Planification d'expériences numériques en phase exploratoire pour la simulation des phénomènes complexes
289
0
0
Texte intégral
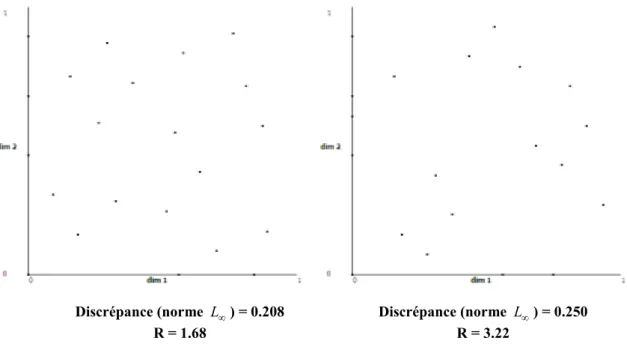
Figure
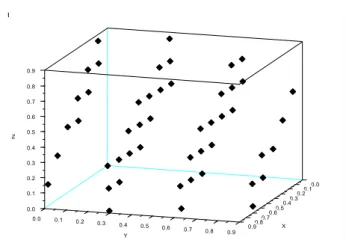
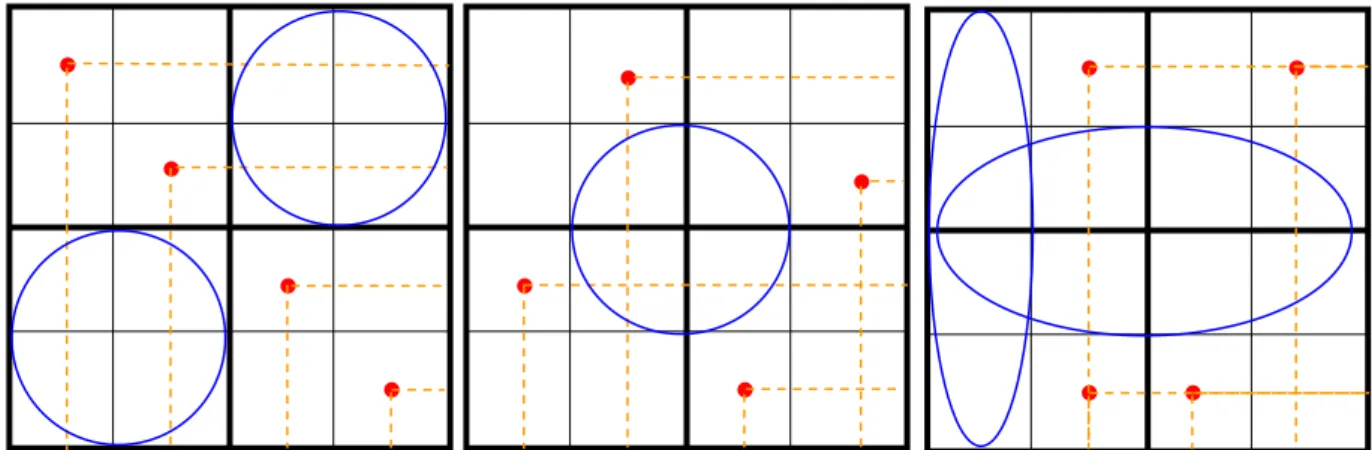
+7





Documents relatifs