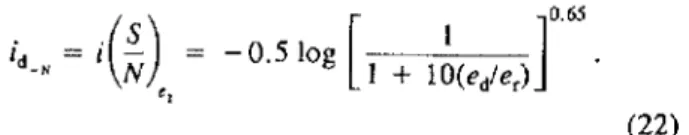Publisher’s version / Version de l'éditeur:
Journal of the Audio Engineering Society, 48, June 6, pp. 531-544, 2000-06-01
READ THESE TERMS AND CONDITIONS CAREFULLY BEFORE USING THIS WEBSITE. https://nrc-publications.canada.ca/eng/copyright
Vous avez des questions? Nous pouvons vous aider. Pour communiquer directement avec un auteur, consultez la première page de la revue dans laquelle son article a été publié afin de trouver ses coordonnées. Si vous n’arrivez pas à les repérer, communiquez avec nous à PublicationsArchive-ArchivesPublications@nrc-cnrc.gc.ca.
Questions? Contact the NRC Publications Archive team at
PublicationsArchive-ArchivesPublications@nrc-cnrc.gc.ca. If you wish to email the authors directly, please see the first page of the publication for their contact information.
NRC Publications Archive
Archives des publications du CNRC
This publication could be one of several versions: author’s original, accepted manuscript or the publisher’s version. / La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur.
Access and use of this website and the material on it are subject to the Terms and Conditions set forth at
Revisiting algorithms for predicting the articulation loss of consonants
ALcons
Bistafa, S. R.; Bradley, J. S.
https://publications-cnrc.canada.ca/fra/droits
L’accès à ce site Web et l’utilisation de son contenu sont assujettis aux conditions présentées dans le site LISEZ CES CONDITIONS ATTENTIVEMENT AVANT D’UTILISER CE SITE WEB.
NRC Publications Record / Notice d'Archives des publications de CNRC:
https://nrc-publications.canada.ca/eng/view/object/?id=c86b9967-2c2f-4009-ba1e-5faf3e32c488 https://publications-cnrc.canada.ca/fra/voir/objet/?id=c86b9967-2c2f-4009-ba1e-5faf3e32c488HU
http://www.nrc-cnrc.gc.ca/ircU
Re visit ing a lgorit hm s for pre dic t ing t he a rt ic ula t ion loss of
c onsona nt s ALc ons
N R C C - 4 3 0 5 6
B i s t a f a , S . R . ; B r a d l e y , J . S .
J u n e 2 0 0 0
A version of this document is published in / Une version de ce document se trouve dans:
Journal of the Audio Engineering Society,
48, (6), June, pp. 531-544, June 01,
2000
The material in this document is covered by the provisions of the Copyright Act, by Canadian laws, policies, regulations and international agreements. Such provisions serve to identify the information source and, in specific instances, to prohibit reproduction of materials without written permission. For more information visit http://laws.justice.gc.ca/en/showtdm/cs/C-42
Les renseignements dans ce document sont protégés par la Loi sur le droit d'auteur, par les lois, les politiques et les règlements du Canada et des accords internationaux. Ces dispositions permettent d'identifier la source de l'information et, dans certains cas, d'interdire la copie de documents sans permission écrite. Pour obtenir de plus amples renseignements : http://lois.justice.gc.ca/fr/showtdm/cs/C-42
PAPERS
/\/;€CC-
L/SDSG
Revisiting Algorithms for Predicting the Articulation Loss
of Consonants ALcons'k
SYLVIO R. BISTAFA" AND JOHN S. BRADLEY, AES Member
Institute for Research in Construction-Acoustics, National Research Council, Ottawa, Canada, KIA OR6
Algorithms thaI bave been proposed for predicting speech intelligibility based on the
articulation loss of」ッョセd。ョエウ A.Lcons are revisited. The simplest algorithm, known as the
architectural form of lbe Peutz equation, is discussed and rederived using a techniquetofind
foons of empirical equations.It is shown that other Peutz algorithms, which use measured values of room acoustical quantities for estimatingALCOlU'arebased on Fletcher'5articulation index concept, which is a quantitative measure of a communication system for transmitting
lbe speech sounds. When compared for diffuse sound fields wilb ideal exponential decays, lbese algorithms provide similar predictions because they were all developed from lbe sarne
experimental data. Unlike the speech transmission index STI and the useful-la-detrimental
sound ratioU50'speech intelligibility predictions based on thealセN algorithms do not take
intoaccount the effects of earlier reflections, single echoes. and the frequency dependence of relevant parameters. These limitations of the ALcoosalgorithms are crucial for accurate predictions of speech intelligibility in rooms.Itis shown thatinsmaller rooms with a diffuse
sound field and ideal exponential decays, 5T1 and U50 are highly correlated with each
other, whereasALconsis not uniquely correlated with eitherofthese speech metrics. Speech intelligibility predictions based on S11 and U9Jare compared with ALClJlIspredictions for the
Harvard phonetically balanced (PB) word test. For this test it is shown that the 511 andU50
speech intelligibility predictions are in good agreement, and that these metrics have equal
sensitivity to speechbeingdegradedbyreverberation and ambient noise, whereas the ALcons
algorithms underpredicted speech intelligibility as the signal-to-noise ratio decreased.
o
INTRODUCTIONThe common method for measuring the intelligibility of speech over communication systems is by performing articulation tests. The obvious advantage of this method
is its directness. However, there are some drawbacks,
such as the need to use trained talkers and listeners, and the lack of information on the type and amount of degradation present in the communication system. These have led to the development of physical measures of speech intelligibility.
Fletcher [I] proposed an index to quantify the amount of speech distortion in telephone systems and related it to articulation scores. This index was called the articulation index. With values between 0 and I the articulation index gives a quantitative measure of a telephone system
* Manuscript received 1999 August II; revised 2000
March 23.
** Visiting Scientist, Department of Mechanical Engi-neering. Polytechnic School. University of Sao Paulo, Sao Paulo. Brazil.
for transmitting the speech sounds. The articulation in-dex value is intended to give the articulation expected when a particular type of articulation test is used to evaluate the speech intelligibility of a transmitting system.
In Fletcher's method for calculating the articulation
index, the characteristics of the communication system
are an integral part of the method. By relating the articu-lation index under various types and magnitudes of speech distortions with subjective measures of intelligi-bility, French and Steinberg [2] developed a procedure in which the calculation of the articulation index of the received speech does not depend explicitly on the partic-uiar type of communication system. All that is necessary
are measurements or estimates of the spectrum level of
the received speech and noise at the ear. These should be given in each of 20 contiguous frequency bands which, at equal signal-to-noise ratios, contribute equally to speech intelligibility. Therefore the difference be-tween both procedures for calculating the articulation
transmit-elSTAFA AND SRADLEY
ting system is necessary, whereas in the former, infor-mation on the characteristics of the system between talker and listener is not required.
Kryter [3] extended the work of French and Steinberg by developing procedures for the calculation of the artic-ulation index from measurements or estimates of octave and one-third-octave frequency-band speech and noise spectra. These procedures were published as ANSI S3.5-1969 (R 1986), which was recently revised and pub-lished as ANSI S3.5-l997 [4]. The articulation index is particularly appropriate for speech distortions due to interfering noise and is not simply applicable to distor-tionsinthe time domain such as reverberation and echoes. Knudsen [5] developed a method for estimating speech intelligibility in rooms from physical measures that affect the listening conditions in this communication system. In this method the speech distortions that are due to the shape of the room, the loudness of speech, reverberation, and ambient noise are expressed as reduc-tion factors of speech intelligibility. In the ideal room for speech, each one of these factors would be equal to unity, so that speech intelligibility is maximized. When these factors are determined for a room in the presence of speech distortions, their product would give the probable percentage of articulation in that room.
Peutz [6], however, felt that the influence of the ambi-ent Doise in combination with the acoustics of the room was not equally well established. He experimentally found that a particular measure of speech intelligibil-ity-the articulation loss of consonants ALcons-is re-lated, in a simple way, to the acoustics of the room and to the speech signal-to-noise ratio. This resulted in the development of an empirical relationship expressing AL,oo, as a function of physical measures. Due to its simplicity, this relationship became a rather popular way of forecasting speech intelligibility in rooms in terms of
alセBL especially by the audio engineering community. After publishing his results in 1971, until the end of the 1980s, Peutz recast his original experimental find-ings in other algorithms used for estimating AL,o", based on measurements of acoustical quantities in rooms. These algorithms have been implemented in specialized measuring systems, and are basically of two kinds, with and without the influence of ambient noise. The form of these algorithms bears no resemblance to the simple empirically based relationship published in Peutz's 1971 paper. Since they are not well documented, one may have little confidence in using and applying them. In fact, those interested in getting deeper into Peutz's work on this topic will find that although most of his work has been published, it is only found in rather limited-access publications, with a great body of work being published in the Dutch language. Another difficulty is that these publications are scattered over a period that spans approximately 20 years. No publication seems to exist that consolidates Peutz's work in this area, espe-cially with respect to the evolution of the measurement-based algorithms. It is therefore one of our goals to revisit the development of Peutz' s algorithms for pre-dicting ALcODS in rooms.
532
PAPERS
Two types of empirically based algorithms were de-veloped by Peutz to predict AL,o",' The first type has its origin in the "liveness" factors, which results in the so-called architectural form of the Peutz equation and can be evaluated easily using a hand calculator. The second type, which considers AL,o", a probabilistic pro-cess in a form similar to that which led to the definition of Fletcher's articulation index, results in algorithms used to estimate ALcons as a part of modern room acous-tics measuring systems.
The use of Peutz's formulas for predicting AL,on, is considered to be limited to speech communications in relatively small-size auditoriums (classrooms and meet-ing rooms). Unlike the speech transmission index (STI) [7] and the useful-to-detrimental sound ratios such as
U,"
[8], these algorithms do not take into account theeffects of earlier reflections, single echoes, and the fre-quency dependence of relevant parameters.
Another objective of the present work was the valida-tion of the derived formulas for the theoretical case of diffuse sound fields with ideal exponential decays. This was accomplished by studying the relationships among AL,oo", STI, and US", and also by comparing speech intelligibility predictions by each of these metrics for the same type of articulation test.
1 PEUTZ ALGORITHMS FOR PREDICTING Alcon. Speech intelligibility is a process of recognizing speech messages. A message can be a sentence, which is composed of a number of more elementary messages, namely, words. A word is, in turn, made up of pho-nemes, which are nevertheless messages. Phonemes are elementary speech sounds representative of vowels and consonants of a particular language. To recognize the meaning of a sentence, one ideally has to recognize all the words in the sentence. Therefore words are cues of a sentence-type message. The same happens when the message is a word, but now the cues are phonemes. The understanding of speech is influenced by other than phonemic cues, such as linguistic, semantic, contextual, and visual cues. Phonemes are a neutral form of message in the sense that they are only recognized as acoustic cues. This characteristic, at least in principle, makes the nonsense syllables a superior type of articulation testing material, and it is recognized as giving more accurate results when compared to tests using words and sentences.
The energy and the duration of vowel sounds are greater than those of consonant sounds. Nevertheless, most of the speech information is carried by the sound of consonants. However, the understanding of simple messages is mainly defined by the sound of vowels due to redundancy if connected discourse and meaningful words are used. Knudsen [5] found that in rooms with different reverberation times the number of errors due to incorrectly perceived vowels was smaller than that due to consonants. The preponderance of the consonant errors was among the final consonants, as a result of the masking produced by the reverberation of the preceding
PAPERS PREDICTING THE ARTICULATION LOSS OF CONSONANTSセ (5) (3) (I) (2) (4) L = Te, 411' cT2D2 T2D2 13. 82ed = (13.82)' - V - = 22.6-y ヲセ e,(t) dt L = '-"-'-'-'--ed
where Kris a constant. Hence AL,oo.! would be given by
cTD2
AL,oo.!= Kr-y.
in which the numerator is the time integral of the re-flected sound energy density during the decay process, and e,(I) is the reflected sound energy density at any time tduring the decay. Under the assumption of a dif-fuse sound field in the room with ideal exponential de-cays, L is given by
is the sound velocity c. AL,oo. is, by definition, a nondi-mensional parameter, and the two other nondinondi-mensional parameters that can be derived are
II,
=
cTID andII,
= DJ/V. When these nondimensional parameters are
re-lated by an adequate function
f,
the determination of AL,oo. can then be made taking into account the com· bined effects of the distance D, tbe reverberation timeT,the room volumeV, and the sound velocity c. Mathe-matically we have
Itis interesting to point out that the nondimensional parameter
II, . II
2 = cTD'/V, multiplied by 411'113.82,is nothing more than the reflected-to-direct sound energy density ratio, that is,e.Jed = (411'1I3.82)cTD2/V, where
e,andedare the reflected and direct sound energy densi-ties, respectively. This comparison gives K
r
= 411'/ 13.82, which is very close to I. Eq. (3) then suggests that AL,o,,, is a function of the reflected-to-direct sound energy density ratio.Maxfield and Albersheim [101 found that the articulation-loss data points reported by Steinberg [Ill, when plotted versus the reflected-to-direct sound energy density ratio, could not be considered to lie on a single curve. However, when the liveness factorL was used instead of the reflected-to-direct sound energy density ratio, a single relation could represent the data points. The liveness factorL was defined as
where AL,oo. is the articulation loss of consonaots based on the
ヲオョ」エゥセョ
f.
The problem now lies in determining the form of the function
f,
and here is where the arbitrariness comes into play. Since AL"",. increases with both the distanceDand the reverberation timeT, a possible form for the function
f
relatingII,
andII,
to AL""" would be to consider the product ofII,
andII,.
In! this case the functionf
can be written asvowel. The greater energy and duration of vowel sounds increase the masking of the consonant sounds by vowels as the reverberation time increases.
Peutz [6J measured speech intelligibility in rOoms us-ing consonant-vowel-consonant (evC) phonetically balanced (PB) word lists for the Dutch language, consist-ing of nonsense as well as meanconsist-ingful words. Each word was preceded and followed by a two-word sentence, known as the carrier sentence. When the carrier sentence is not used, the effect of the ambient noise and reverber-ation will differ and no unique relreverber-ation between subjec-tive test scores and the objecsubjec-tive predictor would be obtained. Like Knudsen [5], Peutz also found that the articulation loss was much smaller for vowels than for consonants. He then defined the articulation loss of con-sonants AL"",. and the articulation loss of vowels AL", respectively, as the proportion of consonants and vowels wrongly perceived. Peutz obtained a better and more coherent set of relations regarding the influence of room acoustics00speech intelligibility in the form of AL",...
He also found that no reliable numbers for AL. could be obtained.
With respect to the parameters that control the process of listening to speech in a room, Peutz [6J found experi-mentally that in rooms with different volumes AL,oo. increased withthe distance from the sound source and with the reverberation time. These findings led to the proposal of a simple formula, known as the architectural form of the Peutz equation. Based on the same experi-mental data, Peutz also developed algorithms that are used as partof modem room acoustics measuring sys-tems. To be presented next is the development of these formulas for predicting AL"",•.
1.1 Architectural Form of the Peutz Equation
The presentation of the original development that led to the architectural form of the Peutz equation will be made in conjunction with a technique that has been used to find forms of empirical equations. This technique is based on the results of the Buckingham's PI theorem [9], which incidentally also provides the basis of physi-cal sphysi-cale models in room acoustics.
The Buckingham's PI theorem can be used to find a function relating AL,oo. to the quantities that control the process of listening to speech in a room, which ac-cording to Peutz [6] are the room volume, the distance from the source, and the reverberation time. The use of the results of this theorem requires first the identification of all apparent and nnnapparent quantities that control the physical phenomena under study. In the present case this is the loss of articulation due to speech distortions in the room. Second they should be grouped into nondi-mensional parameters using a procedure that has been described elsewhere [9J. Finally, a relationship among these nondimensional parameters is sought. As we shall see, the drawback of the technique is that this last step involves some arbitrariness.
The apparent quantities that control AL,o.. are the room volumeV, the distance from the sourceD,and the reverberation timeT. One of the nonapparent quantities
BISTAFA AND BRADLEY PAPERS
T'D'
%AL,o....= 8.9L
+
a = 200-y+
a. (7)valid for T in seconds, D in meters, and V in cubic meters.
A curve fit to a plot presented by Maxfield and Albers-heim [10] of articulation loss versus Iiveness factor L
gives
where %AL is the articulation loss as a percentage based on Steinberg's data points [I I].
When the articulation loss is that of consonants, Peutz [6] found a linear relation between the Iiveness factorL
and his experimental data points in the form
%AL = 4.5Lo.•7 (6)
portant nonapparent quantity that should have been in-cluded in the Buckingham's PI theorem-based formula-tion is a time during the process of sound decay that separates the useful and the detrimental sound retlections as judged by the hearing mechanism. This time will be called the "split" time T.plil ,and the additional
nondimen-sional parameter that it brings about is
TI,
=
TIT.plil 'Speech intelligibility should decrease as
TI,
increases, and the function g relating AL,oo. toTI" TI"
andTI,
can again be considered to be given by the product of
TIl' TI"
andTI,.
That is,T'D'
AL,oo., =
g(TI,; TI,; TI,)
=
Kg'TI, . TI, . TI,
= K-y(9)
Eq. (7) became known as the architectural form of the Peutz equation. In this equation all quantities are given in SI units, and %AL,o,,,
-.
is the articulation loss of consonants as a percentage when there is no ambient noise in the room. Hereais a correction factor, whichmay vary between 1.5% for a "good" listener and 12.5% for a "bad" listener.
Eq. (7) is valid as long as the distance from the source is less than what Peutz called the critical distance. Peutz [6] found that beyond the critical distance %AL,o", is
'N
constant and equal to9T
+
a.The critical distanceD, is given byD, = 0.21
VViT
in meters. I.t can be shown that the critical distance is approximately equal to the so-called limiting distance, which is defined as the distance for which the direct-to-retlected sound energy density ratio is equal to - 10 dB. Therefore beyond the limiting (critical) distance the direct sound is of no significance.In terms of the critical distance D" Eq. (7) can be rewritten as
(8)
These results show that the AL,o", based on the
func-tionf, AL,oo. inEq. (3), does not represent the process
of listening
to
speech. This process is more adequately represented when the retlected-to-direct sound energy density ratio is multiplied by the reverberation timeT.This fact reveals that when two receivers have the same retlected-to-direct sound energy density ratio, the receiver exposed to a longer reverberation time will have less speech intelligibility than the one exposed to a shorter reverberation time. This might be explained as being due to the inertia or the integrating properties of the hearing system, which leads us to consider as useful the early retlections being subjectively summed with the direct sound to increase its apparent strength, and as
detrimental the "blurring" effect of late reflections or reverberation. Longer reverberation times decrease the useful-to-detrimental sound energy ratio, thus reducing speech intelligibility.
The preceding discussion shows that another
im-534
where Kg is a constant, andK
=
KgclT.plil •It can nowbe seen that the form ofEq. (9) is compatible with Eq. (7), which is related linearly to the Iiveness factor Land best represents the process of articulation loss of con-sonants.
Contrary to the general acceptance that sound retlec-tions with delays up to 50 ms after the direct sound are useful to speech intelligibility, Peutz and Klein [12] found experimentally that retlections up to 15 ms have no effect on AL,oo.' Those delayed by more than 15 ms were found to be detrimental and increased AL,oo. up to 45 ms, after which AL,oo. remained constant as delays grew longer. To our knowledge the effects of earlier reflections and echoes were never implemented in any of Peutz's algoritbms.
Peutz [6] also measured the intluence of ambient noise on AL,on.' Ambient noise of a different nature was added, such as white noise, noise of an audience, and traffic noise, however, with unknown spectrum charac-teristics. He then found that the logarithm of AL,oo. is linearly related to the ambient noise, expressed as a signal-to-noise ratio, and with the reverberation time as a parameter. This linear relation held for signal-to-noise ratios below 25 dB. For higher signal-to-noise ratios AL,oo. was independent of the ambient noise. Since the intluence of the ambient noise is strongly dependent on the noise spectrum, his findings are consistent only for conditions where the noise spectrum is similar to the long-term speech spectrum.
Peutz [6] presented the results of the effects of ambi-ent noise on AL,oo. in graphical form. A graphical proce· dure by Peutz and Klein [I2] allows one to take into account both the room acoustic effects and the ambient noise on ALcODS • The expression that follows was
curve-fitted to the Peutz and Klein grapbical results [12]. It gives %AL,o", in analytical form, in terms of both room acoustical effects and ambient noise. The latter is given
as L" - L., whereLo is the ambient noise level andL.
is the speech level,
%ALcons+N = %ALcons_ (1.07IT-o.o"')"+(L.-L.).
N
(10)
In Eq. (10) %AL,oo.
..
is the articulation loss ofPAPERS PREDICTING THE ARTICULATION LOSS OF CCNSONANTS A4000s
where
s,
is the phoneme articulation when only the kthspeech frequency band is received. Taking the logarithm of Eq. (II) gives
nants in the presence of ambient noise. Eq. (10) is the architectural form of the Peutz equation, taking into ac-count the combined effects of the acoustics of the room
and the ambient noise. In this equation %AL,oo.
-,
isgiven by Eqs. (7) or (8) for D '" D" and is equal to
(9T
+
a) for D>
D,. Eq. (10) is valid as longasLo-L. '" -25 dB.
When comparing Eqs. (12) and (13) A is seen to desig-nate the simple additive measure of the contribution of different frequency bands to speech intelligibility. The
variables pandQare factors of proportionality, withp
depending on the talker-listener pair combination; pis
equal to I for a "well-practised and intelligent"
talker-listener pair. Also, A was arbitrarily assumed equal to I for a perfect speech transmission system. For
A
=
P=
I, the value ofQwas found experimentallyby Fletcher [IJ to be equal to 0.55. This means that even for such "ideal" conditions there is still a small prob'ability of 1.5% of not understanding the phoneme. Fletcher called A the articulation index, with values between 0 and I. It gives a quantitative measure of a communication system for transmitting the speech
sounds.
Peutz [13J recast Eq. (13) as
(IS)
(16)
i(R) = 0.5 10g[(1
+
aR')/(1+
R'/a)Jloga
where R is a measure of the relative speech distortion
anda is a constant, which varies from 8to 13 depending
on the type of speech distortion. The recognition func-tion, in its general form as given by Eq. (16), was found to be almost identical to the cumulative Gaussian
distri-bution function. Fig. I is a plot of i(R) versus R, as
given by Eq. (16) and calculated witha = 10.
There are other, more particular foons for the recogni-tion funcrecogni-tion, which were obtained by curve fitting to experimentally obtained data points. When the speech distortion is due to noise, Poutz [16J and Peutz and Kok
where C1is a constant andiwas called the information
index by Peutz.
Peutz and Kok [14J found that the information index i based on the mean of consonantal phonemes gives a good measure of the intelligibility of received speech in rooms. They also found that the values for C, vary according to the type of consonantal phoneme and talker-listener combinations. However, for 15 conso-nants, as spoken by two talkers and five listeners, in all
combinations the values of C1were most frequently in
the range between 2 and 3. In terms of %AL,oo", the articulation loss of consonants as a percentage, Eq. (14) can be rewritten as
where %ALcoas = 100(1 - scons),andSCODSis the
articula-tion for consonantal phonemes.
It is clear that the articulation index A is almost
identi-caIto the information indexi,and Peutz [15J,
recogniz-ing this fact, gives i "" I.IA. The articulation index A was used by Fletcher [IJ to evaluate the quality of tele-phone systems from their physical characteristics. The
information index i, as developed by Peutz [13J-[15],
has found its main application for estimating ALoo..
based on acoustical measurements in rooms. 1.2.1 InformatIon Index and the RecognItion Function
The information index i, with values between 0 and
I,represents the fraction of the emitted information that
can be recognized by the listener. Speech distortions
reduce the information index i. In room acoustics the
speech distortions are ambient noise, reverberation, and echoes.
The value of the information index can be obtained from knowledge of what Peutz [15J called the recogni-tion funcrecogni-tion. This is a funcrecogni-tion that gives the value for the information index for a given magnitude of the speech distortion. He found that the recognition function could be represented by a general form function indepen-dent of the type of speech distortion. Peutz' s experimen-tally obtained recognition function in its general form is given by (14) (12) (II) (13) o e
=
I - s=
IT (I - s,)'-I
"
log(l - s) =2:
10g(1 - s,) .'-I
log(l - s) = -HセI
A . 10g(1 - s) = - C,iEq. (12) was rewritten by Fletcher [I] as
1.2 Peutz Alcon. Algorithms Based on Acoustical Measurements In Rooms
To estimate ALconswhen acoustical measurements in
rooms are available, Peutz reapplied his experimental findings to develop algorithms that were implemented in computer-based measuring systems. The objective of this section is to revisit and discuss these algorithms, and to relate them to the original architectural form of the Peutz equation as given by Eq. (10).
Fletcher [I] considered the articulation s of a phoneme as the probability that it would be correctly understood,
ande = I - sas the complementary event, that is, the
probability that the phoneme will be understood wrongly. Considering the frequency range of speech sounds to be divided into n frequency bands, the error in recognizing a particular phoneme decreases as the number of speech bands of frequency increases, that is,
BISTAFA AND BRADLEY PAPERS
i(T),=-0.8510g [ 0.9 +0.1] (20)
,
VI
+
1O(5IT')whereSINis the signal-to-noise ratio, and the subscripts
e, and e, stand for the experimentally derived form I and form 2 as given by Peutz [16] and Peutz and Kok [14], respectively. In Eqs. (17) and (18), SIN corres-ponds toR'in Eq. (16).
A typical distortion found in room acoustics is signal reverberation. For this type of distortion, Peutz [16] and Peutz and Kok [14] proposed the following recogni-tion funcrecogni-tions:
(21) where idand i, are the information indices of the direct
and the reflected sound paths, respectively, and i. is the room infonnation index.
For application of these results to the evaluation of ALcons ' two situations are of practical interest. In the
first there is no ambient noise in the room, the only distortion to the speech sounds being the room reverber-ation. The second situation corresponds to speech sounds being distorted in the room by both reverberation and ambient noise.
1.2.2 Working with the Information Index
As pointed out earlier, and as shown in Fig. I, the recognition function corresponds to the cumulative Gaussian distribution function and, as such, i(R)can be interpreted as the probability of receiving the informa-tion when it has been distorted by an amount R. In a room, the speech information flows through two differ-ent types of paths, the direct and the reflected sound paths. In elementary probability theory these two paths can be considered as two events, and the probability of receiving the information from at least one of these two events (paths) is
will nOw be applied to derive the AL",,,, algorithms used when acoustical measurements in rooms are available.
1.2.3 ALcon.without Noise
When there is no ambient noise in the room, echoes and reverberation are the only distortions to the direct sound path. These act much like ambient noise, masking the direct speech sounds in the same way as ambient noise. For the case where the distortion is due to rever-beration, the recognition function to be used can be any one of those given by Eqs. (16)-(18). When using Eq. (17), the information index for the direct sound path (17) (18) (19) [ ] 0." - 0.5 log I
+
iセHsjnI
.(S)
I [ 0 . 9 I] I - = - og+
0 N ,,
VI
+
IO(SIN) . i(7)"= -
0.5 logcセI
[14] proposed the following recognition functions:
where T is the reverberation time and, as before, the
subscripts
e,
ande,
stand for the experimentally derived form I and form 2 as given by Peutz [16] and Peutz and Kok [14J, respectively. In Eq. (20), SIT' correspondstoR' in Eq. (16); henceT
=
Y5IR.These experimentally derived forms for the recogni-tion funcrecogni-tion are also shown in Fig. I. Since apparently they are all based on the same experimental data, it can be seen that they all follow similar trends, with incre-asing discrepancies as the relative speech distortion R
increases.
The recognition functions as given by Eqs. (17)-(20)
1.0 0.8 0.6 0.4 0.2 0.0
セ]]]セセ]セNセセセセ
0.1 10 RFig. 1. Information indexias a functionof relativespeech distortionR, as given by differentイ・セョゥエゥッョ functions. D-Recogni-lion function in its general fonn given by Eq. (16) with a = 10:O-Eq. (17) wilhR = VSfN; lI-Eq. (18) withR =
VSi
N; O-Eq. (19) withR
=
Y5fT; +-Eq. (20) withR = \15fT.PAPERS PREDICTING THE ARTICULATiON LOSS OF CONSONANTS Al.coos
without ambient noise is given by
.
.(S)
ld == I - ==
-N N
"
(22)
to the limiting distance, then Eg. (25) in terms of the critical distance De can be written as
(26)
The information index for the reflected sound path can be considered as the one given by Eq. (19), which corresponds to the case where the signal, in this case the reflected speech signal, has been reverberated. Hence the information index for the reflected path with-out ambient noise is given by
ir _N == l(n" == -a.51og
cセI
.
(23)The algorithm used by the so-called time-energy-frequency (TEF) analyzer [17] is based on the experi-mentally derived form 2 for the recognition functions. According to Eq. (21), the information index used by
the TEF analyzerゥセ is then given by
iR,u ==
ゥHセI
+
i(EDT)'l -{ゥHセI
X iCEDT)'l] .tJ e2
(27) As shown by Peutz [16], substitution ofEqs. (22) and
(23) into Eq. (21) results in
where iR-Nis the room information index without
ambi-ent noise, based on the experimambi-entally derived form I for the recognition functions.
Substitution of Eq. (24) into Eq. (15) with C1 == 2
gives
(25)
where %ALeolls_N is the articulation loss of consonants as a percentage for the case where there is no ambient noise in the room.
Assuming diffuse sound field conditions in the room with ideal exponential decays, and further considering
that Peutz's critical distanceDc is approximately equal
Here i(SIN), is given by Eg. (18) and i(EDT), is given, 1
by Eq. (20) with the early decay time EDT substituted for the reverberation time T, because rather than the reverberation time, the early decay time better defines the deterioration of speech due to reverberation. Here %ALcons is obtained by substituting Eq. (27) into Eq.
(15), with Ct == 1.7 anda = O.
For diffuse sound field conditions in a room with ideal
exponential decays, SIN ;= (D/D)2 in Eq. (18) and
T;= EDTinEq. (20). Fig. 2isaplotof%ALeoos versus
-N
(DcID/, with the reverberation time T as a parameter. It can be seen in this figure that contrary to Eq. (8), %ALeon, according to Eq. (26) is a continuous function
ofHd」ャdIセN Fig. 2 shows that for 、ゥウエ。ョ」セセァイ・。エ・イ than
about half the critical distance, Eq. (26) gives lower %ALeons_N than Eq. (8).
Also shown in Fig. 2 is %ALcOllS calculated with the-N
TEF analyzer algorithm, given by Eqs. (27) and (15). It can be seen that under the assumption of a diffuse sound field with ideal exponential decays, for which
T
=
EDT, %ALcon• calculated with the TEF analyzer-N
algorithm shows deviations from the results given by
<;: セ セ 0 u 10 ....J <:( ;f'-1000 100 , "l. " " I I I 100 0.1 10 (Dc ( 0)2
Fig. 2. %ALcooL versus (D,JD)2 with reverberation time T as a parameter, as given by three different algorithms.
-%ALeoo• 」。ャ」オャ。エ・セ with architectural {onn of Peutz equation, Eq. (8); - %ALenn,calculated with architectural {onn of Peutz
BISTAFA AND BRADLEY PAPERS
Eqs. (8) and (26). However, in a private communication [18] it was said to be tbe most accurate form for estimat-ing %ALc;ODS
-,
from measurements in rooms where the sound field is nondiffuse, but requires measurement of EDT at the receiver.1.2.4
ALcon.
with NoiseWhen %AL""" must be determined in the presence of noise, the distortion caused by the ambient noise in the room masks both the direct as well as the reflected sound paths. In this case Eqs. (22) and (23) are modified to take into account the sound energy density of the noise according to
More modem speech intelligibility metrics such as the speech transmission index STI [7] and the useful-to-detrimental sound ratio Usa [8] are often used to assess speech intelligibility in rooms. Unlike STI and Usa'
speech intelligibility predictions based on the AL""" for-mulas do not take into account the effects of earlier reflections, single echoes, and the frequency dependence of relevant parameters. In addition the STI is sensitive to the effects of the masking noise spectrum on speech intelligibility. These limitations of the AL,o.. predictive algorithms are crucial for accurate predictions of speech intelligibility in rooms.
To study the relationships between AL,o" and these two other speech intelligibility metrics, analytical for-mulas for STI and Usa were used which are applicable to rooms with diffuse sound fields with ideal exponential decays. Although a diffuse sound field condition is only approximated in real rooms. itprovides a common basis for the study of the relationships among different speech intelligibility metrics. Thus the room acoustical condi-tions can be expressed as a function of one acoustical parameter, the reverberation timeT, and one geometrical
parameter, the room volume V.
In order not to have to deal analytically with the de-crease of the reflected sound energy density with dis-tance from the source, the rooms chosen for the present study are relatively small rooms for speech, such as classrooms, with volumes up to 500 m' or so. Also, a further simplification was to consider rooms with As verified experimentally by Peutz [6], reductions in the noise-to-signal ratio below - 25 dB have no influ-ence on %AL""" . Therefore %AL,."+N +Ncalculated with
Lo - Lr
= -
25 dB can be considered as "no noise"conditions, and in this case results should agree with %AL,." calculated with the TEF analyzer algorithm. In Fig. 3 the closeness of both curves forL. - L, = - 25 dB confirms this expected result.
When calculating %AL,."
..
in roomS for which the assumption of a diffuse sound field with ideal exponen-tial decays holds, either Eq. (10) or Eq. (15) [with the room information index given by Eqs. (30) and (31)] can be used. Fig. 4 shows plots of %AL,oo,..
versus reverberation time T for a 3OO-m' room, with L.-Lsp I m as a parameter. Here %ALc;ons+ was obtained using Eqs. (10) and (15), in which IO(L. -'l.,)11Owas
calcu-latd according to Eq. (34), with L. - L,pI m values of
-10, - 20, and - 30 dB. Here L,pI m is the long-term
anechoic speech level at I m straight ahead of the talker. These plots show that both equations follow similar trends, but for a given reverberation time and L.
-L,pI m value Eq. (10) predicts slightly higher %AL"",,_
The values of %AL,,,,,,
..
in Fig. 4 do not take into ac-count the contribution of the direct field, that is, under this condition, in Eq. (10) L, = L, and in Eq. (30)id
..
=
O. These results are therefore applicable to dis-tances greater than about the critical distance.2 RELATIONSHIPS BETWEEN Alcon. AND OTHER SPEECH INTELLIGIBILITY METRICS (28) (29) (30) (31) L,)IIO ]
x [
-0.510gcセI
]
x [ -0.5 logHセI
] . { [ I O ( L . - L)IIO ] } "" = -0.3210g 10+
IO(L.-L,)IIO [ I+
IO(L. - L,)1I0 id.,
= -03210.
g I+
(D/D)'+
IO(L.whereen is the noise energy density.
Eqs. (28) and (29) are the information indices for the direct and the reflected sound paths, respectively, in the presence of amhient noise in the room, as presented by Peutz [13]. The room information index with ambient noise iR
..
is obtained by substituting Eqs. (28) and (29)into Eq. (21), which is then substituted into Eq. (15), to obtain the articulation loss of consonants in the pres-ence of ambient noise in the room %ALc;oos
..
.Assuming diffuse sound field conditions in the room with ideal exponential decays, Eqs. (28) and (29) in terms of the critical distance D, can, respectively, be rewritten as
whereL.is the ambient noise level andL,is the reflected speech level. The noise-to-reflected-speech ratio at the receiver is HyL.-4)1I0.
Fig. 3 is a plot of %AL,••,
..
versus (D/D)' for a reverberation timeT = I s, with the noise-to-reflected-speech ratioL. - L,as a parameter. Eq. (15) was used to obtain %ALc;ODS..
,with the room information index given by Eqs. (30) and (31). Also shown in Fig. 3 is %AL,••, calculated with the TEF analyzer algorithm, given by Eqs. (27) and (15). This algorithm does not take into account the effects of ambient noise onALc;ons.PAPERS PREDICTING THE ARTlCULATION LOSS OF CONSONANTS ALco..s
room, an expression for Uso can be found in the form
When calculating %ALcons for distances greater than
+N
Eqs. (32) and(33)are valid for distances greater than about the critical distance, for which the contribution of the direct field is no longer of significance. The predic-tions of m(F) and Uso using Eqs. (32) and(33), respec-tively, are only valid for ideal exponential decays. How-ever, predictions from the room impulse response are more accurate and also include the effects of earlier reflections, echoes, coupled rooms, and so on.
In Eqs. (32) and (33), 1O(L.-4)/IO is the
noise-to-reflected-speech ratio, which forVIS
=
I can be writ-ten as1O(c...-4lllO
=
O.OO32qVT-IeO.I6fT x IO(L.-L",'m)/IO.(34)
volume-to-surface-area ratios VIS "'" I, which covers most rectangular-shaped rooms such as classrooms. The sound source considered was the human voice without amplification, which was acoustically specified in terms of the long-term averaged speech level at I m L.p Im'with a directivity factor q
=
2 straight ahead ofthe talker.
The STI is calculated using a procedure [7] based on the modulation transfer function m(F). Under the assumption of a diffuse sound field in the room, m(F) is given by
m(F)
=
[I
+
cセセR
FT)2r
ll2
[I
+
IO(L,-L,lIIOrl(32)
where F is the speech modulation frequency and Lr is
the reflected speech level.
Under the assumption of a diffuse sound field in the
[
1 - e-O.69IT ]
Uso = tolog e-O.69IT
+
IO(L,-4)/IO . (33)'i= -25 セ c 2 10 ;i, -15
*
-5 +5 1000 100 100 0.1 10 (De/O)2Fig. 3. %AL"""$l'versus(Dc!Dl for reverberation time T "" 1 s, with noise-to-reflected-speech ratio L. - Lras a parameter.
-%AL""". calculated with room information index given by Eqs. (30) and (31); - %ALeon, calculated with TEF analyzer 。ャァッイゥエャオャゥセ Eqs. (21)and (15). Ln - L,plm (dB) -30 10 100 0.1 1 T(s)
Fig. 4. %ALcon• Nversus reverberation timeTfor 300-m3room, withL. - L,plmas a parameter. %ALcon• calculated according
to Eq. (10)
(-f
and Eq. (I5) (-), the latter with room information index given by Eqs. (30) and (31).%AL
oon ' ,I(was obtained with noise-to-signal ratio calculated according to Eq. (34), withL. セ L,p I mvalues of - 10, - 20, and - 30du,
BISTAFA AND BRADLEY PAPERS
The fact that Usa and STI are highly correlated did
about the critical distance using Eq. (lO),Lo - L,can
be substituted forLn - L •.
Some earlier developments of speech intelligibility metrics were based on unfiltered broad-band values of the speech metrics, while some newer metrics are based on octave-band values. For example, Lochner and
Burger's signal-to-noise ratio[19Jwas derived and
cor-related with articulation test scores using broad-band unfiltered impulse responses. More modem speech
met-rics, such as the STI [7) and the weighted version of
Vso ,calledUso(A) [8],have been developed in terms of weighted octave-band values. When summing octave·
band values, the STI and Uso(A) require a specific
octave-band weighting procedure to be applied to each octave-band value in order to obtain a single broad-band number that relates to speech intelligibility. When octave-band values are used, the calculation of ALcon. is only done, by convention, in the 2-kHz octave frequency band. Therefore ALcon. does not take into account the influence of the frequency dependence of parameters on speech intelligibility. This is one of the limitations of this speech intelligibility metric.
The two most common types of speech distortions found in room acoustics, namely, reverberation and am-bient noise, were represented in the present work by one reverberation time and one signal-to-noise ratio value. This reverberation time can be considered to be for a frequency band that represents the room acoustical con-ditions important for speech intelligibility. To be consist-ent with the frequency band normally used to predict ALcDOs' the reverberation time in the 2-kHz band can be chosen. A representative value for the signal-to-noise ratio can be based on the overall A-weighted levels for speech sounds and ambient noise.
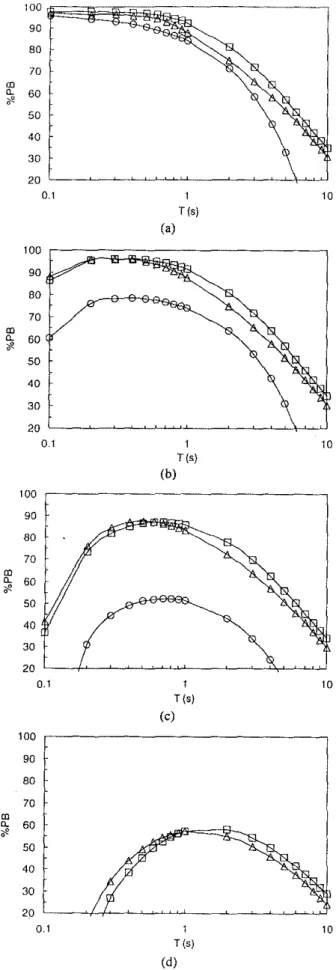
Fig. 5(a)-(c) shows the relationships between
%ALcoD• and STI; %ALcons and Usa' and Uso and STI.
The data points in each of the three plots were obtained
for three room volumes(l00, 300,and 500 m3),and for
reverberation times ranging from 0.1 to 10s. For each
speech metric, and for each room volume, the noise-to-reflected-speech ratio was obtained using Eq. (34), with
LD - L.p Jm,:,alues of 0, -10,and - 20 dB. For a
150-m3classroom, with a reverberation time of 1.0 s, these
would correspond to signal-to-noise ratio values of
ap-proximately 0,10,and 20 dB. Also included in Fig. 5 are
values of the speech metrics calculated with the noise-to-reflected-speech ratio equal to 0, which corresponds to
"no noise" conditions. As can be seen in these plots,
the numerical choice for the acoustical variables covers a broad range of values of these speech metrics.
Fig. 5 indicates that no unique relationship holds be-tween ALcons and STI, and also bebe-tween ALcoo• and Usa, As shown in Fig. 5(c), this is not the case with Usa and STI. A unique linear relationship exists between them, independent of the room volume and the signal-to-noise ratio. This linear relationship is given by
1.0
•
0.8 0.6 811 (a) 0.4 0.2 100 c--...tl. 0.0not come as a suprise, since this has been demonstrated by Houtgast et al. [20] for the same theoretical case of purely exponential reverberation as has been done in the present study. It has also been confirmed from
measure-ments in
a
wide range of rooms [8].The STI is calculated for modulation frequencies F from 0.63 Hz to 12.5 Hz. The high cut-off frequency is chosen to "tune" the effects of reverberation and echoes to a similar effect on their effective signal-to-noise ratio
as that due to additive noise. In fact, as reported by
Jacob [21], because the STI is calculated for modulation
frequencies F ",;; 12.5 Hz, it can be shown that early
reflections arriving within a certain time limit can never lower STI. and, in the presence of late reverberation,
100 ·20 -10 0 10 20 U50 (b) 20 U50 '" 3J .STI -10 0 0 I[) :J -10 -20 0.0 0.2 0.4 0.6 0.8 1.0 811 (c)
Fig. 5. Relationships between (a)
%A.L.o:."
and S11; (b) %AJ....-and Uso; (c) Uso and STI. Data points are for three room volumes: 0-100 m3; 6-300 m3; 0-500 m3, and forreverberation times ranging from0.1 to 10s. For each room
Vand reverberation timeT, the noise-to-reflected·speech ratio was calculated according to Eq. (34), with Ln - Lsp 1mvalues
of 0, - 10, and - 20 dB . • -"No noise" conditIOn.
III 5 .3 10
«
ct III C o .3 10«
ct (35) Uso=
31 STI - 16.PAPERS PREDICTING THE ARTICULATION LOSS OF CONSONANTS A,"",",
I Eq. (40) is not the polynomial obtained in [26]. which
seems tobe in error and does not represent plotted values of the PH word score versus STI of Fig. I.
early reflections increase STI. This reveals that the mod-ulation transfer functionm(F), which forms the basis of the STI calculation scheme, is also related to the useful-to-detrimental sound ratio concept.
As mentioned earlier, the Peutz formulas for predicting AL""" were developed based on articulation scores using consonant-vowel-consonant (CYC) phonetically bal-anced (PB) word lists for the Dutch language [6]. Using the same type of word'lists, Houtgast et al. [20l, [22] reported on the existence of a unique relationship between STI and AL""", which was obtained for 57 auditorium-like conditions, comprising combinations of various signal-to-noise ratios, reverberation times, and echo delay times. This relationship is given by
Eq. (36) is also shown in Fig. 5(a) and has been used for conversions from STI to %AL,o", [23].
The lack of a unique relationship between AL,o", and the two other speech intelligibility metrics (STI and
Uso), as shown in Figs. 5(a) and (b), reveals that for two different room conditions with the same STI or Us. value, the speech intelligibility based on AL,o", may be different when the latter is predicted by Peutz formulas. For speech communication in smaller rooms, speech in-telligibility predictions based on STI and Us. are now compared with AL,,,,,, predictions for the same type of articulation test.
The main body of intelligibility scores related to STI was also obtained using predominantly nonsense PB syl-lables of theCYCtype for the Dutch language [24]. The STI also appears to hold for other languages, as has been demonstrated in a multilanguage evaluation with the simplified version of STI-the rapid speech transmis-sion index (RaSTI)-and calculated only in the 500-Hz and 2-kHz octave frequency bands [25]. The STI was also found to be well correlated with the so-called Har-vard PB word test [26]. The STI has therefore been tested using different types of articulation tests, in differ-ent languages, over differdiffer-ent communication systems including speech transmission in rooms. Usowas corre-lated with articulation scores based On the Fairbanks rhyme test [27].
However, few studies have attempted to correlate dif-ferent speech intelligibility metrics with the same type of articulation test. One of such studies is due to Jacob [21], who used the monosyllabic word intelligibility test according to ANSI S3.2-1960 (RI982) [28] to develop correlations between articulation scores and unfiltered broad-band measured values of ALw .,"STI, and Lochner and Burger's signal-to-noise ratio R" [19]. This articula-tion test is based on a set of 20 PB word lists, each of which contains 50 monosyllabic English words. This test is also known as the Harvard PB word test.
Jacob [21] obtained the best-fit regression equations and
(39)
R" = I.25Us•
+
3.4 .Fig. 6 shows plots of O/OPB based on the Harvard PB word test versus reverberation time for a 300-m3room. The O/OPB values were predicted using Eq. (37) for AL,,,,,," Eqs. (38) and (39) for Us., and Eq. (40) for STI. Here Fig. 6(a) corresponds to the "no noise" condition. With added ambient noise, the noise-to-reflected-speech ratio was calculated according to Eq. (34), withL,
-L,p I m values of -20 dB, -10 dB, and 0 dB in Fig.
6(b)-(d).
It can be seen in Fig. 6(a) that for the "no noise" condition O/OPB predictions based on STI and Us. are in good agreement, whereas AL,,,,,, tends to underpredict O/OPB for the same reverberation time. With added ambi-ent noise, predictions based on STI and Us. continue to present a remarkably good agreement in particular for reverberation times less than about IS, whereas %PB
is increasingly underpredicted by ALw", as the signal-to-noise ratio decreases,
O/OPB = -11.9
+
351.7STI - 374.4STI'+
132.2STI'. (40)' Eqs. (39) and (38) then allow Us. values to be expressed in terms of O/OPB scores.Jacob [21] did not develop a best-fit regression equa-tion relating the STI to the Harvard PB word test scores. He converted STI values to O/OPB scores using the origi-nal regression curve established by Steeneken and Hout-gast [24], which was based on the DutchCYC nonsense syllables. This regression equation falls below the curve for the actual Harvard PB word test because words are more easily understood under difficult communication conditions than nonsense syllables. A regression equa-tion relating the STI to the Harvard PB word test was obtained from Anderson and Kalb [26] results and is given by
In Eqs. (37) and (38), O/OPB denotes the percentage of phonetically correct words. The %ALw ",values used in Eq. (37) were derived from the architectural form of the Peutz equation as given by Eq. (7). Reverberation times and R" values were calculated by squaring and integrating unfiltered broad-band impulse responses, which were experimentally obtained in rooms with dif-ferent volumes and reverberation times.
In a previous study [29] Lochner and Burger's signal-to-noise ratio R" was found to be related linearly to Uso
according to
O/OPB = 100 _ %ALwoo
+
2.12 (37)0.70
O/OPB = 79.458
+
2.99R.. - 0.1368R;, . (38) to convert values of %ALcons and the Lochner andBurger's signal-to-noise ratio Rsn to %PB as
(36) %AL,,,,,, = 170e-S.4STI.
BISTAFA AND BRADLEY PAPERS
3 SUMMARY AND CONCLUSIONS
The present work revisited algorithms developed by Peutz for predicting AL,oo,' It was shown that the sim-plest algorithm, known as the architectural form of the Peutz equation, is based on the liveness factor. Peutz's relationship involving the physical quantities that control the process of listening to speech in a room was con-firmed by a technique based on nondimensional param-eters. Algorithms proposed by Peutz for estimating
AL-coos' which are used when acoustical measurements in
roomS are available, were shown to be based on Fletcher's articulation index. When these algorithms are compared for diffuse sound fields with ideal exponential decays, the present work shows that they all predict similar AL,oo. values because they were all derived from the same experimental data.
The use of the Peutz formulas to predict AL,oo. is restricted to relatively small-size auditoriums (class-rooms and .meeting (class-rooms), and they do not take into account the effects of earlier reflections, echoes, and the frequency dependence of relevant parameters. These limitations are crucial for accurate predictions of speech intelligibility, particularly in larger rooms. STI andU", are considered more adequate speech metrics because they are capable of taking these effects into account.
Itwas shown that in rooms with a diffuse sound field and ideal exponential decays, STI and U,o are highly correlated with each other, whereas ALcons is not
uniquely correlated with either of these speech metrics. The result is that speech intelligibility predictions based on the AL,oo. algorithms may be different from those predicted by STI and U,o.
In fact, it was also shown that based on the Harvard PB word test, STI and U,o have equal sensitivity to speech that has been degraded by reverberation and am-bient noise in small rooms with ideal exponential decays. However, when AL,o", predictions of speech intelligibil-ity are related to the Harvard PB word test, the ALcons These results suggest that the effect of ambient noise
is overrepresented in the ALcons predictive algorithms.
In fact, as far as the effect of ambient noise on speech intelligibility is concerned, Peutz found that AL,oo, in-creases as the signal-to-noise inin-creases up to 25 dB. This result does not agree with a general consensus that signal-to-noise ratios above 15 dB do not affect speech intelligibility and can be considered as "no noise" situations.
Fig. 6(a), which corresponds to the "no-noise" condi-tion, shows that speech intelligibility increases mono-tonically with decreasing reverberation time. However, this situation cannot be realized in real rooms because ambient noise is always present. As the reverberation time decreases, the signal-to-noise ratio as given by Eq. (34) decreases, which tends to deteriorate speech intelli-gibility. As shown in Fig. 6(b)-(d), the presence of ambient noise results in a relatively broad maximum, which shifts to higher reverberation times for lower signal-to-noise ratios. 10 10 10 10 1 T(s) (a) 1 T(s) (b) 1 T(s) (c) 50 40 30 20 0.1 50 40 30 20 GMMセセセセセセセMセセセセMG|Mッセ 01 50 40 30 20 GMMセセセセセセセMセMセNッNLNNNセセキ 0.1 50 40 30 20 0.1 <D Cl. 60
'"
<D Cl. 60'"
QPPセセセQ
90t
80 70 100 エZZZZ・ZセAhAャQAゥE[[[[[ZMMMMMMMMQ 90 80 70 90 80 70 100'"
Cl. 60'"
'"
Cl. 60'"
100 90 80 70 1 T(s) (d)Fig. 6. Speech intelligibility %PB based on Harvard PB word
test versus reverberation timeTfor 300-m3room, %PB values
were predicted using Eq. (37) for AL"" (0). Eqs. (38) and (39) for U", (.6.), andEq. (40) for STI (0). (a) "No noise"
condition. With added ambient noise, the noise-to-reflected· speech ratio was calculated according toEq. (34) withLn
-L, I mvalues of:(b) -20 dB: (c) -10 dB: (d) 0dB. In (d),
%PB predicted byALcons is off the bottom of the scale.
PAPERS
algorithms have a tendency to underpredict speech intel-ligibility values of these same types and amounts of speech distortions, with speech intelligibility being in-creasingly underpredicted by the AL,oo, algorithms as the signal-to-noise ratio decreases.
4 ACKNOWLEDGMENT
The present work has benefited from information pro-vided by the following individuals: Johan van der Werff, Farrel Becker, Pat Brown, Carolyn Davis, and Wolfgang Ahnert. The first author would like to acknowledge the personal financial support for the development of the classroom acoustic project currently under way, granted
by fオョ、。セ。ッ de Amparo
a
Pesquisa do Estado de SaoPaulo-FAPESP. 5 REFERENCES
[I] H. Fletcher, Speech and Hearing in
Communica-tion(Van Nostrand, New York, 1953), pp. 280-283. [2] N. R. French and J. C. Steinberg, "Factors Gov-erning the Intelligibility of Speech Sounds,"J. Acoust. Soc. Am., vol. 19, pp. 90-119 (1947).
[3] K. D. Keyter, "Methods for the Calculation and Use of the Articulation Index,"J. Acoust. Soc. Am.,
vol. 34, pp. 1689-1697 (1962).
[4] ANSI Std. S3.5-1997, revision of ANSI Std. S3.5-1969 (R 1986), "Methods for Calculation of the Speech Intelligibility Index," American National Stan-dards Institute, New York.
[5J V. O. Knudsen, Architectural Acoustics (Wiley, New York, 1932), pp. 351, 395-396.
[6] V. M. A. Peutz, "Articulation Loss of Consonants as a Criterion for Speech Transmission in a Room," J.
Audio Eng. Soc., vol. 19, pp. 915-919 (1971 Dec.). [7] lEC Std. 60268-16, "Objective Rating of Speech Intelligibility by the Speech Transmission Index," 2nd ed., International Electrotechnical Commission, Ge-neva, Switzerland (1998-03).
[8] J. S. Bradley, "Relationships among Measures of Speech Intelligibility in Rooms," J. Audio Eng. Soc.,
vol. 46, pp. 396-405 (1998 May).
[9] E. Buckingham, "Model Experiments and the Form of Empirical Equations," Trans. ASME, vol. 37, pp. 263-296 (1915).
[10] J. P. Maxfield and W. J. Albersheim, "An Acoustic Constant of Enclosed Spaces Correlatable with Their Apparent Liveness," J. Acoust. Soc. Am., vol.
19, pp. 71-79 (1947).
[11] J. C. Steinberg, "Effects of Distortion on the Recognition of Speech Sounds," J. Acoust. Soc. Am.,
vol. I, pp. 121-137 (1929).
[12] V.M. A. Peutz and W. Klein, "Articulation Loss of Consonants Influenced by Noise, Reverberation and Echo," (in Dutch), Acoust. Soc. Netherlands, vol. 28, pp. 11-18 (1974).
[13] V. M. A. Peutz, "Speech Reception and Infor-mation," Tech Topics, vol. 5, no. 12, pp. 1-5 (1978 July) (Synergetic Audio Concepts, Box 1115, San Juan
PREDICTING THE ARTICUlATION LOSS OF CONSONANTS AI."""
Capistrano, CA 92693).
[14] V. M. A. Peutz and B. H. M. Kok, "Speech Intelligibility," presented at the 75th Convention of the Audio Engineering Society, J. Audio Eng. Soc. (Ab-stracts), vol. 32, p. 468 (1984 June), preprint 2089.
[15] V. M. A. Peutz, "Speech Information and Speech Intelligibility," presented at the 85th Convention of the Audio Engineering Society,J. Audio Eng. Soc. (Abstracts), vol. 36, p. 1029 (1998 Dec.), preprint 2732.
[16] V. M. A. Peutz, "Designing Sound Systems for Speech Intelligibility," presented at the 48th Convention of the Audio Engineering Society, J. Audio Eng. Soc. (Abstracts), vol. 22, p. 360 (1974 June), preprint967. [17] D. Davis and C. Davis, Sound System
Engi-neering (Howard W. Sams, Indianapolis, IN, 1987),
pp. 495 -497.
[18] P. Brown, private communication (1999). [19] J. P. A. Lochner and 1. F. Burger, "The Intelligi-bility of Speech under Reverberant Conditions,"
Acus-tica, vol. 11, pp. 195-200 (1961).
[20] T. Houtgast, H. J. M. Steeneken, and R. Plomp, "Predicting Speech Intelligibility in Rooms from the Modulation Transfer Function. I.General Room Acous-tics," Acustica, vol. 46, pp. 60-72 (1980).
[21] K. D. Jacob, "Correlation of Speech Intelligibil-ity Tests in Reverberant Rooms with Three Predictive Algorithms,"J. Audio Eng. Soc., vol. 37, pp. 1020-1030 (1989 Dec.).
[22] T. Houtgast and H. J. M. Steeneken, "A Review of the MTF Concept in Room Acoustics.and Its Use for Estimating Speech Intelligibility in Auditoria," J.
Acoust. Soc. Am., vol. 77, pp. 1069-1077 (1985). [23] C. P. Davis, "Measurement of %AL,oo.'" J.
Audio Eng. Soc. (Engineering Reports), vol. 34, pp. 905-909 (1986 Nov.).
[24] H. J. M. Steeneken and T. Houtgast, "A Physi-cal Method for Measuring Speech-Transmission Qual-ity,"J.Aeoust. Soc. Am.,vol. 67, pp. 318-326 (1980). [25] T. Houtgast and H. J. M. Steeneken, "A Multi-Language Evaluation of the RaSTI-Method for Estimat-ing Speech Intelligibility in Auditoria," Acustica, vol. 54, pp. 185-199 (1984).
[26] B. W. Anderson and 1. T. Kalb, "English Veri-fication of the STI Method for Estimating Speech Intelli-gibility of a Communications Channel,"J.Acoust. Soc. Am., vol. 81, pp. 1982-1985 (1987).
[27] J. S. Bradley, "Predictors of Speech Intelligibil-ity in Rooms,"J. Acoust. Soc. Am., vol. 80, pp. 837-845 (1986).
[28J ANSI Std. S3.2-1989 (ASA 85-1989), "Method for Measuring the Intelligibility of Speech over Commu-nication Systems," revision of "Method for Measure-ment of Monosyllabic Word Intelligibility," American National Standards Institute, New York.
[29] S. R. Bistafa and J. S. Bradley, "Reverberation Time and Maximum Background-Noise Level for Class-rooms from a Comparative Study of Speech Intelligibil-ity Metrics,"J. Acoust. Soc. Am., vol. 107, pp. 861-875 (2000).
BISTAFA AND BRADLEY
S. R. Bistafa
THE AUTHORS
J. S. Bradley
PAPERS
Sylvia R. Bistafa is a professor in the Mechanical Engineering Department of the Polytechnic School and graduate adviser in the Technological Department of the School of Architecture and Urban Planning at the University of Sao Paulo, Brazil. He obtained his under-graduate degree in mechanical engineering at the Indus-trial Engineering College in Sio Bernardo do Campo, Brazil. His M.Sc. and Ph.D. degrees were obtained at The Pennsylvania State University. USA, working on fluid-flow-caused noise. He teaches fluid mechanics and applied acoustics and has done work on architectural acoustics. environmental acoustics. transportation noise, and noise control engineering. He holds four pat-ents in coauthorship and has written or coauthored more than 50 publications in technical journals or conference proceedings. He is currently a visiting scientist with the Acoustics Group at the National Research Council Canad!i, working on speech intelligibility and speech quality in classrooms and meeting rooms.
John Bradley is a senior research officer in the Acoustics Laboratory of the Institute for Research in Construction at the National Research Council of Canada. His under-graduate degree was in physics and was obtained from the University of Western Ontario. His masters degree, received from the same university, involved research on violin acoustics. He obtained his Ph.D. at Imperial College of the University of London on a project concerning elec-tI'oacoustic enhancement systems in rooms.
After teaching acoustics and noise control for several years in the Faculty of Engineering at the University of Western Ontario, he joined the National Research Council. His work has concentrated on both room acous-tics and subjective studies. He has completed studies on the annoyance of various types of noises as well as measurement studies in various rooms. Most recently he has been concerned with the accuracy of various room acoustics measurements as well as the subjective importance of these quantities.