to-market for an Internet venture is quite short and new technologies are developed all the time. In addition, a complex implementation requires a larger technical staff, increasing the costs of the company.
3.1.2 Durability
The second criterion will be durability. I will define durability as scalability, and longevity. If an application is not sufficiently scalable or will be quickly obsolete and unable to perform the necessary services, then it will have to be replaced faster, resulting in the cost of a second implementation before it would otherwise be necessary.
3.1.3 Resistance to Blockage
The third criterion will be resistance to blockage. Because many aggregations may not be welcome by the aggregatees, a resistance to blockage will be essential to maintaining a reliable aggregation technology. In addition to intentional blockages, an aggregator needs to be able to circumvent network problems to provide a reliable source of information despite outages or other problems.
3.1.4 Accuracy of Information
The fourth criterion will be accuracy of information. In any transition of data, there is the possibility of data loss or corruption. Obviously, this is a detrimental factor to any data transfer and should be minimized.
3.1.5 Quantity of Information
The fifth criterion will be quantity of information. Using an aggregation technology has a cost in hardware and processing time. The more information a technology can retrieve, the smaller an implementation can be used. Every technology uses a set amount of system resources (memory, processing time, etc.). A more efficient technology will retrieve the same information with fewer resources; this corresponds to a lesser expense to operate that technology and obtain the information.
3.1.6 Target Friendliness
The sixth criterion will be friendliness to the target site. A technology that adds a significant load to the target's servers will not be welcome on that site.
3.2 Real-Time Agent
The first major type of aggregation technology is active autonomous searching. Technologies of this type gather information from other public sources, primarily other web pages, and index or store this information on the local machine. They are sometimes known as "bots," because they act like an electronic person, browsing different web pages, and writing down what they find. There are two major methods of active
autonomous searching: agents and spiders (also known as robots or wanderers).
Agents in general can be defined as "personal software assistants with authority
delegated from their users.20 More specifically, agents as we will refer to them in this
paper, are pieces of software that intelligently surf the web in real-time in response to a specific request from a user or another agent. They attempt to process the web pages to which they are assigned, retrieve only data that is useful and relevant to their assignment, and navigate the web accordingly. A financial aggregator might have an agent
automatically collect stock quote data from other leading sites, or fill out loan application forms with given parameters and report the resulting rates.
3.2.1 Ease of Implementation
Agents are not particularly easy to implement. Until recently, agents existed only in controlled laboratory environments. These agents were often run on very proprietary networks, and with extremely simple tasks to carry out relative to our concerns. Generic real-time agents have recently become commercially available, (for example, SWI Systemware, Inc. created and supports real-time agent applications on AuctionWatch, among others) but they are expensive and difficult to configure. On the other hand, an aggregation company could build agents in-house, but that would involve a concerted long-term effort by a skilled engineering team.
3.2.2 Durability
A well-designed agent should be adaptable to changing situations, resulting in a
longer useful lifespan. An agent's power can be increased with increasing hardware, and given the standard format of the web, an agent can be expected to operate as long as that format is intact.
3.2.3 Resistance to Blockage
A real-time web agent must gather its information when called. If there is an
obstacle obstructing that agent over repeated attempts, then it cannot complete its task, and will fail. Agents do exhibit intelligent behavior, and may have a limited ability to attempt to circumvent a problem. When the problem is beyond the abilities of the agent, then it will return to its operator and ask for help. For example, an agent designed to automatically log in to a web site may first try to directly view the desired URL. If this is not successful, then it may start at the site's home page, and navigate through a login
script. If this also fails, then the agent will inform the user that it was not successful, and request further "training." Many account aggregators, such as Clickmarks, work this way.
3.2.4 Accuracy of Information
An aggregating agent will directly view other web data, as would a human user. However, the agent is still limited in its ability to interpret that data by the strength of its algorithm, and some degree of error is probable. In addition, the agent, if it is free to select the sites it views, cannot determine whether that site is likely to have valid information.
3.2.5 Quantity of Information
An agent is limited in the amount of information it returns by the efficiency of its algorithm, the power of its processor, the speed of its network connection, and the amount of time given to complete the task. We will assume that the agent has a reasonable algorithm and has been trained to its specific task. Processor speed is generally not a limiting factor, except that it has a certain time period in which to complete the given task. Most computer applications today do not make full use of the processor2, which Moore's Law tells us is doubling in power every 18 to 24 months. In addition, multiple processors can be used together in order to increase speed as might be necessary. High-speed networks and connections to the Internet are readily available for all companies. Financial information, unlike video and audio files, is fairly small in size, so network speed is also not a limiting factor. For comparison, an average Mpeg-3
format audio file is 3-4 megabytes in size, while a collection of information about the exchange rates of the major currencies of the world averages around 10 kilobytes.2 2 A real-time agent must return its results to a user within seconds; the average user will give up and move to a different site if it does not load within eight seconds.2 3 This limited
search time can definitely be a limiting factor. 3.2.6 Target Friendliness
An agent must accomplish as much as possible in a short period of time. In order to meet this goal, a web agent may send as many requests as its network will hold.
However, this automated probing can use up the targets' precious bandwidth.24 At the
beginning of this year, for example, many major websites were brought down by denial-of-service attacks. This sort of attack simply sends a rapid stream of requests to a web server, bogging down its resources until it can no longer adequately respond to legitimate users.
There are standards in place to address this problem (see section 4), but these will limit the effectiveness of the agent, creating a fundamental trade-off between agent friendliness and the amount of information an agent can return. Additionally, an agent may have to masquerade as a human in order to gather its information, filling the target database with fictitious data. For example, the agent behind an auction aggregator, such as AuctionWatch, will simply navigate through an online auction, such as Ebay, using the same steps a user would. It logs on under a fictitious account, follows the same links, and fills out the same forms that human user would encounter. Because it follows the same path, it is indistinguishable from a human user to the server in terms of online behavior.
3.2.7 Summary of Criteria
To summarize, the current real-time agent technology is lacking in several areas. It is extremely difficult to implement. While in operation, it is susceptible to blockage, cannot be relied upon to always return accurate data, and can be a burden on the target servers. On the other hand, real-time agents can return a reasonable amount of
Ease of Durability Resistance Accuracy of Quantity of Target Implementation to Information Information Friendliness
Blockage
Figure 9 Summary of Real-Time Agent criteria
3.2.8 Real-World Examples
There are many web-based aggregation businesses that make extensive use of real-time agents. Agents are a necessary technology when real-time data is needed, and that data is too customized or complex to be obtained via a standard news feed (discussed later).
One such company is AuctionWatch. AuctionWatch uses real-time agents to conduct searches across many auction sites. Since auctions are timed, and constantly updated, a real-time solution is needed. AuctionWatch consolidates information made publicly available on these sites with automated agents; there is no other method
available, aside from an actual human conducting the task. An agent's shortcomings are not a problem in this case, because the number of auction sites is set and relatively few, and these sites do not often change their format; the agent can quickly learn all it needs to about its task, and this can be directly programmed or taught by human users.
AuctionWatch also makes use of real-time agents to help users place items up for bid on these auction sites. These agents need not conduct a search of information displayed on the auction sites, but rather keep track only of the format of product submission forms. They provide one common interface to users placing an item up for bid, then
automatically translates that information into a format understood by the auction sites and posts the items.
Another company that extensively utilizes agents is Clickmarks. Clickmarks allows its users to create a custom habitat consisting of any web content, including news headlines, email accounts, online calendars, etc. All of this information is gathered and kept current by way of sophisticated agents. A user can view the information in their habitat and expect it to be kept current with the original source. If it is not current, the
user is notified, and has the option to deploy the agents at any time to retrieve the most current information.
3.3 Spider
Often, information does not change so fast that a real-time aggregation is
necessary. In this case, conducting real-time searches results in many repetitive results, and therefore unnecessarily consumes resources. A better solution would be to determine how often the data is likely to change, and then conduct a single search after each change and store the results in a local database. These results can then be searched on an
aggregator's local machines, resulting in a far more efficient search without the
complication of using up the computational resources of the aggregatee. For example, frequent flier information is updated with a delay of up to several days. A daily update
by an aggregator is sufficient. This is known as indexing, and the software solution,
defined in this paper as a timed agent, is known as a "spider."
There are two methods that an individual spider can use to search the web; multiple spiders working in tandem can also be used, and will be discussed later. Let us
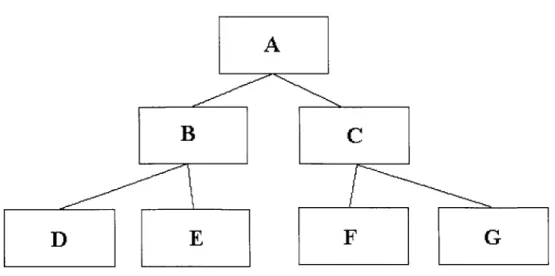
examine a sample web space of two hyperlinks, each referred page containing another two links [shown in figure 1]. We are given the goal that, starting on page A, we want to visit every page. There are two systematic approaches to this problem. The first is to
follow each series of links as far as they will take us, then retrace the minimal amount and follow the next, resulting in the following path: A B D B E B A C F C G (previously unviewed pages are denoted in bold face). This is known as a depth-first search. The
other approach, known as a breadth-first search, will complete its categorization of each level before continuing down another link. The resulting path from this type of search in our example would be A B A C A B D B E B A C F C G.
A
D
EFG
Figure 10 Example state-set for search discussion.
In this example, the depth-first search actually resulted in a shorter path, and therefore it was more efficient. However, the web differs from the simple example of
figure 3-1 in that while there are only a finite number of links on each page (a finite breadth), there is essentially an infinite chain of links that could be followed from any page. The practical result of this observation is that, given the page you are looking for is within a few links of the starting page, a depth-first search would be enormously
inefficient, and may never find the page. If you wished to find page F, you would never arrive unless all links below page B - again, essentially infinite in the web - were followed. A solution to this would be a nondeterministic search, which provides a good compromise between the breadth-first and depth-first searches25. This solution, in essence, switches randomly between breadth-first and depth-first search at each node, resulting in a search somewhere in between.
The nondeterministic search is random in nature, and a more focused search would be ideal. A best-first search assigns scores to each node in its immediate path based on various relevance criteria, and the highest scored node is followed, regardless of
level. In the example of figure 1, C would have a higher score than B, so the spider would start at C instead of B, resulting in a very short search.
A good example of a best-first search on the web is Lycos. Lycos ranks its pages by the number of links (in its database) that refer to the given page. The reasoning is that
pages more often linked to are more popular, and therefore more likely to be the desired
26
result
Another example of a best-first search is Direct Hit. Here the results of a specific query are stored in a database, as well as which of the results returned are viewed by the user. Pages more frequently viewed are judged as being more likely to be the desired page for a new query.
When a general collection of data is the goal, or when it is not possible to accurately assign scores to potential links, then it is important to limit the search, as the web is essentially an infinite search space. Since the depth factor of the web is larger than the branching factor, a breadth-first search is the better choice2 7. As illustrated in
the example in figure 1, where the goal was simply to visit (and presumably index) every page, the breadth-first search was the superior method.
A good example of a breadth-first search on the web is Webcrawler. Webcrawler
uses this strategy to explore as many servers as possible, resulting in a broad index and not placing a heavy load on any target web server28
3.3.1 Ease of Implementation
Because real-time response is not as crucial for spiders as for real-time agents, they do not need to be built as efficiently. Less efficient software equates to easier implementation. Indeed, several spiders of lesser power can work in tandem to provide better, faster results. For example, the Web Ants project has created a system of spiders that communicate with each other to avoid duplicating each others' results29. Many implementations of tandem spiders are in use currently, and several generic spider "packages" are available for purchase or free download.
3.3.2 Durability
As with a real-time agent, a well-designed spider should be adaptable to changing situations, resulting in a longer useful lifespan. A spider's power can be increased with increasing hardware or by running several implementations in parallel, and given the
standard format of the web, a spider can be expected to operate as long as that format is intact.
3.3.3 Resistance to Blockage
A spider is limited by the same factors that limit a human browsing the web; that
is, it will be vulnerable to any network blockages or security actions taken by a target site's administrator. A spider does have the ability to make a large number of repeated attempts to view a page, and since it does not need to immediately interpret what it finds, but only store it for later analysis, it can continue to do this over a longer period of time. 3.3.4 Accuracy of Information
A spider will directly view other web data, as would a human user. The spider
does not need to interpret this information in real-time, except to make the decision about what links to follow. Since the actual analysis and interpretation can occur locally and over an extended time, it will be much more accurate than a real-time analysis. In addition, the spider, if it is free to select the sites it views, cannot determine whether that
site is likely to have valid information. 3.3.5 Quantity of Information
Since spiders do not need to operate in real-time, and multiple spiders can work in tandem, they can return an enormous amount of information. Most major search engines use spiders as their primary means of information acquisition. The average major search
engine has over a hundred million web sites catalogued.30
3.3.6 Friendliness to Target
Spiders have a reputation for being inefficient and hogging resources.31 However, most spiders now follow the standard robot exclusion protocols (discussed in section 4), and are often timed so that they make page requests no faster than one per second. These concessions, while slowing a spider's progress, make it less aggravating to the target
3.3.7 Summary of Criteria
While spiders still have the fundamental flaws of an autonomous information-gathering system, they are able to minimize the effects by not operating in real-time. They capitalize on the advantages of the autonomous system.
Ease of Durability Resistance Accuracy of Quantity of Target Implementation to Information Information Friendliness
Blockage
Figure 11 Summary of Spider criteria
3.3.8 Real-World Examples
Many sites only need very specific information from a few pre-determined sites. This information, however, may change very often. Stock quotes, for example, will only come from a few sources, but are constantly changing. In this case, an automated search may not be the ideal method. A real-time agent consumes an enormous amount of
resources to obtain information, the location of which is already known. A spider, on the other hand, operates far too slowly to be of any use in this situation. The solution, then, is to create a direct pipeline of information from the source to the destination site. This pipeline will probably be purchased from the source, and a destination that wishes to aggregate several sources can simply purchase a pipeline from each of them. Although an information pipeline as described does not strictly fit our definition of an aggregator (it does not transparently collect information), we will discuss this technology briefly, as it is a viable source of information, and one against which other aggregating technologies must compete.
An information pipeline is not overly difficult to implement. A server needs to send the data to the client site - but that implementation is relatively straightforward. From the client's point of view, they simply need to install software to receive the information stream from the server, and then filter that data and display it as appropriate.
Since the server maintains a direct pipeline, durability is not really an issue. As long as information flows in the same format, any filtering software installed on a client site will not care how the information gets there. Given a standard modular