An asymmetric 2D Pointer / 3D Ray for 3D Interaction within Collaborative Virtual Environments
Texte intégral
Figure

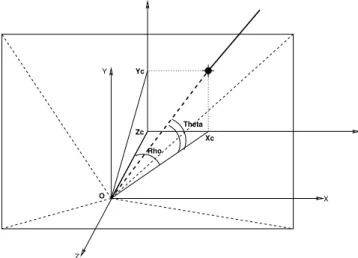
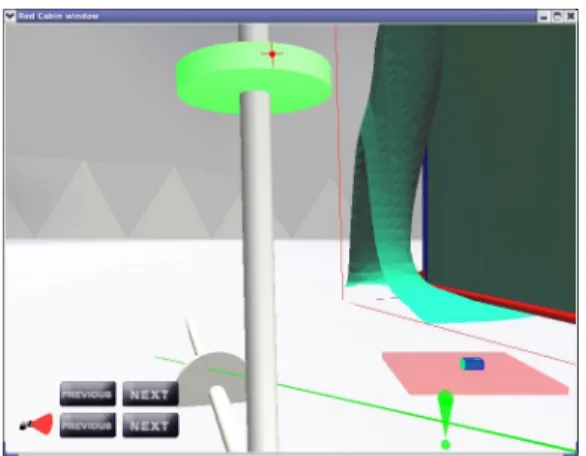

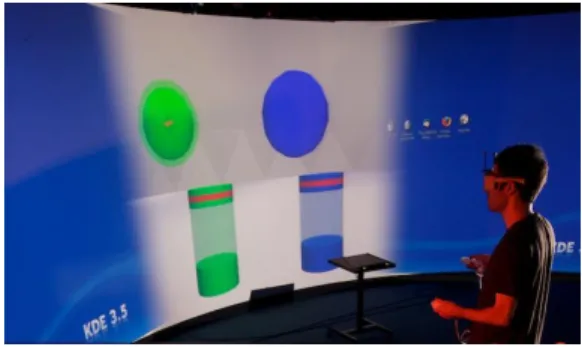
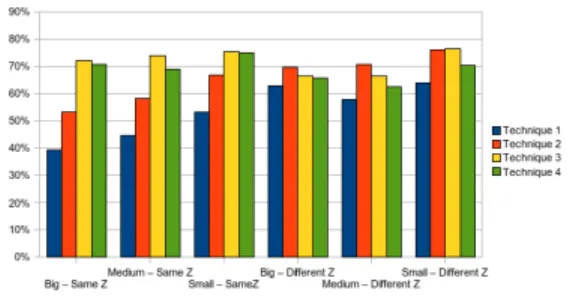
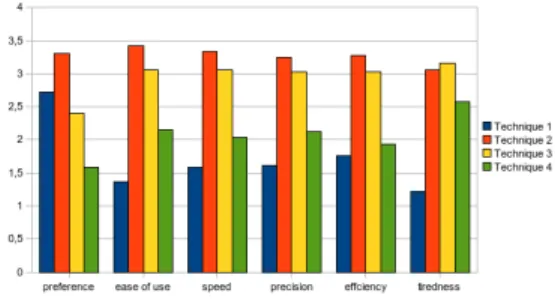
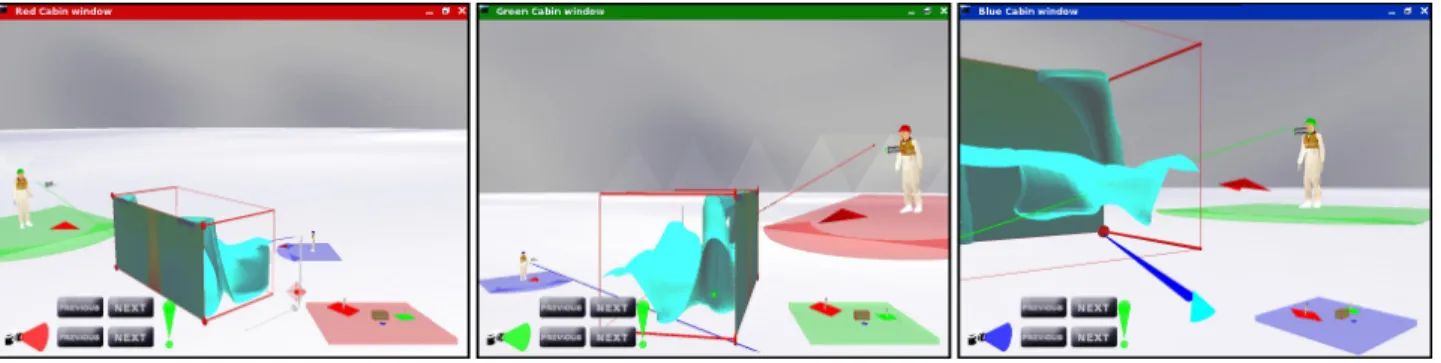
Documents relatifs
13 Such a linking of systems would at once effectively allow inter- firm trading, thus removing many of the unequal costs and perverse incentives now embedded in the CAFE design, and
When patients were stratified by history of mono- or dual zidovudine therapy, the risk of virologic failure among the 31 patients in the simplified group who had a history of
Dans la rédaction de ce livre nous constatons que l'écrivain Hakim Laâlam fait recours à la créativité lexicale pour donner naissance à de nouvelles unités lexicales, c'est
The hybrid approach treats the electrons as a fluid but retains the ion dynamics and thus offers a trade-off between fully kinetic and magnetohydrodynamic (MHD) simulations. This
B A.. In case of dense and crowded environment, the target can be occluded and the curve will select multiple objects. The curve techniques are based on the transparency of
Most of the reported manipulation techniques, includ- ing [BK99, HCC07, MCG10a, MCG10b, KH11, LAFT12, ATF12], were evaluated using a variation of the 3D docking task proposed by
ا لصفل سماخلا جئاتنلا ةشقانمو ليلحتو ضرع 66 : ةـــصلاخ ةصاخلا جئاتنلا ليمحتب لصفلا اذى يف انمق دقل تاذ اييمع لصحملا
1) L’établissement, à partir de son application de gestion administrative, dresse la liste des agents proposables à l’avancement au corps supérieur
