Web 3.0 : Prototype "Les communes dans les Archives fédérales"
Texte intégral
Figure





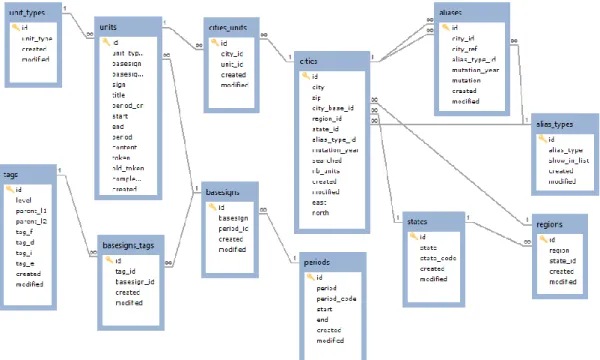
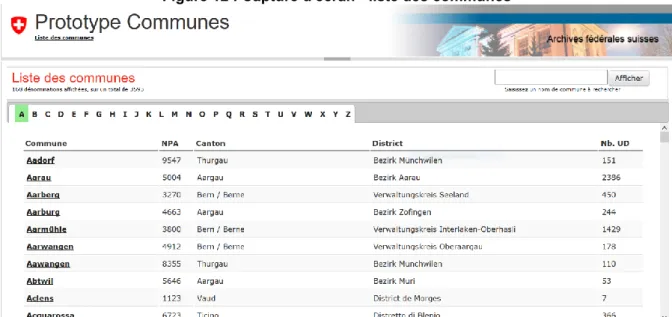

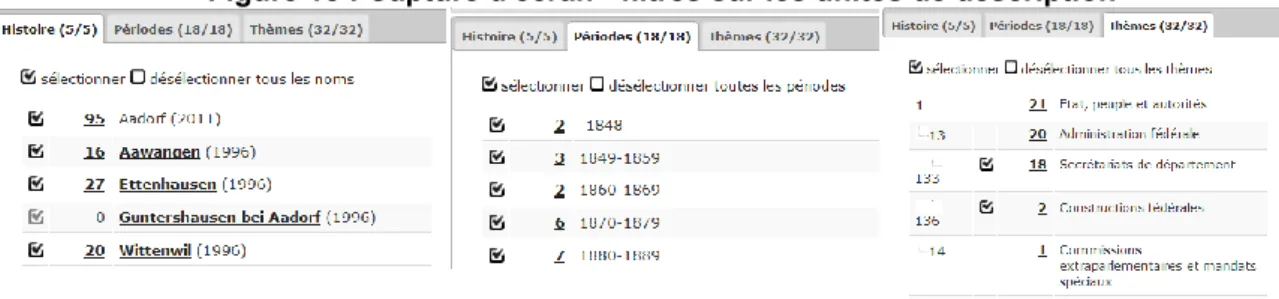

Documents relatifs
Exercice 1 : Dans la phrase, souligne les mots où tu entends le son [e].. Le nez du boulanger ressemble à une énorme pomme
Déterminer dans les deux situations proposées ci-contre l’équation cartésienne du cercle de centre A... Donner une équation cartésienne de
- passer d'une chaîne de caractères entrée au clavier pour représenter un nombre entier, et la convertir dans le format binaire que comprend l'ordinateur, en passant par
• Pour l’effectif salarié et la masse salariale avec la méthode statistique des doubles différences L’analyse de la base de données ACOSSS et l’utilisation de la
Les bilans hydrologiques ont été étudiés entre Walliswil et Olten (pied du Jura, cantons de Berne et Soleure) et dans les régions voisines en vue d'une approche cohérente des
Les personnes éligibles aux deux complémentaires santé affichent des taux de restriction sur les soins médicaux nettement supérieurs à la moyenne des personnes interrogées
Effectuer la division euclidienne (quotient et
Classification des rubriques des URLs visitées du site Web de l’INRIA (équipes de recherche en particulier) à partir des navigations des internautes en vue d'étudier l'impact de
