DNA as a Programmable Material: de novo Gene Synthesis and Error Correction
bySamuel James Hwang S.B., Mechanical Engineering
Massachusetts Institute of Technology, 2006
Submitted to the Department of Materials Science and Engineering in Partial Fulfillment of the Requirements for the Degree of
Master of Science in Materials Science and Engineering
at the MASACHUT
OF TEHNoOG.S Massachusetts Institute of Technology
JUN
16
2008
June 2008
© 2008 Massachusetts Institute of Technology. All rights reserved.
LI.
Signature of Author:
Department of Materials Science and Engineering May 23, 2008 Certified by:
Certified by: Joseph Jacobson Associate Professor of Media Arts and Sciences and Mechanical Engineering i ,Thesis Supervisor
Certified by: VF
Francesco Stellacci Associate Professor of Materials Science and Engineering TheAs Reader in Materials Science and Engineering Accepted by:
Samuel M. Allen POSCO Professor of Physical Metallurgy Chair, Departmental Committee on Graduate Students
DNA as a Programmable Material: de novo Gene Synthesis and Error Correction
bySamuel James Hwang
Submitted to the Department of Materials Science and Engineering on May 23, 2008 in Partial Fulfillment of the
Requirements for the Degree of Master of Science in Materials Science and Engineering
ABSTRACT
Deoxyribonucleic acid (DNA), the polymeric molecule that carries the genetic code of all living organisms, is arguably one of the most programmable assembly materials available to chemists, biologists, and materials scientists. Scientists have used DNA to build many different structures for various applications in disparate areas of research from traditional biological applications to more recent non-biological applications.
Although DNA isn't typically thought of as an assembly material by people not doing research in the area, the availability of decreasing cost synthetic oligonucleotides has led to advances in gene fabrication technology which in turn has enabled synthetic biology to flourish.
Using DNA as a building material for small and large constructs of DNA is reliant on having effective gene synthesis techniques. Construction of synthetic DNA is limited by errors that pervade the final product. To address this problem, effective error correction methods are pivotal. Having extremely robust gene synthesis and error correction techniques will allow researchers to generate very large scale constructs potentially necessary in applications such as genome re-engineering.
Thesis Supervisor: Joseph Jacobson
3-4 i. 1.1 1.2 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 3. 3.1 3.2 3.3 4. 4.1 Cloning 25 4.2 Protein Expression/Purification 25
4.3 Thermophilic Proteins (Thermus aquaticus "Taq MutS") 26 4.4 Hyper-thermophilic Proteins (Thermotoga maritima "Tma MutS" and Aquifex aeolicus
"Aae MutS") 26
4.5 Mutant Versions of Proteins
(Tma Mutant MutS "TmM" and Aae Mutant MutS "AmM") 27
5. CHARACTERIZING PROTEINS
Gel Electrophoresis
Circular Dichroism (CD) Spectroscopy MF20
Table of Contents
TABLE OF CONTENTS
INTRODUCTION 5
Deoxyribonucleic acid (DNA) 5
DNA as a Programmable Material 6
GENE SYNTHESIS 9
Parsing target DNA sequence 10
Choice of oligonucleotide vendor 11
Choice of oligonucleotide length 13
Choice of polymerase 14
One-Step Gene Synthesis: Polymerase Construction Assembly (One-Step PCA) 15 Two-Step Gene Synthesis: Polymerase Construction Assembly (Two-Step PCA) 17 One-Step PCA vs. Two-Step PCA (Advantages and Disadvantages) 19
ERROR CORRECTION IN GENE SYNTHESIS 20
Introduction to Error Correction 20
In-vivo vs. In-vitro Error Correction 22
Our methods of error correction 23
ENGINEERING PROTEINS 24
5.1
5.2 5.3
6. RE. COLI
1. Introduction
1.1 Deoxyribonucleic acid (DNA)
The elucidation of the structure of DNA in a Nature article in 1953 by Watson and Crick is without a doubt the most important biological discovery of the last 100 years.
Deoxyribonucleic acid (DNA), the polymeric molecule that carries the genetic code of all living organisms, is arguably one of the most programmable assembly materials available to chemists, biologists, and materials scientists. Similar to how the computer code in a piece of
software provides instructions for the computer to run specific tasks, DNA contains the
instructions that the body needs in order to run specific tasks to construct essential components of cells such as genes, RNA, and proteins. Scientists have used DNA as a basic material to build many different structures for various applications in disparate areas of research.
Chemically, DNA is composed of units called nucleotides, chemical compounds consisting of a nitrogenous base, a sugar, and one or more phosphate groups (See Figure 1). There are four nitrogenous bases (cytosine, guanine, adenine, and thymine) attached to the sugar
of the alternating sequence of sugars and phosphates in the sugar-phosphate backbone [1]. It is the sequence of these bases along the sugar-phosphate backbone that encodes information about
an organism. Further, it is the DNA sequence that makes each living organism unique from another organism. The sugar in DNA is 2-deoxyribose, a pentose (five-carbon) sugar that are joined by phosphate groups that form phosphodiester bonds between the third and fifth carbon atoms of adjacent sugar rings [2].
In living organisms, DNA exists as two long strands, composed of tightly-associated pairs of molecules, entwined in the shape of a double helix. Each of the four bases (C, G, A, and T) form hydrogen bonds to each other, with C bonding only to G and A bonding only to T.
The double helical structure of DNA with complementary base pairs makes the replication of DNA fairly straightforward. DNA replication, the process of copying a single double-stranded piece of DNA to form two double-stranded pieces, is pivotal in living organisms as this is how a piece of DNA in a cell gets copied into another cell as cell division occurs [2].
Deoxynbonudeic
Acid
(DNA)
Nuc~eotidesECJ~80148
0I
I I Kr"4W
F1*C
!J-
.ann Sm .... a W.. , Ct cyrnk[~II
A'cmnNK
2H
H(b~ A' ________ I.ET
Thyn
0 KkS'oOH In A'f'I
rjana mam a*r ~ir JiFigure 1. DNA is a polymeric molecule that has 4 bases (cytosine, guanine, adenine, and
thymine) and a sugar-phosphate backbone (The Science Creative Quarterly) [3].
1.2 DNA as a programmable material
DNA is a material that can be incorporated into both biological and non-biological
applications. Over the years, there has been increasing interest in using biomaterials, DNA being the most prominent of these, in nanotechnology applications. DNA can be synthesized and
6
4t~r
41 n u rY=Yla*~ I I ·~1 tjSI=~il ~ H~dralgkbnir ~I * ,rrtar;~
manipulated by physical and chemical methods to build various materials at the nanoscale. Potential applications include assembly of molecular electronic devices, nanoscale robotics, DNA-based computation, DNA origami, and DNA circuits [4].
Applications using DNA as a material can be divided into two general categories: using DNA to build molecular structures and using DNA to improve material properties.
An example of using DNA to build molecular structures is a technology developed at the California Institute of Technology, known as DNA origami. In a paper published in Nature in 2006, Rothemund used numerous short single strands of DNA to direct the folding of a long, single strand of DNA into desired shapes that are roughly 100 nm in diameter and have a spatial resolution of about 6 nm [5]. The researchers call these molecules 'scaffolded DNA origami' and have assembled six different shapes, such as squares, triangles, five-pointed stars, and smiley faces (See Figure 2). One application of the "DNA origami" could be the creation of a
'nanobreadboard' to which diverse electrical, chemical, and biological components could be added to make DNA-based components for various applications [5].
100 nm
I
I
Figure 2. Using DNA to build molecular structures (DNA origami). (Figure from Rothemund) [5].
As shown in Figure 3, an example of using DNA to improve material properties is described in a commentary published in Nature Photonics in 2006 by Steckl, from the University
of Cincinnati, which describes incorporating DNA into OLEDs (organic LEDs) as an electron-blocking layer (EBL) to help boost light emission, resulting in "BioLEDs" that are as much as ten times brighter than their OLED counterparts [4].
Figure 3. Using DNA to improve material properties (DNA Photonics).
(Figure from Steckl) [4].
Even with the cost of synthetic oligonucleotides and synthetic genes continuing to decrease and the increasing number of companies working on providing customers with faster turnaround times for "on-demand" oligonucleotide and gene synthesis, there are still several barriers to many applications that require large constructs of DNA. Although all of the above uses for DNA as a programmable material are important, they are beyond the scope of this work. This document focuses on current gene synthesis methods, improved error correction methods, tools for characterizing our error correction tools, and a look into the first step of a genome re-engineering project.
2.
Gene Synthesis
The ability to make DNA de novo, without any starting template material, is crucial to researchers working on constructing and manipulating DNA into DNA-based structures. The ultimate goal of gene synthesis is the in vitro synthesis of any given target gene sequence(s) in the absence of a template. The ability to construct a piece of DNA of arbitrary length and sequence quickly, efficiently, and cost-effectively, will be pivotal to all of the above-mentioned areas of research that use DNA as a biomaterial. There are commercial sources of synthetic DNA that are becoming more economical (less than $1 per base with a turnaround time of 2-4 weeks depending on construct size), however, researchers that want to make large pieces of DNA or make many DNA constructs will benefit by having their own gene synthesis technologies on hand.
In the field of synthetic biology, researchers are developing increasingly large and more complex synthetic genes. Recently, a team of researchers working under J. Craig Venter created the first synthetic bacterial genome named Mycoplasma genitalium JCVI-1.0. It is currently the largest manmade DNA structure to date, being 582,970 DNA base pairs in size [6]. Although the Venter team was able to build this genome, it took a significant amount of effort and expense. Having improved gene synthesis technology will allow researchers to build more complex DNA constructs cheaper, faster, and more robustly.
The techniques for producing designed synthetic genes in the laboratory were introduced over 35 years ago and have been advancing ever since [7]. Many protocols for gene synthesis have been presented in the literature, and many variations on protocols have been introduced since then. There are a number of variables to consider when performing a gene synthesis reaction. These variables will affect the error rate of a given gene synthesis protocol and will
ultimately affect the ability to synthesize a perfect target DNA sequence. We have collected and analyzed data on the following variables: sequence parsing, choice of vendor for
oligonucleotides, oligo length, choice of polymerase, and assembly protocol. Considering these factors and choosing the best variables will allow a researcher to build more robust DNA constructs.
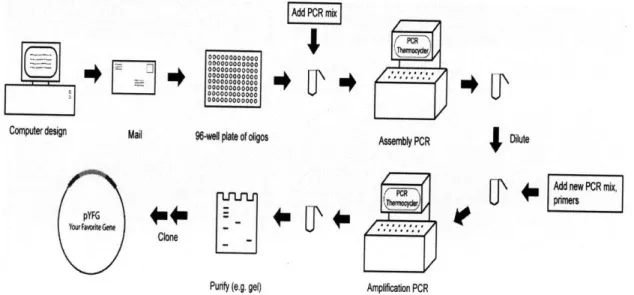
As summarized in Figure 4, a typical gene synthesis protocol we follow involves parsing a target DNA sequence into oligonucleotides between 40-50 base pairs, performing a two-step polymerase chain reaction process to assemble and amplify the target DNA constructs, purifying the DNA construct using gel electrophoresis and then cloning the gene into a vector.
Add PCR mix
'I
000000000000
0D00D0000000
Iooooooooodoooooooooooooo00Q00q000000
0000000000003 `
,ooooooooooo
Compute
design Mail
96W
plateoooooooos
Computer design Mail :96-well plate of oligos
YOU
Assembly PCR Dilute
4 Add
new PCR mix,
0
pners
I
pYFG
40140c
ir F nite Gm
Clone
Purify (e.g. gel) Amplification PCR
Figure 4. General Overview of steps to carry out gene synthesis.
2.1 Parsing target DNA sequence
For our gene assembly protocols, we have used software supported by the NIH, called DNAWorks (http://molbio.info.nih.gov/dnaworks/) to parse our target DNA sequences [18].
Generally we have parsed our target DNA sequences into a set of overlapping oligonucleotides (-40-70 bases in length).
DNAWorks uses an algorithm to optimize for certain parameters including consistent melting temperature, no hairpin formation, no self-annealing, no primer-dimerization, codon frequency in host organisms, and allowance of gaps and overlaps between adjacent
oligonucleotides of the same strand.
2.2 Choice of oligonucleotide vendor
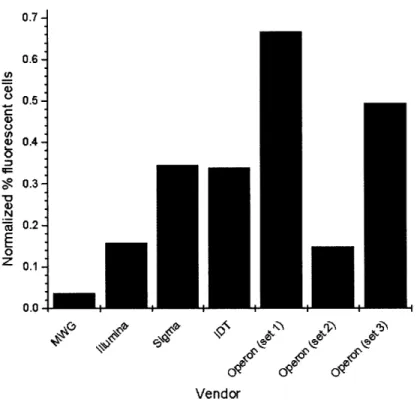
There are many different commercial vendors of oligonucleotides that are currently available. Choosing one vendor over another is an important decision for researchers as different vendors provide synthetic oligos with different error rates (See Figure 6). As one can imagine, errors in a starting oligonucleotide pool will affect the final number of errors present in the resultant synthesized gene product.
Oligonucleotide synthesis is a process that uses organic chemistry to add
phosphoramidite monomers into a chain using chemical synthesis. Different oligo vendors use slight variations of the chemical oligo synthesis process, resulting in different error rates. A typical chemical oligo synthesis involves four steps: de-blocking (detritylation), base
condensation (coupling), capping, and oxidation. In the de-blocking step, DMT is removed with an acid and washed out, resulting in a free 5' hydroxyl group on the first base (See Figure 5). The base condensation step involves activating a phosphoramidite nucleotide and adding it to the previous base by de-protecting the 5' OH of the first base and the phosphate of the second base. The capping step involves adding a protective group in the form of acetic anhydride and 1-methylimidazole which reacts with the free 5' OH groups via acetylation. After excess reagents
are washed out, the final step, oxidation, is performed. Oxidation involves stabilizing the
phosphite linkage between the first and second base by making the phosphate group pentavalent.
si' 0 CH3-C-0 0-S 5. Capping BB 8 HO 0- - OH Final: CleavagweDeprotoction B1' DMT-0 0-0 1. Deblocking
0
4
T-04 OR-- -DMTr-0 0p-P-0 -HO O-@ ation CH3-C-0•p 3. Capping 2. Coupling -P.-N(IPr)2 OR CQBOFigure 5. Steps of Oligonucleotide synthesis. (Figure from E-Oligos) [8].
The primary error in chemical oligo synthesis results from a failure to add a new
phophoramidite monomer to the growing chain. This results in a deletion which will be capped with an acetyl group, preventing further additions to the chain. These truncated products do not add any errors to the final product in gene synthesis. However, if the acetylation step fails or if there is a failure in the de-blocking phase, the oligo construct ends up with a deletion error. This results in the incorporation of a deletion error in the final target DNA construct.
0.7- 0.6-> 0.5-r) (D 0.4-• 0.3-N • 0.2- 0.1-0.0 - -W +- + Vendor
Figure 6. Flow Cytometry data showing the fidelity of various commercial vendors of
oligonucleotides.
2.3 Choice of oligonucleotide length
As shown by Figure 7, oligo length is another important variable to consider when performing a gene synthesis reaction. Because each cycle of oligo synthesis exposes the growing chain to the harsh chemicals used during the chemical process, the bases incorporated earlier in the process have a higher likelihood of being damaged. Base damage in oligos will lead to errors in the final product as these damaged bases will get incorporated into the final product during gene synthesis.
·I . ·
.242 - I-a .215-.0 =D C (nV
a
Q : C_ .192-0 ) W (.159-L_
0 LW w -I- i4~42mer 50mer 60m er 90mer
Oligo Length
Figure 7. Error rate (in errors per thousand base pairs) comparing error rates using various size oligos on final EGFP gene construct.
2.4 Choice ofpolymerase
We found polymerase choice to be important with the biggest factor being the choice of fidelity (proofreading) versus non-fidelity polymerase (See Figure 8). Using a high-fidelity polymerase such as PfuTurbo from Stratagene made negligible contributions to the overall error rate of gene synthesis whereas using a non-high-fidelity polymerase such as Taq polymerase contributed substantially to the final error rate.
Our analysis shows that high-fidelity polymerases give similar performance to each other and that non-proofreading polymerases give similar poor performance to each other.
In
-high fidelity polymerase
t
M Flow cytometry FII ISequencing I Polymerases 700 600 500 400 300 200 100 0Figure 8. Flow cytometry and sequencing data comparing error rate caused by various polymerases. Note: Values for "Titanium Taq" are so low they are not visible on this scale.
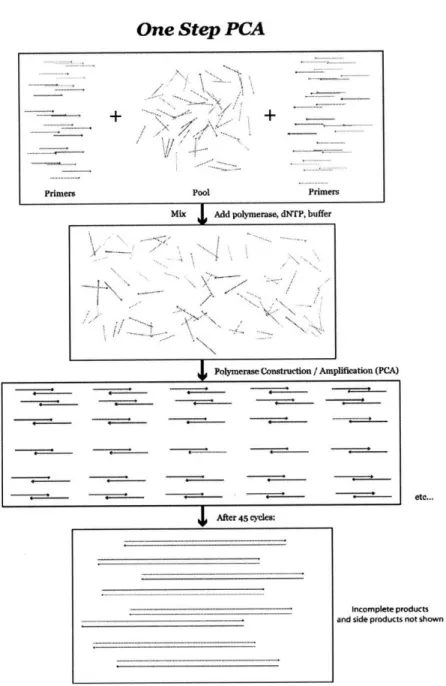
2.5 One-Step Gene Synthesis: Polymerase Construction Assembly (One-Step PCA)
One-Step PCA is a process of gene synthesis that involves the use of one step of thermocycled PCR (See Figure 9). The process includes mixing 300 nM of each of the outer amplification oligonucleotides and an amount of the entire pool of oligonucleotides ranging in concentration between 0-50 nM per oligo. After adding dNTPs to the mixture to a concentration of 1 mM total (250 giM each) we use a manufacturer-recommended amount of polymerase and polymerase reaction buffer (in a final IX concentration).
Depending on the size of the product one is trying to build, the reaction can then be thermocycled for 40-45 cycles of denaturation, annealing, and extension. The user should follow the manufacturer-recommended temperature and time for each step as recommended by the polymerase manufacturer.
After the thermocycling is complete, the user can view the product by use of gel electrophoresis.
One Step PCA
... ... .... ... ... . . . .
...
.
.
+ + __...
-
---
---
·
·
... • " • , ... •I • •" " ... .... ... , -- ,.U ;= . I... ... ... ... Po... ... ...Primers Pool Primers
Mix Add polymerase, dNTP, buffer
SPolymerase Construction / Amplification (PCA)
- e--
--- After 45 cycles: etc...
Incomplete products and side products not shown
Figure 9. One-Step Polymerase Construction Assembly (PCA). 16 " "\ ... ," .. . · .! •.--i .1 . .,,. W K. ...-... .~~. 1~~... .. ... ... ... ... ... ... .. ... .. ... ... .. .. .. .. .. .. ...
2.6 Two-Step Gene Synthesis: Polymerase Construction Assembly (Two-Step PCA)
Two-Step PCA is a process of gene synthesis involving two distinct PCR steps: assembly PCR and amplification PCR (See Figure 10).
The first step of this two-step cycle is the assembly PCR reaction. This is set up (in a total volume of 20 giL) with an oligo pool concentration of about 15 nM each. After adding
dNTPS to a concentration of 1 mM total (250 gM each), the solution is mixed together with manufacturer-recommended amount of polymerase and polymerase reaction buffer (in a final 1X
concentration). The second step, the amplification PCR reaction is set up (in a total volume of 50 gLL) with a 1:20 dilution of the assembly PCR material, 300 nM of each of the outer
amplification oligonucleotides, and 0.8 tM total dNTP (200 nM each). Again, manufacturer-recommended amount of polymerase and polymerase reaction buffer (in a final 1X
concentration) are mixed into this reaction mixture.
Both the assembly and amplification steps are thermocycled for 30 cycles using manufacturer-recommended temperature and times for each cycle.
As in the One-Step PCA, after the thermocycling is complete, the user can view the product by use of gel electrophoresis.
Two Step PCA
etc...
Incomplete products and side products not shown
Figure 10. Two-Step Polymerase Construction / Assembly (PCA).
As mentioned previously, various choices one makes with regards to the several variables lead to differences in the error rate of the final product. In order to make gene synthesis of any target gene a reliable, cost-effective, and robust process, the availability of effective error correction methods is pivotal.
2.7 One-Step PCA vs. Two-Step PCA (Advantages and Disadvantages)
One-Step PCA has the advantage of reduced sample handling and reduced reaction time (one PCR step rather than two) but in our experience, we have found that One-Step PCA is effective for short gene products (<500 bp) whereas it does not build good product for larger constructs. Two-Step PCA, the preferred method for building large constructs, is effective at making constructs larger than 500 bases. Figure 11 shows a side by side comparison of One-Step PCA vs. Two-One-Step PCA. When building the 264 bp product, the two methods produce specific, robust product. However, when building the 1075 bp product, and even more so the 2406 bp product, Two-Step PCA clearly produces more specific, robust product.
Figure 11. One-Step PCA vs. Two-Step PCA for constructs of various sizes with Phusion polymerase. Target DNA constructs of length 264 bp (12 oligos), 475 bp (22 oligos), 682 bp (32 oligos), and 993 bp (42 oligos) from the EGFP gene and of constructs length 545 bp (20 oligos), 1075 bp (38 oligos), 1621 bp (56 oligos), 2163 bp (74 oligos), and 2406 bp (90 oligos) from the Tma MutS gene were assembled using either One-Step PCA (with 10 nM each oligo pool concentration) or Two-Step PCA using Phusion polymerase (Finnzymes). Robustness of
assembly was assessed. 4 uL of each PCA product was run on the 1% agarose gel alongside 2 uL kb ladder (Stratagene). All images were enhanced for contrast with the same parameter [9].
3.
Error Correction in Gene Synthesis
3.1 Introduction to error correctionAs mentioned in the previous section on gene synthesis, there are many variables that can affect the error rate of a given gene synthesis protocol.
10000
1000
100
10
0 1000 2000 3000 4000 5000 6000
synthesis target length (bp)
7000 8000 9000 10000
Figure 12. Gene fabrication of long targets requires improved error rates. The graph shows the number of clones that must be sequenced to obtain at least one clone that is error free (95% Confidence Interval) [9]. The dotted line shows that by sequencing 5 clones one can build larger constructs as error rates improve.
Error correction is extremely important in gene synthesis as the error rate of a gene fabrication process directly affects its usability to synthesize DNA for its various applications. Figure 12 shows the number of clones that need to be sequenced to build a target DNA sequence
given various error rates (1 in 100, 1 in 600, 1 in 1500, 1 in 4000, and 1 in 10000). Because sequencing is a time-intensive and expensive process, it is unrealistic to sequence hundreds or even tens of clones for building any given gene construct.
The method of error correction we use employs the MutS protein as an error recognition tool. After the MutS binds to the error, we employ gel electrophoresis to separate the MutS-bound DNA from the non-MutS-MutS-bound DNA.
Figure 13. Principle steps in the construction of synthetic genes employing MutS for error-reduction. The pie chart indicates the approximate amount of time consumed by each step (in hours), with a red arrow indicating the order of operations. The most time-consuming steps in this process are often oligonucleotide synthesis and DNA sequencing (including plasmid
production). The 24+ and 48+ hours indicated for each of these represent lower bounds on these processes, possible if performed with immediate access to the appropriate equipment. If these steps are performed by outside providers, 3-5 days are typical of each step. Box 1: gene segments are synthesized and amplified using conventional PCR protocols. The resulting products are dissociated and re-annealed so that errors are present as DNAheteroduplexes (mismatches). Box 2: MutS protein is mixed with this pool of molecules and binds to mismatches. The error-enriched (MutS-bound) fraction is resolved from the error-depleted fraction by electrophoresis. Box 3: The error-depleted segments are assembled into the desired gene and amplified by PCR prior to cloning [9].
Figure 13 sums up how good error correction techniques can save researchers both time and money. Cloning, preparing samples, and sequencing take up almost two-thirds of the total process time in gene fabrication. Figure 13 shows the process of gene fabrication as a time pie chart, illustrating the point that by more accurately synthesizing gene targets, one can not only cut down on the number of clones necessary to get one perfect copy, but also avoid the need for any time-consuming additional steps such as site-directed mutagenesis.
3.2 In vivo vs. In vitro MutS Error Correction
MutS is a protein with affinity for binding to DNA duplexes. In vivo, MutS is part of a natural mismatch repair mechanism involving MutL, MutH, and MutS. This repair mechanism works by having MutS bind to a mismatch and then having MutL and MutH bind to the MutS-DNA complex. MutH nicks the unmethylated strand and a helicase and an exonuclease digest part of the top strand until the error is degraded. A DNA polymerase and ligase then fill in the gap, resulting in a corrected strand [10]. Figure 14 summarizes the steps involved in both in vivo and in vitro MutS error correction.
The different types of mismatches that can occur are the following: AA, CC, GG, TT, AC, AG, TC, TG, insertions, and deletions. Different MutS proteins have different binding affinities for these various error types. We have done further work to characterize which of these error types are best bound by our MutS species.
Figure 14. In vivo DNA mismatch repair by MutS (left side) and In vitro DNA mismatch repair
by MutS (right side) [10].
3.3 Our methods of error correction
The version of in vitro error correction we use employs MutS to bind errors in a pool of DNA constructs having both error and non-error pieces. After MutS is bound to DNA constructs with errors, we employ gel electrophoresis to separate the DNA with errors from the presumably
error-free DNA pieces. We then use PCR to amplify the error-free pieces of DNA. The final product will now have significantly less errors than before the error correction protocol.
The method developed by Dr. Peter Carr and Jason Park of our lab reported in Nucleic
Acids Research in 2004 demonstrates a 15-fold reduction in error rates to 1 in 10,000 base pairs.
The method was conducted by synthesizing fragments of EGFP (enhanced green fluorescent protein) and then thermally denaturing and re-annealing to re-assort errors and create error heterodimers. MutS was used to selectively bind error-containing DNA and then polyacrylamide
gel electrophoresis was used to separate MutS-filtered DNA from non-MutS-bound DNA (See Figure 15).
+ MutS
- MutS
I
Figure 15. MutS pull-down filter. Lane 1: kb ladder. Lanes 2,3,4,5: -300mer pieces of GFP
(993 bp), treated with MutS. Lanes 6,7,8,9: Same as lanes 2,3,4,5, except without MutS treatment [9].
4.
Engineering Proteins
Dr. Carr and Jason Park initially used a commercially available version of Taq MutS (from Epicentre) to do the MutS-based gel filtration. However, they used this error correction
protocol to build our own version of Taq MutS. In order to perform error correction in different applications, we decided to engineer and build two new MutS proteins: Thermotoga maritima (Tma) and Aquifex aeolicus (Aae).
4.1 Cloning
Molecular cloning refers to the in vitro process of isolating a DNA sequence and obtaining multiple copies of the DNA sequence. We use cloning to amplify DNA fragments containing genes and we use cloning vectors for protein expression.
We use the plasmid vector pDONR221 with the Clonase II (Invitrogen) recombination system for low-background cloning of gene targets such as GFP (green fluorescent protein). We use the T71ac-promoter based pET system (Novagen) of vectors for protein expression.
Different vectors allow us to add different features during protein expression. For example, we could use the pET-44 cloning vector to have a NusTag fused to our protein of interest for
enhanced protein solubility. We use restriction enzymes from New England BioLabs and we use one of the following chemically competent cell lines from Invitrogen: DH5a MAX Efficiency, DH5a Library Efficiency, and BL21 (DE3).
4.2 Protein expression/purification
We use isopropyl-beta-D-thiogalactopyranoside (IPTG)-inducible T71ac systems for protein expression. Our standard procedure for protein expression involves an overnight culture growth at 370C and 300 rpm from a colony pick followed by 1:100 dilution into fresh LB with
antibiotic and re-growth at 370C and 300 rpm to mid-log phase (-0.6 OD600). The culture is induced with 1 mM IPTG and incubated at 370C and 300 rpm for 2 hours before harvesting the
cells in a centrifuge. We use either sonication or BugBuster reagent with Benzonase nuclease (Novagen) to lyse cells.
We use an AKTApurifier (GE Healthcare) system to automate much of our protein purification work. We use high-flow columns for affinity, ion exchange, and other types of column protein purification.
4.3 Thermophilic Proteins (Thermus aquaticus "Taq MutS")
Thermus aquaticus is a species of bacterium that can tolerate high temperatures, one of
several thermophilic bacteria that belong to the Deinococcus-Thermus group. It is the source of the heat-resistant enzyme Taq DNA Polymerase, one of the most important enzymes in
molecular biology because of its use in the polymerase chain reaction (PCR) DNA amplification technique. Taq thrives at 700C (160OF), but can survive at temperatures of 500C to 800C (1200F to 1750F) [11 ]. As mentioned above, Dr. Carr and Jason Park employed the Taq MutS for their published result in Nucleic Acids Research in 2004 to get the best error rate yet to be published.
4.4 Hyper-thermophilic Proteins (Thermotoga maritima "Tma MutS'" and Aquifex aeolicus "Aae MutS')
Since the Nucleic Acids Research paper published in 2004, we decided to construct the genes for MutS derived from other species to make two additional MutS proteins. Thermotoga
maritima is a rod-shaped bacterium belonging to the order Thermotogales which was originally
isolated from geothermal heated marine sediment in Vulcano, Italy. The organism has an optimum growth temperature of 800C [12].
Aquifex aeolicus is a rod-shaped bacterium discovered near islands north of Sicily. Aquifex aeolicus is one of a handful of species in the Aquificae phylum, an unusual group of
thermophilic bacteria that are thought to be some of the oldest species of bacteria. A. aeolicus grows best in water between 85 to 950C, and can be found near underwater volcanoes or hot
springs [13].
We have tested these two proteins in our standard gel-based error filter protocol, but have not gotten better error rates than the one published in 2004 by our group as of yet. We are currently still working on trying to get better error rates using these proteins and are working on tweaking experimental parameters..
We constructed these two MutS proteins with the idea of potentially making a cocktail of various MutS proteins to use in error correction protocols. From initial tests, we believe that our different MutS proteins have different affinities for binding to different error types.
We have tested and are continuing to work on other error correction applications where having hyper-thermophilic MutS proteins would be useful. One such application is the MSPCR (MutS in PCR) project where we have employed our MutS proteins to keep error-enriched pieces of DNA from being amplified, thus improving the error rate of the final product.
4.5 Mutant Versions of Proteins (Tma Mutant "TmMMutS" and Aae MutS "AmM" Muts)
Because MutS binds ATP and dATP which causes conformational changes in the MutS, making it slide around on DNA, we created "mutant" versions of the Tma and Aae proteins to remove the ATP and dATP-binding sites. We hope that this will make the MutS bind more tightly to errors in DNA, allowing us to get better error rates and allowing us to use it for such applications as MSPCR where we believe the high temperature of the denaturation step will
cause degradation of our Taq MutS protein. We are continuing to work on our various error correction protocols using our new hyper-thermophilic MutS proteins.
5.
Characterizing Proteins
To get more information about our various MutS proteins, we decided to characterize them using various methods that were available to us. Some interesting characteristics of our proteins include: binding affinities for certain mismatches, protein denaturation temperature, and purity of our protein samples.
5.1 Gel Electrophoresis
Gel electrophoresis is a quick and cheap way to analyze DNA or protein samples for size and purity analysis. Larger size DNA and protein constructs move through agarose or
polyacrylamide gels at slower speeds than smaller DNA and protein constructs, so gels can be employed to analyze such samples.
We use two different types of gel electrophoresis in our work: agarose gel electrophoresis and polyacrylamide gel electrophoresis. We employ a 1% agarose gel with 0.5ug/mL ethidium bromide or lX SYBR Safe (Molecular Probes) to analyze PCR products. We use Qiagen Gel Extraction Kits (Qiagen) to extract DNA.
We use polyacrylamide gels to analyze protein and DNA samples. We use precast TBE gradient gels (4% to 12%) (Invitrogen) for DNA analysis and precast Bis-Tris gels (6%)
(Invitrogen) for protein analysis. We use SYBR Gold from Molecular Probes for DNA gel staining and Simply Blue SafeStain from Invitrogen for protein gel staining.
5.2 Circular Dichroism (CD) Spectroscopy
Circular dichroism (CD) spectroscopy measures differences in the absorption of left-handed circularly polarized light versus right-left-handed circularly polarized light which arise due to structural asymmetry in a protein [14].
CD spectroscopy is useful for many measurements for protein characterization. Some of these include: determining whether a protein is folded, comparing the structures of a protein obtained from different sources or comparing structures for different mutants of the same protein, demonstrating comparability of solution conformation after changes in manufacturing processes or formulation, studying the conformational stability of a protein under stress (thermal stability, pH stability, and stability to denaturants), and determining whether protein-protein interactions alter the conformation of protein [14].
We have assessed the thermostability of our three standard MutS proteins (Taq, Tma, and Aae) using circular dichroism spectroscopy. We prepared a sample of protein to be analyzed using the CD by mixing the CD buffer with a protein sample (for a total volume of 400 uL), bringing the concentration of protein to 0. lmg/ml. The CD buffer is a modified Pfu buffer (200mM Tris-HCI (pH 8.8), 20mM MgSO4, 100mM KC1, and 100mM (NH4)2SO4). We took
temperature scans ranging from 25°C to 95"C and then took a scan back down to 25*C. As shown in Figure 16, the observed cooperative unfolding transition temperatures of Taq, Tma, and Aae are approximately 84°C, 87°C, and 95"C, respectively (See Figure 16). Scanning from 95TC back down to 25TC shows that (under these conditions) after our proteins get unfolded, they do not fold back into the same shape they started out from.
MutS in Tris-Based CD Buffer 0.000 6P5 7:5 85 -2.000 ---- ·- · ---·--- · · ... . ...: • . . . i :.. : 4.000.. ...
S-6.000
-- Taq -Tma E -Aae -12.000 . ... ... ..... .... -14.000 -i• Temperature (°C)Figure 16. Temperature Scan (from 250C to 950C and back down to 250C) of three different
MutS samples (Taq, Tma, and Aae) by circular dichroism.
5.3 Fluorescence Correlation Spectroscopy: MF20
Fluorescence correlation spectroscopy (FCS) is a technology that allows scientists to measure the translational diffusion of individual fluorescently-labeled molecules in solutions
[15]. Figure 17 summarizes how FCS works.
(c)
0 5 10 15 20 25 30 Time(d)
4- Fitl FO" 0.016(b)
OBSERVATION VOLUME - FOCAL VOLUME 0.012-0 N 0.008 8 0,004 0.000. Sime IW 0.01 0.1 1 10 100 1000 Correlation Time ¶(ms)Figure 17. (Left) Experimental setup for FCS. (a) A laser beam is first expanded by a telescope
(LI and L2), then focused by a high-NA objective lens (OBJ) on a fluorescent sample (S). The epi-fluorescence is collected by the same objective, reflected by a dichroic mirror (DM), focused by a tube lens (TL), filtered (F), and passed through a confocal aperture (P) onto the detector
(DET). (b) Magnified focal volume (green) within which the sample particles (black circles) are illuminated. The focal volume is the distribution of laser illumination at the focus of the
objective. On the other hand, the observation volume, contained within the focal volume, is the region in space where fluorescent molecules are both excited and detected.
(Right) (c) A typical fluorescence signal, as a function of time, measured for rhodamine green (RG) with excitation wavelength lx=488 nm. (d) Portion of same signal in (c), binned, with expanded time axis and average fluorescence Fbar. The signal F(t) at time t is correlated with itself at a later time (t+T) to produce the autocorrelation G(t). (e) Measured G(t) describing the fluorescence fluctuation of RG molecules due to diffusion only as observed by FCS. Assuming a Gaussian observation volume, G(t) can be least-squares fitted using various analytic functions to extract information about molecular concentration, brightness, diffusion, and chemical kinetics, for one or more diffusing fluorescent species (From Hess et al.) [16].
(a)
LASER TL I1L2 120 115 110 105 DET ence F(t) F -|l•JI = ,, redWe had access to a new FCS machine called the MF20 (See Figure 18), developed by Olympus, that allowed us to take high-throughput measurements of our protein-DNA duplexes.
Figure 18. Olympus MF20. Allows the user to make high-throughput measurements of fluorescently-labeled biological sample by use of a 96-well plate format (Image from Olympus
Corporation) [22].
Because the DNA footprint of MutS is 10-12 base pairs on each side (20-25 total), for the oligo design, we made a random sequence with approximately an equal number of each base type (36 bases in total) and checked the oligonucleotide properties calculator for the possibility of self-complementarity, hairpins, etc. We decided to label a universal oligo with the
5'-TAMRA NHS Ester fluorescent probe and have 10 different complementary pieces of DNA designed to have 10 different error types (AA mismatch, GG mismatch, CC mismatch, TT mismatch, AC mismatch, AG mismatch, CT mismatch, GT mismatch, 1 bp deletion, 1 bp insertion). Oligos were ordered from Integrated DNA Technologies (IDT).
Table 1. Sequence Listing for Oligo Design with mismatch basepairs highlighted in yellow.
(9 A, 9 C, 9 T, 9G)
GTG CAG AGC GTC TCC TCA TGT CCA TTG AAA GTC GAA
Before finalizing the fluorescent probe choice, we looked up the molecular weight of the 5'-TAMRA NHS Ester fluor which is 591.6g/mol (See Figure 19). The molecular weight of our fluor is similar to the molecular weight of a double-stranded DNA base pair. We thought this would limit the potential for steric interference.
k
Figure 19. Chemical Structure of 5'-TAMRA NHS Ester from IDT. Scientific Details:
Molecular Weight: 591.6, Extinction Coefficient: 29100, Absorbance Max: 559 nm, Emission Max: 583, Extinction Coefficient: (At Absorbance Max) 91000 (From IDT) [19].
Protein was dialyzed in MF20 buffer (50mM NaCl, 10mM Tris-HC1, ImM DTT, and ImM EDTA). For the measurement of DNA-protein interactions, different concentrations of protein were incubated with 5nM TAMRA-labeled DNA.
Figure 20 below shows a summary of our experimental design. We tested our non-mismatch strands along with our 10 different error types using our 3 different MutS constructs:
Taq, Tma, and Aae.
Non-mismatch mismatch
/
I
I
I
universal strand variable strand 4-G A A G C T A A C G ins del CT AGCTCGTTUniversal Sequence (order with fluor attached to 5' end)
5'
TTC GAC TTT CAA TGG AI1
GGA GAC GCT CTG CAC
3'
(9 A, 9C, 9 T, 9G)
Figure 20. Experimental Design for MF20.
The data from the MF20 is extremely useful in determining which of our MutS samples bind which error types the best. Having this type of data will allow us to create MutS cocktails in future experiments where we want to target certain error types.
1300 1200 1100 1000 900 800 700 600 10 1 10 100 1000
[MutS] (nM)
-I 1000Figure 21. MF20 data for Taq MutS at varying concentrations bound to various mismatch errors
and non-mismatch DNA.
As shown in Figure 21, the MF20 data can be analyzed to compare relative affinities of a particular MutS protein to the types of errors that can occur in a double stranded piece of DNA. Although not shown in this figure, the data we have collected for Taq MutS protein indicates the following relative mismatch binding affinities: AC > GT = del = AA > CT > GG = CC > TT > AG > GC. The same type of experiment on the Tma MutS protein indicates the following relative mismatch binding affinities: del >> AA = TT > AC = CT = GT > CC = GG = AG = GC. Experimentation is still being conducted on the Aae MutS protein. We compared the mismatch
binding affinities of the Taq and Tma proteins to that of E. coli MutS: del = GT >> AA = TT = CT > AC = AG > CC > GC [21]. Our MF20 data clearly shows that both Taq MutS and Tma MutS have different binding affinities to various types of mismatches not only to each other but to the most widely studied MutS protein in the literature, E. coli MutS.
6.
rE. coli
The rE. coli project refers to the genome-scale re-engineering project that is a collaborative project between the Jacobson Group from MIT and the Church Group from Harvard Medical School co-led by Dr. Peter Carr (MIT) and Dr. Farren Isaacs (Harvard). There are two broad categories of recombineering methods known in the current literature. The first is a cassette based method and the second is a oligo based method.
The cassette based method is described in a paper in Nature (2001) published by Donald Court and co-workers which elucidated a "method of using highly efficient phage-based E. coli homologous recombination systems to enable genomic DNA in bacterial artificial chromosomes to be modified and subcloned" [17]. Court and his colleagues used their recombineering method to quickly and efficiently create a transgenic mouse to facilitate genomic experiments that would otherwise be difficult to carry out. This method of recombineering includes the following steps: "amplifying a cassette by PCR with flanking regions of homology, introducing phage
recombination functions into a BAC-containing bacterial strain, or introducing a BAC into a strain that carries recombination functions, transforming the cassette into cells that contain a BAC and recombination functions, generating a recombinant in vivo, and detecting a
The oligo based method is described in a paper in PNAS (2003) published by Nina Costantino and Donald Court which shows that "red-mediated recombination with synthetic single-strand oligos is very efficient and independent of RecA in E. coli" [20]. The method further shows that "in the absence of mismatch repair, Red-mediated oligo recombination can incorporate a single base change into the chromosome in an unprecedented 25% of cells
surviving electroporation" [20]. The Red system is derived from a bacteriophage lambda. The machinery that makes oligo recombination possible is a protein called Beta, that exists in the bacteriophage lambda system, which directs the ssDNA to the replication fork as it passes the target sequence [20].
The first goal of the rE. coli project is to use such a method of recombineering as described in the PNAS paper from Costantino and Court to remove every amber stop codon (TAG to TAA) from the E. coli genome (See Figure 22). The reason for doing this is to create space in the genome. This space may be used to potentially add non-natural amino acids. The non-natural amino acids can be a useful engineering tool for researchers trying to design new kinds of proteins. Further, the re-arranging of the translation table may lead to cells more resistant to phages and other sources of outside DNA. Later versions of rE. coli will attempt to address these goals.
TAT 21996 TGT 7048
TAC Y 16mi TOC C 8816
TAA sTo 2703 TGA sTop 1256 TAG STOP CAT 17813 CAC H 13227 CAA 208M8 CAO 3921M TGG W 20683 COT 28382 CGC 29M8 R CGOA 4859 CGG 7389
Figure 22. The first step of the rE. coli project which involves changing TAG stop codons to
TAA stop codons.
The first goal of the rE. coli genome project is an on-going collaborative effort between the Church group at Harvard Medical School and the Jacobson group at MIT. Each team took half of the rE. coli genome and divided up each replichore into 16 segments (See Figure 23). The goal is to make site-directed changes to each of the 32 total segments and then assemble these components into an intact re-engineered genome.
ori
replichore 2
replichore
1
dif
Figure 23. The E. coli genome (-4.6MB) is split into 32 segments (16 segments for the Church group and 16 segments for the Jacobson group)
The first step of the rE. coli project is a work in progress that we hope to finish in the next few months.
7.
Conclusions
7.1 Current Work and Future Directions
We are currently working on testing several different MutS error correction protocols. The first of these, called MSPCR (MutS in PCR), involves the use of MutS to separate out error-free DNA from error-enriched DNA, in order to only amplify error-error-free DNA during a standard PCR process. We are also working on employing MutS in a bead filtration method where we bind MutS to agarose beads in a column. After flowing DNA through the MutS-enriched
agarose bead column, we hope the error-enriched DNA will bind to the column and the error-free DNA will flow through the column. Finally, we plan to complete characterization of our various proteins using the tools mentioned earlier in this document.
Members of the Jacobson Group will continue working on these various MutS error correction protocols and carry out the next steps of the rE. coli project.
Acknowledgements
First of all, I would like to mention that this document represents several years of research conducted in a joint, team effort with members of the Jacobson Group including: Dr. Peter Carr, Jason Park, Michael Oh, and Bram Sterling. Many of the above-mentioned
experiments and research were conducted as a joint effort with at least one of the above-mentioned lab members.
I would like to thank Dr. Peter Carr, Professor Joseph Jacobson, and Dr. Shuguang Zhang for teaching and advising me throughout the years of research represented in this thesis. In particular Dr. Carr has spent countless hours teaching me molecular biology techniques, helping me work through roadblocks I ran across during my research, and giving me general guidance on how to think like a scientist. For these things I will always be grateful. Further, I want to thank Jason Park for recruiting me into the Jacobson research group and teaching me many things
about biology and about how to do research. Further, I would also like to thank members of the Jacobson and Zhang research groups for their suggestions and support and to Professor
Francesco Stellacci for agreeing to be my DMSE thesis reader.
Finally, I would like to thank my family and friends for their support, encouragement, and patience without which I would not have been able to complete the research required for this thesis.
References
[1] Watson, J., Crick, F. "Molecular structure of nucleic acids; a structure for deoxyribose nucleic acid." Nature 171 (1953): 737-8.
[2] Ghosh, A., Bansal, M. "A glossary of DNA structures from A to Z." Acta Crystallogr D Biol Crystallogr 59 (2003): 620-6.
[3] A Monk's Flourishing Garden: The Basics of Molecular Biology Explained, The Science Creative Quarterly, 2007 <http://www.scq.ubc.ca/a-monks-flourishing-garden-the-basics-of-molecular-biology-explained/>.
[4] Steckl, A.J. "DNA -a new material for photonics?" Nature Photonics 1 (2007): 3-5.
[5] Rothemund, P.W.K. "Folding DNA to create nanoscale shapes and patterns." Nature 400 (2006): 297-302.
[6] Gibson DG, Benders GA, Andrews-Pfannkoch C, Denisova EA, Baden-Tillson H, Zaveri J, Stockwell TB, Brownley A, Thomas DW, Algire MA, Merryman C, Young L, Noskov
VN, Glass JI, Venter JC, Hutchison CA 3rd, Smith HO. "Complete Chemical Synthesis, Assembly, and Cloning of a Mycoplasma genitalium Genome." Science (2008).
[7] Khorana, H.G., Buchi, H., Caruthers, M.H., Chang, S.H., Gupta, N.K., Kumar, A., Ohtsuka, E., Sgaramella, V., Weber, H. "Progress in the total synthesis of the gene for
ala-tRNA." Cold Spring Harbor Symp Quant Biol 33 (1968): 35-44.
[8] DNA Synthesis, E-oligos., 2003 <http://www.e-oligos.com/eoweb/products/eo-DNASYN.asp>.
[9] Carr, P.A., Park J.S., Lee Y.J., Yu T., Zhang, S., Jacobson J.M. "Protein-mediated error correction for de novo DNA synthesis." Nucleic Acids Research. Vol. 32 (2004).
[10] Modrich, P. "Mechanisms and biological effects of mismatch repair." Annu. Rev. Genet. 25 (1991): 229-53
[11] Brock, T.D. and Freeze, H. "Thermus aquaticus, a Nonsporulating Extreme Thermophile" J. Bact. vol. 98 (1969): 289-297.
[12] Nelson, K.E. et al. "Evidence for lateral gene transfer between Archaea and bacteria from genome sequence of Thermotoga maritima". Nature 399 (1999): 323-9.
[13] Deckert, G. et al. "The complete genome of the hyperthermophilic bacterium Aquifex aeolicus." Nature 392 (1998): 353-358.
[14] Circular Dichroism, Alliance Protein Laboratories, Inc., 2007 <http://www.ap-lab.com/circular dichroism.htm>.
[15] Kobayashi, T., Okamoto, N., Sawasaki, T., and Endo, Y. "Detection of protein-DNA interactions in crude cellular extracts by fluorescence correlation spectroscopy." Analytical Biochemistry 332 (2004): 58-66.
[16] Hess, Huang, Heikal, and Webb. "Experimental Principles of Fluorescence Correlation Spectroscopy." Biochemistry 41 (2002): 697.
[17] Copeland, N.G., Jenkins, N.A., Court, D.L. "Recombineering: A powerful new tool for mouse functional genomics." Nature Reviews 2 (2001): 769-779.
[18] Hoover, D.M. and Lubkowski J. "DNAWorks: an automated method for designing oligonucleotides for PCR-based gene synthesis. Nucleic Acids Research Vol. 30 (2002): 43.
[19] 5' TAMRATM NHS Ester, Integrated DNA Technologies, 2008
<http://www.idtdna.com/catalog/Modifications/Modifications.aspx?ProductlD= 1095>. [20] Constantino, N. and Court, D.L. "Enhanced levels of A Red-Mediated recombinants in
mismatch repair mutants." PNAS Vol. 100 (2003): 15748-15753.
[21.] Brown, J., Brown, T., and Fox, K.R. "Affinity of mismatch-binding protein MutS for heteroduplexes containing different mismatches." Biochem J. Vol. 354 (2001): 627-633. [22] Fluoropoint, Olympus, 2008

![Figure 1. DNA is a polymeric molecule that has 4 bases (cytosine, guanine, adenine, and thymine) and a sugar-phosphate backbone (The Science Creative Quarterly) [3].](https://thumb-eu.123doks.com/thumbv2/123doknet/14752223.580758/6.918.123.427.312.825/polymeric-molecule-cytosine-phosphate-backbone-science-creative-quarterly.webp)


![Figure 5. Steps of Oligonucleotide synthesis. (Figure from E-Oligos) [8].](https://thumb-eu.123doks.com/thumbv2/123doknet/14752223.580758/12.918.116.733.237.734/figure-steps-oligonucleotide-synthesis-figure-e-oligos.webp)