HAL Id: hal-02448972
https://hal.archives-ouvertes.fr/hal-02448972
Submitted on 22 Jan 2020HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come from
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de
Extraction et typage de termes significatifs pour la
description de textes
Nicolas Hernandez, Brigitte Grau
To cite this version:
Nicolas Hernandez, Brigitte Grau. Extraction et typage de termes significatifs pour la description de textes. Actes de la conférence ISKO, 2003, Grenoble, France. �hal-02448972�
Extraction et typage de termes significatifs
pour la description de textes
Nicolas Hernandez1 et Brigitte Grau2 1 Doctorant en Informatique Linguistique
Laboratoire de recherche LIMSI/CNRS – Groupe LIR Université de Paris-Sud
Courriel : [email protected]
2 Maître de Conférences à l'Institut d'Informatique d'Entreprise (IIE - CNAM)
Laboratoire de recherche LIMSI/CNRS – Groupe LIR
Courriel : [email protected]
____________________________________________________________________ Résumé :
Notre but applicatif est de faciliter l’accès au contenu d’un texte. Nous nous situons dans une approche de résumé dynamique s’adaptant aux besoins d’un utilisateur. Á cette fin, nous dégageons des termes significatifs descripteurs des thèmes et de la fonction argumentative d’énoncés. Les techniques d’extraction de ces différents descripteurs s’inspirent de méthodes statistiques que l’on combine avec des heuristiques linguistiques. Les premiers sont identifiés par rapport à leur pertinence dans un document donné, et les suivants en regard du corpus étudié, ici scientifique. Une attention particulière est portée sur cette seconde technique, qui nous permet notamment de construire automatiquement un dictionnaire de concepts et de relations du domaine.
Mots-clés :
Extraction et typage de termes, acquisition de marqueurs rhétoriques, analyse thématique, résumé dynamique.
____________________________________________________________________ Abstract :
We present a dynamic summarization method that combines text segmentation and topical and rhetorical text description to rapidly skim through texts. The speed reading is made thanks to presentation to the user of relevant expressions from text, labelled with topical and rhetorical specification. Both descriptors extraction are inspired from statistical methods that we combine with linguitistic heuristics. The first are identifyed according to their relevance in a given document, and the latter in regards of the corpus, here scientific and technical. In particular, thanks to this technique, we can automatically acquire terminological resources from domain dependant without specific knowledge requirement.
Keywords :
Term extraction and categorization, rhetorical markers acquisition, topic analysis, dynamic summarization.
1. Introduction
La recherche d’information vise non seulement à automatiser la recherche de documents, mais aussi à prendre l’utilisateur en compte afin de lui faciliter la tâche quand il a un besoin d’information. Il est alors pertinent de fournir des clés de lecture avec les documents retournés afin de permettre une prise de connaissance rapide des contenus. Cependant, les documents électroniques suivent souvent une présentation analogue aux documents papiers et conduisent à un parcours de lecture linéaire. Aussi, quand la sélection d’un seul passage serait une réponse trop restrictive, donner une description des différents passages, ainsi qu’une idée de leurs relations dans le document entier permet à l’utilisateur de gagner beaucoup de temps dans l’évaluation de la pertinence des documents et de se focaliser rapidement sur ce qui l’intéresse. Ce constat nous a conduit à travailler sur la visualisation de texte et la navigation intra-document. Notre approche se situe dans la lignée des travaux réalisés par [Minel, 2003 ; Saggion et al., 2000 ] en résumé automatique.
Figure 1. Vue d’ensemble du système
Afin de mettre en évidence les caractéristiques descriptives d’un texte, nous avons travaillé sur son analyse thématique permettant sa décomposition en segments thématiques et sur leurs caractérisations. La segmentation est fondée sur une approche à la [Hearst, 1997]. Un passage est résumé à la fois par le thème global auquel il se rattache et par le thème qu’il traite localement. La description de ces unités est faite en extrayant les termes représentatifs du texte et des segments. Un descripteur thématique correspond à un syntagme nominal sélectionné selon sa pertinence locale et globale [Boguraev et al., 1997].Notre apport se situe dans le typage des termes vis-à-vis de la structure thématique du texte. Par ailleurs, nous essayerons de caractériser aussi le rôle de chaque segment par des méta-descripteurs argumentatifs [Ben Hazez et al., 2001 ; Saggion et al., 2000]. Nous proposons une méthode pour extraire ces termes automatiquement en fonction de critères de fréquence et de répartition sur l’ensemble du corpus. Ce type d’approche s’applique bien sur des articles scientifiques et ne requiert pas de ressources spécifiques. La figure 1 décrit une vue d’ensemble du système.
2. Segmentation thématique
Notre analyse thématique est fondée sur la répartition des mots dans le texte et exploite le fait que le développement d’un thème entraîne la reprise de termes spécifiques, notamment lorsqu’il s’agit de textes techniques ou scientifiques. La reconnaissance de parties de texte liées à un même sujet est alors fondée sur la distribution des mots et leur récurrence. Si un mot apparaît souvent dans l’ensemble du texte, il est peu significatif pour délimiter un thème particulier du texte, alors que sa répétition dans une zone limitée est très significative pour caractériser le thème du segment. Le principe appliqué [Hearst, 1997] consiste à associer un vecteur de descripteurs –mot– à une zone de texte, le paragraphe pour nous, à pondérer ces descripteurs et à calculer les distances des zones consécutives. Une faible distance correspond à un changement de sujet.
3. Description du texte ou de portions du texte
Nous nous plaçons dans une perspective applicative de résumé dynamique automatique. Notre but est alors de fournir à l’utilisateur des clefs de lecture d’un texte. En particulier nous cherchons à l’informer sur le contenu et le type du texte ou d’une de ses portions ; soit en d’autres termes le renseigner sur le sujet du texte ou d’une de ses portions, sur le rôle que joue un segment dans la structure du texte et sur les relations qu’il entretient avec les autres segments.
Dans ce travail, nous émettons l’hypothèse qu’un texte hérite des caractéristiques des descripteurs qu’il contient, en posant qu’un descripteur est une expression linguistique qui renseigne sur le contenu des énoncés dans lesquels il figure, et ainsi, en faciliter leur compréhension.
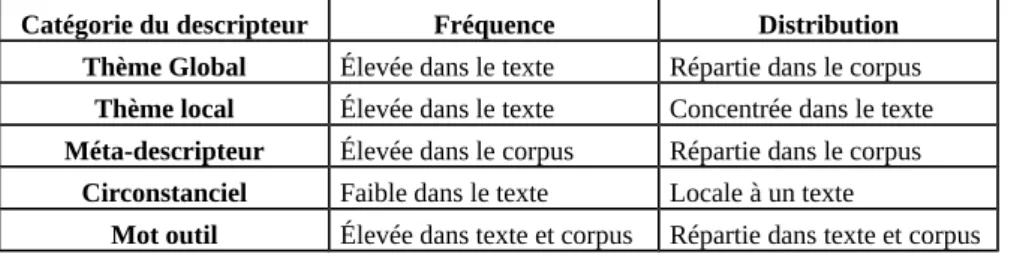
3.1. Catégorie de descripteurs
Nous mettons en avant deux propriétés principales d’un descripteur, la fréquence – nombre d’occurrences – et la distribution lexicale – position des occurrences –, et admettrons que, dans un référentiel donné, ces propriétés sont des indices pertinents pour caractériser un descripteur. Ceci semble au moins vrai au niveau macroscopique (i.e. segment, document, corpus), même si l’on convient que d’autres indices (e.g. la fonction grammaticale, la position dans la phrase, etc.) sont nécessaires au niveau microscopique (i.e. phrase, proposition).
Catégorie du descripteur Fréquence Distribution
Thème Global Élevée dans le texte Répartie dans le corpus
Thème local Élevée dans le texte Concentrée dans le texte
Méta-descripteur Élevée dans le corpus Répartie dans le corpus
Circonstanciel Faible dans le texte Locale à un texte
Mot outil Élevée dans texte et corpus Répartie dans texte et corpus
Cette proposition nous permet de distinguer deux étiquettes principales de descripteurs : les descripteurs thématiques et les descripteurs génériques (appelés aussi meta-descripteurs). Les premiers peuvent être caractérisés en globaux ou en locaux et les derniers peuvent être considérés en tant que concepts ou relations (Cf. figure 2 pour un aperçu plus complet).
Par rapport à notre corpus de type scientifique, les descripteurs thématiques sont propres à un document, ils correspondent « abusivement » à « ce dont parle l’auteur » ; le lexique générique quant à lui se situe sur un autre axe et correspond au vocabulaire propre à l’ensemble des documents de nature scientifique (mis à part les mots outils), c’est-à-dire par exemple « hypothèse, analyse, problème, etc. ».
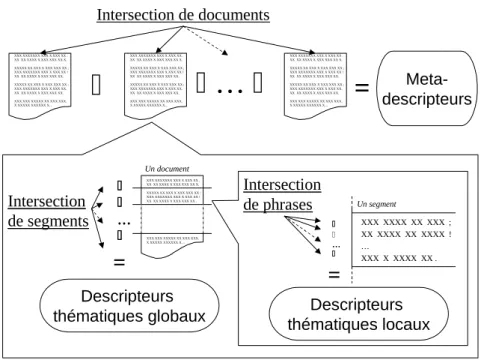
3.2. Caractérisation : méthode de l’intersection lexicale
D’un point de vue théorique, l’opération que l’on réalise pour obtenir les différentes catégories est une intersection lexicale entre toutes les unités de texte, à un même niveau d’imbrication. XXX XXXXXXX XXX X XXX XX . XX XX XXXX X XXX XXX XX X. XXXXX XX XXX X XXX XXX XX ; XXX XXXXXXX XXX X XXX XX ! XX XX XXXX X XXX XXX XX. XXXXX XX XXX X XXX XXX XX ; XXX XXXXXXX XXX X XXX XX. XX XX XXXX X XXX XXX XX. XXX XXX XXXXX XX XXX XXX. X XXXXX XXXXXX X…
…
=
Meta-descripteurs Intersection de documents Intersection de segments Intersection de phrases XXX XXXXXXX XXX X XXX XX . XX XX XXXX X XXX XXX XX X. XXXXX XX XXX X XXX XXX XX ; XXX XXXXXXX XXX X XXX XX ! XX XX XXXX X XXX XXX XX . XXX XXX XXXXX XX XXX XXX. X XXXXX XXXXXX X… … Descripteurs thématiques locaux XXX XXXX XX XXX ; XX XXXX XX XXXX ! … XXX X XXXX XX . XXX XXXXXXX XXX X XXX XX . XX XX XXXX X XXX XXX XX X. XXXXX XX XXX X XXX XXX XX ; XXX XXXXXXX XXX X XXX XX ! XX XX XXXX X XXX XXX XX. XXXXX XX XXX X XXX XXX XX ; XXX XXXXXXX XXX X XXX XX. XX XX XXXX X XXX XXX XX. XXX XXX XXXXX XX XXX XXX. X XXXXX XXXXXX X… XXX XXXXXXX XXX X XXX XX . XX XX XXXX X XXX XXX XX X. XXXXX XX XXX X XXX XXX XX ; XXX XXXXXXX XXX X XXX XX ! XX XX XXXX X XXX XXX XX. XXXXX XX XXX X XXX XXX XX ; XXX XXXXXXX XXX X XXX XX. XX XX XXXX X XXX XXX XX. XXX XXX XXXXX XX XXX XXX. X XXXXX XXXXXX X… … Un document Un segment=
=
Descripteurs thématiques globauxFigure 3. Intersection lexicale à différents niveaux d’imbrication
Par exemple (Cf. figure 3), l’intersection lexicale des documents d’un corpus désigne les méta-descripteurs ; l’intersection lexicale des segments d’un document désigne les descripteurs thématiques globaux et l’intersection lexicale des phrases d’un segment désigne les descripteurs thématiques locaux.
4. Extraction de termes et caractérisation
Du fait de la complexité des propriétés à observer suivant le référentiel, nous avons observé des expressions linguistiques différentes pour les descripteurs thématiques et les descripteurs génériques. Pour les génériques, observés au niveau du corpus, où des critères de fréquences et de distribution sont suffisants, nous n’avons supposé aucun type de forme linguistique et ainsi considéré distinctement tout n-gramme, suite de « n » mots, comme expression candidate (bi-grammes, tri-grammes, et 4- et 5-grammes) ; cette approche nous permet par la suite d’opter préférentiellement pour telle ou telle forme à observer. Les descripteurs thématiques étant observés à une granularité beaucoup plus fine nécessitent la considération de davantage de critères. C’est pourquoi nous restreignons notre étude aux syntagmes nominaux. Ce choix est aussi guidé par la littérature référençant ces formes comme porteuses privilégiées d’attributs thématiques du texte [Boguraev et al., 1997].
4.1. Corpus
Nous travaillons avec un corpus thématiquement hétérogène, dont le type est posé, ici scientifique. Chaque document traite d’un thème qui le distingue des autres . Du fait de la difficulté de construire un corpus thématiquement hétérogène, nous avons opté pour les actes électroniques disponibles des conférences TALN et RÉCITAL des dernières années (2001, 2000 et 1999).
Après transformation dans un format texte exploitable1 et filtrage des entêtes,
résumés et références, nous obtenons 81 textes aux alentours de 4100 mots chacun.
4.1. Acquisition de méta-descripteurs
Nous nous situons dans la continuité des travaux en acquisition terminologique par filtrages statistiques (voir [Bourigault et al., 2001] pour une synthèse). Notre apport réside dans le jeu de recoupements entre listes d’expressions ayant des critères de fréquence et de distribution différente.
4.1.1. Algorithme de base
L’opération d’intersection lexicale pour désigner les expressions linguistiques méta-descriptives est effectivement réalisée comme une intersection :
- d’abord, on extrait de chaque document un exemplaire unique de chaque type d’expression considérée, et ce dans la forme désirée (lemmatisée ou attestée) ; - ensuite, on concatène ces expressions dans une même liste ;
- finalement, la fréquence d’une expression dans cette liste correspond au nombre de documents où elle figure. Un seuil minimal est posé pour les filtrer.
1 Le transcodage de pdf en texte a été réalisé à partir de commandes linux et les éventuelles erreurs dues aux caractères accentués du français ont été corrigées à partir de scripts Perl.
Selon le type d’expression linguistique considéré, les formes obtenues sont plus ou moins « figées » et nécessite en général une intervention humaine pour les valider.
4.1.2. L’utilisation de n-grammes
Nous avons choisi de considérer des n-grammes comme expressions linguistiques présentées en entrée de notre chaîne en raison de ses propriétés de couverture. En effet, son principal avantage est que le rappel des formes figées que l’on souhaite repérer ne dépend que de la taille maximale des n-grammes considérés2 et non de
règles syntaxiques. Dans nos expérimentations, nous n’avons pas dépassé l’indice 5. Néanmoins le principal inconvénient des n-grammes est que même filtrés, nous ne savons rien sur le type des expressions obtenues. En-effet, nous obtenons des listes de bi-grammes, de tri-grammes, de 4- et 5-grammes dont la fréquence est supérieure à un seuil posé mais ne pouvons savoir si le n-gramme considéré est bien une forme figée, ou bien s’il s’agit d’un constituent d’une telle forme, ou bien si elle contient une telle forme, ou encore si forme figée il y a.
4.1.3. Filtrage automatique
Dans l’état, les listes obtenues sont très satisfaisantes et constituent une assistance indéniable pour des terminologues du domaine ; a fortiori si l’on présente dès le départ des expressions figées en entrée de notre chaîne afin de tester leur appartenance aux génériques. Néanmoins, poussé par le désir d’automatisation maximale, nous avons conçu un procédé pour filtrer les expressions non-figées. Celui-ci reprend globalement le mécanisme de l’intersection lexicale :
- on concatène toujours les listes d’expressions de chaque document en une seule mais cette fois-ci on considère indifféremment les n-grammes pour que les bi-grammes, tri-bi-grammes, 4- et 5-grammes se retrouvent dans le même fichier ; - la fréquence de chacune des formes ordonne cette liste et agit en filtre ;
- l’étape suivante est le cœur du procédé, et part de l’hypothèse que si des formes ont une fréquence d’occurrence « voisine » et que l’une est englobée par l’autre, alors certainement ces formes ne font qu’une seule.
F V Expression Etiquette – commentaires
59 46 point Figée car pas de voisin englobant 49 38 vue Figée car pas de voisin englobant
44 34 point de Non-figée car voisin englobant « point de vue » 37 28 de vue Non-figée car voisin englobant « point de vue » 37 28 point de vue Figée car pas de voisin englobant
22 16 un point de vue Non-figée car voisin englobant « d’un point de vue » 20 14 du point de vue Figée car pas de voisin englobant
19 14 d’un point de vue Figée car pas de voisin englobant Figure 4. Filtrage automatique
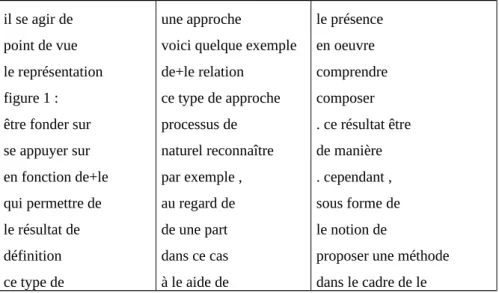
Une expression linguistique – n-gramme – est ainsi dite forme figée, s’il n’existe pas d’expressions qui pourrait l’englober ayant un nombre d’occurrence « voisin ». Empiriquement, nous avons posé ce voisinage à 20% de la fréquence de l’expression. La figure 4 témoigne de ce filtrage effectif avec « F » pour la fréquence de l’expression, et « V » pour celle du dernier voisin (le plus éloigné) testé comme englobant.
il se agir de point de vue le représentation figure 1 : être fonder sur se appuyer sur en fonction de+le qui permettre de le résultat de définition ce type de une approche
voici quelque exemple de+le relation ce type de approche processus de naturel reconnaître par exemple , au regard de de une part dans ce cas à le aide de le présence en oeuvre comprendre composer . ce résultat être de manière . cependant , sous forme de le notion de
proposer une méthode dans le cadre de le
Figure 4. Liste des formes figées extraites3
Pour un seuil de fréquence minimale posé à 5 et un voisinage de 0,2, nous constatons l’importance de la qualité du filtrage des formes relevées. Ceci en sachant que seules les expressions combinaisons de mots vides (pronom, préposition, ponctuation) et thématiques courantes (comme « informatique ; linguistique, syntaxe, phrase, etc. ») ont été retirées de la liste. Le deuxième constat que nous faisons relève de la diversité des types de ces formes. Bien qu’une étude approfondie est nécessaire pour correctement toutes les étiqueter, ces formes semblent toutes jouer un rôle prépondérant dans l’interprétation de la structure rhétorique d’un texte scientifique. Dans le cadre de notre étude, pour la construction d’un dictionnaire du domaine scientifique, nous nous restreignons aux formes nominales et verbales que nous étiquetons respectivement de concepts et de
relations du domaine.
Ces formes étiquetées nous permettent d’annoter les énoncés dans lesquels elles figurent et de fournir un complément d’information aux descripteurs thématiques des textes que l’on chercher à décrire.
4.2. Identification des descripteurs thématiques
Le repérage et l’identification d’un descripteur thématique se déroulent en deux étapes successives. Elles s’inspirent des travaux de [Boguraev et al., 1997]. Une troisième étape intervient pour caractériser sa pertinence thématique vis-à-vis de la structure du texte.
La première étape vise à repérer les expressions « référentes » ; c’est-à-dire les formes nominales ou pronominales faisant référence aux entités du texte. La seconde étape est un système de résolution d’anaphores, qui permet d’une part, de distinguer les formes descriptives d’entités de reprises anaphoriques nominales, et d’autre part de gagner en précision sur la fréquence et la distribution des entités du texte.
4.2.1. Repérage des expressions référentes
Le processus de repérage d’expressions référentes consiste à relever des syntagmes nominaux et des pronoms par reconnaissance de patrons syntaxiques. On distingue les syntagmes nominaux simples seulement constitués de noms et d’adjectifs, des syntagmes nominaux complexes admettant la préposition « de ».
4.2.2. Système de résolution d’anaphores
Nous avons ciblé nos traitements sur les anaphores les plus susceptibles de jouer un rôle de reprise anaphorique ; c’est-à-dire essentiellement les anaphores nominales introduites par un démonstratif et les pronoms personnels dont nous avons filtré les tournures impersonnelles les plus courantes. Seuls des syntagmes nominaux sont envisagés comme antécédent potentiel.
Le système suit une architecture pipeline en trois phases : une sélection des antécédents candidats pour une anaphore donnée, un ordonnancement préférentiel des candidats pour désigner le plus probable et un filtrage des antécédents incompatibles avec l’expression référente en focus. Ces deux dernières étapes sont inversés par rapport à ce que l’on peut trouver dans la littérature [Mitkov, 1998 ; Boguaev, 1997]. Ceci découle du fait qu’en grande majorité il existe un antécédent pour le type d’anaphores que nous traitons, et par là nous voulons forcer son repérage malgré les contraintes de filtrage. Celles-ci sont donc ordonnancées entre elles par degré de contraintes. Le premier antécédent qui valide le plus haut degré est considéré comme l’antécédent de l’anaphore.
Les critères de sélection, de filtrage et de préférence sont fondés sur des critères morphologiques (compatibilité genre/nombre), lexicaux (même tête sémantique), syntaxiques (fonction grammaticale, parallélisme), et discursive (récence) qui permettent de pondérer préférentiellement telle ou telle candidat antécédente. La
phase de préférence calcule deux types de préférences : un poids inhérent au caractère propre de l’antécédent, et un poids en fonction du type de l’anaphore. La plupart des ressources nécessaires pour réaliser ces descriptions d’expressions référentes ont été obtenues à partir d’heuristiques robustes (e.g. l’annotation fonction grammaticale -Sujet, Objet- est détectée selon la position de la forme par rapport au verbe de la proposition et selon sa position par rapport à une préposition).
4.2.3 Caractérisation des descripteurs thématiques
Parmi les entités obtenues seules les entités présentant un « penchant thématique » ont été considérées comme telles. Ce penchant se présente sous forme de seuil minimal sur le poids inhérent d’une entité. Il a été fixé pour considérer, entre autres, les fonctions grammaticales sujet et objet, la récurrence, ou la spécification par un démonstratif comme penchants thématiques. Les caractéristiques d’une entité sont celles de ses individus moyennées.
Les entités thématiques sont ensuite caractérisés en fonction de leur rôle dans la structure thématique du texte. Nous utilisons le nombre de segments thématiques dans lesquels un terme apparaît pour caractériser le descripteur de local s’il apparaît dans un seul segment ou de global., s’il figure dans au moins deux segments. Dans ce dernier cas, certains descripteurs peuvent profiter de l’étiquette descripteur thématique global « de tout le texte » s’ils apparaissant dans le plus grand nombre de segments. L’objectif sous-jacent à ce typage vise à construire une hiérarchie entre les thèmes d’un texte suivant des relations d’élaboration ou d’association.
5. Exemple de repérage de descripteurs
La section présente un exemple d’application de notre système sur un article de la revue de vulgarisation scientifique « la Recherche ». Celui-ci a pour sujet le « vin jaune ». Les auteurs s’interrogent sur la molécule responsable de son goût spécifique. Le fragment présenté à la figure 5 a été relevé automatiquement comme segment thématique. Il traite de la méthode la plus directe pour analyser les vins.
Figure 5. Exemple de visualisation de texte
Le système identifie automatiquement « vin » comme un descripteur thématique global ; ce qui apparaît normal dans un texte traitant entièrement de vin. De la même manière, il identifie « composé et mélange » comme des descripteurs thématiques locaux. Les deux renforcent les rôles des expressions identifiées comme méta-descriptives « analyse et technique ». Pour illustrer cela, on remarquera que le thème global et un méta-descripteur apparaissent tous deux en début de la première phrase, et que le syntagme nominal qui les contient décrit précisément le contenu du segment.
5. Conclusion – synthèse et perspectives
Notre but applicatif est de faciliter l’accès au contenu d’un texte. Nous nous situons ainsi dans une approche de résumé dynamique s’adaptant aux besoins d’un utilisateur. Á cette fin, nous produisons un ensemble d’analyses du texte ou de ses portions, que nous considérons comme autant de vues de différents niveaux d’abstraction. L’accès au texte se réalise ainsi en offrant à l’utilisateur la possibilité de visualiser telle ou telle vue et de naviguer entre elles. Par exemple, l’exploration d’un texte pourra suivre les différents degrés de développement thématique dégagés d’une structuration thématique [Hernandez et al. 2002], et la description d’un segment reposera sur la présentation des différents termes et sur leur catégorisation (pertinence globale, pertinence locale, lexique générique).
Outre cette perspective il convient aussi de porter une attention plus approfondie sur les termes méta-descripteur extraits, notamment en étudiant les relations entre
concepts, entre relations et entre concepts et relations, toujours par observation des collocations, et ce, pour la construction automatique d’ontologie de domaine.
Remerciement
Nous tenons à exprimer nos sincères remerciements à Cécile Barras pour son attention et son aide lors de la relecture de ce papier.
6. Bibliographie
S. Ben Hazez, J.-P. Desclés et J.-L. Minel, « Modèle d’exploration contextuelle pour l’analyse sémantique des textes » , TALN, pp. 73-82, Tours, 2001
B. Boguraev and C. Kennedy, « Salience-based content characterisation of text documents », In Proceedings of ACL'97 Workshop on Intelligent, Scalable Text Summarisation, 1997 D. Bourigault, C. Jacquemin, and M-Cl L'Homme « Recent Advances in Computational
Terminology », John Benjamins, Amsterdam, 2001
M. Hearst, « TextTiling: Segmenting Text into Multi-Paragraph Subtopic Passages »,
Computational Linguistics, 23 (1), pp. 33-64, March 1997
N. Hernandez and B. Grau, « Analyse Thématique du Discours : segmentation, structuration, description et représentation », CIDE'05, Hammamet, Tunisie, 20-23 octobre 2002. N. Masson, « Méthodes pour une génération variable de résumé automatique : vers un
système de réduction de texte », Thèse de doctorat, Université Paris XI, 1998
J.-L. Minel., « Filtrage sémantique. Du résumé automatique à la fouille de textes ». 202 p. Editions Hermès, 2003
R. Mitkov, « Robust pronoun resolution with limited knowledge ».. In Proceedings of the
18th International Conference on Computational Linguistics, COLING/ACL, 1998
H. Saggion and G. Lapalme, « Concept Identification and Presentation in the Context of Technical Text Summarization », ANLP-NAACL, Workshop in Automatic Summarization, Seattle, WA, USA, 2000