Achieving High CPU Efficiency and Low Tail
MASSACHUSETTSINSTITUTE
Latency in Datacenters
OFTECHNO10Yby
OCT 032019
Amy Ousterhout
LIBRARIES
Master of Science, Massachusetts Institute of Technoogy 2015)
Bachelor of Science in Engineering, Princeton University (2013)
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Doctor of Philosophy
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
September 2019
@Massachusetts
Institute of Technology 2019. All rights reserved.
Author ...
Signature redacted
Department of Electrical Engineering and Computer Science
Signature redacted
Certified by...
August 30, 2019
Hari Balakrishnan
Fujitsu Chair Professor of Electrical Engineering and Computer Science
Certified by.
Signature redacted
Thesis Supervisor
Adam M. Belay
Assistant Professor of Electrical Engineering and Computer Science
Acceptedby
Signature redacted
A ee y.U
Thesis Supervisor
...
Leslie A. Kolodziejski
Professor of Electrical Engineering and Computer Science
Chair, Department Committee on Graduate Students
Achieving High CPU Efficiency and Low Tail Latency in
Datacenters
by
Amy Ousterhout
Submitted to the Department of Electrical Engineering and Computer Science on August 30, 2019, in partial fulfillment of the
requirements for the degree of Doctor of Philosophy
Abstract
As datacenters have proliferated over the last couple of decades and datacenter ap-plications have grown increasingly complex, two competing goals have emerged for networks and servers in datacenters. On the one hand, applications demand low latency-on the order of microseconds-in order to respond quickly to user requests. On the other hand, datacenter operators require high CPU efficiency in order to re-duce operating costs. Unfortunately, today's systems do a poor job of providing low latency and high CPU efficiency simultaneously.
This dissertation presents Shenango, a system that improves CPU efficiency while preserving or improving tail latency relative to the state-of-the-art. Shenango es-tablishes that systems today are unable to provide CPU efficiency and low latency simultaneously because they reallocate cores across applications too infrequently. It contributes an efficient algorithm for deciding when applications would benefit from additional cores as well as mechanisms to reallocate cores at microsecond granularity. Shenango's fast core reallocations enable it to match the tail latency of state-of-the-art kernel bypass network stacks while linearly trading throughput for latency-sensitive applications for throughput for batch applications as load varies over time.
While Shenango enables high efficiency and low tail latency at endhosts, end-to-end application performance also depends on the behavior of the network. Thus this dissertation also describes Chimera, a proposal for how to build on Shenango to co-design congestion control with CPU scheduling, so that congestion control can optimize for end-to-end latency and efficiency.
Thesis Supervisor: Hari Balakrishnan
Title: Fujitsu Chair Professor of Electrical Engineering and Computer Science
Thesis Supervisor: Adam M. Belay
Acknowledgments
I am extremely grateful to everyone who assisted, either directly or indirectly, with
this dissertation. First, I would like to thank my advisors, Hari Balakrishnan and Adam Belay. Hari has advised me since I first arrived at MIT six years ago. Of the many things I have learned from Hari, the one that stands out most is the importance of always distilling the key ideas. Whether in picking research problems to work on, preparing talks, or writing papers, Hari excels at separating what is most interesting and novel from the implementation details, and I have learned a great deal about how to do this from him. I have worked with Adam for the last two years since he arrived at MIT. From Adam I have learned how to design, build, and debug high performance systems. Adam is skilled at analyzing unexpected results, asking the right probing questions to determine their root causes, and then designing solutions to overcome them. I have become much better at building and understanding systems as a result. Frans Kaashoek served on my thesis committee, but more importantly, along with Nickolai Zeldovich, Robert Morris, and other members of PDOS, taught me a great deal through PDOS group meetings, which always provide a healthy dose of constructive criticism. From watching countless practice talks and discussing dozens of published papers and submission drafts, I have absorbed much about how to clearly communicate research ideas.
I greatly appreciate the assistance of all my collaborators on the research described
in this dissertation as well as other research I worked on during my PhD. Many thanks to Irene Zhang, Josh Fried, Jonathan Behrens, Ravi Netravali, Mohammad Alizadeh, James Mickens, Jonathan Perry, Petr Lapukhov, Devavrat Shah, and Hans Fugal.
I particularly want to thank Josh for many fruitful research discussions and for his
patience in helping me determine why experiments did not behave as expected. Supportive labmates make research more enjoyable. Therefore I would like to thank my G9 cohabitants, both present and past: Akshay, Vikram, Frank C., Vibhaa, Venkat, Hongzi, Mehrdad, Peter, Anirudh, Guha, Shuo, Tiffany, Pratiksha, Deepti, Keith, Katrina, Frank W., Jon, Tej, Malte, David, and many others. I am also very
grateful to Sheila for all of her assistance with reimbursements, obtaining equipment, and lab snacks and lunches!
I would also like to thank the Hertz Foundation and the NSF Foundation for their generous support throughout my PhD.
Beyond G9, I benefited tremendously from the support of friends in the broader MIT community. Thank you to Danielle, Jennifer, Mandy, Mengfei, Ramya, and Aloni for countless girls' nights and games of Race for the Galaxy. Over the last three years I have also had the pleasure of riding and racing with many wonderful people on the MIT Cycling Team. When research challenges got me down, you buoyed me up, providing me with an outlet for frustrations, another avenue for accomplishment, and a broader sense of community and purpose. Whether standing on the podium at National Championships or huddling in cars waiting for feeling to return to our toes after racing in torrential rain, I am so grateful to have had you all by my side.
Thank you to Mom, Dad, and Kay. I greatly appreciate that, despite their ex-pertise in the same field, my family allowed me to pursue my PhD independently, refraining from interrogating me about research at the dinner table. Finally, thank you to my boyfriend Daniel for his unrelenting patience, support, and encouragement.
Previously Published Material
Portions of this dissertation are based on prior publications. Shenango (Chapters
2-8) extends a conference paper published with Josh Fried, Jonathan Behrens, Adam
Belay, and Hari Balakrishnan
[100].
Chimera (Chapter 9) is based on a workshop paper published with Adam Belay and Irene Zhang 99].Contents
1 Introduction 1
1.1 Background . . . ... . . .. .. . . . . .. . .. .. .. . .. . 1
1.2 CPU Efficiency vs. Tail Latency . . . . 3
1.3 C ontributions . . . . 4
1.4 Lessons Learned .. . .... . . . ... 6
2 Shenango: An Overview 7 2.1 The Case Against Slow Core Allocators . . . . 9
2.2 Challenges and Approach . . . . 12
2.2.1 C hallenges . . . . 12
2.2.2 Shenango's Approach . . . . 13
3 Orchestrating Core Reallocations with the IOKernel 17 3.1 Congestion Detection . . . . 17
3.1.1 Congestion Detection Algorithm . . . . 18
3.1.2 Detecting Congestion in One Queue . . . . 19
3.1.3 What Is the Right Core Allocation Interval? . . . . 19
3.2 Core Selection . . . . 22
4 The Runtime Library 25 4.1 uThread Scheduling . . . . 26
4.2 Networking and Storage . . . . 27
4.3.1 4.3.2
Steering Connections to Cores . . . . Cross-Connection Abstractions . . . . 5 Implementation
5.1 Runtime Implementation . . . 5.2 IOKernel Implementation . . 5.3 Ksched Implementation . . . . 5.4 Flow Steering Implementation
6 Evaluation
6.1 Experimental Setup
6.1.1 Hardware . . . .
6.1.2 Systems Evaluated . . . .
6.1.3 Applications . . . .
6.2 CPU Efficiency and Latency . . . . 6.2.1 Memcached . . . .
6.2.2 Spin Server . . . .
6.2.3 D N S . . . .
6.2.4 Flash Server . . . .
6.3 Resilience to Bursts in Load . . . .
6.4 Core Reallocation Speed and Scalability .
6.4.1 Time to Reallocate a Core . . . . . 6.4.2 How the IOKernel Spends Its Time 6.4.3 Core Allocation Interval . . . .
6.5 Microbenchmarks . . . .
6.5.1 Thread Library . . . .
6.5.2 Network Stack Overheads . . . . .
6.5.3 Congestion Signals . . . . 6.5.4 Runtime Efficiency . . . . 6.5.5 Throughput Scalability . . . . 6.5.6 NUM A . . . . viii 30 33 37 . . . . 38 . . . . 41 . . . . 41 . . . . 43 47 . . . . 47 . . . . 4 7 . . . . 4 8 . . . . 4 9 . . . . 5 0 . . . . 5 1 . . . . 5 3 . . . . 54 . . . . 5 5 . . . . 5 6 . . . . 5 8 . . . . 5 8 . . . . 5 9 . . . . 6 1 . . . . 6 3 . . . . 6 3 . . . . 64 . . . . 6 4 . . . . 6 5 . . . . 6 6 . . . . 6 8
6.5.7 Packet Load Balancing . . . .
6.5.8 Storage Stack . . . .
7 Related Work 8 Discussion
9 Future Work: Leveraging Operating Systems Knowledge for Better Datacenter Congestion Control
9.1 Benefits of Codesign . . . .
9.1.1 Reducing End-to-End Response Latencies . . . . 9.1.2 Increasing Resource Utilization
9.2 Design Decisions . . . . 9.2.1 Receiver-Driven Congestion Control . . . .
9.2.2 Potential to Make Progress as a Busyness Metric
9.2.3 Measuring Potential to Make Progress . . . .
9.3 Co-designing Congestion Control and CPU Scheduling in a O S . . . . 9.3.1 OS Design . . . . 9.3.2 P olicy . . . . 9.4 Open Problems . . . . 9.5 Related Work . . . . 9.6 Conclusion . . . . Datacenter 69 69 71 75 77 79 79 79 81 81 82 84 85 85 86 88 90 91 93 10 Conclusion . . . .
Chapter 1
Introduction
1.1
Background
Networks and computers today are used in drastically different ways than they were
50 years ago. Early networks in the 1960s and 70s were typically used either to
connect remote terminals to a centralized computing facility (e.g., ALOHAnet [19]) or to communicate among a small set of local devices. Indeed, the first paper about Ethernet describes using it to connect "personal minicomputers, printing facilities, large file storage devices, magnetic tape backup stations, larger central computers, and longer-haul communication equipment"
[91.
With the emergence of the Internet and the World Wide Web, new uses of networks and computers have arisen in the form of datacenters. A single datacenter may house tens or hundreds of thousands of servers that support complicated distributed systems dedicated to assembling complex web pages in response to user requests.With the rise of datacenters, two new goals have emerged for the underlying networks and computers that comprise them: low latency and high CPU efficiency. Though users issue their requests to datacenters over wide-area links with latencies in the tens to hundreds of milliseconds 981, applications within datacenters demand extremely low latency-on the order of microseconds. This is because constructing a response to a single user request often requires tens or hundreds of round trips within the datacenter to consult dozens of services and storage devices, and all of
1
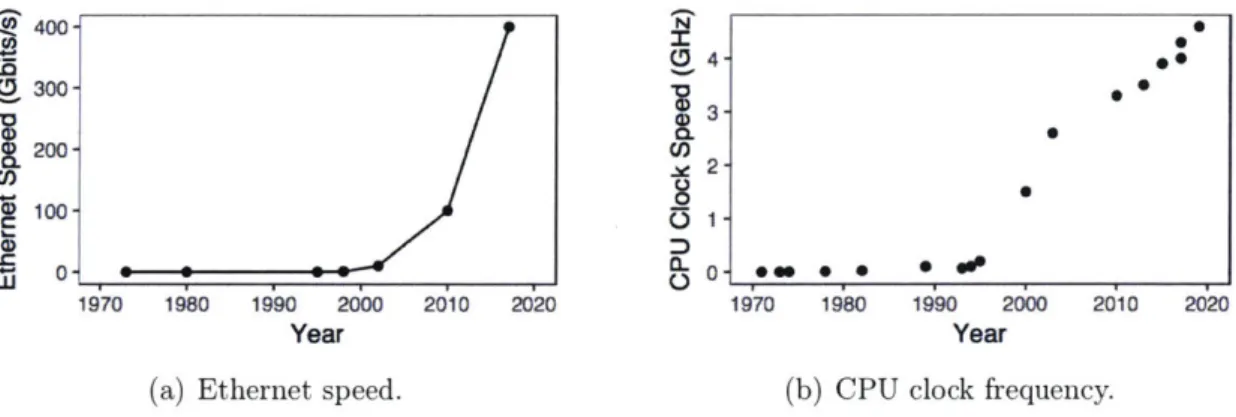
-- U 1400- N 0 4-02300-. 200- C) 100-W 0 1970 1980 1990 2000 2010 2020 1970 1980 1990 2000 2010 2020 Year Year
(a) Ethernet speed. (b) CPU clock frequency.
Figure 1-1: Ethernet speeds and CPU clock frequencies over the past 50 years.
these round trips must complete before a response can be sent back to the user [22]. Furthermore, it is crucial that latencies remain low not just on average, but at the tail (e.g., 9 9.9th percentile) of the distribution, to reduce the likelihood that a user's request is impacted by even one slow query [48, 56, 97, 116].
Fortunately networking and storage hardware have risen to the occasion. In the past 50 years, network speeds have risen from the initial 2.94 Mbits/s ethernet in
1973 [91] to 10 Gbits/s in 2002, and to 100 and 400 Gbits/s in the last decade
(Fig-ure 1-1(a)). As speeds have risen, latency has dropped, so that high-speed networks today provide round-trip times (RTTs) on the order of a few ps [89, 90]. This growth trend will likely continue in the future, as work has already begun on Terabit ether-net
[171.
On the storage side, disks with millisecond-scale access latencies are being replaced by recent flash devices with latencies as low as 10 ps[4].
At the same time, CPU efficiency is emerging as an important goal as well. As dat-acenters become more abundant [14], demand for compute rises as well. For decades,
CPU speeds rose rapidly (Figure 1-1(b)), paralleling the growth in the density of
transistors in integrated circuits predicted by Moore's Law
[95];
these phenomena en-abled increased compute capabilities without significant increases in costs. However, in recent years, Moore's Law has slowed. Chip manufacturers have embraced multi-core to continue scaling compute capabilities, but issues with power dissipation limit the potential of multicore as well[53].
As a result, increasing compute capabilities entails increased costs, both in terms of capital expenditures to build moredatacen-ters and operational costs to power them. Furthermore, as network speeds continue to rise while clock speeds lag, computation increasingly becomes the bottleneck in distributed applications [102].
As a result, datacenter operators increasingly focus on improving CPU efficiency.
By CPU efficiency we mean the fraction of clock cycles that CPUs spend performing
useful work, as opposed to sitting idle or busy-spinning. Because of the scale at which datacenters operate, increasing CPU efficiency by even a few percent can save millions of dollars
[122].
Thus datacenter operators attempt to keep CPU utilization high by packing multiple types of applications onto each server. As load varies for one application, for example, a latency-sensitive application whose load is driven by user requests, other applications, such as less urgent batch-processing applications, can utilize any idle cycles [30]. For example, Microsoft Bing colocates latency-sensitive and batch jobs on over 90,000 servers [661, and the median machine in a Google compute cluster runs eight applications[127].
1.2
CPU Efficiency vs. Tail Latency
Unfortunately, existing systems do a poor job of providing high CPU efficiency and low tail latency simultaneously. Commodity operating systems such as Linux can only support microsecond latency when CPU utilization is kept low, leaving enough idle cores available to quickly handle incoming requests [75, 78, 1271. More recently, kernel-bypass stacks have emerged for networking (e.g., ZygOS [107]) and for storage (e.g, ReFlex [76]); these approaches support microsecond latency at high throughput
by circumventing the kernel scheduler [2, 33, 85, 101, 1051. However, these systems
waste significant CPU cycles. Instead of interrupts, they rely on polling the network interface card (NIC) to detect packet arrivals or the storage device to detect I/O completions, so the CPU is always in use even when there are no requests or responses to process. Moreover, these systems lack mechanisms to quickly reallocate cores across applications, so they must be provisioned with enough cores to handle peak load.
This tension between low tail latency and high CPU efficiency is exacerbated by
the bursty arrival patterns of today's datacenter workloads. Offered load varies not only over long timescales of minutes to hours, but also over timescales as short as a few microseconds. For example, micro bursts in Google's Gmail servers cause sudden
50% increases in CPU usage
[25],
and, in Microsoft's Bing service, 15 threads can become runnable in just 5 ps [66]. This variability requires that servers leave extra cores idle at all times so that they can keep tail latency low during bursts [30, 66, 75].Why do today's systems force us to waste cores to maintain microsecond-scale
latency? A recent paper from Google argues that poor tail latency and efficiency are the result of system software that has been tuned for millisecond-scale I0/ (e.g., disks)
[29].
Indeed, today's schedulers only make thread balancing and core alloca-tion decisions at coarse granularities (every four milliseconds for Linux and 50-100 milliseconds for Arachne [109] and IX [108]), preventing quick reactions to load im-balances.Furthermore, there is little coordination between network schedulers and CPU schedulers; typically they optimize for their own objectives in isolation. For example, the network may optimize for flow completion time
[52]
or fairness across flows [61]. As a result, network congestion control may prioritize traffic from flow A over traffic from flow B only to have A's traffic arrive at a busy server while B's destination server sits idle. Tail latency and utilization of both the CPU and the network could be improved with coordination between the two.1.3
Contributions
The primary contribution of this dissertation is a system called Shenango that recon-ciles the tradeoff between CPU efficiency and low tail latency by rethinking the way
CPU scheduling is done. Unlike prior systems, Shenango grants applications
exclu-sive use of a set of cores and reallocates cores across applications at very fine time scales. Shenango reallocates cores every 5 microseconds, or about every 11,000 clock cycles on our servers, orders of magnitude faster than any prior system. With such fast reallocation rates, Shenango can ensure that applications have enough cores to
maintain low tail latency, but can reallocate underused cores to other applications, thereby maintaining high CPU efficiency.
Shenango achieves such fast reallocation rates with three key ideas. First, Shenango introduces an efficient algorithm called the Congestion Detection Algorithm which detects when an application would benefit from additional cores. This algorithm re-lies on fine-grained high-frequency visibility into thread, packet, and storage queues, which is not available in commodity operating systems today. Thus Shenango's sec-ond contribution is a centralized entity called the IOKernel, which leverages global visibility into all these sources of queeuing to run the congestion detection algorithm and orchestrate core reallocations. Finally, in order to support high throughput, all cores in each Shenango application must be able to perform I/O operations (e.g., sending and receiving packets). Shenango's third contribution is an approach to flow
steering that ensures that packets are steered to a suitable core, even as core
alloca-tions change every few microseconds.
We have implemented Shenango using existing Linux facilities, and its source code is available at https: //github. com/shenango. We found that Shenango achieves similar throughput and latency to ZygOS
1107],
a state-of-the-art kernel-bypass net-work stack, but with much higher CPU efficiency. For example, Shenango can achieve over five million requests per second of memcached throughput while maintaining9 9 .9th percentile latency below 100 ps (one million more than ZygOS). However,
un-like ZygOS, Shenango can linearly trade memcached throughput for batch application throughput when request rates are lower than peak load.
This dissertation also describes a proposal for how to modify network behavior to improve tail latency and efficiency of both the network and the CPU (Chapter
9). We propose to co-design congestion control with CPU scheduling, by exposing
information about how heavily utilized destination endpoints are to congestion con-trol algorithms. This would allow congestion concon-trol to prioritize traffic destined to applications and servers that will be able to handle it sooner. We describe Chimera, a design that builds on Shenango to expose information about application busyness, gathered with the help of the IOKernel, to a receiver-driven congestion control
tocol. The receiver-driven congestion control protocol can then optimize for broader objectives than flow completion time, such as end-to-end response latencies or re-source utilization. Implementing and evaluating Chimera are promising directions for future work.
1.4
Lessons Learned
The most important lesson that arises from this dissertation is that networks and op-erating systems should no longer be optimized in isolation; for the best performance, each should consider the behavior of the other. Chimera clearly and explicitly argues in favor of co-design, but Shenango also relies on such integration. Shenango's Con-gestion Detection Algorithm requires information about the occupancies of packet queues in order to make decisions about how many cores to allocate to each appli-cation, thereby coupling CPU scheduling with networking. Further opportunities for improving performance with co-design likely exist; the challenge in the future will be to continue to co-design while retaining some of the isolation and abstractions that ease programmability and enable independent evolution of systems and networks.
Chapter 2
Shenango: An Overview
Today's systems cannot simultaneously provide low tail latency and high CPU effi-ciency. Commodity operating systems such as Linux can effectively multiplex many applications, but can only provide microsecond latency when CPU utilization is low, ensuring that idle cores remain available to handle incoming requests
[75,
78, 127].In an attempt to achieve better tail latency, kernel-bypass approaches have prolif-erated over the last decade. These approaches, including ZygOS [107], ReFlex
[76],
and many others [2, 7, 33, 71, 85, 101, 105] provide low tail latency by dedicating cores to busy-spinning polling hardware NIC or storage queues. This enables pack-ets to be handled more quickly than with interrupt-driven approaches, but requires cores to remain in use regardless of whether there are packets or I/0 completions to process. Furthermore, none of these approaches can quickly reallocate cores across applications, so they cannot adapt the number of cores they use as load varies over time.
This thesis presents Shenango, a system that focuses on achieving three goals:
(1) microsecond-scale end-to-end tail latencies and high throughput for datacenter
applications; (2) CPU-efficient packing of applications on multi-core machines; and
(3) high application developer productivity, thanks to synchronous I/0 and standard
programming abstractions such as lightweight threads and blocking TCP network sockets.
To achieve its goals, Shenango solves the difficult problem of reallocating cores
across applications at very fine time scales; it reallocates cores every 5 microseconds, orders of magnitude faster than any system we are aware of. Shenango proposes three key ideas. First, Shenango introduces an efficient algorithm called the
Conges-tion DetecConges-tion Algorithm that accurately determines when applicaConges-tions would benefit
from additional cores based on runnable threads and incoming I/0 such as packets
and storage completions. Second, Shenango dedicates a single busy-spinning core
per machine to a centralized software entity called the IOKernel, which leverages its centralized position to gather the queueing information needed by the Congestion
Detection Algorithm and to orchestrate core reallocations. Third, Shenango
con-tributes an approach to flow steering that directs packets to suitable cores, even as core allocations change at microsecond timescales. In Shenango, applications run in user-level runtimes, which provide efficient, high-level programming abstractions and communicate with the IOKernel to facilitate core allocations.
Our implementation of Shenango uses existing Linux facilities, and we have made
it available at https://github.com/shenango. We found that Shenango achieves
similar throughput and latency to ZygOS [107], a state-of-the-art kernel-bypass
net-work stack, but with much higher CPU efficiency. For example, Shenango can achieve over six million requests per second of memcached throughput while maintaining
9 9 .9th percentile latency below 100 ps (37% more than ZygOS). However, unlike
ZygOS, Shenango can linearly trade memcached throughput for batch application
throughput when request rates are lower than peak load. To our knowledge, Shenango is the first system that can both multiplex cores and maintain low tail latency dur-ing microsecond-scale bursts in load. For example, Shenango's core allocator reacts
quickly enough to keep 9 9.9th percentile latency below 150 ps even during an extreme
shift in load from one hundred thousand to five million requests per second. Finally, Shenango provides high-level abstractions such as threading and blocking sockets, easing the burden on developers.
2.1
The Case Against Slow Core Allocators
In this section, we explain why millisecond-scale core allocators are unable to main-tain high CPU efficiency when handling microsecond-scale requests. We define CPU
efficiency as the fraction of cycles spent doing application-level work, as opposed to
busy-spinning, context switching, packet processing, or other systems software over-head.
Modern datacenter applications experience request rate and service time vari-ability over multiple timescales
[30].
To provide low latency in the face of these fluctuations, most kernel bypass network and storage stacks, including ZygOS[107]
and ReFlex[76],
statically provision cores for peak load, wasting significant cycles on busy polling. Recently, efforts such as IX [108] and Arachne [109] introduced user-level core allocators that adjust core allocations at 50-100 millisecond intervals. Similarly, Linux rebalances tasks across cores primarily in response to millisecond-scale timer ticks. Unfortunately, all of these systems adjust cores too slowly to handle microsecond-scale requests efficiently.To show why, we built a simulator that determines a conservative upper-bound on the CPU efficiency of a core allocator that adjusts cores at one millisecond intervals. The simulator models an M/M/n/FCFS queuing system and determines through trial and error the minimum number of cores needed to maintain a tail latency limit for a given level of offered load. We assume a Poisson arrival process
(empirically
shown to be representative of Google's datacenters [88), exponentially distributed service times with a mean of 10 ps, and a latency limit of 100 ps at the 9 9.9th percentile. Toeliminate any time dependence on past load, we also assume that the arrival queue starts out empty at the beginning of each one millisecond interval and that all pending requests can be processed immediately at the end of each millisecond interval. To-gether, these assumptions allow us to calculate the best case CPU efficiency regardless of the core allocation algorithm used.
Figure 2-1 shows the relationship between offered load and CPU efficiency (cycles used divided by cycles allocated) for our simulation. It also shows the efficiency of a
100%-75%-
--
50%-LU 25%- Shenango, 5 pis interval
00/,-- Simulated upper bound, 1 ms interval
0.0 0.2 0.4 0.6
Throughput (million requests/s)
Figure 2-1: With 5 ps intervals between core reallocations, a Shenango runtime achieves higher CPU efficiency than an optimal simulation of a 1 ms core allocator.
Shenango runtime running the same workload locally by spawning a thread to perform synthetic work for the duration of each request. For the simulated results, we label each line segment with the number of cores assigned by the simulator; the sawtooth pattern occurs because it is only possible to assign an integer number of cores. Even with zero network or systems software overhead in the simulation, mostly idle cores must be reserved to absorb bursts in load, resulting in a loss in CPU efficiency. This loss is especially severe between one and four cores, and as load varies over time, applications are likely to spend a significant amount of time in this low-efficiency region. The ideal system would spin up a core for exactly the duration of each request and achieve perfect efficiency, as application-level work would correspond one-to-one with CPU cycles. Shenango comes close to this ideal, yielding significant efficiency improvements over the theoretical upper bound for a slow allocator, despite incurring real-world overheads for context switching, synchronization, etc.
On the other hand, a slow core allocator is likely to perform worse than its the-oretical upper bound in practice. First, CPU efficiency would be even lower if there were more service time variability or tighter tail-latency requirements. Second, if the average request rate were to change during the adjustment interval, latency would spike until more cores could be added; in Arachne, load changes result in latency
spikes lasting a few hundred milliseconds (§6.3) and in IX they last 1-2 seconds [1081.
Finally, accurately predicting the relationship between number of cores and perfor-mance over millisecond intervals is extremely difficult; both IX and Arachne rely on
load estimation parameters that may need to be hand tuned for different applica-tions [108, 109]. If the estimate is too conservative, latency will suffer, and, if it is
too liberal, unnecessary cores will be wasted. We now discuss how Shenango's fast core allocation rate allows it to overcome these problems.
2.2
Challenges and Approach
Shenango's goal is to optimize CPU efficiency by granting each application as few cores as possible while avoiding a condition we call compute congestion, in which failing to grant an additional core to an application would cause work to be delayed
by more than a few microseconds. This objective frees up underused cores for use by
other applications, while still keeping tail latency in check.
Modern services often experience very high request rates. For example, a single flash device can support hundreds of thousands of operations per second and a single server and can send or receive millions of packets per second. With these request rates, core allocation overheads make it infeasible to allocate a new core to handle every request. Instead, Shenango closely approximates this ideal, detecting load changes every five microseconds and adjusting core allocations over 60,000 times per second.
2.2.1
Challenges
Such frequent core allocations raise three key challenges.
Estimating required cores is difficult. Previous systems have used
application-level metrics such as latency, throughput, or core utilization to estimate core require-ments over long time scales [43, 66, 83, 109]. However, these metrics cannot be applied over microsecond-scale intervals. Instead, Shenango aims to estimate instantaneous load, but this is non-trivial. While requests arriving over the network provide one source of load, other I/0 devices can also generate work (e.g., completions from a flash device), timers can fire, and applications themselves can independently spawn threads. All of these sources of load can impact how many cores an application requires.
Core reallocations impose overheads. The speed at which cores can be
reallo-cated is ultimately limited by reallocation overheads: determining that a core should be reallocated, instructing an application to yield a core, etc. Existing systems im-pose too much overhead for microsecond-scale core reallocations to be practical. For
I
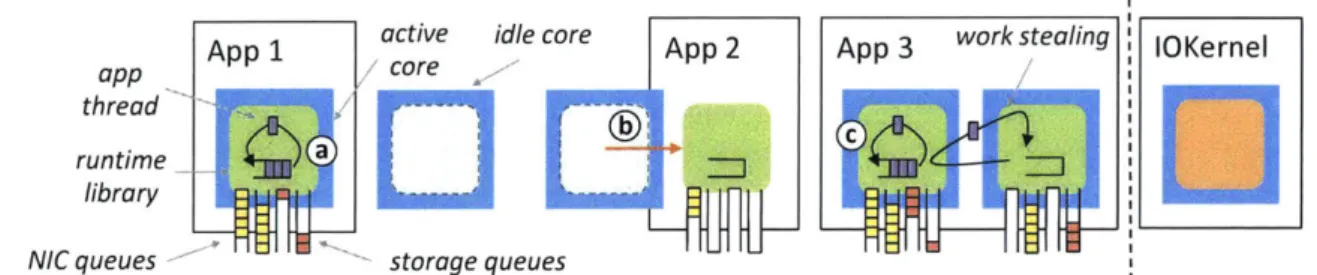
App 1 active idle core App 2 App 3 work stealing IOKernel
app /core
thread
runtime a
library L i
NICqueues storage queues
Figure 2-2: Shenango architecture. (a) User applications run as separate processes and link with our kernel-bypass runtime, directly interacting with hardware NIC and storage queues. (b) The IOKernel runs on a dedicated core. It detects compute con-gestion by examining thread, packet, and storage queues, and responds by allocating cores to runtimes. (c) The runtime schedules lightweight application threads on each core and uses work stealing to balance load.
example, Arachne requires 29 microseconds of latency to reallocate a core, primarily because applications communicate with its Core Arbiter using Linux sockets [109].
Dynamic flow steering imposes overheads. In order to saturate high
through-put I/O devices such as 100 Gbits/s NICs, applications must utilize multiple cores.1 However, accessing a single I/O device from a dynamic set of cores can impose signifi-cant overheads, even when each device exposes multiple hardware queues. When core allocations change, applications must either sychronize across cores to agree which core will poll which queue(s), or else reconfigure the flow steering rules on the NIC to ensure that only queues for active cores receive packets. IX employs the latter approach and takes hundreds of microseconds to migrate flow groups from one core to another [1081. In addition, applications will incur expensive cache misses during packet handling if packets that share state (e.g., those belonging to the same TCP flow or coflow) are steered to different cores.
2.2.2
Shenango's Approach
Shenango addresses these challenges with three key ideas. First, Shenango introduces an efficient congestion detection algorithm (§3.1) which determines if an application
'An earlier version of Shenango in which all network traffic was processed by a single core was limited to 6.5 million packets per second. This suffices to saturate a 40 Gbits/s NIC with packets that are at least 770 bytes long, but cannot achieve line rate with faster NICs or smaller packets [100].
would benefit from more cores. This algorithm considers multiple sources of load: the queueing delay of threads, incoming packets, and I/0 completions as well as expired timers.
The congestion detection algorithm requires fine-grained, high-frequency visibility into all sources of pending work for each application. Thus, Shenango's second key idea is to dedicate a single, busy-spinning core to a centralized software entity called the IOKernel (Chapter 3). The IOKernel process runs with root privileges and peeks into application and device queues (stored in shared memory) at microsecond-scale. This enables it to efficiently obtain the queueing information needed by the congestion detection algorithm, to run the algorithm, and to orchestrate core allocations.
Third, Shenango contributes an approach to flow steering (§4.3) that imposes low overhead, tolerates frequent core reallocations, and steers related packets to the same core. This approach assigns each core in an application its own hardware NIC queue, enabling applications to achieve high throughput. When core allocations change, run-times quickly reconfigure hardware steering rules to steer packets to the active set of queues (§4.3.1). Shenango is able to perform these reconfigurations quickly due to careful selection of hardware mechanisms and to per-socket locks which protect flow state during reconfigurations, allowing them to occur asynchronously. In addi-tion, Shenango introduces two abstractions that enable related network traffic to be affinitized, so that related connections can be handled on the same core even as core allocations change (§4.3.2).
With these contributions, core reallocations complete in only 2.2 ps if a core is available or 7.4 ps if a core must be preempted and require less than one microsecond of IOKernel compute time to orchestrate (§6.4). These overheads support a core allocation rate that is fast enough to both adapt to shifts in load and quickly correct any mispredictions in our congestion detection algorithm.
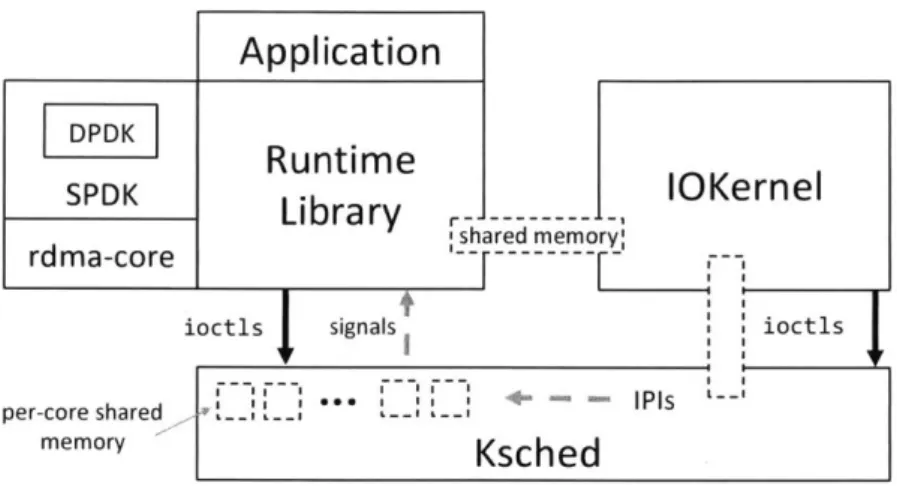
In Shenango, application logic runs in per-application runtimes (Chapter 4), which communicate with the IOKernel via shared memory (Figure 9-1). Each runtime is untrusted and provides useful programming abstractions, including threads, mutexes, condition variables, network sockets, storage queues, and timers. Applications link
with the Shenango runtime as a library, allowing kernel-like functions to run within their address spaces.
At start-up, the runtime creates multiple kernel threads (i.e., pthreads), each with a local runqueue, up to the maximum number of cores the runtime may use. Application logic runs in lightweight user-level threads that are placed into these queues; work is balanced across cores via work stealing. We refer to each per-core kernel thread created by the runtime as a kthread and to the user-level threads as
uthreads. Shenango is designed to coexist inside an unmodified Linux environment;
the IOKernel can be configured to manage a subset of cores while the Linux scheduler manages others. The following chapters describe Shenango's design, implementation, and evaluation in more detail.
15
Chapter 3
Orchestrating Core Reallocations
with the IOKernel
This chapter describes the IOKernel, a single busy-spinning core that orchestrates core reallocations. Its primary tasks are to decide how many cores to allocate to each application at any given time (§3.1) and which cores to allocate to each application
(§3.2). For simplicity, the IOKernel decouples its two decisions; in most cases, it first
decides if an application should be granted an additional core, and then decides which core to grant.
3.1
Congestion Detection
Each application's runtime is provisioned with a number of guaranteed cores and a number of burstable cores. A runtime is always entitled to use its guaranteed cores without risk of preemption (oversubscription is not allowed), but it may use fewer (even zero) cores if it does not have enough work to occupy them. When extra cores are available, the IOKernel may allocate them as burstable cores, allowing busy runtimes to temporarily exceed their guaranteed core limit.
When deciding how many cores to grant a runtime, the IOKernel's objective is to minimize the number of cores allocated to each runtime, while still avoiding compute congestion (§2.2). To determine when a runtime has more cores than necessary,
the IOKernel relies on runtime kthreads to voluntarily yield cores when they are unneeded. When a kthread cannot find any work to do, meaning its local runqueue is empty and it did not find stealable work from other active kthreads, it cedes its core and notifies the IOKernel (we refer to this as parking). The IOKernel may also preempt burstable cores at any time, forcing them to park immediately.
3.1.1
Congestion Detection Algorithm
To determine that a runtime is experiencing incipient compute congestion and would benefit from additional cores, the IOKernel leverages its unique vantage point by monitoring the queue occupancies of kthreads. When a packet arrives or a timer expires for a runtime that has no allocated cores, the IOKernel immediately grants it a core. To monitor active runtimes for congestion, the IOKernel invokes the congestion
detection algorithm at 10 ps intervals (Algorithm 1).
The congestion detection algorithm determines whether a runtime is overloaded or not based on four sources of load: queued threads, queued ingress packets, queued
I/0 completions, and expired timers. If a thread, packet, or completion is found
to be present in a queue for two consecutive runs of the detection algorithm, it indicates that that item queued for at least 10 ps. Because queued items represent work that could be handled in parallel on another core, the runtime is deemed to be "congested." Similarly, expired timers that have not been handled indicate that a runtime is congested. In either of these cases, the IOKernel grants the runtime one additional core. We found that the duration of queuing is a more robust signal than the length of a queue, because using queue length requires carefully tuning a threshold parameter for different durations of requests [109, 124]. If a core cannot be granted immediately because none are idle and the runtime is already using all of its guaranteed cores, the IOKernel marks the runtime as congested, and will consider granting any voluntarily yielded core to it.
1 Function IsAppCongested(app):
2 foreach kthread k of app do
3 prevrun_q *- k's run_q last iteration
4 prevpacket_q 4- k's packet_q last iteration
5 prevcompletion_q 4- k's completion_q last iteration
6 if run_q contains threads in prev run_q then return True
7 if packet_q contains packets in prev_packet_q then return True
8 if completion_q contains completions in prev completion_q then
return True
9 if timer has expired for k then return True
10 end
n1 return False
Algorithm 1: Congestion Detection Algorithm
3.1.2
Detecting Congestion in One Queue
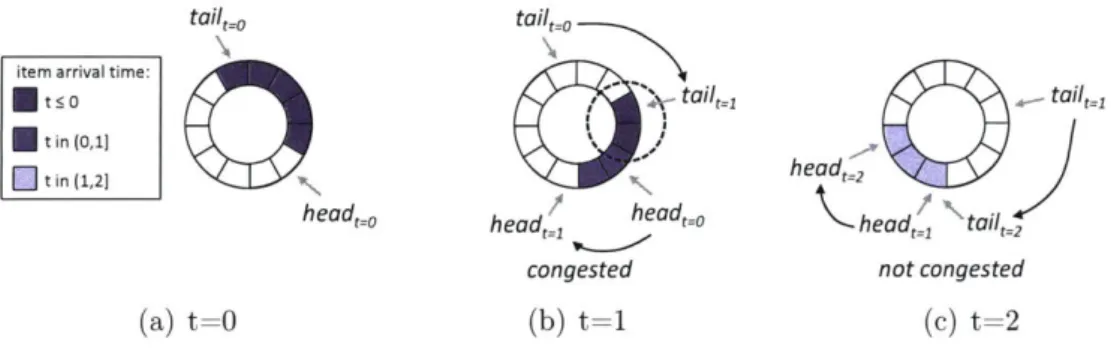
Congestion in a given queue can be detected simply and efficiently if the queue is implemented as a ring buffer, as shown in Figure 3-1. Detecting that an item is present in a queue for two consecutive runs of the detection algorithm is simply a
matter of comparing the current tail pointer with the head pointer from the previous iteration. For example, at time t = 1 in Figure 3-1(b), headt=o > tailt=1 indicates
that the queue is congested.
How does the IOKernel obtain all of these head and tail pointers? Runtimes use
a single cache line of shared memory per kthread to expose the head and tail pointers that they modify to the IOKernel. This includes the head and tail pointers for the runqueue, as well as the tail pointers for packet and storage queues, which indicate how much data the runtime has consumed. Data about the next timer to expire is also stored in this cache line. The IOKernel obtains head pointers for packet and storage queues by monitoring hardware descriptor rings in memory (§5.2).
3.1.3
What Is the Right Core Allocation Interval?
Figure 2-1 demonstrates that 1 ms core allocation intervals must sacrifice either CPU efficiency or tail latency. At the other extreme, allocating an additional core for each task and yielding it immediately when the task completed would achieve 100% CPU
tailt=o tail _O
item arrival time:
S t:5 0 tail t= tailt=1
t in (0,1] h
[]tin(1,2 I X/ head%
headt=0 head'_ headt=0 head- tailt
congested not congested
(a) t=0 (b) t=1 (c) t=2
Figure 3-1: An example of how the IOKernel detects congestion in a queue (a queue is "congested" if any item remains in it for two consecutive runs of the detection algorithm). Between time t=0 in 3-1(a) and time t=1 in 3-1(b), two new items arrive, advancing the head pointer, and three items are processed by the runtime, advancing the tail pointer. At time t=1, two items that were queued at time t=O remain queued, indicating that the queue is congested; the IOKernel detects this by observing that headt=o
>
tailt=1. At time t=2 in 3-1(c), headt=1 = tail=2, indicatingthat the queue is no longer congested.
efficiency and optimal tail latency, but only if reallocating a core could be done with no overhead. In practice, each core reallocation does entail some overhead, preventing the core from being used for useful work for a brief period of time.
Thus the core allocation interval must be chosen judiciously. If the core allocation interval is too short, cores may be reallocated in response to transient bursts that will abate by the time the core is ready to use, thereby wasting CPU cycles on an unhelpful reallocation. Too long of a core allocation interval risks harming tail latency
by reacting too slowly to significant load changes. Furthermore, it is not obvious if a
single fixed core allocation interval is sufficient. For example, is a fixed interval likely to perform well across workloads with different service times?
To better understand the behavior of our congestion detection algorithm with dif-ferent core allocation intervals and workload service times, we consider the behavior of an M/M/1/FCFS queueing system. We calculate the probability that the IOKer-nel will detect compute congestion, assuming a fixed average load.1 We assume for simplicity that the core has a single queue (rather than separate queues for threads,
'This is equivalent to the probability that the waiting time exceeds the core allocation interval. The probability that the waiting time W exceeds t is given by P[W > t] = pe-(1-P) where p is the average load or utilization and y is the average service rate [44].
oM 100%. Service time (ps) .C4 75% 10 .CS / -100 0&50% 2:--Interval (ps) o 25%/-2 / -10 0% 25% 50% 75% 100% Utilization
Figure 3-2: The probability that the IOKernel would detect congestion in a single
M/M/1/FCFS queue with a fixed average load, for different average service times
and core allocation intervals.
packets, etc.), requests follow a Poisson arrival process, and service times are expo-nentially distributed. Figure 3-2 illustrates that, with a given core allocation interval and longer service times, the IOKernel is more likely to allocate an additional core to handle only a few queued requests, even under the same average offered load. This behavior is acceptable because with longer service times, the cycles wasted to reallo-cate a core can be better amortized over the service time. Thus a single fixed core allocation interval may suffice for workloads with different service times. Figure 3-2 also confirms that, for a given service time, smaller core allocation intervals are more likely to cause cores to be reallocated in response to transient bursts.
When selecting a core allocation interval, we consider both how quickly the IOK-ernel should react to newly detected congestion and how long it should wait after granting one core before granting an additional core to the same application. The latter is determined by how long it takes for a core reallocation to complete. If after detecting congestion we allow an application to be granted a second additional core before the first core reallocation has completed, we risk granting multiple cores in response to any small amount of congestion. Thus the IOKernel should not grant multiple cores to the same application within the span of time it takes to reallocate a core; this is about 7 ps if another application needs to be preempted and 2 ps otherwise (§6.4.1).
We use a core allocation interval of 5ps in Shenango because we found that larger intervals were not able to sufficiently rein in tail latency, while shorter intervals
nificantly reduced efficiency (§6.4.3). To ensure that the IOKernel does not grant two cores to the same application before the first core has finished waking, it refrains from granting a runtime additional cores in two consecutive intervals; this ensures that consecutive core allocations to the same application are separated by at least
10 Ps.
3.2
Core Selection
Several factors can influence which core should be allocated to an application at any given time:
1. Hyper-threading efficiency. Intel's HyperThreads enable two hardware threads
to run on the same physical core. These threads share processor resources such as the L and L2 caches and execution units, but are exposed as two separate logical cores [861. If hyper-threads from the same application run on the same physical core, they can benefit from cache locality; if hyper-threads from differ-ent applications share the same physical core, they can contend for cache space and degrade each others' performance. At the same time, hyper-threads from the same application that share a core may also contend for resources. For ex-ample, this can occur if the core only has one functional unit that can perform square roots and the application is square root-intensive.
2. Cache locality. If an application's state is already present in the Li/L2 cache of a core it is newly granted, it can avoid many time-consuming cache misses. Because hyper-threads share the same cache resources, granting an application a hyper-thread pair of an already-running core will yield good cache locality. In addition, an application may experience cache locality benefits by running on a core that it ran on recently.2
3. Socket affinity. On multi-socket machines, an application's performance can
degrade significantly if its cores span multiple sockets. For example, accessing a
2
This benefit is ephemeral; a core with a clock frequency of 2.2 GHz can completely overwrite a
cache line on a remote socket can take 2-7.5 times as long as accessing a cache line on the local socket [47]. Thus it can be beneficial to group cores in the same application on the same socket. However, memory-intensive applications may experience benefits from splitting their cores across multiple NUMA nodes due to the increase in memory bandwidth.
4. Latency. Preempting a core and waiting for it to become available takes time,
and wastes cycles that could be spent doing useful work. Thus, it is better to grant an idle core instead of preempting a busy core when possible.
The IOKernel's policy for deciding which core to grant to an application is pro-grammable, so that users can customize policies for their specific applications and objectives. Here we describe one such core selection policy (Algorithm 2), which considers the factors described above, and which we have found performs well in practice.
A core is only eligible for allocation (function CanBeAllocated) if it is idle, or if the application using core is bursting (using more than its guaranteed number of cores). Amongst the eligible cores, the selection algorithm SelectCore first tries to allocate the hyper-thread pair of a core the application is currently using (lines 2-5). Next, it tries to allocate a core on the socket that the application has indicated that it prefers (function SelectCoreFromSubset). Amongst the cores on the preferred socket, it first tries to find a hyper-thread on a core that has recently been used by this application (lines 11-15). Next, it tried to allocate any idle core, and finally any core from a bursting application. If it fails to find a core on the preferred socket, the algorithm will then consider cores on other sockets.
Once the IOKernel has chosen a core to grant to an application, it must also select one of its parked kthreads to wake up and run on that core. For cache locality, it first attempts to pick one that recently ran on that core. If such a kthread is not available, the IOKernel selects the kthread that has been parked the longest, leaving other kthreads parked in case a core they ran on recently becomes available.
The runtime for each of IsAppCongested(app) and SelectCore(app) are linear in
23
-1 Function SelectCore(app): 2 foreach active core of app do
3 sibling <- the hyper-thread pair core of core
4 if CanBeAllocated(sibling) then return sibling 5 end
6 core - SelectCoreFromSubset (cores on preferred socket) 7 if core is not NULL then return core
8 return SelectCoreFromSubset (cores not on preferred socket) 9
10 Function SelectCoreFromSubset (cores):
n1 foreach recently used core of app do
12 if CanBeAllocated(core) then return core 13 sibling <- the hyper-thread pair core of core 14 if CanBeAllocated(sibling) then return sibling
15 end
16 if there exists an idle core in cores then return core
17 if there exists a core in cores whose app is bursting then return core 18 return NULL
19
20 Function CanBeAllocated(core):
21 return core is idle or core's app is bursting
Algorithm 2: Core Selection Policy
the number of cores on the server. The IOKernel may invoke SelectCore up to once per active application in one pass. Thus the total cost of detecting congestion and granting new cores is O(napps - ncores).
Chapter 4
The Runtime Library
To use Shenango, applications link with the runtime library and express application logic with Shenango's user-level uthreads. The runtime schedules uthreads across the cores allocated to it by the IOKernel (§4.1), provides all networking and other I/O
functionality (§4.2), and manages flow steering (§4.3).
Shenango's runtime enables both programmability and performance. It provides high-level abstractions such as threading, blocking TCP network sockets, blocking storage operations, and synchronization primitives. At the same time, our design scales to thousands of uthreads, each capable of performing arbitrary computation interspersed with synchronous I/O operations. By contrast, many previous kernel-bypass network stacks trade functionality for performance, forcing developers to use restrictive, event-driven programming models with APIs that differ significantly from Berkeley Sockets in order to achieve high network performance
[2,
33, 73, 107].Similar to a library OS
[70,
106], our runtime is linked within each application'saddress space. After the runtime is initialized, applications should only interact with the Linux Kernel to allocate memory; other system calls remain available, but we discourage applications from performing any blocking kernel operations, as this could reduce CPU utilization. Instead, the runtime provides kernel-bypass alternatives to these system calls (in contrast to scheduler activations
[24],
which activates new threads to recover lost concurrency). As an additional benefit, memory and CPU usage, including for packet processing, can be perfectly accounted to each application25
-because the kernel no longer performs these requests on their behalf.
4.1
uThread Scheduling
The runtime performs scheduling within an application across the cores that are dy-namically allocated to it by the IOKernel. During initialization, the runtime registers its kthreads (enough to handle the maximum provisioned number of cores) with the IOKernel and establishes a shared memory region for communicating congestion in-formation. Each time the IOKernel assigns a core, it wakes one of the runtime's kthreads and binds it to that specific core.
Our runtime is structured around per-kthread runqueues and work stealing, sim-ilar to Go
[8]
and in contrast with Arachne's work sharing model[109].
Despite embracing this more traditional design, we found that it was possible to make our uthread handling extremely efficient. For example, because only the local kthread can append to its runqueue, uthread wakeups can be performed without locking. Inspiredby ZygOS, we perform fine-grained work stealing of uthreads to reduce tail latency,
which is particularly beneficial for workloads that have service time variability
11071.
When scheduling uthreads, the runtime employs run-to-completion, allowing uthreads to run uninterrupted until they voluntarily yield (as long as the core is not revokedby the IOKernel). This policy further reduces tail latency with light-tailed request
patterns.1 When a uthread yields, any necessary register state is saved on the stack, allowing execution to resume later. Cooperative yields allow the runtime to save less register state because function call boundaries allow clobbering of some general pur-pose registers as well as all vector and floating point state [841. However, any uthread may be preempted if the IOKernel reclaims a core; in this case all register state must be saved.
To find the next uthread to run after a yield, the runtime first attempts to steal from a parked kthread, to ensure that works does not remain stuck on preempted
'Preemption within an application, as in Shinjuku [711, could reduce tail latency for request patterns with high dispersion or a heavy tail; we leave this to future work.
kthreads. Next the scheduler checks the local runqueue; if it is empty and there are no incoming packets, I/0 completions, or expired timers to process, it attempts to work steal from other kthreads that belong to the same runtime. It first attempts to exploit cache locality by work stealing from the core's hyper-thread sibling. If that fails, the scheduler iterates through all kthreads and tries to steal from each, starting with a random kthread to improve load balancing. It repeats these steps for a couple of microseconds, and if all attempts fail, the scheduler parks the kthread, yielding its core back to the IOKernel.
A kthread's scheduler can avoid parking itself if it knows that work will become
available soon, in order to improve efficiency. If work will become ready in less time than it takes to park and rewake a core (at least 7 ps in Shenango when another application must be preempted), it is more efficient for the kthread to retain the core, and to continue attempting to work steal from other kthreads until the work is ready. Kthreads can anticipate that work will become available soon if they have timers that will expire soon or if they have outstanding storage requests (with our flash device, storage requests can complete in 10 ps
[4]).
4.2
Networking and Storage
Shenango's runtime is responsible for providing all I/0 functionality to the applica-tion. As such, it provides blocking APIs for sending and receiving packets and for issuing reads and writes to storage devices. Underneath these APIs, it implements packet protocol handling (e.g., TCP, UDP, and ARP) and support for storage opera-tions. kthreads directly interface with NIC and storage device hardware queue pairs to perform I/0 operations. This contrasts with an earlier version of Shenango in which runtimes did not directly interact with the NIC hardware; instead, the IOKer-nel polled a single NIC hardware queue and forwarded all network traffic between the NIC and runtimes. However, having the IOKernel on the datapath for all I/0 opera-tions limited throughput to about 6.5 million packets per second. Shenango achieves much better scalability when each runtime core is able to poll its own hardware queue
27