Adaptive Multiple Description Mode Selection for
Error Resilient Video Communications
by
Brian A. Heng
S.M., Massachusetts Institute of Technology (2001) B.S., University of Minnesota, (1999)
Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment of the Requirements for the Degree of
Doctor of Philosophy in Electrical Engineering and Computer Science
at the
Massachusetts Institute of Technology June 2005
C 2005 Massachusetts Institute of Technology All rights reserved
Signature of Author
4-
. it orDepartment of Electrical Engineering and Computer Science June 29, 2005
Certified by
Accepted by
Jae S. Lim Professor of Electrical Engineering Thesis Supervisor
Arthur C. Smithi
Chairman, Departmental Committee on Graduate Students
Adaptive Multiple Description Mode Selection for
Error Resilient Video Communications
by
Brian A. Heng
Submitted to the Department of Electrical Engineering and Computer Science on June 29, 2005 in Partial Fulfillment of the Requirements for the Degree of
Doctor of Philosophy in Electrical Engineering and Computer Science
Abstract
Streaming video applications must be able to withstand the potentially harsh conditions present on best-effort networks like the Internet, including variations in available bandwidth, packet losses, and delay. Multiple description (MD) video coding is one approach that can be used to reduce the detrimental effects caused by transmission over best-effort networks. In a multiple description system, a video sequence is coded into two or more complementary streams in such a way that each stream is independently decodable. The quality of the received video improves with each received description, and the loss of any one of these descriptions does not cause complete failure. A number of approaches have been proposed for MD coding, where each provides a different tradeoff between compression efficiency and error resilience. How effectively each method achieves this tradeoff depends on network conditions as well as on the characteristics of the video itself.
This thesis proposes an adaptive MD coding approach that adapts to changing conditions through the use of MD mode selection. The encoder in this system is able to accurately estimate the expected end-to-end distortion, accounting for both compression and packet-loss-induced distortions, as well as for the bursty nature of channel losses and the effective use of multiple transmission paths. With this model of the expected end-to-end distortion, the encoder selects between MD coding modes in a rate-distortion (R-D) optimized manner to most effectively trade-off compression efficiency for error resilience.
We show how this approach adapts to both the local characteristics of the video and to network conditions and demonstrate the resulting gains in performance using an H.264-based adaptive MD video coder. We also analyze the sensitivity of this system to imperfect knowledge of channel conditions and explore the benefits of using such a system with both single and multiple paths.
Thesis Supervisor: Jae S. Lim
Dedication
To Mom and Dad,
For Always Believing.
To Susanna,
For Her Encouragement,
Patience, and Love.
Acknowledgements
Many people have contributed to this thesis both directly and indirectly during these past few years. I would like to take this opportunity to recognize these contributions and to thank all those
who have made this accomplishment possible.
I would like to start by thanking my thesis supervisor Professor Jae Lim for his guidance and support during my time at MIT. I am very grateful to him for providing me a place in his lab and for the extensive advice he has given me about both research and life. It was a great honor to work with him these last six years. I would also like to express thanks to Dr. John Apostolopoulos and Professor Vivek Goyal for serving on my thesis committee. They have both spent many hours working with me to improve the quality of this research, and their comments have always been useful and insightful. I would also like to acknowledge Hewlett-Packard and the Advanced Telecommunications and Signal Processing (ATSP) group for their financial support of this research.
My friends and colleagues in the ATSP group have made my time at MIT much more enjoyable, and my interactions with each of them have been rewarding in many ways. Special thanks to fellow Ph.D. students Wade Wan, Eric Reed, and David Baylon for making me feel welcome, for helping me get started, and for continuing to assist me even after their careers at MIT. I would like to thank the group's administrative assistant, Cindy LeBlanc, for making my life here so much easier and for always looking out for me.
I am grateful to Jason Demas, Sherman Chen, and Jiang Fu for the opportunity to work with them at Broadcom Corporation. My summers at Broadcom were very enjoyable, and the knowledge I gained during this time has been immensely helpful. I would also like to thank Davis Pan and Shiufun Cheung for giving me the chance to learn from them during my internship at Compaq Computer Corporation.
I have been fortunate to have a number of supportive and loyal friends throughout my life. I am very lucky to have met Wade Wan when I started at MIT. His guidance and advice have been invaluable and I am grateful to have such a close friend. I would like to thank fellow Ph.D.
student Everest Huang for his companionship and for our many enjoyable conversations. To my group of friends back home, including Neil Dizon, Steve Keu, Dao Yang, Mark Schermerhorn, Efren Dizon, Chris Takase, and Nitin Jain, thank you for always being there.
I am privileged to have a wonderful family. I am especially thankful to my parents Mary Jane and Duane Heng for their unending source of love and support. The opportunities they have provided for me have made this accomplishment possible. I would also like to thank my brother David for his encouragement and for always being a good friend. My family has suffered the loss of my grandparents, James and Margaret Pribyl, while I have been away. I hope in my heart I have made them proud on this day. I honor their memory and will never forget them.
Finally, I am very fortunate to have the love and support of my girlfriend, Susanna. It has been difficult living apart all these years, and I am extremely grateful for her patience and understanding. She has always been my source of strength, and her encouragement and love have made this work possible.
Brian Heng Cambridge, MA June 29, 2005
Contents
1 Introduction... 19
1.1 Video Processing Terminology ... 20
1.2 Multiple Description Video Coding ... 23
1.3 Thesis Motivation and Overview... 27
2 Multiple Description Video Coding... 31
2.1 Multiple Description Coding Techniques... 31
2.1.1 Multiple Description Quantization ... 32
2.1.2 Spatial/Temporal MD Splitting ... 34
2.1.3 MD Splitting in the Transform Domain ... 35
2.2 Predictive Multiple Description Coding ... 38
2.3 Applications of Multiple Description Video Coding... 40
3 Adaptive MD Mode Selection... 43
3.1 Adaptive Mode Selection Systems ... 43
3.2 Rate-Distortion Optimized Mode Selection ... 46
3.2.1 Independent Rate-Distortion Optimization... 46
3.2.2 Effects of Dependencies on Rate-Distortion Optimization ... 50
3.3 End-to-End R-D Optimized MD Mode Selection ... 51
3.3.1 Lagrangian Optimization ... 51
3.3.2 Rate-Distortion Optimization over Lossy Channels... 52
4 Modeling End-to-End Distortion over Lossy Packet Networks ... 53
4.1 Optimal Intra-Coding for Error Resilient Video Streams... 53
4.2 Recursive Optimal Per Pixel Estimate of Expected Distortion ... 55
4.3 Multiple Description ROPE Model ... 56
Contents
5 MD Mode Selection System ... 61
5.1 MPEG4-AVC / H.264 Video Coding Standard... 61
5.1.1 Intra-Frame Prediction... 64
5.1.2 Hierarchical Block Motion Estimation... 65
5.1.3 Multiple Reference Frames... 66
5.1.4 Quarter Pixel Motion Vector Accuracy ... 67
5.1.5 In-Loop Deblocking Filter... 68
5.1.6 Entropy Coding... 69
5.1.7 H.264 Performance ... 70
5.2 MD System Implementation... 71
5.2.1 Examined MD Coding Modes ... 72
5.2.2 Data Packetization ... 74
5.2.3 Discussion of Modifications Not in Compliance with H.264 Standard ... 75
6 Experimental Results and Analysis... 77
6.1 Test Sequences... 78
6.2 Performance of Extended ROPE Algorithm... 81
6.3 MD Coding Adapted to Local Video Characteristics... 85
6.4 MD Coding Adapted to Network Conditions... 91
6.4.1 Variations in Average Packet Loss Rate... 91
6.4.2 Variations in Expected Burst Length... 94
6.5 End-to-End R-D Performance ... 97
6.6 Unbalanced Paths and Time Varying Conditions... 99
6.6.1 Balanced versus Unbalanced Paths... 101
6.6.2 Time Varying Network Conditions ... 102
6.7 Sensitivity Analysis ... 104
6.7.1 Sensitivity to Packet Loss Rate... 106
6.7.2 Sensitivity to Burst Length ... 111
Contents
7 Conclusions... 121
7.1 Sum m ary... 121
7.2 Future Research Directions... 123
List of Figures
1.1 Scan Modes for Video Sequences ... 21
1.2 Gilbert Packet Loss Model ... 23
1.3 Two Stream Multiple Description System... 24
1.4 Classic Depiction of an MD System... 24
1.5 Example of Multiple Description Video Coding ... 25
1.6 Comparison between Scalable Video Coding and MD Coding ... 27
2.1 MD Coding of Audio... 32
2.2 MD Scalar Quantization ... 33
2.3 MD Splitting of an Image ... 35
2.4 Transform Domain MD Splitting ... 36
2.5 Applications of MD Coding ... 41
3.1 Dynamic Programming Tree ... 48
3.2 Comparison between Lagrangian Optimization and Dynamic Programming... 49
4.1 Conceptual Computation of First Moment Values in MD ROPE Approach ... 57
4.2 Gilbert Packet Loss Model ... 58
5.1 H.264 Encoder Architecture ... 62
5.2 H.264 Decoder Architecture ... 62
List of Figures
5.4 Two of the Nine Available 4x4 Intra-Prediction Modes ... 63
5.5 16x16 Intra-Prediction M odes ... 64
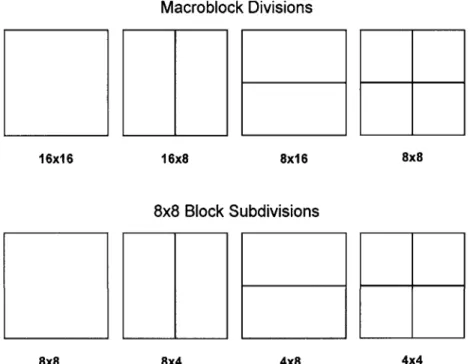
5.6 Macroblock Partitions for Motion Estimation... 65
5.7 M ultiple Reference Fram es... 66
5.8 Six-Tap Filter used for Half Pixel Interpolation... 67
5.9 In-Loop D eblocking Filter ... 68
5.10 Examined MD Coding Modes ... 72
5.11 Packetization of Data in MD Modes... 75
6.1 Performance of ROPE Algorithm - Actual vs. Expected PSNR... 80
6.2 Tim e Varying Packet Loss Rates... 82
6.3 Performance of ROPE Algorithm with Time Varying Loss Rates... 83
6.4 Bernoulli Losses versus Gilbert Losses with ROPE Algorithm... 84
6.5 MD Coding Adapted to Local Video Characteristics... 86
6.6 Distribution of Selected MD Modes - Foreman Sequence ... 87
6.7 Visual Results - Frame 5 Foreman Sequence ... 89
6.8 Visual Results - Frame 231 Foreman Sequence ... 90
6.9 PSNR versus Average Packet Loss Rate ... 92
6.10 PSNR versus Expected Burst Length ... 95
6.11 Effects of Expected Burst Length on the TS Mode ... 96
6.12 End-to-End R-D Performance at 5% Loss Rate with Burst Length of 3... 98
List of Figures
6.14 Distribution of Selected MD Modes - Time Varying Loss Rates... 103
6.15 PSNR versus Frame with Time Varying Loss Rates... 105
6.16 Sensitivity to Errors in Assumed Packet Loss Rate - Part 1 ... 107
6.17 Sensitivity to Errors in Assumed Packet Loss Rate - Part 2 ... 109
6.18 Sensitivity of ADAPT Relative to Non-Adaptive Methods ... 110
6.19 Sensitivity to Errors in Assumed Burst Length - Part 1... 112
6.20 Sensitivity to Errors in Assumed Burst Length - Part 2... 113
6.21 Comparison of Single Path vs. Multiple Paths ... 114
6.22 Multiple Paths vs. Single Path - Variations in Expected Burst Length ... 116
6.23 Multiple Paths vs. Single Path - Variations in Packet Loss Rate... 118
List of Tables
5.1 Exponential-Golomb Codebook ... 69
5.2 List of M D Coding M odes... 74
6.1 Test Sequences... 79
6.2 Distribution of MD Modes at 0%, 5%, and 10% Packet Loss Rates... 93
6.3 Distribution of MD Modes at Various Burst Lengths ... 97
6.4 Distribution of MD Modes with Unbalanced Paths ... 101
Chapter
1
Introduction
The transmission of video information over error prone channels poses a number of interesting challenges. One would like to compress the video as much as possible in order to transmit it in a timely manner and/or store it within a limited amount of space. Yet, by compressing a video sequence, one tends to make it more susceptible to transmission losses and errors. Video applications ranging from high definition television down to wireless video phones all face this same tradeoff. However, best-effort networks like the Internet present a particularly harsh environment for real-time streaming video applications. In this type of environment, applications must be able to withstand inhospitable conditions including variations in available bandwidth, packet losses, and delays. Those that are unable to adapt to these conditions can suffer serious performance degradations each time the network becomes congested.
Multiple description (MD) video coding is one approach that can be used to reduce the
detrimental effects caused by packet loss on best-effort networks. In a multiple description system, a video sequence is coded into two or more complementary streams in such a way that each stream is independently decodable. The quality of the received video improves with each received description, but the loss of any one of these descriptions does not cause complete failure. If one of the streams is lost or delivered late, the video playback can continue with hopefully only a slight reduction in overall quality.
There have been a number of proposals for MD video coding, each providing its own tradeoff between compression efficiency and error resilience. Previous MD coding approaches applied a single MD technique to an entire sequence. However, the optimal MD coding method will depend on many factors including the amount of motion in the scene, the amount of spatial detail, desired bitrates, error recovery capabilities of each technique, and current network conditions. This thesis examines the adaptive use of multiple MD coding modes within a single sequence. Specifically, this thesis proposes adaptive MD mode selection by allowing the encoder to select among MD coding modes in an optimized manner as a function of local video characteristics and network conditions.
The following section presents a brief introduction to video processing, establishing the terminology used throughout this thesis and providing background information necessary for discussing this work. In the second section, we discuss the motivation behind this research and present an overview of this thesis.
1.1
Video Processing Terminology
A video frame is a picture made up of a two-dimensional discrete grid of pixels or picture
elements. A video sequence is a collection of frames, with equal dimensions, displayed at fixed
time intervals. The dimensions of each frame are referred to as the spatial resolution, and the resolution along the temporal direction is known as the frame rate. The term macroblock is used to describe a subdivision of a frame of size 16x16 pixels. For the purposes of this research, a
video stream will be defined as a sequence transmitted across the given network (e.g. the
Internet, wireless connections, etc...) and viewed in real-time. This differs from video file
transfer in which sequences are fully downloaded and playback only begins once the entire
video sequence has been received. Buffering is the process of storing up data at the receiver before playback begins in the event that the network throughput drops temporarily. All streaming applications use some amount of buffering in order to reduce the effect of variations in network bandwidth and delay. The more buffering used, the longer it takes to initially fill that buffer, and thus, the more delay experienced at the receiver. Video file transfer is essentially the same as maximum buffering; the entire video sequence is stored at the receiver before playback begins.
The scan mode is the method in which the pixels of each frame are displayed. As shown in
Figure 1.1, video sequences can have one of two scan modes: progressive or interlaced. A progressive scan sequence is one in which every line of the video is scanned in every frame. This type of scanning is typically used in computer monitors, handheld devices, and high definition television displays. An interlaced sequence is one in which the display alternates between scanning the even lines and odd lines of the corresponding progressive frames. The termfield is used (rather than frame) to describe pictures scanned using interlaced scanning, with the even field containing all the even lines of one frame and the odd field containing the odd lines. Interlaced scanning is currently used in many standard television displays. The process of interlaced to progressive conversion is known as deinterlacing.
Interlaced Progressive
n-1 n-1
n n
field frame
(a) (b)
Figure 1.1: Scan modes for video sequences. (a) In interlaced fields either the even or the odd lines are scanned. The solid lines represent the field that is present in the current frame. (b) In progressively scanned frames all lines are scanned in each frame.
The main focus of this research will be on real-time video streaming and the difficulties presented when the network is unable to meet necessary time constraints. With this application in mind, the sequences analyzed in this work are progressively scanned sequences since the vast majority of computer and handheld displays use progressive scanning. However, it is sometimes useful to process fields independently, which is where the concepts of interlacing and deinterlacing become important. Also, the work described here could later be applied to interlaced sequences in a fairly straightforward manner.
The extensive bandwidth required for transmission of raw video sequences is typically not feasible, so most systems require the use of significant video compression to reduce the amount of bandwidth needed. There can be a considerable amount of redundant information present in a typical video sequence in both the spatial and temporal directions. Within a single frame, each pixel is likely to be highly correlated with neighboring pixels since most frames contain relatively large regions of smoothly varying intensity. Similarly, in the temporal direction two frames are likely to be highly correlated since typical sequences do not change rapidly from one frame to the next. There are many ways to take advantage of this redundancy in video coding. To reduce correlation along the temporal direction, most video coders use some form of motion
estimation / motion compensation to predict the current frame from previously decoded frames.
In this approach, the encoder estimates the motion from one frame to the next, and uses this model to generate a prediction of the next frame by compensating for the motion that has
Introduction
occurred. Coded blocks that depend on other frames due to the use of motion compensated prediction are referred to as inter-coded blocks; blocks that do not depend on any other frames are referred to as intra-coded. Once the temporal redundancy has been exploited, most encoders use the Discrete Cosine Transform (DCT), or some other decorrelating transform, to remove as
much remaining redundancy as possible from the spatial dimension.
Despite efficient exploitation of the spatial and temporal redundancy present in typical video sequences, the resulting bandwidth is typically not low enough to allow for lossless transmission. For this reason, lossy compression algorithms are necessary for an effective transmission scheme. For the purposes of this thesis, the distortion caused by losses during data compression as well as losses during network transmission will be quantitatively measured using
the peak-signal-to-noise ratio (PSNR). The PSNR for a given frame is defined as
PSNR =10 -lo 5 (1.1)
(MSE)
where the mean square error (MSE) is the average squared difference between the original and distorted video frames, F, and Fd .
NI-1 N2-1
MSE= NIN I I(F[n,n 2]-Fd[n n 2 (1.2)
n1=0 n2=0
Here the values N, and N2 represent the horizontal and vertical dimensions of the frames, and
the values n and n2 are used to index each pixel location. The value 255 is used as the peak
signal value since it is the maximum value encountered with 8-bit pixel representations. It should be noted that PSNR and perceived quality are not always directly correlated. Higher PSNR does not necessarily indicate better video, but the use of PSNR is a common practice and has been found to be a useful estimate of video quality.
In this thesis we have simulated network losses by using various probabilistic packet loss models. In the Bernoulli loss model, the packet losses are independent and have equal probability. Actual network losses tend to arrive in bursts, a behavior that is not captured by the Bernoulli loss model and that has been shown to significantly affect video quality [2, 27]. We use the Gilbert model to simulate the nature of bursty losses where packet losses are more likely
Introduction
State 1: packet received
State 0: packet lost 1-PO
Average Packet Loss Rate =
1+ p1 - pO
Po0 0
1
1Expected Burst Length - 0I P P1
Figure 1.2: Gilbert packet loss model. Assuming pi < po , there is a greater probability the current packet will be lost if the previous packet was lost. This causes bursty losses in the resulting stream.
if the previous packet has been lost. This can be represented by the Markov model shown in Figure 1.2 assuming p, < po.
1.2
Multiple Description Video Coding
The demand for streaming video applications has grown rapidly over recent years, and by all indications this demand will continue to grow in the future. However, the majority of packet networks, like the Internet, provide only best-effort service; there are no guarantees of minimum bandwidth or delay [54]. Applications must be able to withstand changing conditions on the network or they can suffer severe performance degradations.
For some applications, these problems can be reduced by using a suitable amount of buffering at the receiver. However, buffering introduces an extra delay in the system that is unacceptable for many applications such as video conferencing. This type of application requires a high degree of interaction between opposite ends of the network and places stringent demands on end-to-end delay. There exists a limit on the maximum amount of delay that can exist between two users attempting to maintain a reasonable conversation. Once this limit is exceeded, the two parties can no longer interact without significant effort. Therefore significant buffering is not an option. Even in applications where some amount of buffering is acceptable, the amount of buffering necessary in any situation is unknown ahead of time due to the time-varying properties of the network. Occasionally network links fail altogether, and there may be some extended period of time during which two nodes in the network cannot talk to one another at all. This type of outage can underflow any reasonably-sized buffer. For these reasons, current approaches for
Introduction
Packet Network
Original MD Packet Stream 1 MD Reconstructed
Video Encoder Decoder
Packet Stream 2
Figure 1.3: Two stream multiple description system. The original video source is
encoded into two complementary streams which are transmitted independently through the network. As long as both streams are not simultaneously lost, the remaining stream
can still be decoded to achieve acceptable video quality.
Reconstructed Video Decoder 1 - Good Quality
Original _ MD Decoder 0 -+ Best Quality
Video
EncoderI
Decoder 2 -+ Good Quality
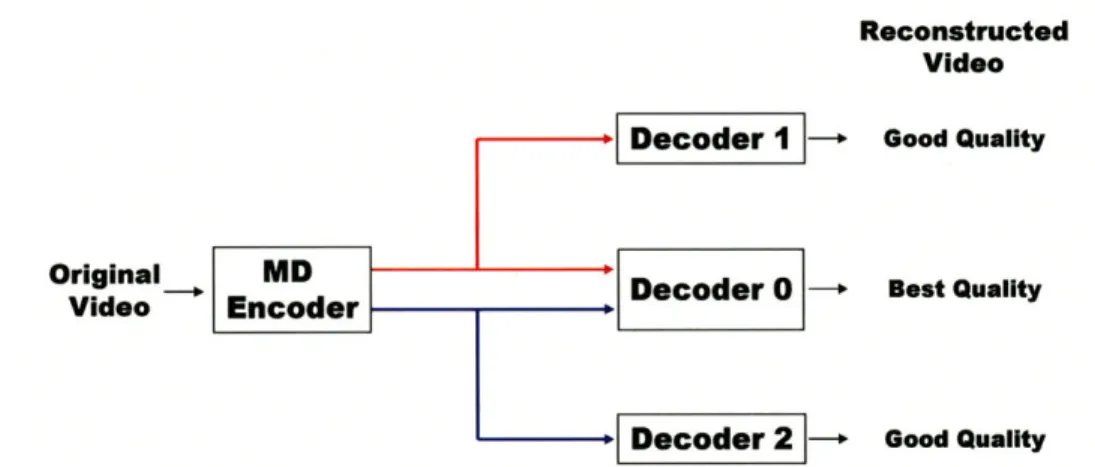
Figure 1.4: Classic depiction of a two stream MD coding system. The central decoder (Decoder 0) uses both descriptions to reconstruct the highest quality video. The two side decoders (Decoders 1 and 2) use only one description to generate acceptable quality video.
real-time video streaming often suffer from severe glitches each time the network becomes congested.
Multiple description video coding is one method that can be used to reduce the detrimental effects caused by this type of best-effort network. In a multiple description system, a video sequence is encoded into two or more complementary streams in such a way that each stream is independently decodable (see Figure 1.3). When combined, the streams provide the highest level of quality, but even independently they are able to provide an acceptable level of quality. These streams can then be sent along separate paths through the network to experience more or less
... *4 4 6 8 1..
Figure 1.5: One example of multiple description coding. Original sequence is partitioned along the temporal direction into even and odd frames. Even frames are predicted from even frames and odd from odd. If an even frame is lost (e.g. Frame 4), errors will propagate to other even frames, but the remaining description (the odd frames) can still be straightforwardly decoded, resulting in video at half the original frame rate.
independent losses and delays. In the event that a portion of one of the streams is lost or delivered late, the video playback will not suffer a severe glitch or stop completely to allow for rebuffering. On the contrary, the remaining stream(s) will continue to be played out with only a slight reduction in overall quality. Conceptually, a two stream MD decoder can be thought of as three separate decoders, as shown in Figure 1.4. Here the central decoder (Decoder 0) is able to decode both descriptions resulting in the highest quality video. The two side decoders (Decoders 1 and 2) receive only one of the descriptions resulting in lower, but still acceptable, video
quality.
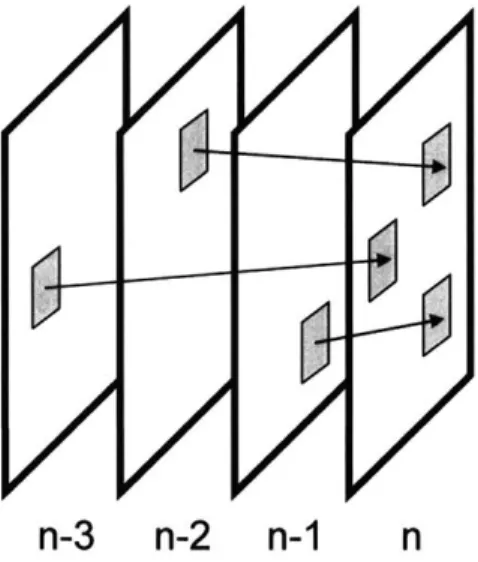
Perhaps the simplest example of an MD video coding system is one where the original video sequence is partitioned along the temporal direction into even and odd frames that are then independently coded into two separate streams for transmission over the network. As shown in Figure 1.5, this approach generates two descriptions, where each has half the temporal resolution of the original video. In the event that both descriptions are received, the frames from each can be decoded and interleaved together to reconstruct the full sequence. In the event one stream is lost, the remaining stream can still be straightforwardly decoded and displayed, resulting in video at half the original frame rate.
Of course, this gain in robustness comes at a cost. Temporally sub-sampling the sequence lowers the temporal correlation, thus reducing coding efficiency and increasing the number of bits necessary to maintain the same level of quality per frame. Without losses, the total bit rate necessary for this MD system to achieve a given distortion will in general be higher than the
Introduction
corresponding rate for a single description (SD) encoder to achieve the same distortion. This is a tradeoff between coding efficiency and robustness. However, in the type of application under consideration, it is not so much a question of whether it is useful to give up some amount of efficiency for an increase in reliability as it is a question of finding the most effective way to achieve this tradeoff.
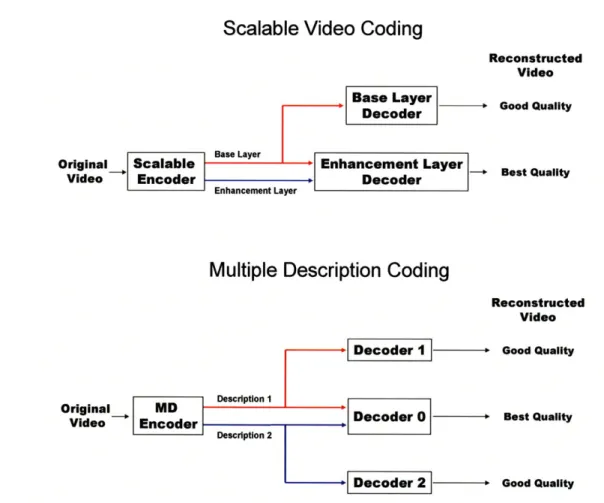
It should be noted here that multiple description coding is not the same as scalable video coding. Similar to MD coding, a scalable coder encodes a sequence into multiple streams that are referred to as layers. However, scalable coding makes use of a single independent base layer followed by one or more dependent enhancement layers (see Figure 1.6). This allows some receivers to receive basic video by decoding only the base layer, while others can decode the base layer and one or more enhancement layers to achieve improved quality, spatial resolution, and/or frame rate. However, unlike MD coding, the loss of the base layer renders the enhancement layer(s) useless. In some sense, scalable coding is a special case approach to multiple description coding where it is assumed that the base layer will be delivered with absolute reliability.
Scalable Video Coding
Reconstructed Video
Base Layer P Good Quality
Decoder
Original Scalable Enhancement Layer - Best Quality Video Encoder Decoder
Enhancement Layer
Multiple Description Coding
Reconstructed
Video
Decoder 1 Good Quality
Original MD Decoder 0
- Best Quality Video Encoder
Description 2
Decoder 2 - Good Quality
Figure 1.6: A comparison between scalable video coding and multiple description
coding. In scalable coding the enhancement layer(s) are dependent on the base layer, and therefore the enhancement layer alone is not useful. In multiple description coding, each stream is equally important, so either Description 1 or Description 2 will still yield acceptable video quality.
1.3
Thesis Motivation and Overview
There have been many approaches proposed for MD coding, each providing a different tradeoff between compression efficiency and error resilience. How efficiently each method achieves this tradeoff depends on the quality of video desired, the current network conditions, and the
characteristics of the video itself. Most prior work in MD coding apply a single MD method to the entire sequence; this approach is taken so as to evaluate the performance of each MD method. However, it would be more efficient to adaptively select the best MD method based on
the situation at hand [22]. Since the encoder in such a system has access to the original source, it is possible to analyze the performance of each coding mode and adaptively select between them in an optimized manner. That insight has provided the main motivation for this research. Variations in both source material and network conditions make it highly unlikely that any single MD approach will be most effective under all situations. By selecting between a small number of complementary MD modes, it is possible for the system to more effectively adapt to all possible video inputs and network conditions.
A number of adaptive MD approaches have been previously proposed [26, 33, 34, 47], but the concept of adaptive MD mode selection has not been fully explored. In general, previous adaptive approaches have used a single approach to MD coding, but have allowed the encoder to adjust the amount of redundancy used to match source and/or channel characteristics. Dynamically trading off compression efficiency for error resilience, in such a way, can provide significant improvements over a non-adaptive MD approach, but fundamentally each of these systems use a single MD method for an entire sequence. For instance, if the encoder in such a system encounters a block that is particularly susceptible to errors, the response taken is to increase redundancy and therefore increase the number of bits used to code this region. However, it may be more effective to use an entirely different approach for this region, which may allow the encoder to achieve the same error resilience without increasing the bitrate as
significantly, if at all.
The main goal of this thesis is to investigate the use of adaptive MD mode selection and better understand its applicability to error resilient video streaming. There are many different aspects of this idea that have not been fully explored. For instance, can we find a small set of complementary MD modes that is able to adapt to a variety of video sources and network conditions? If there are gains possible from adaptive mode selection, can these gains overcome the overhead necessary for adaptive processing? Is it even possible for the encoder to make mode selection choices in an optimized manner? We have previously suggested that the encoder can analyze the performance of each MD method, however the random nature of channel losses combined with spatial and temporal error propagation make this quite a difficult task. These are some of the questions that motivated this work.
In the second chapter of this thesis, we provide a more detailed introduction to multiple description video coding and provide an overview of previous research in this field. The chapter begins with a review of MD coding techniques followed by a discussion of some of the issues
Introduction
that arise specifically when applying MD coding to video compression. The final section of Chapter 2 discusses some applications that are particularly well suited for the use of MD coding.
Chapter 3 provides a more in-depth introduction to the concept of adaptive MD mode selection. Section 3.1 reviews the role adaptive mode selection has played throughout the history of video processing and describes some previous uses of adaptive mode selection. Section 3.2 discusses the process of optimal mode selection and provides a review of rate-distortion (R-D) theory. Finally, Section 3.3 describes how these techniques can be used for adaptive MD mode selection and also includes a discussion on R-D optimization for lossy packet networks.
The use of R-D optimization over lossy channels requires the use of some form of channel modeling to estimate the effects potential losses will have on end-to-end distortion. Chapter 4 provides a review of previous attempts at this type of modeling and suggests one particular approach that can quite effectively model end-to-end distortion taking into account both the distortion due to quantization as well as the distortion due to channel losses.
Chapter 5 provides an overview of the system designed to investigate the concept of adaptive MD mode selection. The system has been implemented based on the H.264 video coding standard. The first portion of Chapter 5 reviews the H.264 codec to provide the necessary background information for discussing this work. The remainder of Chapter 5 details the specific implementation of the system we have used in this thesis.
The implementation described in Chapter 5 has been used to perform a number of different simulations in order to evaluate the performance and behavior of the adaptive MD mode selection system. The results of these experiments are provided in Chapter 6. We show how this approach adapts to both the local characteristics of the video and to network conditions and demonstrate the resulting gains in performance using our H.264-based adaptive MD video coder. We also analyze the sensitivity of this system to imperfect knowledge of channel conditions and explore the benefits of such a system when using both single and multiple paths.
Chapter 7 summarizes the main conclusions of this thesis and describes possible future research directions.
Chapter 2
Multiple Description Video Coding
This chapter provides a more detailed introduction to multiple description video coding and provides a summary of previous research in this area. The first section discusses several techniques commonly used for multiple description coding and some background on the history of the topic. Predictive coding is used in most video coding systems to remove the temporal redundancy that exists in typical video sequences. This approach significantly increases the efficiency of the overall system but also introduces the possibility for error propagation. Section 2.2 discusses some of the challenges introduced by the use of predictive coding in a MD system and some of the approaches that have been used for addressing these issues. Finally, in Section 2.3, we discuss some applications that are particularly well suited for the use of MD video coding.
2.1
Multiple Description Coding Techniques
The multiple description approach was originally introduced for audio coding through research done at AT&T Bell labs in the 1970s to increase the reliability of the telephone system. One early approach was suggested by Jayant [24, 25]. Here audio is partitioned along the temporal direction into even and odd samples in an attempt to improve the reliability of digital audio communications (see Figure 2.1). In this approach, if either stream is lost, the remaining stream can still be played at half the original sampling rate.
Around the same time, the MD problem was introduced into the information theory community by Wyner, Witsenhausen, Wolf, and Ziv [52, 53]. This problem became very interesting from a theoretical point of view and much work has been done to analyze the problem in depth. The main focus in the information theory community has been on characterizing the multiple description region, defined as the set of all achievable operating points, under various assumptions about the statistical properties of the source. Extensive work has been done to map
Multiple Description Video Coding
T
r
Stream 1
Original Audio
Stream 2
Figure 2.1: Multiple description coding of audio using even-odd sample splitting. Each
sub-sampled audio stream is encoded independently and transmitted over the network. The temporary loss of either stream can be concealed by up-sampling the correctly received stream by interpolating the missing values [24].
out achievable rate-distortion regions using multiple description codes for channel splitting [14]. The problem has many variations including generalizations to more than two channels.
For some time, multiple description coding was viewed only as an interesting information theory problem. Only in recent years has the value of MD coding become apparent. The widespread use of packetized multimedia applications over best-effort networks has brought the MD problem to forefront. Using multiple description coding for packetized data can provide a powerful tool for providing error resilient packet streams. Many approaches have been suggested for multiple description coding including correlating transforms [18, 34, 48, 49], MD-Forward Error Correction (FEC) techniques [11, 32], as well as MD splitting in the spatial [43], temporal [1, 2], and transform domains [6, 8, 9, 19, 36]. Some of these methods are further discussed in the following sections. For a more in depth review of the MD problem, see the overview by
Goyal [15].
2.1.1 Multiple Description Quantization
One of the early proposals for MD coding was multiple description quantization [41, 43]. Here two or more complementary quantizers are used to compress the original source. A single quantization gives a coarse reconstruction of the source. Any additional received quantizations
Chapter 2 Multiple Description Video Coding 0 1 2 3 4 5 6 7 I I I I I I I L 0 1 2 3 4 5 6 7 1 1 1 1 1 1 1 1 Combined 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Figure 2.2: Multiple description scalar quantizer. Quantizers 1 and 2 independently
describe the original source with 3 bits of accuracy. When combined together (by taking the average of the two reconstruction levels) they can provide 3.9 bits of accuracy.
further refine this description. Given that quantizers are already an essential piece in any lossy compression system, making slight modifications to form MD quantizers can be an easy way to generate multiple descriptions of a source. One can design complementary quantizers that alone coarsely describe a single source, but when combined together provide a more refined description.
As a simple example, consider Figure 2.2. Here the reconstruction levels from two uniform scalar quantizers independently divide the given space. Both of these are three bit quantizers and they can each provide coarse descriptions of the original source. However, when both quantizations are received, the two reconstructions can be combined to generate the 15 reconstruction levels shown below. The example shows how to use two complementary 3-bit quantizers to create a log2 (15) = 3.9 bit combined quantizer.
As with any MD approach, the example above makes a tradeoff between compression efficiency and error resilience. Using a single description coding approach with the same number of bits, the encoder could have described this source with 6 bits of accuracy. However, in general if this data had been lost there would be no way of reconstructing it. The MD approach sacrifices 2.1 bits of accuracy for an increase in error resilience. This is only one example of possible quantizers. Through proper choice of reconstruction levels, systems with more or less redundancy can be easily designed. This is one beneficial feature of MD quantization. The same concept is extendable to vector quantization and trellis coded quantization as well [12, 16, 42, 45].
Quantizer
1
Multiple Description Video Coding
2.1.2 Spatial/Temporal MD Splitting
A straightforward method of creating multiple description streams is to sub-sample a sequence along the spatial or temporal direction and encode each sub-sequence independently. The significant redundancy in video or audio data, for example, can be used quite effectively to reconstruct any missing descriptions.
Figure 2.1 is an illustration of this approach applied to audio coding, but the same idea can be extended to video coding as well. The original video sequence could, for example, be partitioned temporally into even and odd frames. As shown in Figure 1.5, this approach generates two descriptions, where each has half the frame rate of the original video. In the event that both descriptions are received, the frames from each can be interleaved to reconstruct the full sequence. In the event one stream is lost, the other stream can still be straightforwardly decoded and displayed, resulting in video at half the original frame rate.
One such approach has been suggested by Apostolopoulos [1]. Here the author develops a novel approach for repairing a damaged description by using a clean description through the use of sophisticated motion compensated temporal interpolation. The wealth of information present in correctly received previous and future frames can be used to accurately estimate missing frames. By filtering the motion vector fields from neighboring frames, an estimate of the motion vectors from the current frame can be obtained. Then, the data from the missing frame is estimated by interpolating along these motion vectors, while accounting for covered and uncovered regions.
It has been shown that this approach can accurately reconstruct missing frames. However, this gain comes at a cost. In order to maintain two separate prediction loops, motion compensated prediction cannot be used with directly adjacent frames; even frames must be predicted from even frames and odd from odd. Since temporal prediction decreases in efficiency as the distance between two frames increases, these two streams are coded less efficiently than when they are coded as a single stream.
Chapter 2 MultilE Cdesripi -+ o odn
Figure 2.3: Spatial splitting of an image. The original image is low-pass filtered using
four shifted averaging filters. The outputs are then sub-sampled and independently JPEG encoded. After transmission, the loss of any one stream can be concealed quite accurately given the significant correlation with the remaining streams [46].
One approach for splitting data in the spatial direction was suggested by Wang and Chung for image coding [46]. Their algorithm creates four sub-images by filtering an image with an averaging filter and its shifted variants (see Figure 2.3). They found that this approach was extremely robust, but correspondingly very inefficient. The correlation between the four streams allows for very accurate reconstruction when one description is missing. This also greatly reduces coding efficiency, since the encoder cannot make use of this correlation to help reduce the bit rate. In the end, their encoder required nearly double the bit rate to achieve the same distortion as the single stream case in the absence of losses.
2.1.3 MD Splitting in the Transform Domain
Given the inefficiencies of spatial or temporal domain splitting, many have suggested making use of the compression efficiency of decorrelating transforms, like the DCT, prior to partitioning the sequence (see Figure 2.4). By decorrelating the data first, a significant gain in compression efficiency is obtained. However, this gain comes at the cost of reconstruction quality since
Chapter 2 Multiple Description Video Coding
Figure 2.4: Transform domain multiple description splitting. Use of the decorrelating transform (e.g. DCT) prior to partitioning allows the MD encoder to take advantage of the significant spatial correlation present in a video sequence. The transformed coefficients are then partitioned, quantized, and independently entropy coded [6].
transformed coefficients are, by design, less correlated and thus more difficult to predict from one another.
In image and video coding, the multiple description quantizers presented in Section 2.1.1 are essentially transform domain splitting techniques. Strictly speaking, they do not need to be used in the transform domain, and can work quite effectively in spatial/temporal domains, as is done in speech applications. In image and video coding, the transform domain is where quantization takes place, and thus, MD quantization is one approach for transform domain splitting. The only reason MD quantization appears separately in this chapter is that it was not historically developed specifically for use in the transform domain.
The use of correlating transforms is another approach for transform domain splitting. In general, there exists extensive correlation between neighboring pixels of an image or video frame. In image or video coding the purpose of decorrelating transforms, like the DCT, is exactly that: to decorrelate the input variables and to reduce spatial correlation. This allows for much more efficient coding and significant bit rate reduction. However, by removing this correlation between transformed coefficients, it becomes very difficult to estimate missing coefficients in the event that one of the descriptions is lost. One method to help solve this problem is the use of correlating transforms [17, 49]. These transforms add back correlation between coefficients by introducing statistical redundancy. The variance of the resulting coefficients, conditioned on correctly receiving other descriptions, can be significantly reduced and can allow much more accurate estimation.
Consider the following example. Let,
[y,][A B[xl](2.1)
Y2 _C D x2
. ... ... .
-Multiple Description Video Coding Chapter 2
where x, and x2 are zero-mean independent Gaussian random variables with variances oC and 72 respectively. E [yIy2]= E [(A -x, + B. x 2 ) (C -x +D. x2) (2.2) =AC - +BD-a22
Given that the correlation between x, and x2 was 0 by definition, any appropriate choice for A,
B, C, and D will increase the correlation between y, and y2 relative to the correlation between
x1 and x2 . At this point, assuming y2 has been lost, y, can be used to estimate x, and x2
-Depending on whether y, or y2was correctly received, and given that the random variables are jointly Gaussian, the optimal estimators are
X,~ A 72Y (2.3) LA 2 A207+B2o2 BoJ(. 1 1 Cc7 22 y (2.4) 2 C2f+D2 _Dcr22
-The corresponding average mean squared error distortions are
( A2 +B2)aofiy (C2 +D2)0a
given y1 or given Y. (2.5)
2(A2o2+ B22 ) 2(C2o2+D22 2
With appropriate choices for A, B, C, and D, these expected distortions can be made lower than
2 2
the expected distortion using only x, and x2, namely " or 2. As always, this gain comes at a cost. The increased correlation between y, and y2 will decrease the relative efficiency of
entropy coding and will increase the bit rate of the stream. Also, and perhaps more important for image and video coding, is that this type approach can be highly inefficient when most of the quantized coefficients are equal to zero. Most image/video coders use run-length encoding (encoding the number of consecutive zeros, not each individual zero value) to take advantage of this sparse nature of quantized coefficient data. The use of correlating transforms will generally
increase the number of nonzero coefficients, which decreases the effectiveness of run-length coding and can be very costly.
In contrast to methods like the correlating transforms suggested above, that insert artificial redundancy into the transformed coefficients, a number of techniques have been developed that make use of splitting transformed coefficients directly. Using the block-based DCT and splitting coefficients in the DCT domain is one option. However, DCT coefficients are highly uncorrelated and any attempt at reconstruction when one description is missing can leave a great deal of visual distortion. In [8] and [9], this idea is modified by using a lapped orthogonal transform. The overlapping nature of this particular transform introduces redundancy and allows for easier reconstructions in the event of lost descriptions. Bajic and Woods suggest using sub-band wavelet transforms rather than a DCT allowing for more accurate reconstruction by using interpolation in the lowest frequency bands [6].
2.2
Predictive Multiple Description Coding
In a typical video sequence there exists a significant amount of redundancy between one frame and the next. Thus, coding efficiency can be considerably improved by using some form of predictive coding (specifically most video coders use motion compensated temporal prediction). Predictive coding is based on the assumption that the encoder and the decoder are able to maintain the same state, meaning that the frames they use for prediction are identical. However, transmission losses can cause errors in frames at the decoder resulting in a mismatch in states between the encoder and the decoder. This state mismatch can lead to significant error propagation into subsequent frames, even if those frames are correctly received. This section discusses some of the issues predictive MD coding presents since predictive coding is an essential piece of most video coding systems. For an in-depth review of MD video coding see the overview by Wang, Reibman, and Lin [50].
In the strictest sense, each MD stream should be independently decodable and losses in one description should not affect any other descriptions. Given the use of predictive coding, accomplishing this requirement can be somewhat difficult. There are a number of approaches to predictive MD coding; some accomplish this strict independence constraint while others relax or
ignore this constraint to some extent. In [50], the authors partition predictive MD coders into
three useful classes. We use these same classes here since they provide a convenient means of understanding this topic.
Predictors from the first class, Class A, achieve complete independence through the use of less efficient predictors. For instance, the system proposed in [1] uses two independent prediction loops; even frames are predicted from even frames and odd frames are predicted from odd frames. This prevents losses in one description from propagating to other descriptions (e.g. the loss of an even frame will only propagate to future even frames). Another approach is to use a single prediction loop, but only predict from information known to be present in both streams [7].
Each of the approaches from Class A trade off some amount of prediction efficiency in order to maintain independence between each of the descriptions. The second class, Class B, relaxes the independence constraint in favor of using the most efficient predictors possible. In this case each prediction is generated in the same way as a single description coding scheme resulting in greater coding efficiency. However, with this approach, losses in one description can propagate to the remaining descriptions. Some systems using this approach also code the residual error to reduce the effect of mismatch, others do not.
The final class of predictors, Class C, uses some combination of the first two. They trade off some of the efficiency of Class B for the increased resilience of Class A. There will be some amount of mismatch in this type of approach, but presumably less than when using only the most effective predictors (Class B). In addition, predictors from this class are often able to adapt between the two extremes, gaining more error resilience where it is most needed. Some examples of this type of system are [26] and [34]. Depending on the particular modes used, the adaptive MD mode selection proposed in this thesis can use any one of these three approaches. By using an end-to-end rate-distortion optimized framework, the approach proposed in this thesis can most effectively trade off efficiency for resilience to optimize the expected quality at the receiver. The particular implementation described in Chapter 5 is an example of a Class C predictor.
Multiple Description Video Coding
2.3
Applications of Multiple Description Video Coding
Multiple description coding can be useful for a wide range of video streaming applications. This section discusses a few of examples where MD coding can make a significant impact on overall performance.
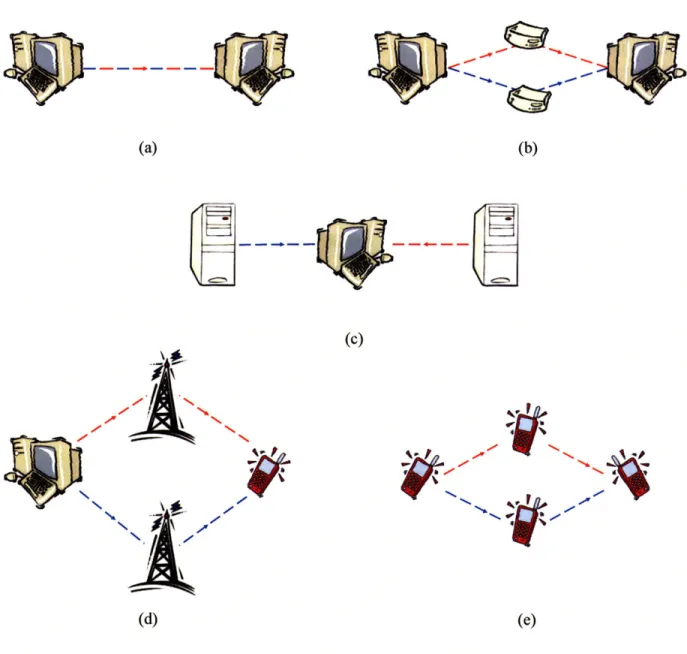
MD coding can certainly be used to improve standard point-to-point video communications over a single path, see Figure 2.5 (a). This approach can not handle a total outage of the single path, yet the susceptibility to packet loss may be reduced relative to single description coding. If packet losses along this path are approximately independent (Bernoulli) then any particular subset of packets sent along the path will also be lost independent of all other subsets. With this in mind, each description is lost or received independently of all other descriptions. However, packet losses are often bursty in nature. To remain effective, the MD coding approach relies on the assumption that it is unlikely that losses will occur on both descriptions. Bursty packet losses along a single transmission path can cause losses in both descriptions which can significantly reduce the effectiveness of the MD approach. Interleaving (reordering the sequence or transmitted packets) is often used to reduce the effect of bursty packet losses. However, the delay constraints of real-time systems limit the extent to which this is possible.
While MD codes can be used to improve transmission over a single path, they are particularly well suited for use with multiple paths, see Figure 2.5 (b) and (c). In this type of approach, each description is sent along an independent path through the network to the receiver. Even if the channel experiences bursty losses along one path, path diversity makes it unlikely that both descriptions will be lost. There are a number of approaches for transmitting over multiple paths. For instance, standard point-to-point transmissions over the Internet can be modified to include multi-path routing, as in Figure 2.5 (b). The sender can explicitly route packets along separate paths by directing them to intermediate routers on their way to the receiver. Another approach is to use a streaming media content delivery network (CDN) to stream complementary descriptions from multiple senders as shown in Figure 2.5 (c) [3, 5]. Even with this type of multiple path approach, it is often difficult to generate completely independent paths through the network. Eventually, the paths are likely to converge resulting in two paths that are partially independent and partially shared. In [4], the authors provide a useful model for evaluating the performance of path diversity and multiple description streaming along partially independent, partially shared paths. They use this model to show the benefits of MD
Chapter 2 Multiple Description Video Coding (a) (b)
rr1,
(c) N Ile 1-0 ~ j 0~~ 4 '9. p *A.~ h ~7 '9., -* N. (d) bE -w (e)Figure 2.5: Applications of multiple description coding. (a) Traditional point-to-point communications. (b) Point-to-point communications using multiple paths. (c) Multiple senders via Content Delivery Networks (CDN). (d) Wireless communication via multiple base stations. (e) Ad-hoc peer-to-peer wireless networks.
Chapter 2 Multiple Description Video Coding
Multiple Description Video Coding
coding in situations ranging from fully independent paths to fully dependent paths. These models also enable one to select the best paths [3, 5].
The use of MD coding also has significant potential in wireless applications. Individual links often fail due to interference from the environment or from other wireless devices. In addition, a single link may not be able to support the necessary bandwidth for video transmission. Thus, transmission using multiple paths in wireless applications is particularly attractive. For instance, packets could be routed through two different base stations on their way to the handheld device as shown in Figure 2.5 (d). If one of the links begins to fail due to interference, multiple description coding can allow graceful degradation in quality, allowing time for the device to initiate communications with a third base station or wait for the interference to clear. The same approach can be used with ad-hoc peer-to-peer wireless devices as shown in Figure 2.5 (e). Individual devices enter and exit the network sporadically due to the movement of each device, interference with other devices, or simply from being turned on/off. The use of MD coding allows the system to be more resilient to this type of dynamic network topology and to maintain reasonable video quality.
Chapter 3
Adaptive MD Mode Selection
Each approach to MD coding trades off some amount of compression efficiency for an increase in error resilience. How efficiently each method achieves this tradeoff depends on the quality of video desired, the current network conditions, and the characteristics of the video itself. Most prior research in MD coding involved the design and analysis of novel MD coding techniques, where a single MD method is applied to the entire sequence. This approach is taken so as to evaluate the performance of each MD method. However, it would be more effective to adaptively select the best MD method based on the situation at hand. Since the encoder in this type of adaptive MD mode selection system has access to the original source, it is possible to analyze the performance of each coding mode and select between MD modes in an R-D optimized manner.
This chapter introduces the concept of adaptive MD mode selection in more detail and presents some of the tools that can be used to achieve it. The first section of this chapter discusses the essential role adaptive mode selection plays in video coding, and the second introduces R-D optimization techniques that can be used to accomplish optimized mode selection. The final section discusses how this thesis has applied these ideas to adaptive MD mode selection.
3.1 Adaptive Mode Selection Systems
Adaptive mode selection (AMS) has played a vital role throughout the history of video coding. Even the earliest video coding standards made use of hybrid inter/intra coding which is fundamentally an AMS approach. This adaptation between inter-coded blocks, which are predicted from previously coded frames, and intra-coded blocks, which are coded independently of any other frames, has been shown to greatly improve video compression efficiency.