A NUMA Aware Scheduler for a Parallel Sparse Direct Solver
Texte intégral
Figure





Documents relatifs
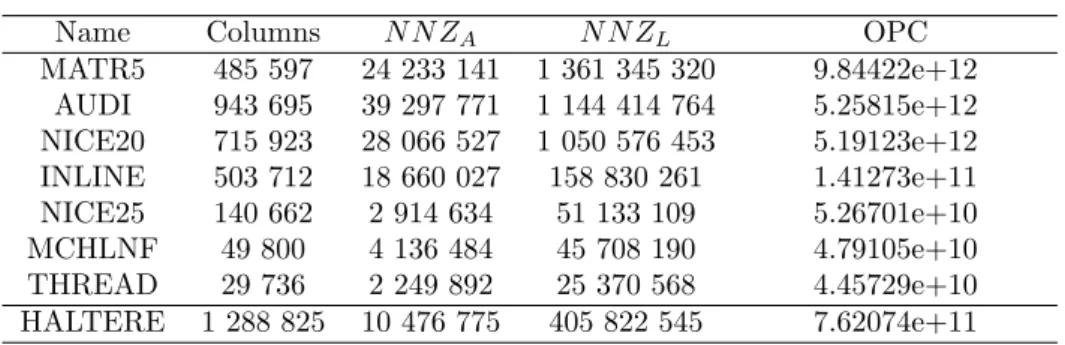
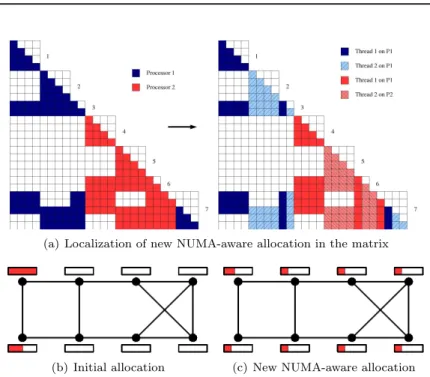
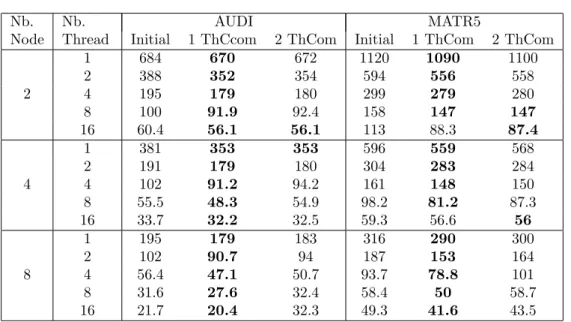
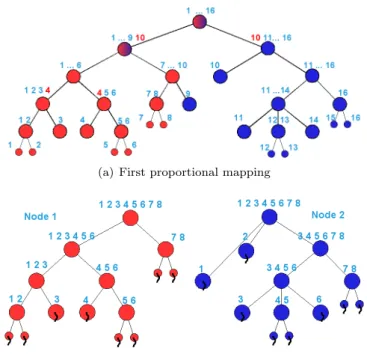
We identified three major steps in the task scheduler work- flow that may have an impact on parallel applications on NUMA systems : the data dis- tribution, the assignment of
Dans une étude rétrospective incluant une cohorte de 100 patients confirmés par autopsie, Respondek et al (29) ont analysé les formes phénotypiques de la PSP
La première phase de travail, basée sur le contrôle hebdomadaire pendant 47 semaines de paramètres bactériologiques (dénombrement des bactéries en épifluorescence, dénombrement des
Mais 94% des hôpitaux qui ont des processus spécial de stérilisation pour lutter contre les ATNC <<prion>>, ils n’ont pas une fiche de déclaration
Wynants, P 1988, 'Le repérage des communautés religieuses enseignantes dans les archives communales du XIXe siècle', Revue d'histoire religieuse du Brabant wallon,
The translation of formulae into counter automata takes advantage of the fact that only one index is used in the difference bound constraints on array values, making the
For our numerical experiments, we used the parallel nested dissection algorithm of PT-Scotch to extract eight subdomains and used a minimum degree ordering on each subdomain to
• no-freeze: each imported clause is actually stored with the current learnt database of the thread, and will be evaluated (and possibly frozen) during the next call to updateDB..
