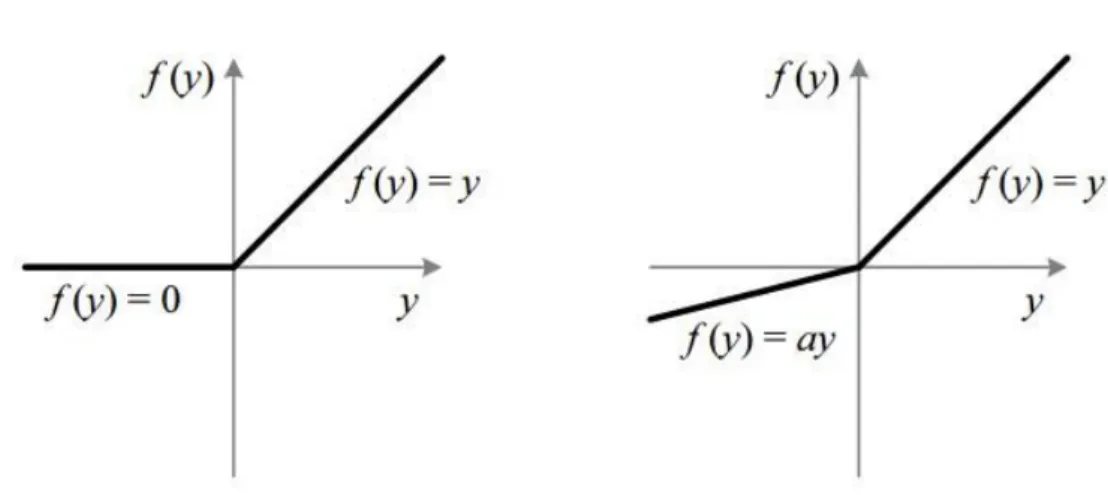Generated suspect photo board using artificial
intelligence
Bachelor Project submitted for the degree of
Bachelor of Science HES in Business Information Systems
by
Mélanie MANIVANH
Bachelor Project Mentor:
David BILLARD, Professor
Disclaimer
This report is submitted as part of the final examination requirements of the Haute école de Gestion de Genève, for the Bachelor of Science HES-SO in Business Information Systems. The use of any conclusions or recommendations made in or based upon this report, with no prejudice to their value, engages the responsibility neither of the author, nor the author’s mentor, nor the jury members nor the HEG or any of its employees.
Geneva, July 6th, 2020
Acknowledgements
I would like to thank my Bachelor Project Mentor, the Professor David Billard for letting me work on this project. His support and guidance helped me going through the whole process while focusing on the essential parts.
I would also like to thank Mr Sebastien Capt for this proposal as his patience and understanding throughout the whole process.
In addition to this, I would like to thank Flávio Alexandre Barreiro Lindo for his support and who read my work with a lot of attention.
Finally, I want to thank my mother, my father and my brother for their encouragement to pursue and realise my bachelor thesis as well as my bachelor’s degree.
Executive Summary
In this thesis I will analyse different artificial neural network solutions for creating fake portraits. The final objective is to create a photo board with 1 real portrait and 8 fake ones that are indistinguishable from the real world. In order to achieve the final goal, a description of how an artificial neural network works, how to train one is going to be explained. An overview of the different and most used technologies use to work with artificial neural networks will be presented. Not to mention that practical results are exposed in the last part of this thesis.
Contents
Generated suspect photo board using artificial intelligence ... 1
Disclaimer ... i
Acknowledgements ... ii
Executive Summary ... iii
Contents ... 1
List of Tables ... Erreur ! Signet non défini. List of Figures ... 3
1. Introduction ... 4
1.1 Scientific Police of Geneva ... 4
1.2 The Problem addressed in this work ... 5
2. Neural Network ... 8
2.1 What is it? ... 8
2.2 Perceptron ... 9
2.2.1 What does it need to function? ... 9
2.2.2 Input ... 10
2.2.3 Weight ... 10
2.2.4 Activation function ... 10
2.2.5 Output ... 14
2.2.6 Loss Function ... 14
2.3 Multi-Layer neural network ... 15
2.4 Supervised Learning vs Unsupervised learning ... 15
2.5 Convolutional Neural Network ... 16
2.5.1 Convolutional Layer ... 16
2.5.2 Non-linearity (ReLU) ... 17
2.5.3 Pooling... 18
2.5.4 Classification... 18
2.6 Generative Adversarial Network ... 19
2.6.2 Generator ... 21
2.6.3 Image Generator ... 21
2.6.4 Dataset and Real image... 21
2.6.5 Discriminator ... 21
2.6.6 Real or fake ... 21
2.6.7 Maximize and minimize error ... 21
3. State of the art ... 21
3.1 Style GAN ... 22
3.2 Transparent latent-space GAN... 22
3.3 Progressive Growing GAN ... 23
3.4 Generated.photos ... 24
4. Choice of the technology ... 24
4.1 TensorFlow ... 24
4.2 Keras ... 25
4.3 Pytorch ... 25
5. In practice ... 25
6. Ethical point of view ... 30
7. Conclusion ... 32
Bibliography ... 33
List of Figures
Figure 1 - Photo board as shown to the witnesses ... 5
Figure 2 - These people are not real ... 6
Figure 3 - Style Transfer 1/2 ... 7
Figure 4 - Style transfer 2/2 ... 7
Figure 5 - Comparison between a human neural network and an artificial one ... 8
Figure 6 - Representation of a perceptron ... 9
Figure 7 - Sigmoid activation function ...11
Figure 8 - Tanh compared to sigmoid ...12
Figure 9 - ReLU activation function ...12
Figure 10 - ReLU vs Leaky ReLU ...13
Figure 11 - Step activation function ...14
Figure 12 - Single layer perceptron and perceptron with hidden layer ...15
Figure 13 - Convolution ...16
Figure 14 - ReLU layer ...17
Figure 15 - Pooling ...18
Figure 16- Process of a GAN ...19
Figure 17 - Latent space representation ...20
Figure 18 - Compressed data in a latent space ...20
Figure 19 - These faces are still not real ...22
Figure 20 - Transparent latent-space results ...22
Figure 21 - Progressive GAN in action ...23
Figure 22 - Samples from generated.photos...24
Figure 23 - Sample of StyleGAN ...26
Figure 24 -Artifacts in StyleGAN ...26
Figure 25 - Expected time for training StyleGAN ...27
Figure 26 - TL-GAN in practice ...28
Figure 27 - TL-GAN changing the parameters ...28
Figure 28 - Epoch 50 – Epoch 7500- Epoch 15000 ...29
Figure 29 -Targeted policing for drug crimes, by race ...30
1. Introduction
1.1 Scientific Police of Geneva
The scientific police of Geneva is a department that belongs to the Police of Geneva. There are two domains where they operate judicial coordination and operational criminal analysis. The judicial coordination helps to treat data collected in reports, declarations and recordings linked to crime such as robberies, assault, etc. The judicial coordination allows for having an overall point of view and a support to the identification of phenomena.
The second domain concerns the operational criminal analysis. When needed, it treats and structures the data corresponding to a specific investigation. It develops investigation files as databases.
The first domain is the one that is relevant in this thesis as they establish photo board for any other department.
1.2 The Problem addressed in this work
Figure 1 - Photo board as shown to the witnesses
When interrogating the witness, the police presents a photo board of 9 suspects as shown in Figure 1. Some of the suspects are chosen randomly in the database of pictures of Geneva. The witness may recognise a familiar face that has nothing to do with the incident and therefore can mislead the witness. Besides, it is also a privacy issue to use people’s faces without their consent.
The intent of the photo board is to create 8 AI generated portraits that are indistinguishable from a human face. This would prevent a witness from identifying the real culprit through process of elimination.
Figure 2 - These people are not real
Source: (Karras, Laine, Aila 2018) On
Figure you can see the portraits generated by the generator of pictures from Nvidia named StyleGAN (Generative Adversarial Network). The technology the police wants to use would be inspired by the GAN except that it would be customisable.
This is one of the first GANs that produces faces that are the closest to the reality. It uses the idea of style transfer network, which is superposing two images to create a new one. Style Transfer is a principle that can be easily explained: the idea is that you have one content image and one style image; combining these two pictures will present a unique fusion of the two of them.
Figure 3 - Style Transfer 1/2
Source: (Neural style transfer | TensorFlow Core 2020)
In Figure 3 - Style Transfer 1/2 the content image is a golden retriever and the style image is a painting of Kandinsky. The idea is to overlay the two images to create a unique and new picture as seen in Figure 4 - Style transfer 2/2.
Figure 4 - Style transfer 2/2
2. Neural Network
2.1 What is it?
Source:(Maltarollo, Honório, Silva 2013)
First, I would like to explain how an artificial neural network is made, I will then further explain how it works.
To begin with, a neural network is highly inspired by the human body. Let us look at Figure 5. Points A and C represent a human neuron and its connection to another. Points B and D are a perceptron and its network. In A, the dendrites are receiving a stimulus
Figure 5 - Comparison between a human neural network and an artificial
one
Now, if you look at point B you can see the comparison as the dendrites are represented by the variables x1, x2, …, xn. These are called input. Then, the terminal axon would be the output of the artificial neuron: yi.
As the synapse in point C transmits the information in a chemical reaction, the synapses in an artificial model are the hidden layers of an artificial system on point D.
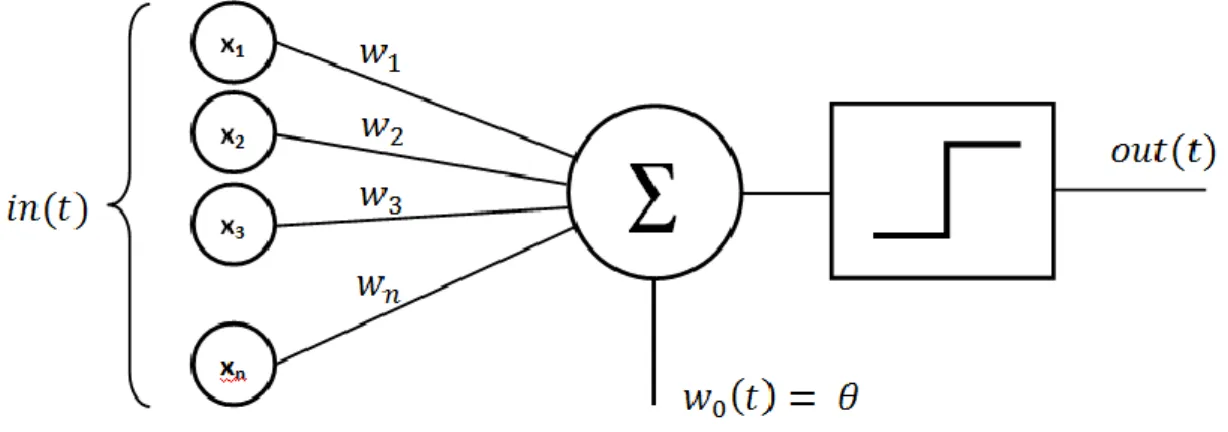
2.2 Perceptron
Figure 6 - Representation of a perceptron
Source: (Loiseau 2019)
The perceptron was invented by a scientist named Frank Rosenblatt during the 1950s and 1960s. He used the work of Warren McCulloch and Walter Pitts to create it. (Nielsen 2015). To be simply put, it is a linear classifier as the weights and the input directly influence the output.
2.2.1 What does it need to function?
The perceptron as presented in Figure 6 is the simplest form of artificial neural network. It needs an input along with two parameters: an activation function and weights and it gives an output. The input is multiplied by the weight and then added.
Its formula is represented as this:
𝑐 = ∑𝑛𝑖=1𝑤𝑖∙ 𝑥𝑖+ 𝑤0 or 𝑐 = 𝑤𝑡 𝑥 + 𝑏
2.2.2 Input
The input can be different kind of variables such as categorical or numerical. Categorical is the type values that would be qualifying an object, for example the colour of the eyes. They are represented by the in(t) above. In our case the inputs are the pixels. For example, if you have a picture that is 28 by 28 pixels you are going to have inputs of 284. Also, it would be better to have greyscale as it is easily identifiable. Each of these values are either going to be between 0 and 1 which signifies that the pixel is activated or not (Barreiro Lindo 2018). Usually the inputs can be normalized (making their value fall between 0 and 1) so that the learning process can be optimized and have values that can be more comparable.
2.2.3 Weight
The weights are represented as w1, w2, w3 in Figure 6. They reflect the importance of each input. They adjust during the training in order to give the best accuracy for the output. In the case of the perceptron, the adjustments are going through the backpropagation and using gradient descent.
Gradient descent is useful for any function. As the loss function often results in a function with squared formula, it is perfect for it. With the gradient descent you can find a minima of the loss function. In order to do that, the first time you need to take random parameters in the function and then compute the slope with a derivative. As the slope gets closer to 0, it means that the function is at its minimum. If the slope is big, the step towards the minima may be too large. To counter this problem, there is a learning rate which regulates the size of each step. Then we use the backpropagation algorithm to update the weights to reduce the loss function.
2.2.4 Activation function
The perceptron as an actual neuron needs to meet a threshold to be activated. They are used with neural networks that are not made with too many complex layers. There are
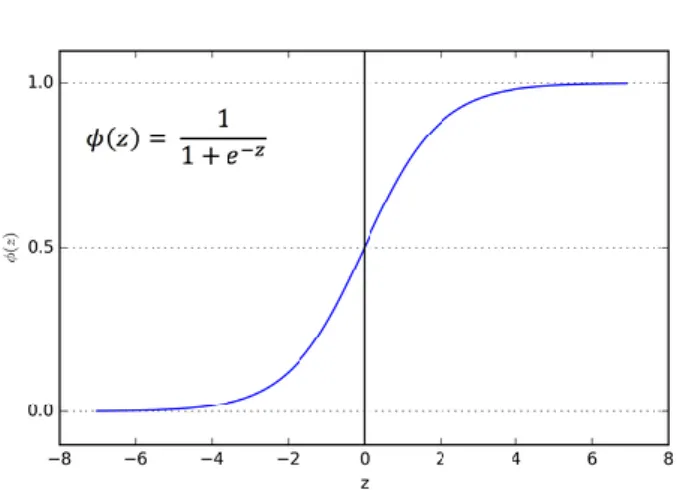
2.2.4.1 Sigmoid
Figure 7 - Sigmoid activation function
Source : (Sharma 2017)
The sigmoid function squeezes the inputs into values contained between 0 and 1. The output is going to be (0,1).
Even though this activation function is typically used for single label classification, it may create problems during the training phase. Like mentioned in 2.2.3, gradient descent uses the slope of the loss function to decide which direction minimizes the error of a perceptron. However, when the weights are above 4 or below -4, the derivative of sigmoid becomes almost zero. Meaning that a perceptron or neural network may stop learning.
2.2.4.2 Tanh
Figure 8 - Tanh compared to sigmoid
Source : (Sharma 2017) The tanh function is almost the same as the sigmoid function, except that the inputs are between 1 and -1. The optimisation is better than the sigmoid function because it is centred at 0. The tanh has the same vanishing gradient problem.
2.2.4.3 ReLU
Figure 9 - ReLU activation function
then it is easier to be computed than the sigmoid function or tanh function. Moreover, the results are as good as using sigmoid or tanh.
2.2.4.4 LeakyReLU
Figure 10 - ReLU vs Leaky ReLU
Despite the uses of the ReLU activation function, occasionally an issue known as “dying ReLU” presents itself. Indeed, while all the negative value are brought to 0, some of the neurons might never get activated during the training and therefore “die” (Lu, Shin, Su, Karniadakis 2019). Leaky ReLU is an altered version of ReLU that was created to fix this problem. Rather than setting all the negative values to 0, the slope of the activation function of Leaky ReLU is slightly negative (for instance -0.01) so that the training can still be fast and efficient.
2.2.4.5 Step
Figure 11 - Step activation function
Source : (Bhattarai 2018)
Step function is the function that is used in the perceptron. The value can be either 0 or 1. It is useful when the output you expect is binary.
2.2.5 Output
The output of the perceptron depends on the activation function; therefore, it can give (0;1) or (1; -1) as an output.
2.2.6 Loss Function
The Loss function is an error function that is given with the difference between the true classification and the result obtained throughout the training. The loss function goal is to minimise this error to get the best accuracy from the perceptron. In the case of the perceptron, if the input is well classified, the loss function will give you 0 as a result otherwise it is 1.
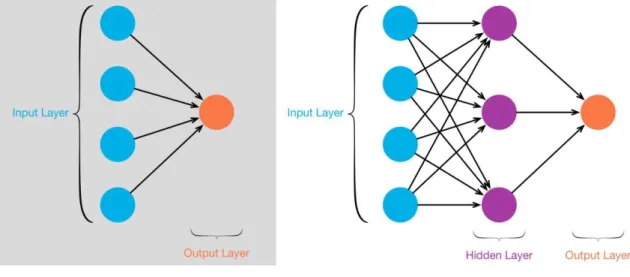
2.3 Multi-Layer neural network
Figure 12 - Single layer perceptron and perceptron with hidden layer
Source : (Kang 2019)
In section 2.2, we saw how a perceptron works. The multi-layer perceptron can be described as multiple perceptrons stacked on top of each other. Each artificial neuron is connected to all the neurons of the next layer. The first layer is called input, the last one is called output and the layers in-between are called hidden layers. More complex problems that are not linear can be solved with this model. As in the perceptron, each connection has a weight and every layer has an activation function and bias.
2.4 Supervised Learning vs Unsupervised learning
Supervised learning is a method where you give the neural network the input along with an expected output. So, if the network gives you an incorrect output, it can compare to the desired output and adjust its hidden layers so that it matches most accurately to the given results.
Unsupervised learning is another method where you give the inputs, but you expect the model to produce a result to which you do not know the correct answer.
For example, if you need to create a new song out of artificial intelligence, you will likely use an unsupervised network. On the other hand, if you need to classify a type of plant you should use a supervised learning as you know the outcome of the outputs.
2.5 Convolutional Neural Network
The convolutional network is a network used to classify images. It has 4 main parts: 1. Convolutional layer
2. Non-Linearity (ReLU) 3. Pooling
4. Classification
2.5.1 Convolutional Layer
This layer is where you can apply filters to extract feature from the input. A filter (a matrix) is applied to the image to extract the most interesting parts.
Figure 13 - Convolution
Source : (Saha 2018)
The image is the whole grid 5 x 5. The filter is represented by the yellow grid.
Each square of the filter is multiplied by the value of the image and then summed. This result is then reported in the convolved feature. The filter is moving along the image until the first line is done. Then it goes below so that the whole image is passed through the filter. Depending on the filter, you can extract the feature that you like such as the borders, the horizontal lines; the more the filter matches the values in the image, the more the score of the convolved feature is going to increase and so you know that the higher this result is, the more a part of the image is relevant. (Barreiro Lindo 2018)
2.5.2 Non-linearity (ReLU)
Figure 14 - ReLU layer
Source : (Prabhu 2019)
We saw in 2.2.4.3 what ReLU was.
Using the ReLU layer is mandatory after a convolution layer. The technique is the same as in a simple neural network, you have an input image and the filter is like the weights applied to an input. Hence, ReLU is applied so that the response is non-linear.
2.5.3 Pooling
Figure 15 - Pooling
Source : (Doshi 2019)
Pooling is used to reduce the size of an image while keeping the most important information. The different colours represented in Figure 15 are called kernels. The stride is the size of steps it must do before shifting into the next part of the input image. (Doshi 2019) Here, the stride is a stride of 2.
The Max pooling is the idea that the maximum value in the kernel is retained. The average pooling takes all the values in the kernel and make an average with it.
Max Pooling is the most used feature because it makes almost no computational power and keeps what is most important. Since convolution makes a part of an image activate more, it is this part that is kept.
2.5.4 Classification
2.6 Generative Adversarial Network
The Generative Adversarial Network (GAN) is a specified field of machine learning. Indeed, it is made to produce a result without supervising learning. It was invented in 2014 by Ian Goodfellow and his colleagues (Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville, Bengio 2014).
Source: (Kalin 2018) When using a GAN, two models need to be trained. First, the generator that generates the image in our case. Then the discriminator is going to tell if the image the generator produced is fake or real. The discriminator gives a result. If the result turned out to be fake, then the generator needs to adjust its parameters to convince the discriminator that the picture is real. As the training goes further, the discriminator becomes better at recognizing a fake from a real, therefore the Generator needs to improve itself to trick the discriminator (Kalin 2018).
2.6.1 Latent space
Figure 17 - Latent space representation
Source : (Tiu 2020) Latent space is the space that is used to make you recognise the difference between a chair and a table. For the faces, it is the space used to make you identify a smile from a frown. As shown in Figure 17, the representation of an image in the latent space is a compressed format of the input. The input is encoded and put in a latent space. Then, it is decoded and reconstructed.
Figure 18 - Compressed data in a latent space
2.6.2 Generator
The generator creates the fake data that will need to get analysed by the discriminator. In general, it uses the random noise at the beginning and as the discriminator gives a feedback, it updates his output. (Kahng, Thorat, Chau, Viégas, Wattenberg 2019)
2.6.3 Image Generator
The Image Generator is the output that the generator produces.
2.6.4 Dataset and Real image
The dataset is the set that is used by the discriminator as a basis to distinguish the real from the fakes. Usually the images from the dataset and the images created by the generator are mixed with a ratio of 0.5 so that the discriminator does not know if it’s a fake or a real that it receives. (Kahng, Thorat, Chau, Viégas, Wattenberg 2019)
2.6.5 Discriminator
The discriminator is a classifier neural network, a convolutional neural network. It just needs to classify the image it receives as real or fake. Its output is 0 or 1.
2.6.6 Real or fake
This is the result of the discriminator.
2.6.7 Maximize and minimize error
This is the function that stop the training of the whole GAN. Indeed, as the function becomes stables, it means that the training can stop, because the goal was reached. In the case of the GAN, there must be two error functions: one for the generator and discriminator. The discriminator tries to maximize the objective to discriminate as the generator tries to minimize the discrimination.
3. State of the art
This part will be focusing mainly on the faces generator since it is the part that interest us the most.
3.1 Style GAN
Source : (Karras, Laine, Aittala, Hellsten, Jaakko Lehtinen, Aila 2020)
As discussed in 1.2, this GAN belongs to NVIDIA, they used Flickr as an image database to produce the given results. They released a newer version of this GAN with better resolution and fluidity by redesign the generator normalization.
3.2 Transparent latent-space GAN
Figure 20 - Transparent latent-space results
Figure 19 - These faces are still not real
Source: (Guan 2018)
The transparent latent-space GAN is based on using the understanding of latent space to control the image. The dataset they used is a small set of celebrities, mostly from western celebrities.
This network makes the customization of the face into a fine granularity. The customization goes from the age gender, and hair colour to the size of the nose, the thickness of a beard.
The problem they encountered was that to be able to customize the faces, they needed to label the dataset first so that the model could adjust and control the faces produced. This labelling was possible using pre-trained neural networks capable of extracting characteristics from a face.
3.3 Progressive Growing GAN
Figure 21 - Progressive GAN in action
Source :(Karras, Aila, Laine, Lehtinen 2018)
The idea of this GAN lies into putting the resolution of the picture for the generator and the discriminator to the lowest possible. Then, by progressively increasing the resolution the model can produces better images faster and with more stability.
3.4 Generated.photos
Figure 22 - Samples from generated.photos
Source :(Generated Photos | Unique, worry-free model photos [no date])
This is the closest to the goal we are trying to achieve. Indeed, Generated photos is an API that displays faces generated by a GAN. To be more specific, it is said that the StyleGAN from Nvidia was used to create the faces. Moreover, this one matches our case because they classified the faces with some parameters such as, ethnicity, emotion, etc. Then, you can choose to filter these faces with those parameters. However, to be able to use this API, you need to pay to use it.
4. Choice of the technology
4.1 TensorFlow
TensorFlow is an open source library created by Google in 2017. It is used for large scale machine learning and computations. It is interesting because it uses a graph structure which can give you quick insights as how the execution of the model while occur allowing it to be better optimised. (Yegulalp 2019)
4.1.1 TensorFlow GPU
TensorFlow release a version that uses the GPU with the same API as for the CPU. Using this version allows for a developer the use the same knowledge for both types of execution.
4.2 Keras
Keras is an API that is now integrated to TensorFlow 2.0. This API was made to be user friendly and easy to use. Keras uses mainly two types of models. Sequential model and Model class from the functional API.
The sequential model is linear, and the layers are simple. In the functional API, the layers are more flexible and therefore more customisable.(Heller 2019)
4.3 Pytorch
Pytorch was created by Facebook AI in 2018. As Keras is an API, Pytorch is a framework just like Tensorflow, and uses a graph structure. It was made to be more integrated with Python.
It has two types of model: multi-layer classes and cell-level classes.
5. In practice
To avoid any problems of compatibility I used a software named Anaconda. This software creates a new environment for you to be able to install any library you want without worrying about the version compatibility.
As the research goes on, it seems that running a GAN takes a lot of resources. The main reason is that you need to train two neural networks at the same time.
5.1 Getting result of StyleGAN
With simply running the neuron network of Nvidia, the results get out quickly; here is a small sample of what you obtain.
Figure 23 - Sample of StyleGAN
All the faces from this size look real and with no flaws. Nevertheless, when zooming in you can see that some of them present with irregularities called artifacts. These artifacts are pointed out on Figure 24. Sometimes one part of the face does not look regular and sometimes it is the background.
Figure 24 -Artifacts in StyleGAN
However, to train the StyleGAN starting from the ground up you will need a GPU containing 32 GB of memory and this is the time that should take you to train the model
Figure 25 - Expected time for training StyleGAN
Source : (NVlabs/stylegan 2020) Basically, the time to train a neural network this complex is way too long for a computer used at home, as you can see in Figure 25 to generate pictures of good quality would take 41 days and 4 hours to achieve.
5.2 TL-GAN
Figure 26 - TL-GAN in practice
As you can see on Figure 26, the generated face can have issues and therefore be useless in a suspect photo board. The face gets worse when the parameters got modified, see Figure 27.
5.3 Generating on my own
Figure 28 - Epoch 50 – Epoch 7500- Epoch 15000
I took 5 hours to train a neural network with 8 GB of GPU to have the last result shown in Figure 28.
One epoch occurs when the whole network has seen all the training data once.
After 50 epochs of the neural network, you can guess that there is faces but it is far from being realistic. After 7500 epochs, the faces are already more distinguishable compared to the epoch 50, however there is a blue color that is coming out from some portraits. The last picture is the result obtained after 15000 epochs. The tones of the pictures are closer to the reality. Unfortunately, there are a lot of faces that are distorted, and therefore would be impossible to put into a suspect photo board.
5.4 Suggestions
The main idea would be to find in the latent space where the background is generated to be able to make all the picture coming from the same database. Another was to have the same background would be to remove it. (Shperber 2019)
In addition to this, the idea of the TL-GAN would be good as the feature of the face is customisable.
6. Ethical point of view
6.1 Ethnicity problem
The importance of the dataset is relevant and can cause the neural network to have prejudice against a certain race or gender. It is not directly related to this case, but its importance became apparent in 2013, when a man named Robert McDaniel was arrested because an artificial intelligence forecast that he was a person with a high risk of becoming a danger to society. The mistake was probably made as the dataset was not a representation of equal entries. Indeed, the black ethnicity was more targeted even though their use of drugs in terms of percentage was lower than white people.(Lum, Isaac 2016)
Figure 30 -Estimated drug use by race
Source : (Lum, Isaac 2016)
6.2 Noticeably fake
As the whole photo board excepted for the real suspect are unreal, it can be question whereas if there is a doubt that maybe the witness might recognize which pictures are fakes and which one is the real one.
7. Conclusion
All the technologies seen in this work are already advanced and it is amazing how artificial neural networks are now able to generate fake images which look almost indistinguishable from the real world.
However, whenever the possibilities differ from the training data, the results are catastrophic. Even though some images are good, if one is trying to distinguish and remember faces, every detail is important.
Also, trying to create my own GAN has shown me that this type of technology only exists in the realm of those who possess powerful hardware. Any individual that is trying to achieve similar results as those found in scientific papers, may need to invest in cloud solutions to obtain satisfactory results.
Finally, I do not think this technology is ready to be used as it is, at least in the context that was given for this thesis. I do think that a GAN combined with a user capable of editing the fake photos to remove any imperfection, may create a better tool for police investigation.
Bibliography
BARREIRO LINDO, Flavio, 2018. Interprétation d’images basée sur la technologie des
réseaux de neurones. 2 July 2018.
BHATTARAI, Saugat, 2018. What is Activation Functions in Neural Network (NN)? A Tech Blog [online]. 20 June 2018. [Viewed 30 June 2020]. Available from: https://saugatbhattarai.com.np/what-is-activation-functions-in-neural-network-nn/ DOSHI, Sanket, 2019. Convolutional Neural Network: Learn And Apply. Medium [online].
31 March 2019. [Viewed 5 July 2020]. Available from:
https://medium.com/@sdoshi579/convolutional-neural-network-learn-and-apply-3dac9acfe2b6
Generated Photos | Unique, worry-free model photos, [no date]. [online]. [Viewed 16 June 2020]. Available from: https://icons8.com GOODFELLOW, Ian J., POUGET-ABADIE, Jean, MIRZA, Mehdi, XU, Bing, WARDE-FARLEY, David, OZAIR, Sherjil, COURVILLE, Aaron and BENGIO, Yoshua, 2014. Generative Adversarial Networks. [online]. 10 June 2014. [Viewed 23 April 2020].
Available from: https://arxiv.org/abs/1406.2661v1
GRACCI, Fiorenza, 2017. Comment les neurones font-ils fonctionner notre cerveau ? - Science & Vie. [online]. 4 December 2017. [Viewed 29 March 2020]. Available from: https://www.science-et-vie.com/questions-reponses/comment-les-neurones-font-ils-fonctionner-notre-cerveau-10079
GUAN, Shaobo, 2018. Generating custom photo-realistic faces using AI. Medium [online]. 26 October 2018. [Viewed 9 March 2020]. Available from: https://blog.insightdatascience.com/generating-custom-photo-realistic-faces-using-ai-d170b1b59255
HELLER, Martin, 2019. What is Keras? The deep neural network API explained | InfoWorld. [online]. 28 January 2019. [Viewed 23 June 2020]. Available from: https://www.infoworld.com/article/3336192/what-is-keras-the-deep-neural-network-api-explained.html
KAHNG, Minsuk, THORAT, Nikhil, CHAU, Polo, VIÉGAS, Fernanda and WATTENBERG, Martin, 2019. GAN Lab: Play with Generative Adversarial Networks in Your Browser! [online]. January 2019. [Viewed 19 June 2020]. Available from: https://poloclub.github.io/ganlab/
KALIN, Josh, 2018. Generative Adversarial Networks Cookbook : Over 100 recipes to build generative models using Python, TensorFlow, and Keras. Packt. ISBN 978-1-78913-990-7.
KANG, Nahua, 2019. Multi-Layer Neural Networks with Sigmoid Function— Deep Learning for Rookies (2). Medium [online]. 4 February 2019. [Viewed 5 July 2020]. Available from: https://towardsdatascience.com/multi-layer-neural-networks-with-sigmoid-function-deep-learning-for-rookies-2-bf464f09eb7f
KARRAS, Tero, AILA, Timo, LAINE, Samuli and LEHTINEN, Jaakko, 2018. tkarras/progressive_growing_of_gans [online]. Python. [Viewed 23 April 2020]. Available from: https://github.com/tkarras/progressive_growing_of_gans KARRAS, Tero, LAINE, Samuli and AILA, Timo, 2018. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv:1812.04948 [cs, stat] [online]. 12 December 2018. [Viewed 24 October 2019]. Available from: http://arxiv.org/abs/1812.04948
KARRAS, Tero, LAINE, Samuli, AITTALA, Miika, HELLSTEN, Janne, JAAKKO LEHTINEN and AILA, Timo, 2020. NVlabs/stylegan2 [online]. Python. NVIDIA Research Projects. [Viewed 22 April 2020]. Available from: https://github.com/NVlabs/stylegan2 LOISEAU, Jean-Christophe B., 2019. Rosenblatt’s perceptron, the very first neural network. mc.ai [online]. 11 March 2019. [Viewed 17 April 2020]. Available from: https://mc.ai/rosenblatts-perceptron-the-very-first-neural-network/
LU, Lu, SHIN, Yeonjong, SU, Yanhui and KARNIADAKIS, George Em, 2019. Dying ReLU and Initialization: Theory and Numerical Examples. arXiv:1903.06733 [cs, math, stat] [online]. 12 November 2019. [Viewed 5 July 2020]. Available from: http://arxiv.org/abs/1903.06733
LUM, Kristian and ISAAC, William, 2016. To predict and serve? Significance. 2016. Vol. 13, no. 5, p. 14–19. DOI 10.1111/j.1740-9713.2016.00960.x.
MALTAROLLO, Vinícius Gonçalves, HONÓRIO, Káthia Maria and SILVA, Albérico Borges Ferreira da, 2013. Applications of Artificial Neural Networks in Chemical Problems. Artificial Neural Networks - Architectures and Applications [online]. 16 January 2013. [Viewed 9 March 2020]. DOI 10.5772/51275. Available from:
https://www.intechopen.com/books/artificial-neural-networks-architectures-and-applications/applications-of-artificial-neural-networks-in-chemical-problems/
Neural style transfer | TensorFlow Core, 2020. TensorFlow [online].
[Viewed 23 June 2020]. Available from:
PRABHU, 2019. Understanding of Convolutional Neural Network (CNN) — Deep Learning. Medium [online]. 21 November 2019. [Viewed 5 July 2020]. Available from: https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
SAHA, Sumit, 2018. A Comprehensive Guide to Convolutional Neural Networks — the ELI5 way. Medium [online]. 17 December 2018. [Viewed 5 July 2020]. Available from:
https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
SHARMA, Sagar, 2017. Activation Functions in Neural Networks. Medium [online]. 6
September 2017. [Viewed 30 June 2020]. Available from:
https://towardsdatascience.com/activation-functions-neural-networks-1cbd9f8d91d6 SHPERBER, Gidi, 2019. Background removal with deep learning. Medium [online]. 26
May 2019. [Viewed 6 July 2020]. Available from:
https://towardsdatascience.com/background-removal-with-deep-learning-c4f2104b3157 SIVARAJKUMAR, Sonish, 2019. ReLU — Most popular Activation Function for Deep Neural Networks. Medium [online]. 15 May 2019. [Viewed 30 June 2020]. Available from: https://medium.com/@sonish.sivarajkumar/relu-most-popular-activation-function-for-deep-neural-networks-10160af37dda
TIU, Ekin, 2020. Understanding Latent Space in Machine Learning. Medium [online]. 4
February 2020. [Viewed 2 July 2020]. Available from:
https://towardsdatascience.com/understanding-latent-space-in-machine-learning-de5a7c687d8d
YEGULALP, Serdar, 2019. What is TensorFlow? The machine learning library explained | InfoWorld. [online]. 18 June 2019. [Viewed 23 June 2020]. Available from: https://www.infoworld.com/article/3278008/what-is-tensorflow-the-machine-learning-library-explained.html
Appendix 1: Scientific Police of Geneva
1.
Domaines d’action:
Groupe coordination judiciaire :
Le groupe de coordination judiciaire s'occupe du traitement systématique des données contenues dans les rapports, déclarations, enregistrements dans les bases de données de la police dans les domaines liés à la délinquance sérielle[1]. Le processus de veille sous-jacent à
l'activité de la coordination judiciaire lui permet de disposer d'une vue d'ensemble et de fournir un appui aux entités partenaires dans l'identification de phénomènes, l'établissement de séries et le suivi opérationnel quotidien.
La coordination judiciaire est également l'entité de liaison genevoise avec ses homologues du concordat RBT, dans le cadre du CICOP. A cet effet, elle exploite et alimente la base de données partagée PICAR[2], ce qui lui permet de disposer d'informations consolidées afin de pouvoir
procéder à des analyses/recherches tant sur les évènements du territoire genevois que ceux survenus dans les cantons partenaires[3].
Groupe analyse criminelle opérationnelle :
Le groupe d'analyse criminelle opérationnelle intervient sur requête dans le cadre d'opérations/enquêtes particulières. Il agit comme entité de soutien à l'enquête lorsque le volume de données à traiter devient important, que le cas présente une certaine complexité ou que des analyses spécifiques doivent être effectuées.
A cet effet, le groupe exploite tous les outils communément utilisés dans le domaine[4] et peut
également fournir un appui dans l'utilisation de ceux-ci par les personnes formées ACO I ou II dans les brigades.
Finalement, l'équipe de l'analyse criminelle opérationnelle assure une activité de veille scientifique et de développement tant pour l'interne de la brigade que pour les brigades partenaires.
2.
Tâches particulières :
Groupe coordination judiciaire :
assure la gestion de la base de données PICAR au niveau genevois o trie, saisie, codifie les événements quotidiennement
• effectue spontanément ou sur demande des recherches dans le but de mettre en évidence les phénomènes ou séries de délits
• établi des livrables à destination des services partenaires : o planche photographique
o flash
o synthèse hebdomadaire o rapport de renseignement
o diffusion de personnes recherchées o tableaux de bord thématiques
• assure les échanges et centralise le renseignement criminel avec l'ensemble des services partenaires à l'interne comme à l'externe de la police genevoise
Groupe analyse criminelle opérationnelle :
sur demande, traite, structure et analyse les données liées à une enquête particulière • développe des fichiers d'enquêtes sous la forme de bases de données
• assure la veille technologique et propose de nouvelles méthodes de travail ou l'acquisition de nouveaux outils
• appuie les analystes de niveau I et II dans l'utilisation de base des outils d'analyse criminelle opérationnelle
• participe comme formateurs aux cours donnés dans le domaine, tant en interne qu'à l'externe de la PJ
[1] Principalement : Cambriolages, Vols, Brigandages, Incendies, Agressions, Cas mœurs [2] Uniquement avec les données relatives à la délinquance sérielle
[3] A l'exception du canton de Berne qui n'a pas encore d'accès à PICAR
[4] Systèmes de gestion de base de données, systèmes d'informations géographiques, outils de