A Counting: System Architecture and
Implementation of a Voice Portrait of the United
States
by
Toby Holtzman
B.S. in Electrical Engineering and Computer Science, MIT (2019)
Submitted to the Department of Electrical Engineering and Computer
Science
in partial fulfillment of the requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
September 2020
c
○ Massachusetts Institute of Technology 2020. All rights reserved.
Author . . . .
Department of Electrical Engineering and Computer Science
August 14, 2020
Certified by . . . .
Ekene Ijeoma
Assistant Professor
Thesis Supervisor
Accepted by . . . .
Katrina LaCurts
Chair, Master of Engineering Thesis Committee
A Counting: System Architecture and Implementation of a
Voice Portrait of the United States
by
Toby Holtzman
Submitted to the Department of Electrical Engineering and Computer Science on August 14, 2020, in partial fulfillment of the
requirements for the degree of
Master of Engineering in Electrical Engineering and Computer Science
Abstract
In this thesis, I present the technical architecture of A Counting, a voice portrait of the United States through a nationwide repeating “count” from one to one hundred as a response to historical miscounting by the US Census. Using a novel audio pro-cessing pipeline, voice recordings from participants’ counts are split into individual audio samples. These samples are then recombined into the continuous count that is displayed through a video on a web page. Every iteration of this count is unique, as each number is selected at random from all recordings submitted so far. I also present an architecture for participants to verify and transcribe their own and others’ record-ings, giving them control over the representation of their language, and enabling the artwork to be self-sustaining through voluntary participation. The artwork has been featured in museums and galleries, garnered a community of hundreds of participants, and continues to expand across the United States.
Thesis Supervisor: Ekene Ijeoma Title: Assistant Professor
Contents
1 Introduction 9
1.1 The United States Census . . . 10
1.2 Language . . . 10
1.3 Thesis Structure . . . 11
2 System Architecture 13 2.1 System Overview . . . 13
2.1.1 Data Collection through Phone Lines . . . 13
2.1.2 Media Storage . . . 15
2.1.3 Web Application . . . 15
2.1.4 Web Platform . . . 16
2.1.5 Audio Pipeline . . . 18
2.1.6 Participant Verification and Transcription . . . 18
2.1.7 Video . . . 18 2.1.8 Database Architecture . . . 18 2.2 Concepts . . . 19 2.2.1 Participant . . . 19 2.2.2 Call . . . 19 2.2.3 Recording . . . 19 2.2.4 Number . . . 21 2.2.5 Transcription . . . 21 2.2.6 Language . . . 21 2.2.7 City . . . 22
3 Audio Pipeline 23 3.1 Pipeline Overview . . . 23 3.2 Input . . . 23 3.3 Silence Detection . . . 25 3.4 Noise Reduction . . . 27 3.5 Volume Normalization . . . 28
4 Generating the Video 29 4.1 Language Acknowledgement . . . 29
4.2 Choosing Audio Samples . . . 30
4.3 Artificial Pauses . . . 30
4.4 Videos by Region . . . 31
5 Participant Verification and Transcribing 33 5.1 Errors in the Video . . . 33
5.1.1 Errors in Transcriptions . . . 33
5.1.2 Errors in Audio . . . 35
5.2 Participant Verification and Transcription . . . 35
5.2.1 Verifying and Transcribing a Call . . . 36
5.2.2 Unknown Languages . . . 38 5.2.3 Credits . . . 38 6 Discussion 41 6.1 Evaluation . . . 41 6.2 Future Work . . . 42 A Sample Count 45
List of Figures
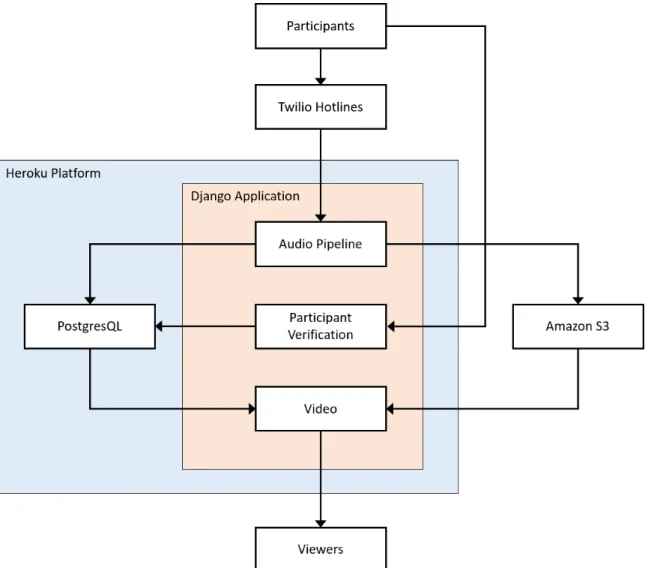
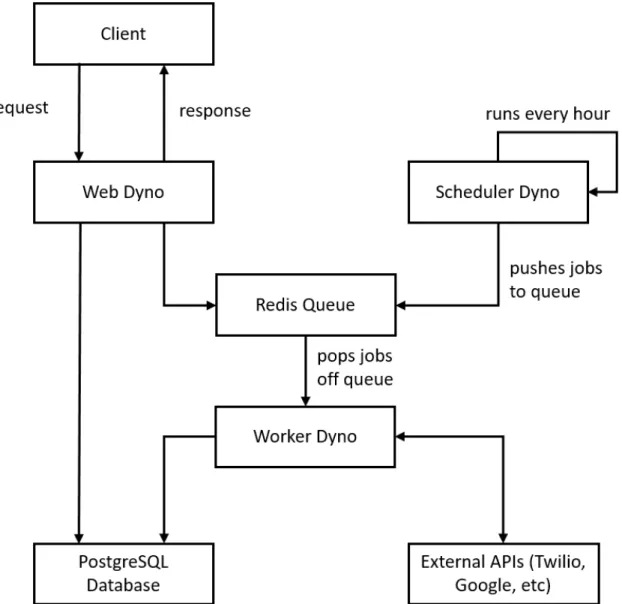
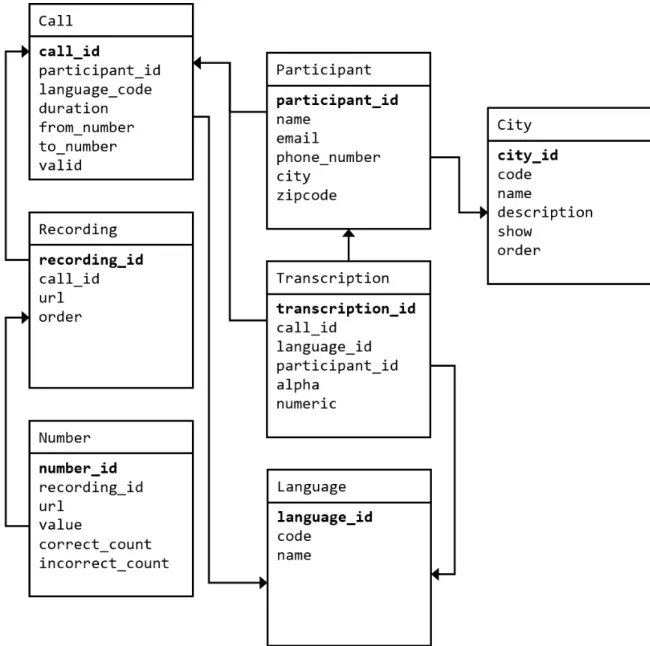
2-1 System architecture overview of A Counting. . . 14 2-2 Server architecture using Heroku dynos. . . 17 2-3 PostgreSQL database schema diagram. Arrows represent a
"many-to-one" relationship in the direction of the arrow. . . 20 2-4 Screenshot of the video while an audio sample for the number 18 in
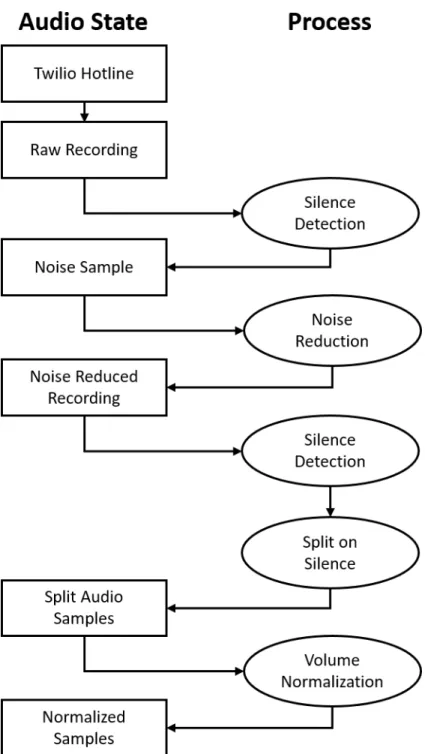
Spanish plays. . . 22 3-1 Audio processing pipeline. Boxes represent chunks of audio and ovals
represent processes and/or algorithms. . . 24 3-2 The silence detection and removal process on the same audio with
differing thresholds. The upper graphs show the input audio, and the lower graphs show the SVM assigned probability that the audio is not silence. Vertical lines mark locations to cut the audio. . . 26 5-1 The transcriber view. . . 37
Chapter 1
Introduction
New York City alone houses native speakers of over six hundred different languages; yet in 2015, the US Census Bureau reported speakers of only three hundred and fifty languages across the entire United States [14, 3]. This thesis presents the technical architecture of A Counting, a voice portrait of the United States through a nationwide repeating “count” from one to one hundred as a response to miscounting by the US Census. Speakers of different languages across the US call in to our hotlines and record themselves counting from one to one hundred in their native language or languages. We then automatically split these recordings into individual numbers, using a novel audio processing pipeline to reduce background noise and split recorded phone audio into individual samples. These samples are then recombined into a continuous count from one to one-hundred. Every iteration of this count is unique, as each number is selected at random from all recordings submitted so far.
In order to ensure the correctness of the audio processing algorithms, this the-sis also presents an architecture for participants to view and edit uploaded record-ings, giving them control over what they submit and allowing the artwork to be self-sustaining through crowd sourced participation.
The final output of the artwork is a generative video that displays the generated counts indefinitely from one to one hundred in different languages alongside text transcriptions of each number. A New York City only version of the artwork is on display as part of the Who We Are exhibit at the Museum of the City of New York.
So far, the nationwide web version has audio from over 800 participants and 100 languages, numbers that are expected to increase as the project grows [7].
1.1
The United States Census
At the time of writing, the US Census Bureau is hosting the 2020 Census. The Census is a gathering of information about the population of the United States, the results of which inform policy, funding and resource allocation, and seats in Congress. However, the information gathered by the US Census has historically been abused to harm those that respond to it [13]. The Census also does not reflect and miscounts the vast diversity present in the US when it comes to language. Speakers of rare and endangered languages are not accounted for: how is it possible that the Census reports 250 fewer languages in the entire United States than the number of languages spoken in just New York City? When the Census does not accurately count languages, how can it be trusted to accurately represent minorities and other groups in the US? A Counting seeks to allow us to reflect and question the Census, give a voice to people who are typically unheard, and show how an accurate census may look.
1.2
Language
It is surprisingly difficult to state precisely what defines a language. At what point are differences in speech different dialects or different languages all together? Are mixtures of two languages, also known as creole languages, different languages then either of their origins? In an extreme case, the languages Catalan and Mallorquín are syntactically and grammatically identical [10]. Yet these two regions will fervently argue that the other does not speak the same language!
In this thesis, I make no attempt to define what language is. Instead, this work is in part an exploration of the concept of language, allowing individual participants to make decisions about how their own language is represented. As such, the approach for dealing with language is bottom-up rather than top-down; participants personally
define the boundaries of what language is and the result is reflected in the artwork. I believe giving this choice to participants will allow viewers to reflect on what language means, both individually and collectively.
1.3
Thesis Structure
The rest of this thesis is structured as follows:
Chapter 2 gives an overview of the system architecture as a whole and explains specific concepts that are relevant to the project. Chapter 3 breaks down the audio pipeline and explains the specific methods used to process and split up recordings from participants in the artwork into individual audio samples. Chapter 4 explains how those individual audio samples are recombined into a generative video, which continuously displays counts from one to one-hundred. Chapter 5 details the meth-ods for verifying correctness and fixing issues with the audio recordings and their transcriptions. Finally, Chapter 6 provides a discussion of the implementation and results of this thesis.
Chapter 2
System Architecture
This thesis posits a robust system for collecting audio from participants, processing that audio, and then enabling participants to verify and transcribe their own and others’ contributions. The core of this system will continue to be used for future projects in the Poetic Justice group.
2.1
System Overview
2.1.1
Data Collection through Phone Lines
Participants call in to several phone lines set up over several US cities. These hotlines are managed through Twilio, a service that provides an online interface and APIs (Application Programming Interfaces) for managing phone and SMS capabilities.
When someone calls one of our Twilio hotlines, they are led through the process of counting from one to one-hundred in their native language. They are asked to first say the name of the language. Then, they are asked to begin counting. The count is split up over four recordings. The participant will first count one through twenty-five, then twenty-six through fifty, and so on until they reach one hundred. After counting, they may leave another recording for any feedback, questions, or any thoughts after going through the experience of counting. Finally, they are asked to enter their zip code, which is used later to create city and location-specific videos.
After they complete the call, we automatically send them a text asking if they would like to be credited for their contribution and how the credit should appear on the website.
Twilio offers the ability to record audio over the phone, which we leveraged to obtain audio recordings, formatted as mp3 files, of participants counting. When a participant calls one of our hotline and counts, the individual recordings from their call are stored on Twilio’s cloud service. In order to access these recordings, our Django application periodically sends requests to Twilio’s API to download any new recordings since the last pull. After the recordings are processed into individual audio samples, the created samples are then uploaded to Amazon S3.
2.1.2
Media Storage
For storing our many audio and other media files, we used Amazon S3, an object store service provided by Amazon as part of AWS (Amazon Web Services). Since this project involves storing large amounts of audio, we used S3 as the storage back-end to keep all of our processed audio. S3 provides a file-system like interface called a bucket. Each file in an S3 bucket can be accessed through a unique url provided by S3. Each audio sample used in the artwork is stored in a folder in our S3 bucket with a unique file name, giving us access to a unique url that can be used by the front-end of the web application (the video) to display the artwork.
2.1.3
Web Application
The code for the web application is written in the Python programming language using the Django framework. Django is a Python framework that comes bundled with many handy features for rapid web development, including an ORM (object relational model), request and response routing functionality, a templating language for front-end display, and several others. Our Django application handles all web requests and responses. It is also responsible for periodically pulling recordings from the Twilio hotlines, running the audio through our processing pipeline, and uploading
the finished samples to Amazon S3. The application is hosted on the Heroku platform.
2.1.4
Web Platform
The web platform hosts the Django web application that manages the main website and processes audio as calls come in live. For A Counting, we used Heroku, an appli-cation platform that provides web server hosting and comes bundled with extensions like databases and queues. Heroku relies on an abstraction called a dyno. A dyno is a Linux container that contains a copy of the application code, and executes based on user-specific commands [8]. Below is an explanation of the responsibilities of each component of the A Counting server architecture in Figure 2-2.
∙ Web dyno. The web dyno handles all requests from web clients and returns the appropriate responses. The web dyno is primarily responsible for serving web pages and hosting API endpoints to deliver necessary data for the front end and internal statistics.
∙ Worker dyno. The worker dyno handles any tasks that are time-intensive. In order to ensure correctness and good user experiences, it is important that the web server returns a response as quickly as responsible. Therefore, we offload as many processing and time-intensive tasks to the worker dyno. Most of the audio processing code and calls to external APIs are done on the worker dyno. ∙ Scheduler dyno. The scheduler dyno runs a fixed set of tasks at the beginning of each hour. Most of these tasks are actually pushed to the Redis queue described below and executed by the worker dyno. Though the scheduler dyno performs several tasks, the primary task is one that downloads and processes any recordings from new calls through requests to the Twilio API and sends the recordings to the audio pipeline in section 2.1.5.
∙ Redis queue. The Redis queue links the worker dyno to the web and scheduler dynos. Individual jobs are pushed onto the queue by the web and scheduler dynos. The worker dyno continually listens for new jobs. When it finds a new
job on the queue, it pops the job off of the queue and executes it. Jobs are executed in the order they are placed on the queue in typical first-in first-out style. However, each job can be assigned one of three priority levels: low, medium, or high. The worker dyno will always execute first jobs with higher priority over jobs with lower priority.
2.1.5
Audio Pipeline
The audio pipeline converts raw recordings into individually sliced samples ready for use in the final video. After processing, the audio files of these samples is stored in Amazon S3, while metadata is stored in the PostgreSQL database discussed in section 2.1.8. I discuss the details of the audio pipeline and specific methods for processing this audio in chapter 3.
2.1.6
Participant Verification and Transcription
Before samples can be added to counts, they must be verified and transcribed by par-ticipants that speak the language of the sample. These parpar-ticipants can be the same ones that made the call, or other individuals that just speak the same language. I dis-cuss the motivations and implementation of participant verification and transcription in greater detail in Chapter 5.
2.1.7
Video
The video combines the processed and verified audio samples into a continuous count. It is the final result of the artwork, meant to be watched and listened to. The video is also hosted on the Django application, and is available online on the A Counting web site. I discuss the video further in Chapter 4.
2.1.8
Database Architecture
Though Amazon S3 can store all of our audio and media files, we still require storage for all referential and meta data about audio samples, calls, and participants. We
used a PostgreSQL database to store this data. PostgreSQL is a state of the art, fast database that comes bundled with the Heroku platform. PostgreSQL is also a relational database, meaning it dovetails well with Django’s built-in ORM. See Figure 2-3 for the database schema and table relationships.
2.2
Concepts
These are some of the important concepts to this system. Each of these concepts has a corresponding table in the PostgreSQL database. Below, I will explain each conceptually, and also some of the most important properties of each. The rest of this thesis may reference these concepts and properties.
2.2.1
Participant
A Participant represents a person who participates in the artwork in some way. People who call in to the hotlines and record languages, people who verify recordings are cor-rect, and people who identify unknown languages are all Participants. A Participant has a phone number or email address as an identifier.
2.2.2
Call
A Call represents a single call and recording session to a hotline. Each call has an associated Participant that made the call, and up to six Recordings generated from Participants’ responses to prompts in the call.
2.2.3
Recording
A Recording represents a single uninterrupted piece of audio recorded during a Call. There are different types of Recordings, since we ask different prompts during the Call. Most Recordings contain Numbers, but some contain the name of the language spoken during the Call or even feedback from the Participant on the experience. Each
Figure 2-3: PostgreSQL database schema diagram. Arrows represent a "many-to-one" relationship in the direction of the arrow.
Recording is linked to the Call from which it was generated, and has a unique Amazon S3 url which links to the full audio of the recording.
2.2.4
Number
A Number represents a particular number spoken by a participant as part of a partic-ular Recording in their native Language. Each Number consists of an audio sample and a numerical value. Each Number is also linked to the Recording that contains it, and has a unique Amazon S3 url which links to the audio file of that Number. Each Number is assigned a default Transcription when it is created, but could have more Participant-added ones later. The audio from Numbers make up the audio portion of the counting video.
2.2.5
Transcription
A Transcription represents the written portion of a Number in a particular Lan-guage. A Transcription is connected to the Participant that created the transcription and the Call that generated the Number associated with this Number. The text of Transcriptions make up the visual portion of the video, as shown in Figure 2-4.
We were able to amass a large database of default Transcriptions from various sources such as Google Translate, Omniglot, and the Endangered Language Alliance [1, 2].
2.2.6
Language
A Language represents a language spoken by an participant in the artwork. There are no restrictions on Languages beyond that each has a unique name. Different dialects will each have their own Language in this system. This ensures we are able to capture the full diversity of languages in the US and that Participants have control over how their Language is represented in the artwork.
Figure 2-4: Screenshot of the video while an audio sample for the number 18 in Spanish plays.
2.2.7
City
A City represents the home city of a Participant that calls into the artwork. We place Participants into Cities through their zip code that they can provide while calling our hotlines. Cities are also used for determining when to use indigenous languages for Language Acknowledgement. See section 4.1 for more details.
Chapter 3
Audio Pipeline
How do we obtain audio samples of individual numbers if we ask participants to record audio all at once? In order to make this happen, the raw audio from the phone recordings goes through an audio processing pipeline before it is ready to be verified and played in the video.
3.1
Pipeline Overview
The audio processing pipeline converts the raw audio from the Twilio phone recordings into cleanly sliced audio samples, with each sample containing clean audio of exactly one number. The pipeline consists of an algorithm to split audio on silence (in order to obtain a sample of silence), a noise reduction algorithm, a parameter sweep over another split on silence in order to actually split the audio, and finally a volume normalization to ensure the audibility of each sample.
3.2
Input
The raw audio is input directly from Twilio voice recordings as mp3 files. Assuming the participant followed the prompts correctly, each recording should contain exactly twenty-five numbers in the participant’s native language. Therefore, each complete call to a hotline results in exactly four recordings so that we have all one hundred
Figure 3-1: Audio processing pipeline. Boxes represent chunks of audio and ovals represent processes and/or algorithms.
numbers. We ask that each participant leave a roughly second-long pause in between each number while recording. This comes in handy when we wish to slice the record-ings into individual numbers; details are described in section 3.3. These recordrecord-ings make up the input to the audio pipeline in Figure 3-1.
3.3
Silence Detection
Since each recording has twenty-five individual numbers separated by roughly one second of silence, we require a way to detect these silences and split the recording into twenty-five individual audio samples at those periods of silence. The easiest way to do this is with a fixed audio threshold. Whenever the volume of the audio is below this threshold, it is considered "silence" and a cut can be made at that point.
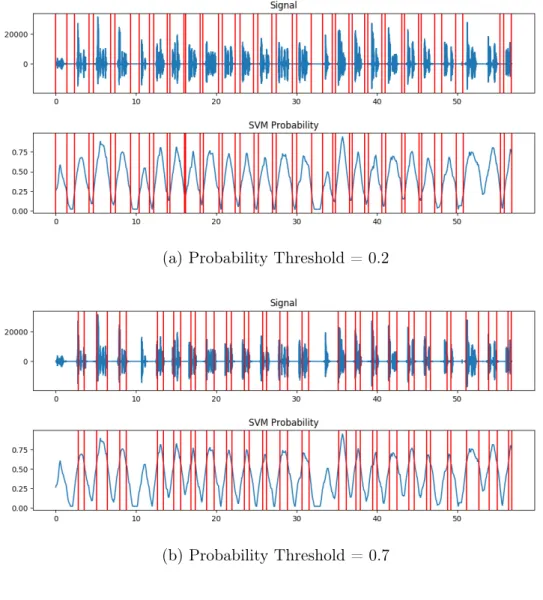
But how can we determine what the threshold should be? Due to unpredictable recording conditions (audio quality, volume, length of silences, and noise levels vary hugely across calls), it is impossible to determine a fixed threshold that will split these recordings correctly across most circumstances. Instead, through the Python library pyAudioAnalysis, we train an SVM (Support Vector Machine) to assign a probability to each point of the sample [15]. Then, we use a fixed threshold on the probability values to determine points of silence. This probability threshold, unlike the audio threshold, is lower bounded by 0 and upper bounded by 1. Whenever the probability that a section of audio is signal dips below the threshold, that section is marked as silence (see Figure 3-2). Using this method allows us to account for inconsistencies in audio input from different recordings and even within a single recording!
This is much better, but we still haven’t answered the previous question: how do we choose what the threshold will be? Figure 3-2 shows that low threshold values will be more "lenient," produce cuts that include more silence, and may miss cuts, while high threshold values will be more "strict," produce cuts with less silence, and may add too many cuts. Any single threshold may be too strict or too lenient and produce outputs with too few or too many samples. However, here we apply a clever solution to this issue. Since we know that there should be exactly twenty-five samples
Figure 3-2: The silence detection and removal process on the same audio with differing thresholds. The upper graphs show the input audio, and the lower graphs show the SVM assigned probability that the audio is not silence. Vertical lines mark locations to cut the audio.
(a) Probability Threshold = 0.2
in every recording, and the threshold value is bounded by 0 and 1, we perform a sweep over possible threshold values in increments of 0.5 to find a "good" threshold - i.e. one that results in exactly twenty-five slices of signal audio. If no threshold value results in exactly twenty-five samples, it is likely there was a mistake in the input or it was corrupted, and we simply use a low threshold value that generally produces good results.
3.4
Noise Reduction
The most common source of error in the silence detection process is noise in au-dio. Noise “fuzzes” the audio waveform, decreasing the certainty of the SVM when assigning a section of audio as high-energy or low-energy. This in turn makes the probability threshold less likely to split the recording cleanly, as noise may cause the probability to spike unexpectedly or cross the threshold prematurely. To improve results of silence detection, we should first reduce the noise of the original recording as much as possible. In addition to the benefits for silence detection, the samples will simply sound more pleasant if noise is reduced.
Noise reduction can be a difficult task, since noise is very different across different environments. To fix this, most noise reduction algorithms require some variety of noise profile of the environment of the sample. We used a spectral gating noise reduction algorithm, which requires two inputs: A noise audio clip, which contains the prototypical noise described above, and a signal audio clip [12]. In our case, the signal clip is the original recording with that has both the counting audio we want to keep and the noise that we want to be reduced.
How can we obtain the noise profile in the first place? Since each call comes in from a different environment, we employ a clever technique to find a workable profile for each call - the silence detection method described in section 3.3. Since we already have an algorithm to split samples based on silence, by definition, we also have an algorithm that splits silence based on samples. By cutting out the silence and removing the signal we can effectively obtain a period of silence that can be used as
the noise profile for the silence reduction algorithm. Therefore, we make two runs of the silence detection algorithm: first, a "rough" pass with a high threshold to cut out the signal and obtain the noise profile, and second, a "smooth" pass with a sweeping threshold after noise reduction to cut out the silence and obtain just the signal.
3.5
Volume Normalization
It is important that all of the samples are listenable and that there is a consistent auditory experience while listening to the artwork. However, after the previous some recordings are at different volume levels due to different circumstances while recording. This creates an effect where some samples are much louder than others, and the final output does not sound consistent or pleasant. To solve this problem, we implemented a volume normalization algorithm that adjusts the peak of each sample to -24 dBFS (decibels per full scale). This means that each audio sample is roughly one-fourth as loud as the maximum possible volume of a .wav file, meaning the final output is at a consistent listenable volume [9]. Also, it is important that this step in the process occurs after the samples have already been split, as volume can vary drastically even within a single call or recording. Volume normalization is the last step in the audio processing pipeline. After it completes, each mp3 file is uploaded individually to Amazon S3 and assigned a unique filename, and a new Number object is created in the database with a link to the audio sample.
Chapter 4
Generating the Video
The video is the final component of the project: the view-able and listenable portion of the artwork. Once the audio is first processed through the audio pipeline, reviewed, and transcribed, it is then added to a generative video that is displayed on request. The video continuously plays audio samples out loud and displays counts from one to one-hundred. Each count consists of exactly one-hundred numbers, and each number has a numerical value and a written transcription. These counts repeat infinitely, generating a completely new set of random samples each time. Assuming each count takes approximately two minutes and thirty seconds, it would take over a week of continuous listening to get through every iteration of numbers in just New York City.
4.1
Language Acknowledgement
Though there are an incredible number of diverse languages spoken in America, some have very few native speakers left. Many of these languages belong to the indigenous peoples of America, and the scarcity of their languages is a direct result of colonialism and oppression of indigenous peoples throughout American history. Since A Counting is a voice portrait of America, it would not be complete without including indigenous voices. As such, we acknowledge in A Counting the languages of indigenous speakers through ensuring that the first number - the “one” of each count - is in an indigenous language for the region if possible. Thanks to The Lenape Center and the Lenape
Talking Dictionary, the New York City version of A Counting features samples in Lenape, an indigenous language to the NYC area [4, 5].
4.2
Choosing Audio Samples
Each audio sample has a duration around the one to four second range. Each count randomly chooses one hundred of these samples to combine into one continuous count. In order for a sample to be chosen for the count, it must have all of the following properties:
∙ Was marked correct by a transcriber. For more information see Chapter 5.
∙ Has an associated transcription. If there are multiple transcriptions, the latest one is used.
∙ Was created by a caller from the video’s region, OR is a number from a language indigenous to the video’s region. For more information on regions see section 4.4.
After the count completes, the server writes the result to a .json file hosted in Amazon S3. For an example count, see Appendix A. Each time a count is requested from the server, the server first sends the last generated count .json file from S3. Then, the server computes a new count and overwrites the count file in S3, so that the subsequent count is unique.
4.3
Artificial Pauses
The initial prototype of the counting video simply concatenated every sample in the count together with a constant delay in between each sample. However, this resulted in an “uncanny valley” effect for very short samples. The issue mainly affected samples with numerical values below ten, as shorter numbers tend to have a longer pause between them while counting. We tend to count with a particular rhythm, and the
shorter the word, the longer we must pause to maintain the rhythm. To fix this, we add an artificial extra pause to short samples, simulating the longer pause humans naturally use while counting. This pause causes the count to sound and rhythmically feel like a real person counting, instead of a rapid-fire listing of numbers. This artificial pause is dynamic - the shorter the word, the longer the inserted pause.
4.4
Videos by Region
Recall that in addition to collecting audio recordings from the hotline, we also ask participants to enter their zip code. This allows us to generate counts that are local-ized to speakers from any arbitrary geographic region, such as cities, states, or even the entire United States.
Since the project began as a New York City specific artwork, we began by using the hotline called to determine location. However, once we expanded to cover the entire United States, we added the ability for participants to enter zip codes, enabling the use of one national hotline that can be split up easily into various regions.
When a participant enters their zip code, their code is matched using a database of geographical information [11]. If their zip code falls within one of the cities partici-pating in the artwork, they will be assigned that city. If a participant’s zip code does not coincide with one of the cities in the artwork, or if a participant places a call but does not enter a zip code, their city is assigned based on the hotline that they called. Then, when the server is generating counts, it can look up the city of a participant to determine which numbers should be used for the count.
Chapter 5
Participant Verification and
Transcribing
5.1
Errors in the Video
As the artwork grew in size, we began to receive reports from native speakers that they had seen errors in the video. Occasionally, transcriptions were not matching audio samples and audio samples were themselves the incorrect number or cut-off. Though these errors were infrequent, they were very jarring for those experiencing the artwork that spoke these languages, and misrepresented their language in an artwork that is supposed to highlight and celebrate underrepresented languages. Clearly, the manual review process by members of the Poetic Justice team was not enough. But why were issues arising in the first place?
5.1.1
Errors in Transcriptions
Since transcriptions make up the visuals of the artwork, it’s especially important that we minimize the number of errors and present every number as accurately as possible. While finding transcriptions for numbers may not sound particularly difficult, there were several factors that increased complexity many-fold:
lan-guages, rarely-spoken languages are not so well documented and internet sources are unreliable or outdated. Online, transcriptions for most languages were only found on one or two sites like Omniglot [1]. These sites, while usually reliable, can have missing information for particular numbers. For example, in many cases, the numbers 1-10 are transcribed, but only every tenth number is tran-scribed for numbers 20-100. In addition, any time a single source of information is used can lead to the possibility of introducing errors.
∙ Methods of counting can change in different dialects in the same language. In fact, some languages have different counting systems even with no dialect changes. For example, we found that roughly half of Korean callers used one number system, and the other half used a different one - with no way to differ-entiate the two without knowing Korean.
∙ Some languages, such as Vietnamese, elide numbers as a kind of shorthand during speech. This would result in numbers that were much shorter than the given transcription. It can be jarring to hear words that don’t match up with text on the screen, even if the written version is grammatically and syntactically correct. We wanted to make sure that what was written down on the screen was what participants had actually spoken, but with so many possible variations within a single language, such a task is very difficult.
One might expect some kind of automatic speech recognition and transcription services and software, such as services offered by Google Cloud Speech-to-Text or the open-sourced software Mozilla Deepspeech to be well suited for transcribing au-dio samples. These solutions were investigated, but unfortunately these services use models that work by training on curated sets of data [6]. These training sets are usually based on a particular language. Therefore, these models would not be able to handle the wide array of foreign and less-spoken languages that are central to A Counting. Additionally, if we already had access to a training set with those lan-guages, we would not need models in the first place.
5.1.2
Errors in Audio
Though the audio processing pipeline normally does extremely well at splitting sam-ples automatically, it can still result in errors if there are issues with the input. The major reasons the audio pipeline could make mistakes are:
∙ If the environment is very noisy, the audio pipeline may struggle to slice the audio correctly - see section 3.3 for more details.
∙ An unexpected sound, such as a door closing or burst of noise, can be treated as a number by the algorithm, resulting in some audio samples being off by one, or an audio sample that is just a burst of noise instead of a number.
∙ If the caller skips a number or adds an extra number, the algorithm will likely not be able to parse the audio correctly, as it attempts to force the output to twenty-five samples.
∙ The caller may also simply say a number incorrectly or make a mistake. This is the most difficult type of error to catch, as no algorithm can check for these types of errors.
5.2
Participant Verification and Transcription
Due to the above factors of complexity and the apparent errors in the video, we realized that we would need speakers of each language included in the count to ensure accurate transcriptions. Though we in Poetic Justice aren’t able to translate and transcribe these languages ourselves since we are not native speakers, we realized that through the participatory nature of this artwork, we already have access to a broad network of foreign language speakers: the participants themselves.
In order to solve the issues in section 5.1, I designed a system for participants to verify their own and others’ calls. These participants include those who called our hotline and want to verify and transcribe their own calls, and those who did not call
but simply want to engage in the artwork and ensure their language is represented accurately.
This system must accurately verify:
1. Correctness of audio. The given audio must match the expected number exactly. In addition, audio samples must not be cut off or inaudible.
2. Correctness of transcription. The text of each transcription must match the audio exactly.
After a participant calls and records a count, they receive a personalized link to their participant dashboard. The participant dashboard gives participants a queue of calls that they can verify and transcribe. If the participant has made one or more calls themselves, they will see their own calls in the queue. After they have transcribed their calls, they are then given the option to transcribe and verify calls of others. We also require that participants only verify and transcribe calls of languages that they speak, so the queue is filtered by language.
5.2.1
Verifying and Transcribing a Call
If the language of a call is known, then when a participant views the call, they will see the transcriber view in Figure 5-1. At this point it is important that the participant actually speaks the language of this call, as they must be able to detect whether or not the audio is correct and which number it refers to. Each audio sample in the call is displayed along with a both a media player to play the audio sample and a text box with the corresponding transcription.
The participant then reviews each sample individually. After reviewing the sam-ple, the participant is able to verify the audio by selecting one of the values in the drop-down list. In most cases, the correct number will already be selected. However, for reasons discussed in section 5.1, it is possible the sample contains the wrong num-ber or has other issues. If there is an error, the participant should select one of the values in the dropdown with an "N/A" and type of error. If the participant selects a
value that is not N/A, then the sample is marked "correct" - otherwise, the sample is marked "incorrect". Then, the participant is able to transcribe the number by simply editing the text box to contain the appropriate text. Again, normally the transcription will already be correct, but sometimes edits will be necessary. Once the call is submitted, the verifications and transcriptions will be attached to the call and utilized when creating the video. Before submitting, the participant must listen to each sample in the video.
5.2.2
Unknown Languages
How do we know what language a participant is counting in? Since the hotline is open for callers of all languages, when a participant places a call to a hotline, we have them leave an additional recording for the name of the language they called. The call is processed as normal, since the audio processing algorithms are language agnostic. The call is given the marking “Unknown” and placed into the “Unknown” grouping of calls, which appear on the home page of A Counting.
When participants or administrators go to transcribe an “Unknown” call, the standard form in section 5.2.1 does not appear. Instead, users see a list of all unknown calls, and next to each is a recording and a text box. Users can listen to the recording, select the correct language, and enter it in the text box. If the language is not already in the system, an email will be sent to the Poetic Justice group to add the new language. After the language is selected, the call is associated with the selected language and will enter the transcription queue of that language. In this way, even identifying languages becomes a participatory activity.
5.2.3
Credits
Since A Counting is a participatory artwork that aims to promote unheard voices, we decided that participants should be credited for their contributions to the artwork. Participants may provide their name to us through texting our hotlines or on the A Counting website. Once they call or transcribe, their name will appear on the
appropriate credits section on the home page of A Counting. Participants are free to use any moniker; for example, "Maria L. Smith," "Mari," and "A Latina Woman" are all valid names. If a participant does not provide their name to us, we use the default name "Anonymous." Additionally, we show credits at the end of each count with the names of the callers whose samples were used during that count.
Chapter 6
Discussion
6.1
Evaluation
As of time of writing, over eight hundred participants have engaged with the artwork by calling in to our national hotlines or helping transcribe others’ calls. We have received over one thousand calls and over ten thousand participant-submitted tran-scriptions across roughly one hundred languages. Though we have not yet gathered more languages than the Census records, some of the languages given a voice in A Counting are ones not accounted for on the Census. Thanks to the methods presented in this thesis, the video is free from jarring errors and provides a consistent and en-gaging counting experience. The artwork has been featured in museums, galleries, news articles,is available online on the A Counting website, and continues to welcome new participants and their languages.
We can evaluate A Counting holistically through the "say anything" recordings left by participants after counting and calling into our hotlines. Some of these messages were focused on the mechanical process of counting in the participant’s language, as several languages have unique numbering systems or counting quirks. These were very interesting, as there are both broad similarities across completely unrelated languages and stark contrasts between closely related languages. Many recordings provided feedback on things the hotline could do better, or apologies for making a mistake while counting. These were valuable pieces of information that we used to
improve our systems and make counting more accessible. The largest and most sur-prising category where those that simply thanked us for the experience of counting. Several participants told us that counting in their native language was an unexpect-edly emotional experience. Though the US has many diverse peoples and languages, some people don’t have opportunities to speak their language as everything tends towards English.
We also did not expect the growth of a community of participants who transcribed the calls of others but did not call themselves. At the beginning of the project, we did not anticipate any issues with transcriptions, and it was only after finding errors in the audio that we implemented the ability for participants to transcribe audio themselves. Though unplanned, this resulted in the genesis of a community of transcribers that may have not been involved in the project at all otherwise. Many people that may not have been comfortable or able to call in to our hotlines were still able to engage with the artwork and affect the representation of their native language through transcribing. The unexpected forming of this community allows us to reflect on the driving force behind this work. Why does the US Census not result in such communities forming, and how can the process of counting in the United States change so that we can come together and account for everyone in our communities?
6.2
Future Work
Going forward with A Counting, there are certainly ways to improve and goals to reach for. One current goal is continued outreach to find more speakers of rare and endangered languages that can contribute to the artwork. We also wish to highlight these voices even more by weighting samples by the inverse of their rarity, so that rarer languages are more likely to be chosen in the count. Finally, A Counting is currently limited to the US, and outreach is specifically targeted towards cities and areas with high diversity. Ideally, the artwork will continue to expand and allow participants from anywhere the US and eventually globally to transform into a voice portrait of the world.
Beyond A Counting, the core of this project will be used for new participatory and generative work from the Poetic Justice Group. The group is currently working on a new artwork that expands on the audio collection and participatory verification and transcription methods described in this thesis to manifest a national and global dialogue of what freedom means. Though we were limited to counting and numbers in A Counting, there are no restrictions on what kinds of ideas and messages can be communicated in the future; the concept of phone lines as interactive artwork is yet unexplored. The architecture in this thesis provides a platform through which ideas and dialogues can manifest asynchronously throughout the United States and world in a novel way, and I look forward to seeing what is to come.
Appendix A
Sample Count
{ numbers: [ { language: "Lenape", numeric: 1, alpha: "kwëti", url: "https://poetic-justice-a-counting.s3.amazonaws.com/medi a/REc314c1efb2917bf552dedb55a7cd2521_001.mp3",name: "Nora Thompson Dean" }, { language: "English", numeric: 2, alpha: "two", url: "https://poetic-justice-a-counting.s3.amazonaws.com/medi a/RE8a2627a031de76677f5badec8b839c88_002.mp3", name: "Anonymous" }, { language: "Romanian",
numeric: 3, alpha: "trei",
url: "https://poetic-justice-a-counting.s3.amazonaws.com/medi a/REe121fd57a008194ee6e12d1a023f9cf3_003.mp3",
name: "Elena Radu" }, { language: "Croatian", numeric: 4, alpha: "četiri", url: "https://poetic-justice-a-counting.s3.amazonaws.com/medi a/REea76b8857fd1c70cbc36111404faf0f1_004.mp3", name: "Peter" }, { language: "English", numeric: 5, alpha: "five", url: "https://poetic-justice-a-counting.s3.amazonaws.com/medi a/RE4e1bae2f9ed4caf186f81ea741a53059_005.mp3",
name: "Joeseph Smith" }
] }
Bibliography
[1] Simon Ager. the online encyclopedia of writing systems and languages. url: https://omniglot.com/.
[2] Endangered Language Alliance. Languages. url: https://elalliance.org/ languages/.
[3] US Census Bureau. Census Bureau Reports at Least 350 Languages Spoken in U.S. Homes. Nov. 2015. url: https://www.census.gov/newsroom/press-releases/2015/cb15-185.html.
[4] The Lenape Center. url: https://thelenapecenter.com/.
[5] The Lenape Talking Dictionary. Welcome to the Lenape Talking Dictionary. url: http://www.talk-lenape.org/.
[6] Google. Speech-to-Text basics | Cloud Speech-to-Text Documentation. url: https: //cloud.google.com/speech-to-text/docs/basics.
[7] Poetic Justice Group. A Counting: A voice portrait of the US. url: https: //www.a-counting.us/.
[8] Heroku. Heroku Dynos. url: https://www.heroku.com/dynos.
[9] Federal Agencies Digitization Guidelines Initiative. Term: Decibels relative to full scale. url: http://www.digitizationguidelines.gov/term.php?term= decibelsrelativetofullscale.
[10] MajorcanVillas. United We Speak: Catalan or Mallorquín? url: https://www. majorcanvillas.com/blog/united-we-speak-catalan-or-mallorquin. [11] Sean Pianka. Zipcodes. url: https://github.com/seanpianka/zipcodes.
[12] Tim Sainburg. Noise reduction using spectral gating in python. url: https : //github.com/timsainb/noisereduce/.
[13] Los Angeles Times. Uses and Misuses of Census Bureau Data. Apr. 1990. url: https : / / www . latimes . com / archives / la xpm 1990 04 06 fi 820 -story.html.
[14] Mark Turin. New York, a graveyard for languages. Dec. 2012. url: http:// www.bbc.com/news/magazine-20716344.