Fast Liveness Checking for SSA-Form Programs
10
0
0
Texte intégral
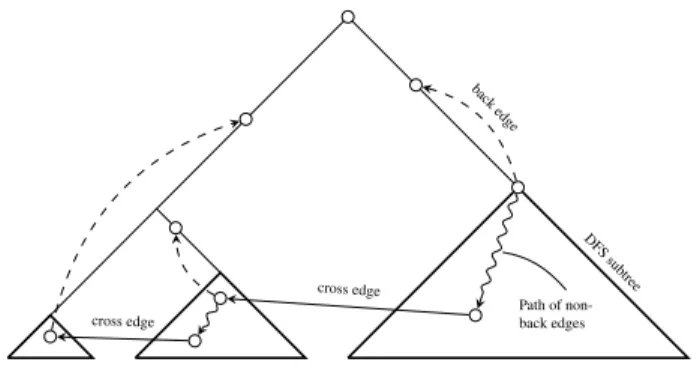
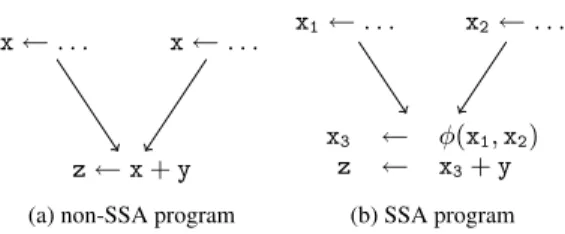
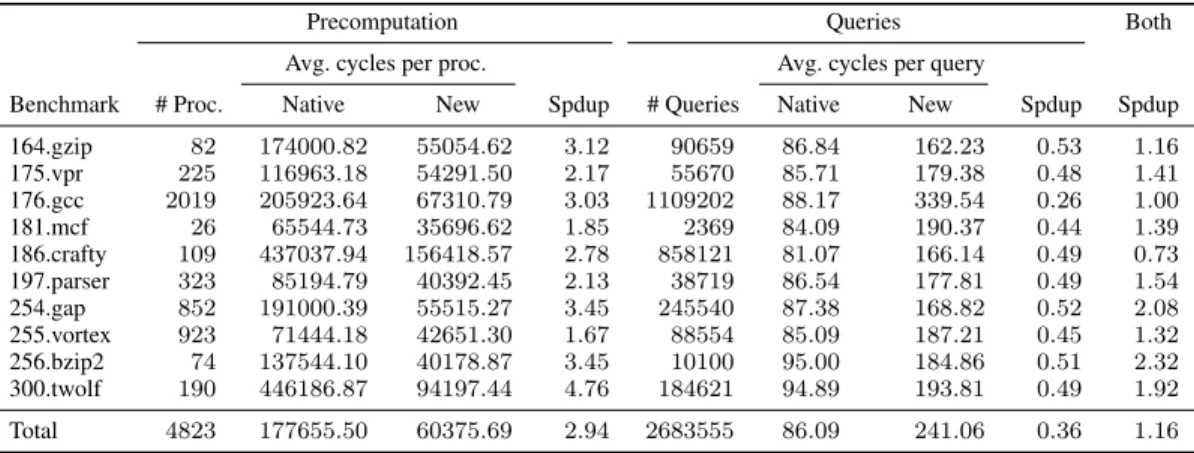
Figure

Documents relatifs