Deep Learning and Domain Transfer for Orca Vocalization Detection
8
0
0
Texte intégral
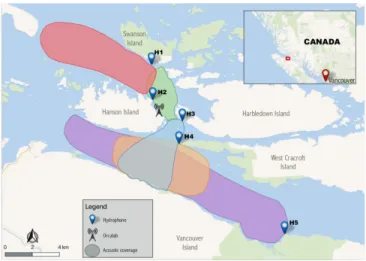
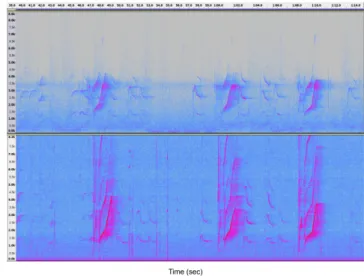
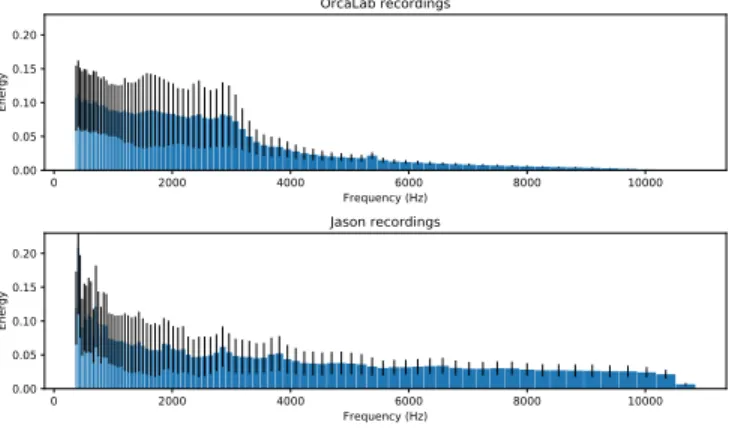
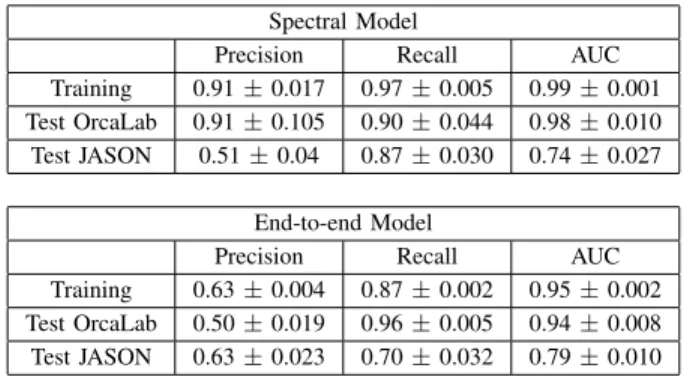
Figure
Documents relatifs
