Estimating the execution context for refining submission strategies on production grids
23
0
0
Texte intégral
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
Figure

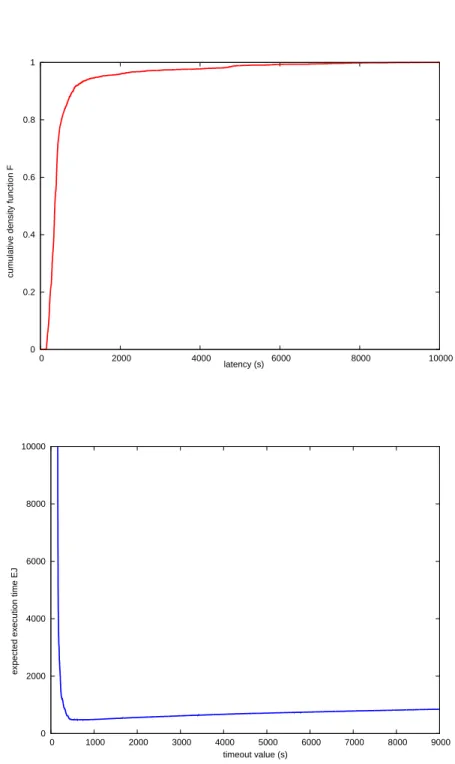

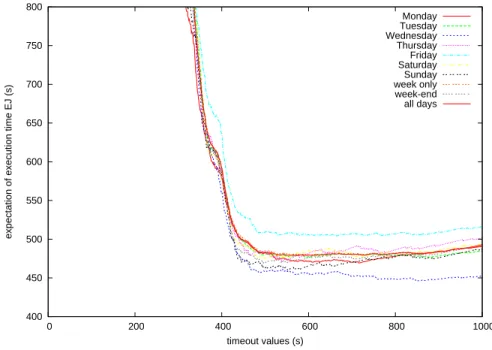
+7
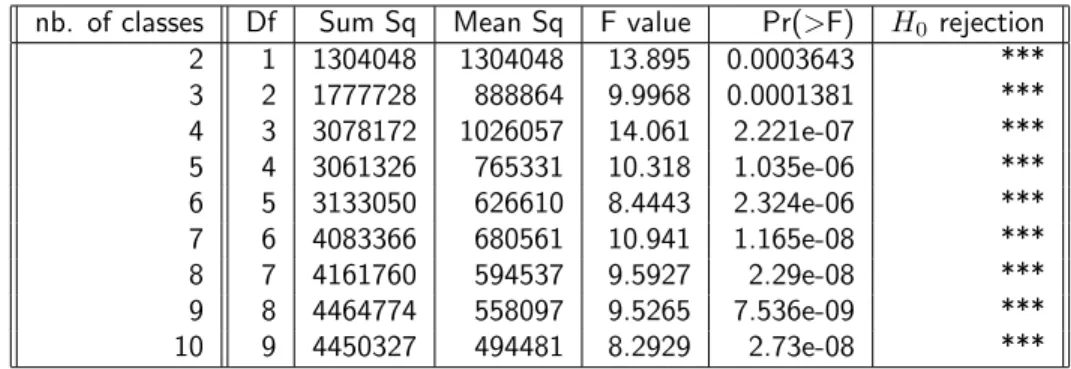
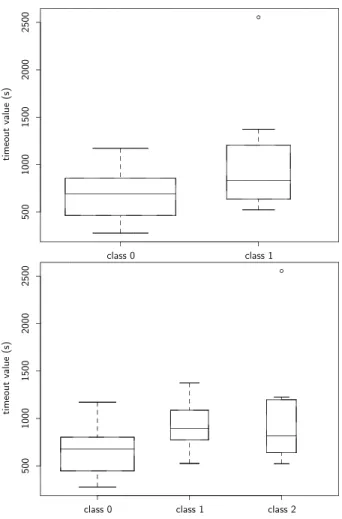


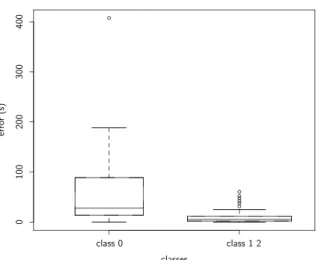
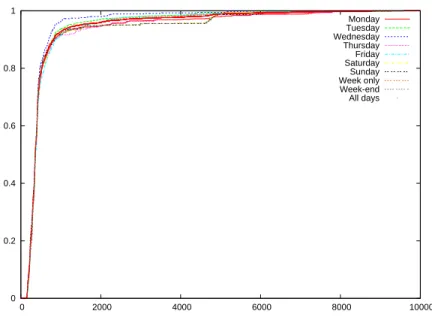
Documents relatifs
The requirements to the method of compiling the project execution plan for the multi-agent model are formalized and an overview of applied tasks of work planning in multi-agent
It is plain that we are not only acquaintcd with the complex " Self-acquainted-with-A," but we also know the proposition "I am acquainted with A." Now here the
(b) Certain criteria are related to semantic anomalies detection in the PLM (for example, the no existence of dead features in the PLM, a dead feature is a feature that can never
We will show in the subsection 3.3 that the possible permutations at a given level l (taking into account all the ways of attributing l black points to cluster.. configurations) are
neuroimaging studies of subliminal priming suggest that processing of stimuli made subjectively invisible by masking is extensive and can include visual recognition, but also
Grid data management is complemented with local storage used as a failover in case of file transfer errors.. Between November 2010 and April 2011 the platform was used by 10 users
The problem of rewriting a global query into queries on the data sources is one relevant problem in integration systems [23], and several approaches have been defined to
There were 35 measurements out of a total of 8738 1-Hz 2D-S measurements that contained ice particles ≥100 µm, and the maximum infocus particle size observed is 165 µm.. The
