A Bayesian Bandit Approach to Personalized
Online Coupon Recommendations
by Xiang Song
Bachelor of Engineering, Civil Engineering Zhejiang University (2011)
Master of Science, Transportation Massachusetts Institute of Technology (201 3)
Submitted to the Sloan School of Management in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN MANAGEMENT RESEARCH
at the
MASSACHUSETTS INSTITUTE OF TECHNOLOGY
Fe bruary 2016
C 2016 Massachusetts Institute of Technology. All rights reserved.
Signature of Author
...
Signature redacted
C ertified by ... Accepted by
...
S ig natu re
MASSACHUSE INSTITUTE OF TEC* LOGYJAN 2
6
2016
LIBRARIES
Sloan School of Management January 5, 2016
Signature redacted
John D. C. Little Institute Professor Professor of Marketing Thesis SupervisorI rUdULtU
Catherine Tucker Sloan Distinguished Professor of Management Science Professor of Marketing Chair, MIT Sloan PhD Program ... .. .. ... . ... . . ...A Bayesian Bandit Approach to Personalized
Online Coupon Recommendations
byXiang Song
Submitted to the Sloan School of Management
on January 5, 2016, in partial fulfillment of the requirements for the degree of
Master of Science in Management Research
Abstract
A digital coupon distributing firm selects coupons from its coupon pool and posts them online for its customers to activate them. Its objective is to maximize the total number of clicks that activate the coupons by sequential arriving customers.
This paper resolves this problem by using a multi-armed bandit approach to balance the exploration (learning customers' preference for coupons) with exploitation (maximizing short term activation clicks). The proposed approach is evaluated with synthetic data. Results showed a 60% click lift compared to the benchmark approach.
Thesis Supervisor: John D. C. Little
Acknowledgement
During the past two and half years, I have been very fortunate to have received help and
support from numerous people.
First, I would like to express my greatest gratitude towards my thesis advisor John Little. It would not be possible without his great mentorship, knowledge, patience and insights. From meeting with him many times, I not only improved my thesis but also learnt tremendously in conducting research which will benefit me in long term.
I would like to thank Per Jensen, vice president of analytics and insights from a digital distributing firm. His knowledge and support greatly facilitated and inspired the thesis.
I would also like to thank all other faculty members who provide various forms of guidance and support. John Hauser introduced me various latest technical methods applied in marketing including multi-armed bandit problems and inspired me various research directions. Juanjuan Zhang was always available for guidance and discussion in many ways, and first introduced me the field of marketing before I applied to the program. Duncan Simester provided not only research assistantship in the first summer but also taught me on causal inference and various research topics including word of mouth. I also benefited from Joshua Ackerman, Sinan Aral, Itai Ashlagi, Dean Eckles, Drazen Prelec, Catherine Tucker, and Birger Wernerfelt in various ways. I am also greatly indebted to Moshe Ben-Akiva who led me to demand modeling and exploring important research topics in many fields including transportation and marketing.
I would also thank peer students Aliaa, Artem, James, Jeff, Jeremy, Jim my, John, Nell, Sachin, Shan, Shuyi, Song, Xinyu, Xitong, Yixin, and many students outside Sloan including He. Lingling, Peter, Yang, and Yicheng.
My special thanks to my family and especially my girlfriend, Xiaoyu Zhang, for all their love and support throughout these years.
Contents
Chapter 1 Introduction ...
9
1.1 Background ... 9
1.2 Problem Description ... 9
1 .3 O u tlin e ... 14
Chapter 2 Rank Order and Probability of Consideration...15
2.1 Introduction of Consideration and Activation Structure ... 15
2.2 Probability of Consideration Model... 15
2 .2 .1 Fu ll M o d e l ... 15
2.2.2 Simplified Model ... 16
2.3 M odel Estimation...17
C hapter
3
M odel...
20
3.1 Reward Functions...20
3.2 Customer Type in Activation... 22
3.2.1 Customer Type ... 22
3.2.2 Customer Type Estimation... 23
C hapter 4 M ethod...
25
4.1 Review of M ulti-armed Bandit Approach ... 25
4.2 Bayes-UCB Procedure ... 25
4.3 Parameter Updates...26
C hapter 5 Evaluation...
27
5 .1 P o licie s ... 2 7 5.2 Synth etic User ... 27
5 .3 O u tco m e s ... 28
C hapter 6 D iscussion ...
30
6 .1 S u m m a ry ... 30
6 .2 Exte n sio n s ... 3 1
A ppendix A
-
N otations ...
33
A ppendix B
-
H euristic Finding O ptim al Index ...
36
Chapter 1 Introduction
1.1 Background
Coupons are one of the most important promotional tools in the grocery retailing industry. They help manufacturers to compete for price-sensitive consumers.
According to the 2014 Coupon Trends Report by Inmar [1], some 329 billion coupons for
Consumer Packaged Goods (CPGs) - including paper coupons and digital coupons - were
distributed in the U.S. in 2013. The preferred method of distributing by marketers - and the most popular method for redemption by consumers - is still Free-standing Inserts (FSIs). FSIs take up 89 percent of all the distributed coupons in 2013, and represented 41 percent of all the redeemed coupons. Forty nine percent of shoppers regularly use FSI coupons. In terms of redemptions, more than one billion of the 2.9 billion coupons redeemed in 2013 are FSIs.
Another major method is the digital coupon. Digital coupons may be described as Big Data. They can help marketers enhance personalized targeting. The use of digital coupons continues to grow faster than the number of overall coupons. In addition, their share of redemptions is also growing fast. One kind of digital coupons is load-to-card coupons. Consumers call load their grocery discounts to their shopper loyalty accounts from the retailers' or publishers' websites. There is no paper involved with these offers. The discounts will be credited to the shoppers' bank accounts after the shoppers present their loyalty cards for scanning at checkout in
supermarkets. According to Inmar [I], there are more than 66 million digital coupons redeemed industry-wide, which is a 141 percent increase over 2012.
1.2 Problem Description
The problem in our study comes from a digital coupon distributing firm. It has the following problem. The firm could select from a pool of N coupons to post on its website for each individual customer. It wants to maximize the total activation clicks across all customers. Activation is a step in the coupon redemption procedure.
There is a group of registered customers who registered their store loyalty card on the website. These customers will visit the website and look for coupons they like. When they find what they want, they click on the coupons and activate them. After they activate the coupon, the coupon
information will be associated with their loyalty card (or loaded to their card). Then they need to go to the supermarkets or grocery stores to purchase the couponed products. In order to get
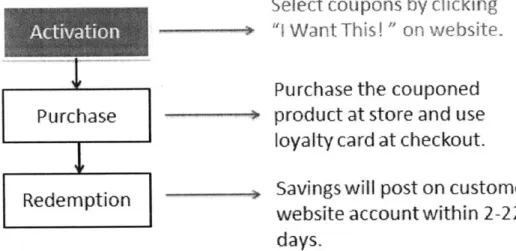
redeemed, they have to scan their loyalty cards at checkout. After a few days, the coupons get redeemed and the savings will be posted in their bank accounts. Figure 1.1 illustrates the procedure of L2C coupon redemption.
Figure 1.1 Procedure of Coupon Redemption
Purchase
Redemption
Select coupons
by
clicking
"I Want This! " on website.
Purchase the couponed
product at store and use
loyalty card at checkout.
Savings will post on customer
website
account within 2-22
days.
Figure 1.2 shows a coupon which is typical on the firm's website. It has face value ($1), product name (Chex cereals), and expiration date (10/31/2015). Customer who clicks on the button "I
Want This!" (the button in the right-bottom corner) will activate the coupon and this behavior is captured by the firm.
Figure 1.2 A Coupon on the Firm's Website
heR yo % a
-T fz OE
con~~I iwig
The number of display slots (K) on the firm's website is limited. But the number of coupons in the pool is larger than the number of slots (N>K). For example, we have 6 coupons in the pool and 4 slots on the website. See Figures 1.3 (a) and (b).
Figure 1.3 (a) Coupons in Pool
Coupon 1 Coupon2 Coupon 3 Coupon 4 Coupon 5
:
Coupon 6 1.3 (b) Slots on Website Slot 1 Slot 2 Slot 3 Slot 4Obviously, the customer is more likely to consider a coupon in a slot with a smaller number. The firm could allocate these six coupons to four slots differently, which may result to different activation responses from customers. Figures 1.4 (a) and (b) shows two different allocations.
1ocoupon 2 Copn
Coupon 4
~
)Coupon6 LFigure 1.4 (b) Allocation 2
Coupon 2 Coupon 1
In general, the firm would have about 50-100 coupons and 30 slots. As the number (N and K) goes larger, such combinatorial optimization becomes harder.
There will be T customers arriving sequentially to activate the coupons. In the following chapters, we will make the implicit assumption that customer t+1 comes after customer t has made her activations.
For the firm, since it controls the allocation, it can decide allocations to maximize the total number of activation clicks. There would be two types of policies. One policy is the Fixed Policy that they could fix the presentation order of the coupons for all the customers. As a result of that, every customer sees the same set of coupons. Alternatively, the firm could personalize the allocation offered to customers because customers have heterogeneous coupon preferences. This is the Personalized Policy.
Basically, the firm needs to know the customers' probability of activating coupons in the pool of N coupons. However, it is a hard problem for the fin to predict these probabilities.
First, the coupon activation behaviors by customers are rare compared with purchases made without coupons.
In addition, if we assume that the customers' preference for product purchase is linear with their preference for coupon activation, we will have more data to estimate the probability of activation. However, given that assumption, we will have a high dimensional choice data analysis. For such analysis, there are many problems with computation and modeling [2]. For example, the choice model works well in low dimension may not work in high dimension; data may be quite sparse
in high dimension.
Finally, many coupons are for new products. So we don't have any historical data for estimation at all.
Let us define the total number of activations by a specific customer Linder a specific allocation as the reward. Since the probability of activation is uncertain, the reward is also uncertain. We have
to learn the uncertain reward by testing different allocation to customers.
Traditionally, we could use AB testing to evaluate the performance of different allocations. However, it's too costly since the number of allocations and the number of arriving customers would be large.
The failure of AB testing is because it cannot solve the trade-off of exploration and exploitation. We have to solve the trade-off of exploration and exploitation. Exploration means learning the uncertain rewards but it might be costly since it may result to poor short-term rewards.
Exploitation means obtaining good short-term rewards and not learning the uncertain rewards which may be potentially high.
To resolve this trade-off, we could frame this problem as a multi-armed bandit problem [3.4.5].
In addition, since different slots have different slot-specific advantages, we break down the decision making process of coupon activation into two sequential components, which will be illustrated in the next chapter.
1.3 Outline
In the first chapter, we introduced the background of the current coupon industry and innovation and growth of digital coupons. Then we introduced the coupon presentation order allocation
problem we would solve in this paper.
In Chapter 2, we break down the activation by customer into consideration and activation. We also introduce and estimate the probability of consideration, which will be essential in the model.
In Chapter 3, we formulate this sequential decision making problem as an optimization problem. In addition, we reduce the dimensionality of the problem by using historical purchase data.
In Chapter 4, we solve the model through a multi-armed bandit approach. The approach or algorithm will iteratively decide which allocation to show to different customers and update the value of unknown parameters in the model.
In Chapter 5, we use synthetic users to evaluate the performance of our algorithm. By comparing different policies, we conclude our algorithm is good compared to clairvoyant's policies.
Chapter 2 Rank Order and Probability of Consideration
2.1 Introduction of Consideration and Activation Structure
In this chapter, we will introduce the structure of consideration and activation by introducing the probability of consideration, its model and estimation.
As introduced in Chapter 1, we know that the firm could allocate coupon to different slots. We assume that the customers are more likely to consider the coupons on the top than those in the bottom. Given this assumption, the position or rank order of the coupon plays an important role in the probability that coupon is activated. To include such phenomenon. we introduce the probability of consideration.
For example, for a given individual customer,
Probability (coupon "chex cereal" in slot 4 will be activated)= Probability (slot 4 is considered
by customer) * Probability (coupon "chex cereal" will be activated slot 4 is considered by
customer).
We term the probability of customer considering slot as probability of consideration and it is rank-specific (or slot-specific). Regarding the customer behavior of activating a coupon, the customer has to first make cognitive effort to consider the coupon before she really activates it. If no such effort has been made, activation is not possible. Given consideration, the probability of customer activating the coupon will depend on customer preference for the coupon, her
inventory of the couponed product, and some other customer-specific characteristics. We will talk about them in the following chapter.
Next we will give a model of probability of activation. Since we have historical data of coupon activation and their corresponding rank orders, we Will use these data to calibrate the proposed model.
2.2 Probability of Consideration Model
2.2.1 Full Model
Let w(k) be the probability of consideration of slot k. In next chapter, we will use JTk instead. We assume it decays exponentially with its rank order.
m(k) = w(1) * e-a(k-1), k = 1. K (2.1)
Currently, we just assume 7r(1) = 1, therefore,
wT(k) = e~A(k-1), k - 1, ... ,K (2.2) We call the unknown parameter A as rank decay parameter.
There are three characteristics determining the number of activations of a given Coupon including the quality of the coupon, number of coupons on top of it, and number of days that coupon has been offered.
Let n(j, t) be the number of activations of couponj at time t, which will be a function of quality, position and time. Let's assume it also decays by number of days. We have
n(j, t) = iT(p(j, t)) * q(j) * exp(-pt) (2.3)
where
p(j, t) is the position of coupon
j
at time t.p(j, 0) is the original position of coupon
j
at introduction.q(j) denotes the quality of couponj and is fixed and unobservable.
exp(-t) Is tIe decay term' over time wit positive parameter i. p is called time decay
parameter which is unknown.
Let n (j) be the number of activations of coupon j, which is sum of n(j, t) over horizon T (one month).
T
n(j) = n(j, t) (2.4)
t=1
2.2.2 Simplified Model
We do not have historic data of n(j, t). We only know n(j) and p(j, t). Given the property of exponential model, we could simplify the model.
T T / n(j) = n(p(j, t), t) =Y n(p(j, 1), 1) exp -A d(t')
-t=1
t=1
t
)=] T T T = n(p(j, 1), 1)p(t) = n(p(j, 1), 1) p(t) = q(j) * 7r(p(j, 1)) Y p(t) t=1 t=1 t=1 = Q(j) exp(-A(pj, 1) - 1)) (2.5)Where d(t') denote the number of coupons introduced at time t', and Q(j) = q(j) ET=1 p(t)
If we assume that all the coupons have the same quality, we have
n(k) = 7z(1) * n(k) = n(1) * e -(k- 1), k = 1,..., K (2.6) We will use historical data to estimate unknown parameter A through model (2.6).
2.3 Model Estimation
We have many different sequences of n(k) with different begin dates. Given the property of exponential model, we focus on one big manufacturer who offers dozens of coupons at the
beginning of the month. Since these coupons are offered by the same big manufacturer, the assumption of same quality is likely a good approximate to reality.
Transforming the model by logarithm, we have
in = -A(k - 1), k = 1,.. K (2.7)
\nf(1)/
We estimate a single A from all the different sequences of n(k)/n(1) with different begin dates. We have
X= 0.022
The mean square error (MSE) of n(k)/n(1) is 0.125. For some months, it fits quite well. For example, the following table shows the estimated and real n(k)/n(1). Its MSE is 0.033.
Table 2. 1 Estimated and real n(k)/n(1)
1.058379 0.97797 0.006466 3 0.897176 0.956426 0.003511 4 0.872901 0.935357 0.003901 5 0.952678 0.914751 0.001438 6 0.621406 0.894599 0.074635 7 1.068802 0.874892 0.037601 8 1.003676 0.855618 0.021921 9 0.936 0.836769 0.009847 10 0.314727 0.818336 0.253622 11 0.92352 0.800308 0.015181 12 0.833719 0.782678 0.002605 13 0.931833 0.765436 0.027688 14 0.716377 0.748574 0.001037 15 0.293513 0.732083 0.192344 16 0.710255 0.715955 3.25E-O5 17 0.688416 0.700183 0.000138 18 0.579757 0.684758 0.011025 19 0.710255 0.669674 0.001647
20 0.67223 0.654921 0.0003
We will use X = 0.022 in the following chapters for probability of consideration.
Then we fixed the rank decay parameter X and plug it into the equation (2.5) to estimate the latent qualities of individual coupons and the time decay parameter p. We first estimate the latent qualities of individual coupons. After plugging the latent qualities, we estimate [t = 1.5122
through nonlinear least square estimation.
The following table shows the decay by time of offered days. We noticed that after four days, the number of activation on each day only accounts for a very small portion of the total number of activation.
Days 1 2 3 4
Chapter 3 Model
3.1 Reward Functions
We consider the total number of activations by customer t E {1,2, ... , T} as the reward for the
firm. The coupon pool has N coupons in total and each coupon is indexed n E
f
1,2, ... , NJ. There are K slots on the website and each slot is indexed by k c {1,2, ... , K}.Since we select K coupons from N total and allocate them to K slots, we have N! allocations (N-K)!
in total. Each allocation is an arm. Let C E = {1,2, . N!
}
be the index of arms. Each arm (N-K)!index denotes a different K-length vector, i.e., which coupon is allocated as which slot. Let It C j denotes the index of arm selected for customer t by the firm. We also use the index of arm as a K length vector of coupon indices later. So Itk = n means in arm (or allocation) It the coupon n is
placed at slot k.
Write this structure in equation. We have
Y1,k . Ck 1,k (3.1) Where Ck O= w01 W - 7"k and atj tO W.P.Ztltk
0,w.P. 1 - 71k f 0,w WP. 1 - Zt~~
Pr(yt, - 1) - 7TkZtk (.2)
ytJ kis the binary random variable that the coupon in slot k is activated by customer t under
allocation It.
Ck is the binary random variable that the slot k is considered by customer t. wT is the probability
that the slot k is considered by customer t, which we will call the probability of consideration afterwards. Since we assume that all the customers have the same probability distribution of consideration, we omit the subscript t in these two notations.
at "t is the binary random variable that the coupon in slot k under allocation It is activated given the slot k is considered by customer t. zt, is the corresponding probability that a equals to
1, which we will call the probability of activation afterwards. Let zt, be the probability that
We assume that the firm knows H since it doesn't change with coupon placed in it and i > Tuj
when i < j which means the customer will more likely consider the slot in the top.
Let
H
= (rl, T2, --- , EK) E RKand Zt,
(zt,,,'Zt,I, -- ,zt,tK)' E RKLet
Zt= (Ztl, ..., Zt,N)' E ,NFor each customer t, the firm has to decide which arm to select. In the model formulation, we assume that the customer t would have made activation decisions before the next customer t+1 comes, which will simplify the description of the algorithm.
Let yt,lt be the number of coupon activations by customer t under allocation It.
K K
ytit YtItk , (3.3) k=1 k=1
The expected reward by customer t tinder allocation It.
-K K - K K
E[yt,t] = E
[i
YtJtk EI
ckarJtk E[I
WkZtltk = E[ H'Zt,lt] (3.4)-k=1 -k=1 -k=1
The expectation is taken over all the randomization.
The objective of the firm is to select optimal It for every customer t which will maximize the total expected reward over horizon.
T T
max
YE[ytIt]
=max
E[fl'Zti] (3.5)It,1sts5T It1:5t:5TI
t=1 t=1
The regret is defined as the aggregate expected gap between the reward achieved by a
clairvoyant who knows which arm is optimal for each customer t and the reward achieved by our proposed allocations over horizon.
Let RT denote the expected aggregate regret over horizon T. We have,
T T
RT =
E[y
- ytIt] = E [max Fl'Zt, -'Zt,
(3.6)
t=1 t=1
Since the first term in the regret maxjEj H'Ztj will be a constant term, minimizing the regret is equivalent with maximizing the reward.
Therefore, we could rewrite the problem as
7.
min RT = min E [max 'Zt,. - D'Zt, (3.7)
It,1:5t<T It,1:5t:T Ljej
t=1
Many near optimal solutions to multi-armed bandit such as UCB (upper confidence bound) are developed from minimizing the regret function, which we will review in the next chapter.
3.2 Customer Type in Activation
3.2.1 Customer Type
For product n, let C,, denote the product c'ategorv of product n. Assumptions: the customer
preferencesfor category C, belong to Mc.,, types. For simplicity. we use n as C
Let ot,mn denote the probability of customer t's for category C,, belong to type m,,
{1, 2n, ... , Mnj. Let st,n be the type of customer t for category CII. Then stn = m, denote that
the type of the customer t for category C, is mn,,.
Pr(st,n = n,,1<) = #Ptj,, (3.8) Mn
1 =1 (3.9)
Assumption 1: Customer preference/b;- product purchase is linear with preelrencejfbr coupon
activation.
Assumption 2: within each type inn, the customer's probability of purchasing product n is the
samne.
Let Ot denote the probability that a type n,, customer activates the coupon n C {1,2, ... , N}. Let d',1 denote the binary random variable that the type mn, customer activates the coupon n.
Zt,n = 1 t,mnO/if (3.11)
Mn
at,n = Ptmd 1 (3.12)
m,=1
Assumption 3: We fixed the total number of types across coupons, Mn = M, = M.
3.2.2 Customer Type Estimation
I will show how I estimate customer type for customers under specific product category using historical purchase data. Assume that there are only two brands of cereals, Kellogg and Chex.
We assume that the customers do not consider the difference between the brands. They only have brand preference. We are using historical purchase counts in different brands to summarize such brand preference information in customer type.
In further extension, we could incorporate other information from historical data such as their consumption rate, inventory and stock-out cost. A more detailed discussion is in the final chapter.
Let's say, we have product purchase history counts such as
Customer I. C(K) = 31, C(C) = 21;
Customer 2. C(K) = 18, C(C) = 41;
C(K) = 31 means that the customer I has purchase Kellogg cereal for 31 times. In this simple example, we ignore the heterogeneity of cereal size and varieties other than brand.
If
we set customer types to be three, then type I customer is indifferent between K and C, type 2 customer prefers K, type 3 customer prefers C.Using a soft clustering method, we have following type membership probability (#tmn)
1. C(K)= 31,C(C)= 21;
011 = 72%, (1,2 = 22%, 013 =6%
2. C(K)= 18, C(C) = 41;
P2,1 = 30%. (2,2 = 4%, (2,3 = 66%
Introduction of customer type is an important simplification. By introducing customer types, we
Chapter 4 Method
4.1 Review of Multi-armed Bandit Approach
The basic multi-armed bandit is the independent bandit problem. For such problem, the rewards are assumed to be random and distributed independently according to a probability distribution that is specific to each arm - See [6, 7, 8, 9] for reference. Gittins index is designed for such classic problem and has been applied in marketing [3, 4].
Recently, many researchers are paying attention to structural bandit problems in which the distributions of rewards associated with each arm are linked to a common unknown vector [10, 11, 12, 13, 14, 15]. Such model is suitable for problems where the number of arms is large and
payoffs are interrelated. Given our problem description, our problem could be solved as a structural bandit problem. One method called Bayes-UCB is good for us to use here due to the generality of Bayesian approach [16].
4.2 Bayes-UCB Procedure
We describe the algorithm below. Let Ytj be the predictive distribution for the reward by customer t under arm j, which could be computed offline. Let Q (a,T) be the quantile function such that P (X Q(a, r)) = a.
K K M
Y Ckat~ = 7Tkt ( m|n) (4.-1)
=1 k=1 m=1
Then we compute an index for each arm such that
qj(t) = Q (1 - -, Yt,j (4.2)
The arm is selected by the maximum index.
It = arg max qj (t) (4.3) jEj
Since
IJ
is very large, we use a sorting heuristic to find the maximum index. Please see the appendix.4.3 Parameter Updates
Assumption: brand purchase type is same as coupon activation type. Since the firm has rich brand purchase history, we can estimate each customer's activation type Pt,,i, in advance.
Assume that the 00, (the prior distribution before customer I comes) follows beta distribution.
6 ~Beta(ain,, fo) (4.4)
We assume a non-informative prior such that an=
i
= 1.I) If t,k = n, which means the coupon n has been chosen and Pr(at,, = 1Ian-1, f-t, (P n)
Pi-(at,,, ~ ~
( -1
n,1 )7)O _(.5a
Pr(atn =
jyt,
1 = 0) 1 - (4.5a)(1 - ) + (1 -)
Pr(at~n =
1yt
11 =0) =(4.5b)
Pr(at, = 1ytn = 1) = 1 (4.5c)
Pr(at = Olyt n = 1) = 0 (4.5d) For 6 E f0,11, and a, = S
Ot I,
atl-1 1 ,in a at n~-Beta(at t, j, (4.6)Otat7 1,f- -Beta(at-f + 5,1t-1 + (1 - 5))4) ,,, Beta(at,
)
(4.7)According to literature [3], we can approximate the above function as ac4 = a~- +tn * S (4.8a)
f#t = fiti + t, ,I * (1 - 6) (4.8b)
2) For i 0 It. which means the coupon has not been chosen. OL I ac-,
fi;~'~Beta.(at,
fit) (4.9)at, = rT1 (4.10a)
Chapter 5 Evaluation
5.1 Policies
One problem is to find meaningful way to evaluate our policy. We will try to evaluate the performance of our policy through comparisons.
Assume there is a clairvoyant who knows the true distribution of Omn. We let clairvoyant choose what allocation is the best for each individual, which is the optimal recommendation that the firm could offer. In addition, we let clairvoyant choose an optimal fixed allocation for all the
customers, which is the best choice for the firm if they don't do personalized recommendation.
We listed these policies below.
1. Fixed Order (Clairvoyant): an optimal fixed allocation of coupons offered to all the customers. Each customer sees the coupons in the same order.
2. Personalized Order (Clairvoyant): the optimal personalized allocations of coupons offered for each customer. Each customer may see the coupons in a different order.
3. Our Policy: a personalized order policy we developed to resolve the trade-off of
exploration and exploitation.
5.2 Synthetic User
We simulated customers' activation clicks under T=1000, K=5. N=10. We set M=15 for all the coupons. We will plot two ratios of accumulative rewards:
1. our policy vs. fixed order by clairvoyant 2. our policy vs. personalized order by clairvoyant
Since individual customer's reward may be quite different from each other, absolute value may fluctuate a lot simply due to the taste heterogeneity. Some customers are good and some are not. Accumulative ratio would illustrate the performance of our algorithm more clearly in the graphs.
5.3 Outcomes
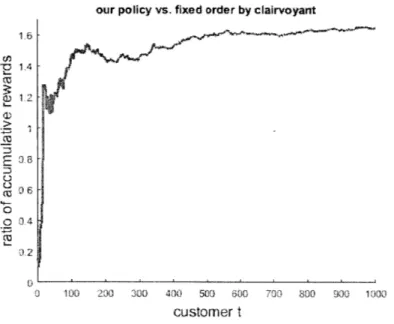
The following two figures show the comparisons between these policies. The figure 5.1 shows
the performance between our policy and fixed order policy by clairvoyant. The figure 5.2 shows the performance between our policy and personalized order policy by clairvoyant.
Figure 5.1 Our Policy vs. Fixed Order
our policy vs. fixed order by clairvoyant
02
'x 1. 4
I LID 20 3 00 4110 50G CiOk0 7131 4900 cKa 1,003
customer t
In figure 5.1 and figYUre 5.2, the horizontal axis means the sequential arriving customer. T'he proposed algorithm is learning more information througrh more Customers' responses. Therefore. the performance (in terms of ratio of aCCUMUlative rewards) shown in vertical axis is being improved with the nUmber of arriving customers increasing.
1I1 fig)Ure 5. 1, we see the performance of proposed algorithmr inc reases sharply to around 1.3 in first few dozens of custorners. Then in the next several hundreds of customers, the performance
Continues to improve slowly. After about 600
customners'
arrival, the performance reachesplateaui. It shows that Our fixed policy im-proves the reward of best fixed order by clairvoyant by
60% when the performance reaches plateaul.
Similarly, we Could identify the trend in figuire 2 about our policy vs. personalized order policy.
1 -our policy vs. personalized order by clairvoyant 0.9 -o E O' U 0.6 o0.4 S 100 206 300 4 W 51-V 6W0 7f 800 9C00W 0 custorner t
In figJUre 5.2, the performance of proposed algorithm reaches about 60% in first few customners. Then until 600
customers'
arrival, the performance continues toimprove
and we still see tinyimprovements after then. From figure 5.2, we notice that our personalized policy reaches 80% rewards of best personalized order by clairvoyant.
Chapter 6 Discussion
6.1 Summary
Proposing most appropriate web-based content at the best time for individual customers is an important and challenging problem. In many cases, designing such web-based content could be thought of as a resource allocation problem associated with rank order and consideration by content consumers.
For example. a daily newspaper has to decide dozens of news articles displayed on its first page of the website and it has to decide which article to display and in what order they are displayed; an online travel agency may have five available advertisement slots for a hotel and want to know what allocation will maximize the total click-through; when you search certain product at an online retailer, it always wants to show you all the available products in an order of propensity to purchase.
In all these examples, the firm (content provider) will have to decide how to allocate items to slots on the webpage which are displayed to customers. In most cases, these allocations would be personalized or targeted to certain groups of customers. The number of slots is usually fixed and items are usually fixed during a period. The number of visitors will be much larger than the number of items. The benefits or rewards for the firm could be counted based on clicks. However, different slots may have different advantages to be clicked due to the browsing behavior and cognitive capacity constraints of customers. Such advantages are not related with items allocated in slot. In other words, there are different probabilities of considering item in specific slot. We term this as probability of consideration (of the slot).
The chapter 2 in this paper explores the relationship between probability of consideration and slot rank using historical data. As discussed above, it is an important direction with lots of real world application. We hope to extend it in the future.
Besides the rank order and consideration problem, this problem is challenging since the
customers' responses such as clicks on the items are not easily predicted. More specifically, the uncertainty may be because the items are new or the historical behavior of the customers is limited. Therefore, we don't have enough information to predict the potential rewards of different allocations.
Traditionally, methods such as A/B testing are popular to solve this type of the problem.
However, the number of different allocation is a permutation number based on number of items and slots. Hence it is too costly for the firm to use these traditional method to test the
effectiveness (or reward) of different allocation designs.
Sequential allocation problem can also be formulated as multi-anned bandit problem (MAB). In MAB formulation, each arm can be thought of as each different allocation. Solving MAB requires the algorithm to balance the exploration and exploitation. The exploration means trying allocations for information gathering purpose; the exploitation means trying the current best allocation to obtain more rewards.
In sum, we proposed a personalized online coupon recommendation approach to resolve the firm's problem. Given the problem description, we formulate the model with structure of consideration and activation. The model of rank-specific probability of consideration is developed and estimated from historical data.
Given the challenge of exploration and exploitation trade-off, we developed a modified Bayes bandit approach based on existing method called Bayes-UCB. In addition, we successfully reduce the size of unknown parameters from T x N to M x N by introducing the customer latent types learnt from historical purchase count data.
Finally, we evaluate our policy with two policies played by clairvoyant by simulating responses from synthetic customers. Our proposed policy achieved 80% of the personalized order policy and obtained 160% of fixed order policy. The evaluation shows that implementing our policy will greatly improve the revenue performance of the firm we studied.
6.2 Extensions
In Chapter 3, we summarize the customers' preference by static customer purchase counts in different brands. However, we know that the probability that customers purchase certain
products not only depends on the static product preference but also depends on the risk of stock-out and her perception of stock-stock-out. More specifically, the inventory level and consumption rate of grocery products of customers will impact on her purchase and activation decisions. For example, if one have lots of paper tissues in stock, no matter how loyal she is with the promoted
brand, it's unlikely that she would buy it and stock these extra products in her home. Modeling such decision making process involves estimating customers' inventory level and consumption
rate from historical data, modeling stock-out risk and costs, and estimating customers' stock cost.
In addition, in the previous evaluation, we only tried small number of slots and coupons. When these number increase, the multi-armed bandit approach may not be able to learn the true
parameter distribution so fast. Therefore, we need to enhance the learning speed. One way to
enhance learning performance is to add a sparsity-inducing prior for the matrix
{04
1N. The
idea of introducing such prior is based on the assumption that customer would greatly prefer a few brands to many others. By intuition and observation of the data, it is definitely the case. Therefore, applying such prior may be a good way to improve the performance of current method.
Appendix A
-
Notations
k= index for couponK=total number of coupons
A = rank decay parameter
Tk = the probability of consideration of coupon in slot i. n(j, t) = the number of activations of coupon j at time t
p(j, t) = the position of coupon j at time t.
p(j, 0) = the original position of coupon j at introduction. q(j) = the quality of coupon j and is fixed and unobservable. p = time decay parameter.
n(j) the number of activations of coUponj
T
Q)=
q(j) p(t)t=1
t= index for arriving customer
T=total number of customers
j=
index of armJ= set of arm indices (J = {1,2, ... , K!}).
H = (r,r 2, --- ,rK)I E RK
It=
the index of selected arm at time t.'t,k= the coupon in slot k under allocation It
H1 = the vector of probabilities of consideration for the selected arm at time t.
yt=k the binary random variable that the coupon in slot k is activated by customer t under allocation It.
at,ltk = the binary random variable that the coupon in slot k under allocation It is activated given the slot k is considered by customer t.
Ztk = the corresponding probability that aLItk equals to 1.
z n = the probability that coupon n will be activated by customer t.
=tt (Zt,lt,1' Zt,It,2' '' ZItlK)' E
Re
Zt= (zt, zt, ... , ZtN)'
E
RN
YO, = the number of coupon activations by customer t under allocation It.
RT= expected
cumulated
regret until time T.Cn = the product category of product n.
Mc,= types associated with product category C.
Mn = Mcn for simplicity
=the probability of customer 's for category C, belong to type m
M,= a type belong to M,.
ot = vector of all 't, across different types.
st,.= customer 's type for product category C,.
o. = the probability that a type m, customer activates the coupon n1.
dlt1 = the binary random variable that the type
mn,
customer activates the coupon n.M= total number of types fixed for any category.
C(K) = historical purchase count in Kellogg cereal.
C(C) = historical purchase count in Chex cereal.
Q(a, T)= the quantile function such that PW(X ; Q(a, T)) = a
qj(t)= index for j-th arm at time t.
00= prior for ,,,n.
a,4 = ,0I = 1 in prior Beta distribution.
at,
fl= Beta parameters after updating from t-th customer's response.
S= realized value of random variable at,..
Appendix B
-
Heuristic Finding Optimal Index
In this appendix, I will introduce the heuristic I used to find the optimal index. Basically I am using the selection sort heuristic and finding the optimal order in terms of best UCB-Bayes index.
1. Start with an initial order of coupons. 2. Loop i froml to N
3. Loop j from i+I to N
4. Compute temp be the product of probability of consideration times corresponding probability of activation given consideration.
5. Compare if coupon i is better than the coupons behind it; if not, then swap the better one with the current coupon in position i.
6. Continue Loopj and continue loop i.
The heuristic does not guarantee to find the optimal index. The reason is because
M=i Vp r transformation may not be an increasing transformation. If the customer types are not introduced, then we just need to find the best order of probability of activation given consideration. A sorting heuristic is then guaranteed to find the optimal order.
Bibliography
[1] Inmar 2014 Coupon Trends Report (2014). Retrieved December 27, 2015, from http://go.inmar.com/rs/inrnar/images/Irnar_2014 CouponTrends_Report.pdf
[2] Naik, Prasad, et al. "Challenges and opportunities in high-dimensional choice data analyses." Marketing Letters 19.3-4 (2008): 201-213.
[3] Hauser, John R., et al. "Website morphing." Marketing Science 28.2 (2009): 202-223. [4] Schwartz, Eric M., Eric T. Brad low, Peter S. Fader (2013), "Customer Acquisition via Display Advertising Using Multi-Armed Bandit Experiments," working paper.
[5] Li, Lihong, et al. "A contextual-bandit approach to personalized news article
recommendation." Proceedings o/fthe 19th international conference on World w ide reh. ACM,
2010.
[6] T.L. Lai and H. Robbins. Asymptotically efficient adaptive allocation rules. Advances in
Applied Mathematics, 6(1 ):4-22, 1985.
[7] P. Auer, N. Cesa-Bianchi, and P. Fischer. Finite-time analysis of the multiarmed bandit problem. Machine Learning, 47(2):235-256, 2002.
[8] N. Cesa-Bianchi and G. Lugosi. Prediction, learning, and gaines. Cambridge Univ Pr, 2006. [9] J. Audibert, R. Munos, and Cs. Szepesv'ari. Tuning bandit algorithms in stochastic
environments.
Lecture Notes in Computer Science, 4754:150, 2007.
[10] C.C. Wang, S.R. Kulkarni, and H.V. Poor. Bandit problems with side observations. IEEE
Transaclions on A utomatic Control, 50(3 ):33 8-355, 2005.
[lI I J. Langford and T. Zhang. The epoch-greedy algorithm for multi-armed bandits with side
information. Advances in N'eural In/ormation Processing Svstems, pages 817-824, 2008.
[12] S. Pandey, D. Chakrabarti, and D. Agarwal. Multi-armed bandit problems with dependent
arms. International Conference on
Machine
learning, pages 72 1-728, 2007.[13] V. Dani, T.P. Hayes, and S.M. Kakade. Stochastic linear optimization under bandit feedback.
Conftrence on Learning Theory, 2008.
[14] S.M. Kakade, S. Shalev-Shwartz, and A. Tewari. Efficient bandit algorithms for online
multiclass prediction. In Proceedings ofthe 25th International Confierence on Machine
[ 15] Filippi, Sarah, et al. "Parametric bandits: The generalized linear case."Advances i Neural
Inuformation Processing Sy'stemns. 20 10.
[16] Kaufmann, Emilie, Olivier Capp6, and Aurelien Garivier. "On Bayesian upper confidence bounds for bandit problems." Internaional Couftrence on Airli/icial Intelligence and Statistics.