Evaluation of a context-aware voice interface for Ambient Assisted Living: qualitative user study vs. quantitative system evaluation
Texte intégral
Figure
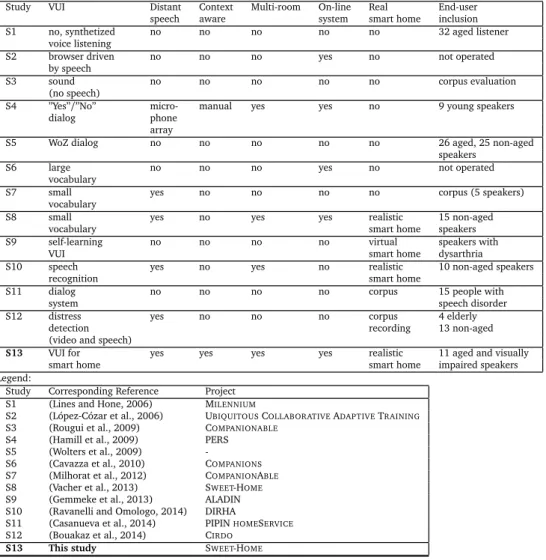
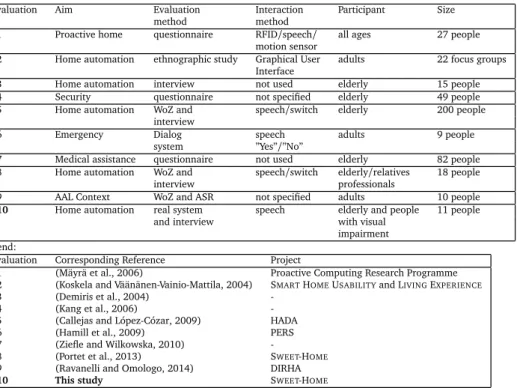
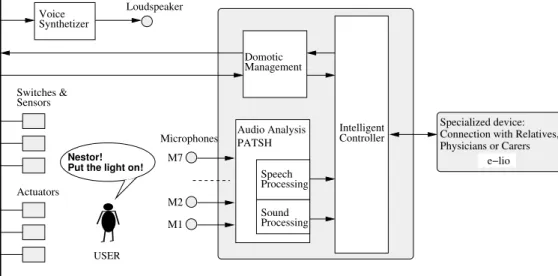
![Figure 2: The PATSH architecture [ Vacher et al., 2013 ] . On the top, the different modules of the process pipeline](https://thumb-eu.123doks.com/thumbv2/123doknet/14484509.524759/14.637.28.617.43.215/figure-patsh-architecture-vacher-different-modules-process-pipeline.webp)



Documents relatifs
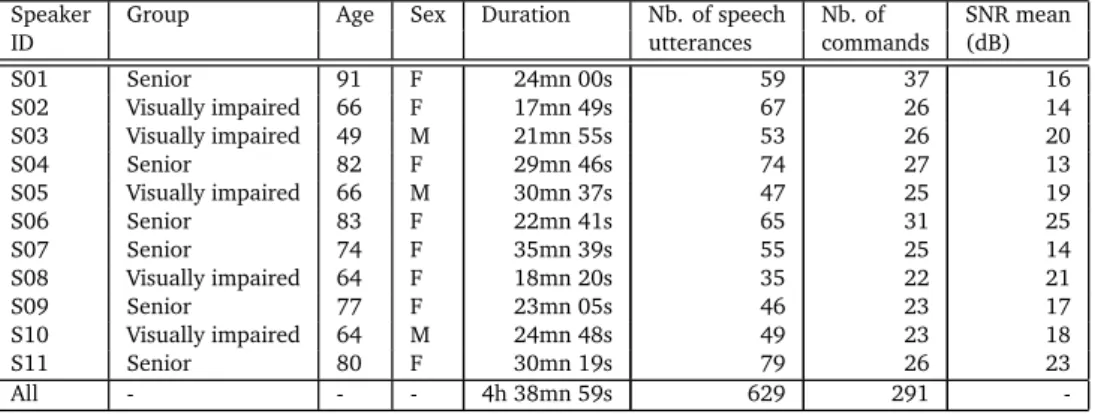
The considerable increase of dependent people brings out important needs of monitoring to ensure a safe and secure independent living and adapted services to compensate for
F0MeanGlobalWord Mean of the F0 value in the current utterance F0VarianceGlobalWord Variance of the F 0 value in the current utterance Mean jitter Mean value of the jitter in
Dans ce développement, on propose de combiner la correction de (Jin et al 2015), liées au taux de défaillance non détecté par le proof test , avec les équations de la norme CEI 61508
Whether o r not the free hydroxyl groups are the centre of adsorption on siliceous surfaces has been the subject of considerable controversy.. In their
Despite this phenotypic overlap with previ- ous models in postnatal growth, a detailed analysis of paternal, maternal and homozygous Pw1 mutant females showed that all aspects
Most diarization systems rely on statistical models to address four sub-tasks: speech activity de- tection (SAD), speaker change detection (SCD), speech turn clustering,
We shall also give an algebraic characterization of the modal logic notion of normal- ity as maps that preserve finite suprema.. We then give a complete characterization and
/ La version de cette publication peut être l’une des suivantes : la version prépublication de l’auteur, la version acceptée du manuscrit ou la version de l’éditeur. Access
