THÈSE
THÈSE
En vue de l’obtention du
DOCTORAT DE L’UNIVERSITÉ DE TOULOUSE
Délivré par : l’Université Toulouse 3 Paul Sabatier (UT3 Paul Sabatier)Présentée et soutenue le 23/11/2017 par : Thibaut THONET
Modèles thématiques pour la découverte non supervisée de points de vue sur le Web
JURY
Nathalie AUSSENAC-GILLES DR au CNRS, Université Toulouse 3 Présidente du jury Patrick GALLINARI Professeur, Université Pierre et Marie Curie Rapporteur Éric GAUSSIER Professeur, Université Grenoble-Alpes Rapporteur
Julien VELCIN MCF-HDR, Université Lyon 2 Examinateur
Guillaume CABANAC MCF-HDR, Université Toulouse 3 Directeur de thèse Karen PINEL-SAUVAGNAT MCF, Université Toulouse 3 Co-encadrante Mohand BOUGHANEM Professeur, Université Toulouse 3 Co-encadrant
École doctorale et spécialité :
MITT : Image, Information, Hypermédia Unité de Recherche :
Institut de Recherche en Informatique de Toulouse (UMR 5505) Directeur(s) de Thèse :
Guillaume CABANAC,Karen PINEL-SAUVAGNAT etMohand BOUGHANEM
Rapporteurs :
Remerciements
Cette thèse n’aurait pu aboutir sans l’aide bienveillante et le soutien indéfectible que m’ont témoignés les nombreuses personnes côtoyées durant ces quelques années à l’IRIT et au delà. Mes premiers remerciements vont tout naturellement à mes encadrants de thèse, Monsieur Guillaume Cabanac, Madame Karen Pinel-Sauvagnat et Monsieur Mohand Boughanem. Je ne saurais trouver les mots pour exprimer la gratitude que j’éprouve à leur égard pour leur patience, leur sollicitude et leurs encouragements de tous les instants, qui m’ont permis de continuer à avancer même lorsque le moral manquait. Plus que des encadrants, je peux sans le moindre doute affirmer avoir trouver en eux des mentors, des exemples à suivre, qui m’ont transmis leur passion pour leur profession.
Je souhaite également exprimer toute ma reconnaissance aux rapporteurs de ma thèse, Monsieur Patrick Gallinari et Monsieur Éric Gaussier, qui m’ont fait l’honneur d’apporter leur précieuse expertise dans l’évaluation de mes travaux. Au delà de son rôle de rapporteur, je remercie par ailleurs Éric pour son aide dans la relecture de mes articles, pour nos multiples discussions ou correspondances passionnantes, ainsi que pour son invitation à effectuer un séminaire au laboratoire LIG de l’Université Grenoble Alpes – opportunité qui s’est avérée fort enrichissante pour moi.
Mes sincères remerciements vont de même à Madame Nathalie Aussenac-Gilles et Mon-sieur Julien Velcin, qui ont gracieusement accepté de siéger dans mon jury de thèse en tant qu’examinatrice et examinateur, respectivement. Je remercie par ailleurs Julien pour nos nom-breux échanges sur l’évaluation des modèles thématiques et pour sa participation au groupe de travail CaRaThoVe, aux cotés de Monsieur Pierre Ratinaud et Monsieur Guillaume Ca-banac – collaboration qui, j’en suis convaincu, ne tardera pas à porter ses fruits.
Cette thèse n’aurait eu la même saveur sans toutes les personnes que j’ai rencontrées et côtoyées à l’IRIT. Mes remerciements vont spécialement à celles et ceux avec qui j’ai par-tagé le bureau 406. J’ai une reconnaissance toute particulière pour Diep qui m’a accompagné durant toutes ces années de thèse et m’a toujours gratifié de son soutien sans faille. Plus géné-ralement, je remercie les différents membres de l’équipe IRIS, passés ou présents, permanents ou doctorants.
Enfin, j’éprouve une immense gratitude pour ma famille et mes amis qui m’ont soutenu – voire supporté – durant ces années de thèse parfois éprouvantes mais toujours exaltantes. Je remercie en particulier mes parents pour leur enthousiasme, leur disponibilité, leur patience et leur amour inconditionnel, sans lesquels cette thèse n’aurait été possible.
Table des matières
Publications xiii
Introduction générale 1
1 Contexte . . . 1
1.1 Fouille d’opinions sur le Web . . . 1
1.2 Vers la fouille de points de vue . . . 2
2 Problématiques . . . 3
3 Contributions . . . 4
4 Organisation du mémoire . . . 5
I Revue de l’état de l’art 7 1 Fouille d’opinions 9 1.1 Introduction . . . 9
1.1.1 Définitions et objectifs . . . 10
1.1.2 Motivations et applications . . . 11
1.1.3 Défis . . . 13
1.1.4 Processus de fouille d’opinions . . . 14
1.2 Détection de subjectivité . . . 15
1.3 Identification de la polarité et de la nuance des opinions . . . 16
1.3.1 Cas des opinions de granularité grossière . . . 16
1.3.1.1 Classification supervisée . . . 17
1.3.1.2 Classification semi-supervisée ou non supervisée . . . 17
1.3.1.3 Régression . . . 18
1.3.2.1 Extraction des aspects . . . 19
1.3.2.2 Identification des opinions associées aux aspects . . . 20
1.3.2.3 Approches conjointes . . . 20
1.4 Génération de résumés d’opinions . . . 22
1.4.1 Résumés d’opinions basés sur les aspects . . . 22
1.4.1.1 Résumés extractifs . . . 24
1.4.1.2 Résumés abstractifs . . . 25
1.4.2 Résumés d’opinions contrastés . . . 26
1.5 Conclusion . . . 27
2 Fouille de points de vue 29 2.1 Introduction . . . 29
2.1.1 Définitions et objectifs . . . 30
2.1.2 Motivations et applications . . . 30
2.1.3 Difficultés et spécificités par rapport à la fouille d’opinions individuelles 32 2.1.4 Scénarios de fouille de points de vue . . . 35
2.2 Fouille au niveau microscopique : mots et phrases . . . 36
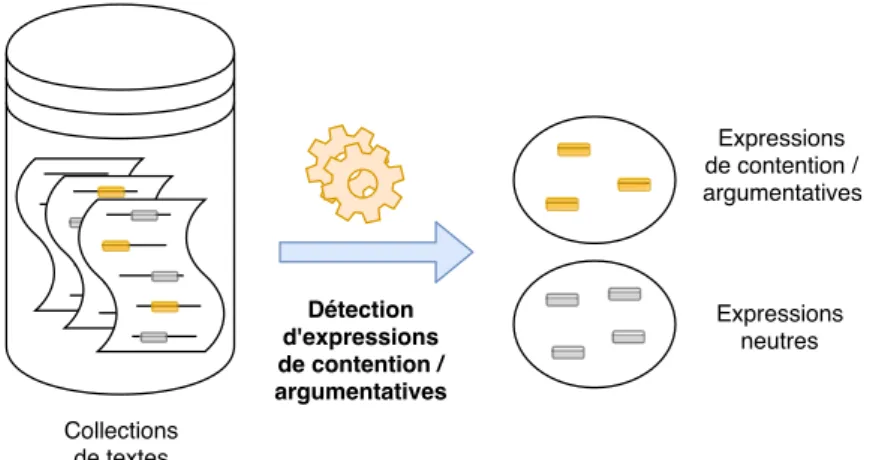
2.2.1 Détection d’expressions d’argumentation et de contention . . . 36
2.2.2 Classification de points de vue dans les documents courts . . . 38
2.3 Fouille au niveau mésoscopique : documents longs et utilisateurs . . . 39
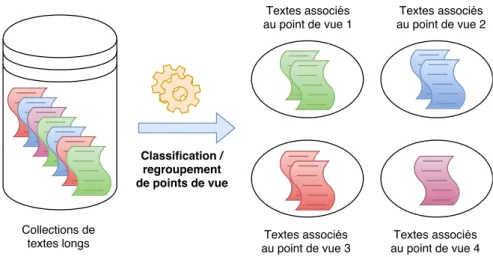
2.3.1 Identification de points de vue dans les documents longs . . . 41
2.3.1.1 Points de vue dans les essais . . . 41
2.3.1.2 Points de vue dans les textes législatifs . . . 42
2.3.2 Identification du point de vue des utilisateurs de médias sociaux . . . 43
2.3.2.1 Approches supervisées . . . 44
2.3.2.2 Approches semi-supervisées et non supervisées . . . 45
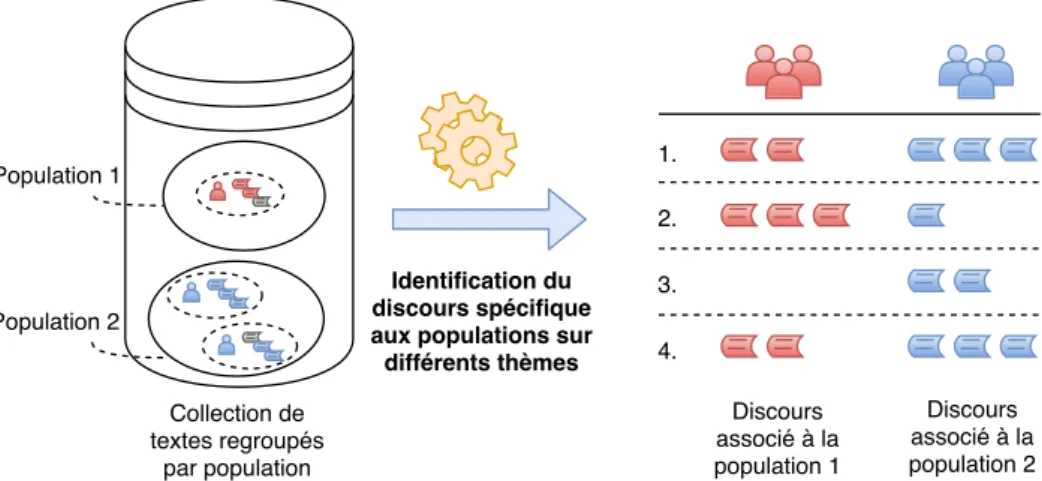
2.4.1 Analyse comparative des points de vue entre différentes populations . 47
2.4.2 Détection de sujets de controverse . . . 49
2.5 Conclusion . . . 50
3 Modèles thématiques probabilistes 53 3.1 Introduction . . . 53
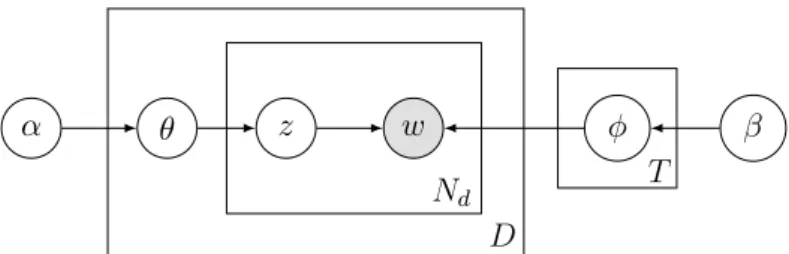
3.2 LDA : allocation de Dirichlet latente . . . 54
3.2.1 Histoire générative . . . 54
3.2.2 Représentation sous forme de modèle graphique . . . 56
3.2.3 Vraisemblance et probabilité postérieure du modèle . . . 56
3.3 Méthodes d’inférence postérieure approchées . . . 57
3.3.1 Échantillonnage de Gibbs . . . 58
3.3.1.1 Principe général . . . 58
3.3.1.2 Échantillonnage de Gibbs marginalisé . . . 60
3.3.1.3 Application à LDA . . . 61 3.3.2 Inférence variationnelle . . . 65 3.3.2.1 Principe général . . . 65 3.3.2.2 Application à LDA . . . 66 3.4 Évaluation . . . 67 3.4.1 Perplexité . . . 68 3.4.2 Cohérence thématique . . . 69
3.4.3 Évaluation basée sur des tâches externes . . . 70
3.5 Conclusion . . . 71
II Contributions à la découverte de points de vue sur le Web 73
4.1 VODUM : un modèle unifiant la découverte des thèmes, des opinions et des points de vue . . . 76 4.1.1 Description du modèle . . . 76 4.1.2 Inférence postérieure . . . 79 4.2 Expérimentations . . . 82 4.2.1 Cadre expérimental . . . 84 4.2.1.1 Modèles de référence . . . 84 4.2.1.2 Collection de données . . . 87
4.2.1.3 Choix des paramètres . . . 87
4.2.2 Évaluation . . . 88
4.2.2.1 Perplexité . . . 88
4.2.2.2 Regroupement de points de vue . . . 90
4.2.2.3 Analyse qualitative des thèmes et des points de vue découverts par VODUM . . . 92
4.3 Discussions . . . 95
5 Intégration des interactions sur les réseaux sociaux pour la découverte de points de vue 97 5.1 SNVDM : un modèle thématique pour la découverte de points de vue dans les réseaux sociaux . . . 98
5.1.1 Préliminaires . . . 98
5.1.2 Description du modèle . . . 99
5.1.3 Inférence postérieure . . . 104
5.1.4 Limites de SNVDM . . . 107
5.2 SNVDM-GPU : extension de SNVDM basée sur les urnes de Pólya généralisées 108 5.2.1 Urnes de Pólya simples . . . 108
5.2.2 Urnes de Pólya généralisées . . . 109
5.3 Expérimentations . . . 112
5.3.1 Cadre expérimental . . . 113
5.3.1.1 Modèles de référence . . . 113
5.3.1.2 Collections de données . . . 114
5.3.1.3 Choix des paramètres . . . 116
5.3.2 Évaluation . . . 117
5.3.2.1 Regroupement de points de vue . . . 117
5.3.2.2 Robustesse aux réseaux sociaux de faible densité . . . 120
5.3.2.3 Temps d’exécution . . . 122
5.3.2.4 Analyse qualitative des thèmes et des points de vue découverts 122 5.4 Discussions . . . 123
Conclusion générale 127 1 Résumé des contributions . . . 127
2 Perspectives et travaux futurs . . . 129
Table des figures
1.1 Exemple de critiques postées sur Amazon (11 juin 2016). . . 12
1.2 Processus complet de fouille d’opinions. . . 14
1.3 Exemple de résumé d’opinions visuel basé sur les aspects. . . 23
2.1 Exemple de carte argumentative sur le gaz de schiste. . . 33
2.2 Annotation de la carte argumentative sur le gaz de schiste. . . 34
2.3 Tâches de fouille de points de vue au niveau microscopique. . . 37
2.4 Tâches de fouille de points de vue au niveau mésoscopique. . . 40
2.5 Tâches de fouille de points de vue au niveau macroscopique. . . 48
3.1 Représentation de LDA sous forme de modèle graphique. . . 56
4.1 Représentation de VODUM sous forme de modèle graphique. . . 76
4.2 Modèles graphiques des versions dégénérées de VODUM. . . 86
4.3 Perplexité des modèles VODUM, TAM, JTV et LDA calculée pour 5, 10, 15, 20, 30 et 50 thèmes. . . 89
4.4 Exactitude d’identification des points de vue (VIA) pour VODUM, TAM, JTV, LDA, VODUM-D, VODUM-O, VODUM-W et VODUM-S. . . 93
5.1 Représentation sous forme de modèle graphique de TAM, SN-LDA et notre modèle SNVDM. . . 103
5.2 Tirage et remise pour une urne de Pólya simple. . . 109
5.3 Tirage et remise pour une urne de Pólya généralisée. . . 110
5.4 Représentation sous forme de modèle graphique de SNVDM-WII. . . 114
5.5 Résultats du regroupement de points de vue sur la collection Indyref en terme de Pureté et de NMI pour les modèles TAM, SN-LDA, VODUM, SNDM-WII, SNVDM, SNVDM-GPU (τ = 10) et SNVDM-GPU (τ = ∞) avec différents nombres de thèmes (5, 10, 15 et 20). . . 118
5.6 Résultats du regroupement de points de vue sur la collection Midterms en terme de Pureté et de NMI pour les modèles TAM, SN-LDA, VODUM, SNDM-WII, SNVDM, SNVDM-GPU (τ = 10) et SNVDM-GPU (τ = ∞) avec différents nombres de thèmes (5, 10, 15 et 20). . . 119
5.7 Résultats du regroupement de points de vue sur la collection Indyref en terme de Pureté et de NMI pour les modèles SN-LDA, SNVDM, SNVDM-GPU (τ = 10) et SNVDM-GPU (τ = ∞) en conservant différents pourcentages des interactions disponibles dans le réseau social (10 %, 25 %, 50 % et 100 %) . 121
Liste des tableaux
1.1 Exemple de résumé d’opinions textuel basé sur les aspects pour un film de cinéma (imaginaire). . . 24
1.2 Exemple de résumé d’opinions contrasté pour un jeu vidéo (imaginaire). . . . 26
1.3 Exemple de résumé de points de vue sur l’avortement. . . 27
3.1 Notations adoptées pour le modèle LDA. . . 55
4.1 Notations adoptées pour décrire VODUM. . . 77
4.2 Perplexité des modèles VODUM, TAM, JTV et LDA calculée pour 5, 10, 15, 20, 30 et 50 thèmes. . . 90
4.3 Exactitude d’identification des points de vue (VIA) et intervalle de confiance (IC) à 95 % autour de la VIA moyenne pour VODUM, TAM, JTV, LDA, VODUM-D, VODUM-O, VODUM-W et VODUM-S. . . 92
4.4 Listes des 20 mots thématiques et des 20 mots d’opinion (racinisés) les plus probables associés au thème manuellement étiqueté comme « conflits au Moyen-Orient ». . . 94
4.5 Listes des 20 mots thématiques et des 20 mots d’opinion (racinisés) les plus probables associés au thème manuellement étiqueté comme « justice et protec-tion ». . . 95
5.1 Notations adoptées pour décrire notre modèle SNVDM. . . 100
5.2 Statistiques des collections utilisées dans les expérimentations sur SNVDM et SNVDM-GPU. . . 116
5.3 Temps d’exécution d’une itération de l’échantillonnage de Gibbs marginalisé pour les modèles TAM, SN-LDA, VODUM, WII, SNVDM, SNVDM-GPU (τ = 10) et SNVDM-SNVDM-GPU (τ = ∞) sur la collection Indyref et Midterms. 122
5.4 Listes des 20 mots thématiques et des 20 mots de point de vue thématiques les plus probables associés au thème manuellement étiqueté comme « indépen-dance de l’Écosse ». . . 124
5.5 Listes des 20 mots thématiques et des 20 mots de point de vue thématiques les plus probables associés au thème manuellement étiqueté comme « énergie et ressources ». . . 125
Publications
Articles de conférences internationales avec comité de lecture
1. Thibaut Thonet, Guillaume Cabanac, Mohand Boughanem, Karen Pinel-Sauvagnat (2017). Users Are Known by the Company They Keep: Topic Models for Viewpoint Discovery in Social Networks. In Proceedings of the 26th ACM International Conference
on Information and Knowledge Management, CIKM ’17. (À paraître.)
2. Thibaut Thonet, Guillaume Cabanac, Mohand Boughanem, Karen Pinel-Sauvagnat (2016). VODUM: A Topic Model Unifying Viewpoint, Topic and Opinion Discovery. In
Proceedings of the 38th European Conference on IR Research, ECIR ’16, pages 533–545.
Article de conférence nationale avec comité de lecture
1. Thibaut Thonet, Romain Deveaud, Iadh Ounis, Craig Macdonald (2015). Suggestion Contextuelle Composite. In Actes de la 12ème Conférence en Recherche d’Information
et Applications, CORIA ’15, pages 89–104.
Article de campagne d’évaluation internationale (sans comité de lecture)
1. Richard McCreadie, Romain Deveaud, M-Dyaa Albakour, Stuart Mackie, Nut Limso-patham, Craig Macdonald, Iadh Ounis, Thibaut Thonet, Bekir Taner Dinçer (2014). University of Glasgow at TREC 2014: Experiments with Terrier in Contextual Sug-gestion, Temporal Summarisation and Web Tracks. In Proceedings of the 23rd Text
Introduction générale
1
Contexte
À une ère où le numérique est omniprésent et où le Web rythme nos vies quotidiennes, nous disposons de moyens auparavant inégalés par leur ampleur et leur rapidité pour nous informer, communiquer et partager du contenu. Cette révolution de possibilités est notamment le fruit de l’émergence de plateformes en ligne permettant à leurs utilisateurs de s’exprimer ou d’interagir. À travers ces plateformes, les internautes ont alors accès à un outil simple à prendre en main pour diffuser leurs opinions. On peut citer en exemple le site de commerce en ligne Amazon1– qui permet aux acheteurs de noter et critiquer les produits commandés –
ou la plateforme de microblogging Twitter2 – qui offre à ses utilisateurs la possibilité de s’exprimer publiquement sous la forme de courts messages de 140 caractères.
Loin d’être anodine, cette richesse d’opinions publiées sur le Web s’est rapidement avérée d’importance capitale pour une multitude d’acteurs économiques. En effet, nous ne sommes pour la plupart pas insensibles aux opinions partagées par les autres internautes, et en par-ticulier dans le cas de l’achat en ligne. Un sondage du Pew Research Center3 réalisé en
2016 va dans ce sens : 82 % des personnes (de nationalité américaine) interrogées ont déclaré consulter les notes et les critiques en ligne lorsqu’elles achètent un produit pour la première fois [Smith et Anderson, 2016]. La masse de données d’opinions disponible – et les promesses qu’elle offre – a alors motivé à la fois chercheurs universitaires et industriels à développer des systèmes de fouille de textes focalisés sur ces données subjectives. Ce domaine d’étude est aujourd’hui connu sous le nom de fouille d’opinions (opinion mining) ou d’analyse de
sentiments (sentiment analysis) [Pang et Lee, 2008].
1.1 Fouille d’opinions sur le Web
La fouille d’opinions, développée à la fin des années 1990 [Hatzivassiloglou et McKeown, 1997], se positionne à l’intersection de plusieurs spécialités de l’informatique telles que le traitement automatique du langage naturel, la recherche d’information, la fouille de texte et l’apprentissage automatique. Elle est définie par Pang et Lee [2008] comme étant « le traitement informatique de l’opinion, du sentiment et de la subjectivité dans le texte ». Dans le faits, les travaux en fouille d’opinions se sont longtemps focalisés sur les opinions formulées dans les critiques en ligne, telles que celles trouvées sur Amazon. Ce type d’opinions est typiquement associé à une polarité positive ou négative (voire un intermédiaire entre ces deux extrêmes), indiquant l’avis de l’internaute vis-à-vis du produit acheté.
1. https://www.amazon.fr/ 2. https://twitter.com/ 3. http://www.pewresearch.org/
Les approches classiques de fouille d’opinions, traditionnellement basées sur des lexiques de mots d’opinions [Jo et Oh, 2011; Lin et He, 2009; Yu et Hatzivassiloglou, 2003], sont toutefois difficilement utilisables lorsque l’on souhaite étudier des opinions plus complexes telles que les opinions politiques. Par exemple, dans le contexte de l’élection présidentielle américaine de 2016, le fait qu’un utilisateur de médias sociaux emploie fréquemment un lexique positif ou négatif ne sera pas nécessairement révélateur de son soutien pour Donald Trump ou Hillary Clinton. Des techniques nouvelles sont alors requises pour aller au delà de la catégorisation des opinions en « positives » et « négatives ». Nous regroupons ici ces techniques sous le nom de fouille de points de vue, où la notion de point de vue généralise l’opinion au delà de son acception usuelle liée à la polarité (positive ou négative).
1.2 Vers la fouille de points de vue
Il est pertinent de se demander dans quelle mesure la fouille de points de vue – qui pré-sente les défis inédits évoqués précédemment – est nécessaire et ce qu’elle peut apporter. Le besoin d’avancées en fouille de points de vue repose – en partie – sur l’importance qu’a revêtu la discussion politique dans les médias sociaux et sur le Web en général. Par exemple, un sondage du Pew Research Center [Duggan et Smith, 2016] indique qu’en 2016 environ un tiers des utilisateurs de médias sociaux de nationalité américaine commentent, participent à des discussions ou postent du contenu en rapport avec le gouvernement et la politique. Cet important volume de données d’opinions politiques semble alors susceptible de pouvoir com-plémenter (à défaut de supplanter [Kim et al., 2014]) les opinions recueillies par les sondages classiques [O’Connor et al., 2010].
Ce même rapport du Pew Research Center [Duggan et Smith, 2016] relate par ailleurs la propension des utilisateurs de médias sociaux à s’abonner aux personnalités politiques qui partagent le même point de vue : 66 % des utilisateurs s’abonnent à des personnalités politiques qui partagent le même point de vue, alors que seulement 31 % (respectivement, 3 %) s’abonnent à des personnalités politiques aux points de vue variés (respectivement, opposés aux leurs). Ainsi, les internautes auront plus tendance à être exposés à du contenu soutenant leur propre point de vue qu’à du contenu qui y est opposé. Ce phénomène récemment mis à jour est connu sous le nom de « chambre d’échos » [Sunstein, 2009] et de « bulle de filtres » [Pariser, 2011]. Dans ce contexte, un système automatisé de fouille de points de vue pourrait être employé pour permettre aux utilisateurs d’accéder à des opinions variées (par exemple, sous forme de résumés de points de vue) et ainsi réduire l’effet des chambres d’échos et des bulles de filtre. Une autre application possible est la détection de fausses nouvelles (fake news) – un phénomène qui a fait couler beaucoup d’encre depuis l’élection présidentielle américaine de 2016 en raison de l’impact sur la victoire de Donald Trump qui lui est parfois imputé [Allcott et Gentzkow, 2017]. Les fausses nouvelles sont caractérisées par une forte subjectivité, ce qui justifie le potentiel de techniques basées sur la fouille de points de vue [Jin
et al., 2016].
Ainsi, la fouille de points de vue constitue une problématique chargée de défis scientifiques et présente un potentiel d’application à différents problèmes d’actualité. Dans la Section 2,
nous définissons plus spécifiquement les problématiques liées à la fouille de point de vue auxquelles nous nous sommes intéressé dans cette thèse.
2
Problématiques
Cette thèse attaque un sous-problème de la fouille de points de vue, que nous dénomme-rons « découverte de points de vue », dont l’objectif est d’identifier le point de vue exprimé dans chaque texte ou par chaque auteur (par exemple un utilisateur de médias sociaux) d’une collection de documents. La découverte de points de vue constitue la première étape vers la mise en œuvre des différentes applications sus-mentionnées et est par conséquent fonda-mentale. Ce problème pourrait être envisagé comme un problème de classification (chaque classe correspondant à un point de vue) et abordé par des approches supervisées. Cependant, l’annotation manuelle de collections de données – nécessaire aux approches supervisées – est souvent difficile et coûteuse à obtenir. Nous avons donc choisi dans cette thèse d’adopter un cadre non supervisé, dans lequel nous ne disposons pas d’informations a priori sur la na-ture des points de vue à identifier. Contrairement aux techniques non supervisées de fouille d’opinions classique – focalisées sur les opinions positives et négatives – nous ne pouvons pas exploiter des lexiques de mots pré-existants. En effet, le vocabulaire propre à un point de vue n’est généralement pas transposable à d’autres sujets. Par exemple, les mots spécifiques aux partisans de Donald Trump ou à ceux de Hillary Clinton ne pourront vraisemblablement pas être exploités pour différencier des textes écrits selon les points de vue pro-israéliens ou pro-palestiniens.
Par conséquent, nous explorons dans cette thèse d’autres indices disponibles dans les textes et sur les médias sociaux pour faciliter la découverte de points de vue. Les problématiques auxquelles nous nous sommes intéressé peuvent ainsi être découpées suivant les deux questions et quatre sous-questions suivantes :
1. Comment exploiter le contenu textuel des documents sur le Web pour découvrir les points de vue qui y sont exprimés ?
(a) Comment utiliser à cette fin la co-occurrence des mots et la nature distributionnelle du langage, pour faire émerger des motifs lexicaux révélateurs des différents points de vue ?
(b) Est-il possible et pertinent d’intégrer des indicateurs de subjectivité, tels que les parties de discours pour identifier les mots porteurs de points de vue ?
2. Comment tirer parti des métadonnées disponibles dans les médias sociaux, telles que les interactions entre utilisateurs, pour raffiner la découverte de points de vue ?
(a) Une approche exploitant conjointement le contenu textuel et les métadonnées est-elle envisageable ?
(b) Quel est l’impact de ces métadonnées sur les performances d’une telle approche, en comparaison avec la seule exploitation d’indices textuels ?
Les contributions que nous avons apportées dans le cadre de cette thèse pour répondre à ces questions sont synthétisées dans la Section 3.
3
Contributions
Comme nous l’avons mentionné dans la Section 2, une caractéristique des documents textuels qui s’avère précieuse dans le cadre non supervisé est la co-occurrence des mots : deux mots qui apparaissent fréquemment dans le même contexte (par exemple, le même document ou la même phrase) ont tendance à être sémantiquement liés. Ce phénomène peut être exploité par une catégorie de modèles non supervisés nommés modèles thématiques (topic models), dans laquelle l’allocation de Dirichlet latente (LDA – latent Dirichlet allocation) [Blei et al., 2001, 2003] s’inscrit. Les modèles thématiques constituent une approche polyvalente pour découvrir sans annotations préalables des thèmes ainsi que d’autres dimensions latentes (telles que les points de vue) à partir d’un corpus de textes. Nous avons donc décidé de baser nos approches pour la fouille de points de vue sur les modèles thématiques et en particulier ceux inspirés de LDA. Nos contributions à la fouille de points de vue reposent sur la proposition de deux modèles thématiques originaux :
1. Notre première contribution [Thonet et al., 2016] se focalise sur la modélisation des points de vue dans les documents textuels sans métadonnées disponibles. Nous définis-sons en particulier la tâche de découverte des points de vue et des opinions (viewpoint
and opinion discovery), qui consiste à analyser une collection de documents afin
d’iden-tifier le point de vue de chaque document, les thèmes mentionnés par chaque document et les opinions spécifiques aux points de vue pour chaque thème. Pour traiter ce pro-blème, nous proposons le modèle VODUM (viewpoint and opinion discovery unification
model), une approche non supervisée permettant la modélisation conjointe des points
de vue et des thèmes en différenciant mots d’opinion (spécifiques aux points de vue et aux thèmes) et mots thématiques (spécifiques aux thèmes uniquement et neutres vis-à-vis des différents points de vue). À travers VODUM, nous étudions dans quelle mesure les parties de discours peuvent être exploitées pour distinguer les mots d’opinion et les mots thématiques dans un cadre non supervisé.
2. Dans notre seconde contribution [Thonet et al., 2017], nous nous intéressons à étendre la découverte de points de vue aux réseaux sociaux en exploitant les métadonnées qui y sont disponibles. En particulier, notre objectif est ici d’analyser dans quelle mesure l’utilisation des interactions entre utilisateurs, en plus de leur contenu textuel généré, est bénéfique pour l’identification de leurs points de vue. L’intuition que nous développons ici repose sur le principe d’homophilie selon lequel les individus « similaires » entre eux (par exemple dans leurs opinions politiques) ont une plus forte propension à créer des liens. Nous présentons ainsi dans un premier temps le modèle SNVDM (Social
Network Viewpoint Discovery Model) qui exploite conjointement le contenu généré par
les utilisateurs et leurs interactions pour modéliser sans supervision à la fois les points de vue et les thèmes qui leur sont associés. Afin de surmonter les cas où le réseau d’interactions sociales est peu dense (sparse) – lorsqu’un utilisateur n’interagit qu’avec un nombre limité d’utilisateurs tiers – nous proposons ensuite une extension de SNVDM, nommée SNVDM-GPU, basée sur les urnes de Pólya généralisées [Mahmoud, 2008]. SNVDM-GPU présente notamment l’avantage d’intégrer les relations d’« accointances d’accointances » afin de prendre en compte les liens faibles existant entre les utilisateurs.
4
Organisation du mémoire
Le contenu de ce mémoire est organisé en deux parties. La Partie I synthétise les travaux de l’état de l’art pertinents aux problématiques abordées dans cette thèse. En particulier, le Chapitre 1 décrit les concepts de base, les tâches et les méthodes associées à la fouille d’opinions. Ce chapitre couvre l’approche « classique » de la fouille d’opinions, focalisée sur les opinions positives et négatives. Dans le Chapitre 2, nous introduisons le sous-domaine de la fouille d’opinions que nous dénotons par l’appellation « fouille de points de vue ». Nous proposons d’unifier sous cette dénomination un ensemble de tâches et de scénarios reliés par la notion de point de vue. Le Chapitre 3 détaille quant à lui l’allocation de Dirichlet latente (LDA – latent Dirichlet allocation), que nos contributions proposent d’étendre afin de modéliser conjointement thèmes et points de vue. Plus généralement, ce chapitre décrit les aspects méthodologiques et les éléments mathématiques inhérents aux modèles thématiques, nécessaires à la contribution des chapitres suivants.
La Partie II présente ensuite les contributions de cette thèse, œuvrant à faciliter la dé-couverte de points de vue sur le Web lorsqu’aucune donnée annotée n’est disponible. Notre première contribution, détaillée dans le Chapitre 4, définit une modélisation conjointe des thèmes et des points de vue dans laquelle nous explorons l’idée de différencier mots d’opi-nions (spécifiques à la fois à un point de vue et à un thème) et mots thématiques (dépendants du thème mais neutres vis-à-vis des différents points de vue). Cette séparation entre mots d’opinion et mots thématiques est basée sur les parties de discours, inspirée par des pratiques similaires dans la littérature de fouille d’opinions classique – restreinte aux opinions positives et négatives. Dans le Chapitre 5, nous nous focalisons cette-fois sur les points de vue expri-més sur les réseaux sociaux. Notre objectif est alors d’analyser dans quelle mesure l’utilisation des interactions entre utilisateurs, en plus de leur contenu textuel généré, est bénéfique pour l’identification de leurs points de vue.
Enfin, nous concluons le mémoire en résumant les différents résultats obtenus dans cette thèse et en discutant des extensions possibles de nos travaux.
Première partie
Chapitre 1
Fouille d’opinions
Sommaire 1.1 Introduction . . . . 9 1.1.1 Définitions et objectifs . . . 10 1.1.2 Motivations et applications . . . 11 1.1.3 Défis . . . 13 1.1.4 Processus de fouille d’opinions . . . 141.2 Détection de subjectivité . . . . 15 1.3 Identification de la polarité et de la nuance des opinions . . . . 16
1.3.1 Cas des opinions de granularité grossière . . . 16 1.3.2 Cas des opinions basées sur les aspects . . . 19
1.4 Génération de résumés d’opinions . . . . 22
1.4.1 Résumés d’opinions basés sur les aspects . . . 22 1.4.2 Résumés d’opinions contrastés . . . 26
1.5 Conclusion . . . . 27
1.1
Introduction
Nous présentons dans ce chapitre un aperçu des travaux existants en fouille d’opinions. Étant donné le volume important de littérature en la matière, cet état de l’art sur la fouille d’opinions n’a pas vocation à être exhaustif. Il en couvre les concepts et problèmes principaux afin de fournir le contexte de la fouille de points de vue – le cœur de cette thèse – qui constitue un sous-domaine de la fouille d’opinions. Pour une revue plus exhaustive et détaillée sur la fouille d’opinions, le lecteur intéressé peut se référer aux deux états de l’art références dans ce domaine : celui de Pang et Lee [2008] et celui de Liu [2012].
Tout d’abord, nous définirons les concepts clés et les objectifs de la fouille d’opinions (Section 1.1.1). Dans les Sections 1.1.2 et 1.1.3 nous expliquerons dans quelle mesure les systèmes de fouille d’opinions sont critiques autant pour les individus que pour les entreprises et les décideurs, et quels sont les défis de tels systèmes, respectivement. La Section 1.1.4 donnera un aperçu des tâches successives nécessaires à la construction d’un système de fouille d’opinions : la détection de la subjectivité, l’identification de la polarité des opinions, et la génération de résumés d’opinions, détaillées respectivement dans les Sections 1.2, 1.3 et 1.4.
1.1.1 Définitions et objectifs
La fouille d’opinions (opinion mining), également parfois désignée sous le nom d’analyse de sentiments (sentiment analysis), est un sous-domaine de l’informatique à l’intersection de plusieurs disciplines telles que le traitement automatique du langage naturel, la recherche d’information, la fouille de texte et l’apprentissage automatique. Les termes « fouille d’opi-nions » et « analyse de sentiments » ont été respectivement introduits dans [Dave et al., 2003] et [Nasukawa et Yi, 2003]. Avant de définir plus précisément ce sous-domaine, attardons-nous d’abord sur la notion clé d’opinion. Selon le dictionnaire Larousse en ligne1, une opinion
désigne :
1. un « jugement, avis, sentiment qu’un individu ou un groupe émet sur un sujet, des faits, ce qu’il en pense » ;
2. ou l’« ensemble des idées d’un groupe social sur les problèmes politiques, économiques, moraux, etc. ».
La première définition positionne l’opinion au niveau de l’individu, alors que la seconde dé-finition évoque une opinion collective et partagée. Considérons les exemples suivants pour apprécier les nuances de ces deux définitions :
1. Quelle est ton opinion sur ce livre ? 2. Quelles sont tes opinions politiques ?
La première question attend principalement une réponse exprimant un avis positif ou négatif (voire neutre éventuellement) exprimant respectivement si la personne questionnée a aimé ou non le livre évoqué. Il s’agit du type d’opinions personnelles ciblées (ici, vers un livre) que l’on peut trouver dans les critiques de produits ou de services en ligne (online reviews) sur des sites web tels que Amazon2et TripAdvisor3. La seconde question est quant à elle plus complexe et demande une réponse élaborée, autre que positive ou négative. Il est attendu de la personne questionnée qu’elle se positionne par rapport au monde et à la société en définissant un ensemble de principes et de valeurs – qui sont par ailleurs communs aux individus partageant son idéologie politique. La première question fait ainsi référence à la première définition de l’opinion – celle d’une opinion individuelle – alors que la seconde question mentionne la seconde définition – celle d’une opinion collective. Cette seconde définition correspond en réalité à ce que nous nommerons plus tard « points de vue » dans le Chapitre 2.
La notion d’opinion étant clarifiée, nous pouvons maintenant expliciter la tâche de fouille d’opinions. Dans leur état de l’art qui fait référence en la matière [Pang et Lee, 2008], Pang et Lee définissent la fouille d’opinions comme « le traitement informatique de l’opinion, du sentiment et de la subjectivité dans le texte ». Ici, le « traitement informatique » se rapporte à un processus automatisé et algorithmique. « Sentiment » peut être considéré comme un synonyme de l’opinion individuelle détaillée dans la première définition ; ce terme ne doit pas être confondu avec ses définitions alternatives telles que l’état affectif ou le penchant4. Un
1. http://www.larousse.fr/dictionnaires/francais/opinion/56197 2. https://www.amazon.fr/
3. https://www.tripadvisor.fr/
texte est considéré comme subjectif lorsqu’il exprime une opinion – nous reviendrons sur la notion de subjectivité dans la Section 1.2.
Les travaux en fouille d’opinions se sont longtemps focalisés sur les opinions individuelles formulées dans les critiques en ligne. Ce n’est que plus récemment, depuis des travaux pion-niers tels que [Lin et al., 2006, 2008; Paul et al., 2010; Popescu et Pennacchiotti, 2010], que les chercheurs ont étudié les opinions collectives (par exemple, les opinions politiques), désormais exprimées massivement dans les médias sociaux. Dans le présent chapitre, nous nous intéres-serons essentiellement à ces premiers travaux sur les opinions individuelles, qui ont établi les bases de la fouille d’opinions. Les travaux sur l’analyse de points de vue (ou, autrement dit, l’analyse d’opinions collectives) – qui sont au cœur du problème étudié dans cette thèse – seront abordés en détail dans le Chapitre 2. Par conséquent, sauf en cas de mention expli-cite du contraire, nous utiliserons simplement « fouille d’opinions » pour désigner la fouille d’opinions individuelles dans le reste de ce chapitre.
1.1.2 Motivations et applications
Depuis l’apparition du phénomène populairement nommé « Web 2.0 »5, les internautes
se sont vus offrir de nouvelles possibilités en matière d’interaction et de sociabilité en ligne. Les nouveaux services proposés permettent aux utilisateurs d’Internet de générer leur propre contenu et ainsi exprimer leurs opinions, par exemple sous la forme de billets de blog, ou encore par l’intermédiaire de posts sur des plateformes de réseaux sociaux telles que Twit-ter6 et Facebook7. Ainsi, en 2016, le nombre d’utilisateurs de médias sociaux était estimé à 2, 34 milliards dans le monde8. D’après un rapport du Centre de Recherche pour l’Étude et l’Observation des Conditions de Vie (CRÉDOC9) de 2016 [Croutte et Lautié, 2016], le pour-centage d’internautes français membres de réseaux sociaux s’élevait à 56 % sur l’ensemble des classes d’âge, et 84 % pour les moins de 40 ans. Les critiques publiées sur les sites de com-merce en ligne tels que Amazon et TripAdvisor jouent également un rôle prépondérant pour les consommateurs. Selon un sondage du Pew Research Center10 réalisé en 2016 auprès de 4 787 adultes américains, 82 % des personnes interrogées ont déclaré consulter les notes et les critiques en ligne lorsqu’elles achètent un produit pour la première fois [Smith et Anderson, 2016]. De plus, 39 % ont déjà partagé leur opinion vis-à-vis d’un produit dans les médias sociaux.
Analysons un exemple pour montrer l’intérêt des systèmes de fouille d’opinions vis-à-vis des critiques en ligne. La Figure 1.1 montre un extrait des critiques de la tablette Fire rédigées sur Amazon.11Un total de 859 critiques en français ont été postées par les utilisateurs d’Ama-zon qui ont acheté ce produit. On peut observer qu’Amad’Ama-zon indique par un histogramme les
5. http://www.oreilly.com/pub/a//web2/archive/what-is-web-20.html 6. https://twitter.com/ 7. https://www.facebook.com/ 8. https://www.statista.com/statistics/278414/number-of-worldwide-social-network-users/ 9. http://www.credoc.fr/ 10. http://www.pewresearch.org/ 11. https://www.amazon.fr/Amazon-Tablette-Fire-7-Pouces-8Go/dp/B00ZDWLEEG/
proportions des différentes notes attribuées (entre une et cinq étoiles). On note également qu’une critique positive et une critique négative sont mises en avant en haut de la page. Le reste de la page contient ensuite la liste de toutes les critiques, qu’il est éventuellement possible de trier par note. L’acheteur potentiel qui ne se contente pas de la note moyenne et souhaite prendre en compte les critiques pour prendre sa décision d’achat se verra contraint de lire une par une un grand nombre de ces critiques afin d’avoir une idée précise de la qualité du produit. Cette lecture s’avère rébarbative et coûteuse en temps.
Par conséquent, un système capable de fournir automatiquement un résumé des diffé-rentes opinions exprimées sur un produit permettrait de réduire considérablement les efforts de l’utilisateur. Un tel résumé consisterait par exemple à présenter les aspects positifs et négatifs du produit ciblé par les critiques – nous reviendrons sur la notion d’aspect dans la Section 1.3.2. Un tel résumé n’est pas seulement utile pour les utilisateurs, il l’est aussi pour l’entreprise qui a fabriqué le produit : savoir quels aspects du produit ont été appréciés ou non permet de corriger ses défauts ou en proposer une version améliorée dans le futur. Plus généralement, le contenu généré par les internautes vis-à-vis d’un produit – dans des critiques en ligne, sur des blogs ou sur les réseaux sociaux – permet à l’entreprise concernée de surveiller l’image publique de sa marque (faire du brand monitoring) [Kim, 2006]. Gérer sa réputation est également un élément clé pour les acteurs politiques.
Ainsi, le développement de systèmes de fouille d’opinions est une tâche critique avec un impact à la fois économique et politique. Cette raison a motivé l’intérêt des chercheurs – en particulier dans le domaine du traitement automatique du langage naturel et celui de la recherche d’information – et la nécessité d’évaluer ces systèmes a mené au développement de benchmarks sur la fouille d’opinions dans des campagnes d’évaluation telles que TREC12 (Text REtrieval Conference) en 2006 [Ounis et al., 2006], et SemEval13(Semantic Evaluation
Workshop) entre 2007 et 2017 [Kiritchenko et Mohammad, 2016; Mohammad et al., 2016;
Nakov et al., 2016, 2013; Pontiki et al., 2016, 2014; Rosenthal et al., 2015; Strapparava et Mihalcea, 2007; Wu, 2010]. Dans la section qui suit, nous décrivons les défis que présente la construction d’un système de fouille d’opinions.
1.1.3 Défis
Étant donné que la fouille d’opinions est une instance de la fouille de textes, il est légitime de se demander ce qui rend cette première tâche spécifique et difficile. Par exemple, qu’est-ce qui différencie la classification de textes positifs et négatifs de la classification de courriels indésirables (spam) et de courriels désirables (ham) [Russell et Norvig, 2010] ? Le niveau de difficulté d’une tâche de classification de textes est lié aux différences lexicales entre les classes : plus les classes utilisent un vocabulaire distinct, plus il sera facile d’assigner un texte à la bonne classe. Les courriels indésirables sont souvent des publicités, par exemple pour des sites pornographiques ou des médicaments tels que le viagra. Le lexique de ce genre de contenu est généralement distinct de celui des courriels désirables, traitant par exemple de
12. http://trec.nist.gov/
Figure 1.2 – Processus complet de fouille d’opinions.
sujets professionnels. Cependant, la différence entre un texte d’opinion positive et un texte d’opinion négative est plus subtile. Il est possible que les deux textes traitent du même thème (par exemple, un film de cinéma donné), induisant ainsi une grande similarité lexicale entre les classes positives et négatives. De plus, bien que certains mots tels que « super » et « mauvais » semblent indiquer de manière fiable la classe d’opinions, ignorer la négation de ces adjectifs faussera la classification. Par ailleurs, une opinion peut être exprimée de manière implicite (« Je ne reviendrai pas dans ce restaurant. ») ou peut même inclure de l’ironie (« Bravo les bleus pour votre excellent match ! ») [Karoui et al., 2015]. Ainsi, la fouille d’opinions nécessite d’être abordée différemment de la fouille de textes classiques.
1.1.4 Processus de fouille d’opinions
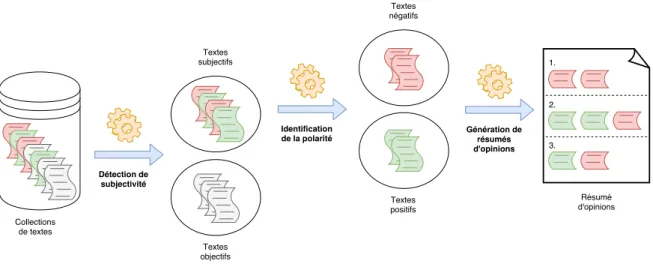
La fouille d’opinions peut être considérée comme un processus en plusieurs étapes qui prend en entrée un ensemble de textes sur une cible (target – par exemple, un produit ou une personnalité) et fournit en sortie un résumé agrégeant les opinions exprimées dans le texte vis-à-vis de la cible ou éventuellement vis-vis-à-vis des aspects de la cible [Dave et al., 2003]. L’aspect d’une cible est une caractéristique, un attribut ou un élément composant de la cible ; nous reviendrons plus en détail sur cette notion dans la Section 1.3. On peut ainsi découper le processus de fouille d’opinions en trois étapes principales, illustrées dans la Figure 1.2 :
1. détecter les textes subjectifs, c’est-à-dire les textes exprimant une opinion vis-à-vis d’une cible donnée ;
2. identifier si l’opinion exprimée dans chaque texte subjectif est positive ou négative à l’égard de la cible et éventuellement à l’égard de ses aspects ;
3. former un résumé des différentes opinions présentes dans l’ensemble de textes.
Notons que dans ce processus nous supposons avoir déjà à disposition un ensemble de textes pertinents vis-à-vis de la cible. Obtenir un tel ensemble de textes, par exemple à partir d’une requête formulée en langage naturel, est généralement loin d’être trivial – c’est le cœur même
de la tâche de la recherche d’information. Cependant, ce type de pré-filtrage basé sur la pertinence ne nécessite pas de traitement propre aux textes d’opinions. Nous n’aborderons donc pas cette phase de recherche des textes pertinents dans ce mémoire. Pour un aperçu plus détaillé sur les techniques utilisées en recherche d’information, le lecteur peut se référer aux ouvrages de référence de Baeza-Yates et Ribeiro-Neto [1999] et de Manning et al. [2008].
Dans le reste de ce chapitre, nous détaillons les travaux de l’état de l’art associés à cha-cune des trois étapes du processus de fouille d’opinions. La Section 1.2 présente les approches permettant de détecter si un texte est subjectif. Dans la Section 1.3, nous décrivons les diffé-rentes méthodes d’identification de la polarité des opinions (c’est-à-dire l’orientation positive ou négative des opinions). Enfin, la Section 1.4 passe en revue les travaux sur la génération de résumés d’opinions à partir des opinions extraites à l’issue des étapes précédentes.
1.2
Détection de subjectivité
Une tâche préliminaire à l’analyse des opinions contenues dans une collection de textes consiste à détecter les documents ou portions de documents subjectifs, c’est-à-dire exprimant des opinions. En effet, certains documents peuvent s’avérer purement factuels (par exemple, un article de presse relatant un évènement sportif) alors que d’autres documents mentionnant des sujets plus polémiques reflètent les opinions de leurs auteurs (par exemple, un essai politique). De plus, un document exprimant une opinion n’est pas nécessairement subjectif dans son intégralité. Par exemple, une critique en ligne sur un téléphone mobile peut contenir une phrase telle que « J’ai commandé le modèle blanc. », qui ne porte aucune marque d’opinion et pourrait aussi bien être utilisée dans une critique positive que dans une critique négative.
La détection de subjectivité constitue ainsi un problème à part entière – qui se révèle en réalité être souvent plus difficile que l’analyse subséquente de la polarité des opinions [Mihal-cea et al., 2007]. Afin d’encourager la recherche sur ce problème, la campagne d’évaluation TREC a proposé en 2006 une tâche de recherche d’opinions sur les blogs [Ounis et al., 2006]. Dans le cadre de cette tâche, un document est jugé subjectif s’il contient « une expression explicite d’opinion ou de sentiment vis-à-vis de la cible, révélant une position personnelle de l’auteur » (traduit de l’anglais). Le but de TREC Blog 2006 était ainsi d’identifier les documents (c’est-à-dire les posts de blogs) à la fois pertinents vis-à-vis d’un sujet donné et subjectifs. D’autres travaux ont porté sur la détection de subjectivité au niveau de la phrase [Hatzivassiloglou et Wiebe, 2000; Wiebe et al., 1999; Yu et Hatzivassiloglou, 2003] ou au niveau des expressions [Riloff et Wiebe, 2003; Wiebe et Wilson, 2002] plutôt qu’au niveau du document. De manière générale, les approches pour la détection de subjectivité reposent sur une combinaison des méthodes suivantes :
— l’utilisation de lexiques de mots d’opinions externes, construits manuellement ou auto-matiquement [Mishne, 2006; Oard et al., 2006; Yang et al., 2006] ;
— l’exploitation de marqueurs linguistiques tels que les parties du discours (part of speech) en considérant par exemple les pronoms et les adjectifs comme des marques de
subjec-tivité [Hatzivassiloglou et Wiebe, 2000; Riloff et Wiebe, 2003; Wiebe et Wilson, 2002; Yang et al., 2006; Yu et Hatzivassiloglou, 2003] ;
— la mise en œuvre de classifieurs supervisés tels que les machines à vecteurs de support (SVM) et classifieurs bayésiens naïfs [Hatzivassiloglou et Wiebe, 2000; Wiebe et Wilson, 2002; Wiebe et al., 1999; Yu et Hatzivassiloglou, 2003; Zhang et Yu, 2006] ;
— l’application de méthodes symboliques basées sur des règles et des motifs, définis ma-nuellement ou automatiquement [Riloff et Wiebe, 2003; Wiebe et Wilson, 2002]. Une fois que les documents ou fragments de texte subjectifs ont été détectés, les opinions qui y sont exprimées peuvent en être extraites et leur polarité identifiée.
1.3
Identification de la polarité et de la nuance des opinions
En fouille d’opinions individuelles, les opinions sont considérées comme positives, néga-tives ou une nuance de ces extrêmes. On désigne ainsi par degré de polarité ou simplement
polarité la position d’une opinion sur cet axe comprenant les différents niveaux de négativité
et de positivité – on trouve également le terme « orientation sémantique » dans la littéra-ture [Hatzivassiloglou et McKeown, 1997]. La polarité peut être définie par des catégories telles que « positif », « neutre », et « négatif », ou encore par des nombres dénotant le degré de positivité ou de négativité. Par exemple, la polarité peut être définie entre 1 et 5, où 1 désigne une polarité très négative, et 5 désigne une polarité très positive – cela correspond au format des notes données dans les critiques en ligne sur Amazon et TripAdvisor.
Comme nous l’avons précisé dans la Section 1.1.1, une opinion individuelle est ciblée. Cette cible peut être de diverses natures suivant le type de données d’opinions concernées. Par exemple, une critique en ligne cible généralement un produit commercial (par exemple, un téléphone mobile) ou un service (par exemple, un hébergement dans un hôtel). Un message sur un réseau social ou sur un blog peut quant à lui porter sur une célébrité, telle qu’un artiste ou un homme politique. Ainsi, on peut considérer qu’un texte d’opinion dont la polarité est positive révèle l’approbation globale de l’auteur du texte vis-à-vis de la cible, et inversement un texte négatif dénote une dépréciation globale. Cette considération présuppose implicitement qu’un texte d’opinion est homogène : il est soit totalement positif, soit totalement négatif (éventuellement neutre) vis-à-vis de la cible étudiée. La Section 1.3.1 détaille les travaux basés sur ce postulat en considérant les opinions à un niveau de granularité grossière
(coarse-grained opinions), c’est-à-dire en étudiant les opinions associées à la cible dans sa globalité.
1.3.1 Cas des opinions de granularité grossière
Les premières approches de fouille d’opinions s’intéressent à l’opinion globale exprimée vis-à-vis de la cible dans un document subjectif. Autrement dit, ces travaux considèrent qu’un document est associé à une polarité unique et qu’un document ne forme pas un mélange d’opi-nions de polarités différentes. Cette considération est d’autant plus valide que le document
est court. Par exemple, une critique en ligne témoigne généralement de l’appréciation globale ou de la dépréciation globale du produit ou service.
À partir de cette supposition, de nombreux travaux se sont donnés pour but l’identification automatique de la polarité globale au niveau du document [Dave et al., 2003; Gamon, 2004; Goldberg et Zhu, 2006; McDonald et al., 2007; Pang et Lee, 2004, 2005; Pang et al., 2002; Turney, 2002] ou de la phrase [Kim et Hovy, 2004; McDonald et al., 2007; Socher et al., 2011; Yu et Hatzivassiloglou, 2003]. Ces différentes approches peuvent être regroupées en fonction du niveau de supervision adopté et la nature du problème d’apprentissage de l’identification de polarité :
— classification supervisée : [Dave et al., 2003; Gamon, 2004; Kim et Hovy, 2004; McDonald
et al., 2007; Pang et Lee, 2004; Pang et al., 2002; Yu et Hatzivassiloglou, 2003] ;
— classification semi-supervisée ou non supervisée : [Socher et al., 2011; Turney, 2002] ; — régression : [Goldberg et Zhu, 2006; Pang et Lee, 2005].
Nous détaillons dans le reste de cette section les travaux adoptant ces différents paradigmes.
1.3.1.1 Classification supervisée
Les méthodes de classification supervisée abordent le problème d’identification de polarité en se basant sur deux catégories (positif et négatif) [Dave et al., 2003; Gamon, 2004; Pang et Lee, 2004; Pang et al., 2002; Yu et Hatzivassiloglou, 2003] ou trois catégories (positif, négatif, ou neutre) [Kim et Hovy, 2004]. Elles sont basées sur des classifieurs tels que le classifieur bayésien naïf [Dave et al., 2003; Pang et Lee, 2004; Pang et al., 2002], la machine à vecteurs de support [Gamon, 2004; Pang et Lee, 2004; Pang et al., 2002] ou le classifieur à maximum d’entropie [Pang et al., 2002]. McDonald et al. [2007] proposent quant à eux de traiter le pro-blème de classification en utilisant un modèle apparenté aux champs aléatoires conditionnels (conditional random fields). Les traits (features) des différents classifieurs sont essentiellement basés sur les n-grammes [Dave et al., 2003; Gamon, 2004; McDonald et al., 2007; Pang et al., 2002], les parties du discours [Gamon, 2004; McDonald et al., 2007; Pang et al., 2002], la position relative des mots [Dave et al., 2003; Pang et al., 2002], ou sur des ressources externes telles que WordNet [Dave et al., 2003] ou des lexiques de mots d’opinions [Yu et Hatzivas-siloglou, 2003]. Dans [Pang et Lee, 2004], l’identification de polarité est réalisée à partir de traits extraits des phrases subjectives uniquement, obtenues par formulation d’un problème de graphes basé sur la coupe minimale (minimum cut).
1.3.1.2 Classification semi-supervisée ou non supervisée
L’inconvénient majeur des classifieurs supervisés est leur dépendance vis-à-vis d’une quan-tité importante d’exemples annotés, utilisés lors de la phase d’apprentissage. Ces données annotées sont généralement difficiles à obtenir et peuvent représenter un coup prohibitif lorsque l’annotation doit être réalisée manuellement. Par conséquent, l’identification de la
polarité d’un texte a également été abordé sous l’angle d’un problème de classification semi-supervisée [Socher et al., 2011], voire non semi-supervisée [Turney, 2002]. L’approche semi-semi-supervisée proposée dans [Socher et al., 2011] est basée sur un réseau de neurones auto-encodeur récursif (recursive autoencoder ) pour prédire la distribution d’opinions au niveau de la phrase. Elle tire avantage de la nature compositionnelle de la sémantique en déduisant la polarité d’une phrase à partir de celle des mots qui la composent. L’algorithme décrit par Turney [2002] est quant à lui totalement non supervisé. Il estime dans un premier temps la polarité des adjectifs et des adverbes présents dans des critiques d’opinion en calculant leur proximité, basée sur l’information mutuelle ponctuelle (PMI – pointwise mutual information), avec des mots tels que poor et excellent. La polarité globale de la critique est ensuite déduite en agrégeant la polarité des adjectifs et adverbes qui la composent.
1.3.1.3 Régression
Une vision alternative de la tâche d’identification de la polarité est de la considérer comme un problème de régression. Désormais, le but n’est plus d’assigner au texte d’opinion une catégorie parmi {positif, négatif} ou parmi {positif, négatif, neutre}, mais plutôt de lui associer un nombre (éventuellement réel) dénotant le degré de polarité du texte. En adoptant le système de notes utilisé sur Amazon et TripAdvisor (entre 1 et 5), l’objectif des modèles de régression est de prédire les notes des différentes critiques. Une telle approche a été proposée par Pang et Lee [2005], basée sur une régression par machine à vecteurs de support. La fonction de similarité entre deux textes, nécessaire à la tâche de régression, est définie à partir de la proportion de phrases positives et de phrases négatives dans les textes, apprise par un classifieur bayésien naïf entraîné sur un corpus externe de critiques positives et négatives. Ce travail a par la suite été étendu dans [Goldberg et Zhu, 2006] où est présentée une approche semi-supervisée basée sur une représentation des documents sous forme de graphe, permettant ainsi d’exploiter des données d’apprentissage non annotées.
Les approches présentées dans cette section suppose qu’un texte d’opinion, tel qu’un do-cument ou une phrase, reflète une opinion de polarité unique vis-à-vis de la cible étudiée. En réalité, un tel texte est souvent nuancé et n’exprime pas uniquement une opinion globale-ment positive ou globaleglobale-ment négative. Par exemple, le spectateur d’un film de cinéma peut expliquer dans une critique qu’il trouve l’histoire intéressante et le jeu d’acteurs de qualité, mais que les décors sont de mauvaise facture et les effets spéciaux pauvres. On voit émerger à travers cet exemple la notion d’aspect : un aspect d’un texte d’opinion est une caractéristique ou un attribut de la cible sur lequel l’auteur a émis un avis. Dans l’exemple précédent, la cible est le film de cinéma et les aspects sont l’histoire, le jeu d’acteurs, les décors et les effets spéciaux. Cette approche de l’opinion à un niveau de granularité plus fin est connue dans la littérature sous le nom de fouille d’opinions basées sur les aspects (aspect-based opinion
mi-ning). La Section 1.3.2 décrit les différents travaux identifiant la polarité des opinions basées
1.3.2 Cas des opinions basées sur les aspects
Pour une cible donnée, l’identification de la polarité des opinions basées sur des aspects consiste à déterminer la polarité associée à chaque aspect de la cible. Cependant, les aspects d’une cible ne sont généralement pas connus a priori, et ils varient d’une cible à une autre. Par exemple, les aspects d’un téléphone mobile sont sa batterie, son appareil photo, son poids, etc., alors que les aspects d’un film de cinéma sont son histoire, son jeu d’acteurs, ses décors, etc. Ainsi, une difficulté additionnelle dans la fouille d’opinions basées sur des aspects est d’extraire les aspects dans un premier temps. La seconde étape, similaire à l’identification de la polarité d’opinions de granularité grossière, associe une polarité aux différents aspects extraits.
Les opinions basées sur des aspects ont été le sujet d’un important nombre de travaux et ont également fait l’objet de plusieurs tâches dans la campagne d’évaluation SemEval [Pontiki
et al., 2016, 2014]. On distingue dans la littérature deux types de travaux sur la fouille
d’opinions basées sur les aspects :
— Certains travaux séparent le problème en deux phases et traitent l’une de ces phases ou les deux : extraction des aspects de la cible dans le texte [Brody et Elhadad, 2010; Hu et Liu, 2004; Liu et al., 2005; Popescu et Etzioni, 2005] et identification des opinions (ainsi que leur polarité) associées aux aspects [Brody et Elhadad, 2010; Ding et al., 2008; Hu et Liu, 2004; Popescu et Etzioni, 2005; Snyder et Barzilay, 2007].
— D’autres travaux proposent de découvrir conjointement les aspects et les opinions [He
et al., 2012, 2013; Jo et Oh, 2011; Lim et Buntine, 2014; Lin et He, 2009; Lin et al.,
2012; Rahman et Wang, 2016; Wang et al., 2016; Zhao et al., 2010].
Nous détaillons dans le reste de cette section les approches permettant l’extraction des as-pects, les approches identifiant les opinions exprimées vis-à-vis des asas-pects, et les approches proposant une solution unifiée à ces deux problèmes.
1.3.2.1 Extraction des aspects
L’extraction d’aspects peut être considérée comme une instance du problème d’extraction d’informations (information extraction) : l’objectif est d’inférer des informations structurées (la liste des aspects) à partir de données non structurées (les textes d’opinions). Certains travaux ont ainsi opté pour une approche symbolique basée sur des règles et sur les parties de discours [Hu et Liu, 2004; Liu et al., 2005]. La méthode utilisée dans [Hu et Liu, 2004; Liu et al., 2005] se base sur un algorithme de fouille d’associations (association mining) en s’appuyant sur l’hypothèse que les aspects sont souvent représentés par des syntagmes nominaux. De manière similaire, l’approche de Popescu et Etzioni [2005] extrait les aspects en calculant l’information mutuelle ponctuelle entre les syntagmes nominaux et la cible. Une méthode basée sur l’allocation de Dirichlet latente (latent dirichlet allocation) a également été proposée pour découvrir les aspects, en supposant l’équivalence entre thèmes et aspects [Brody et Elhadad, 2010].
1.3.2.2 Identification des opinions associées aux aspects
De même que pour l’extraction d’aspects, l’identification des opinions peut exploiter les parties de discours. De nombreux travaux associent l’expression de l’opinion aux adjectifs et aux adverbes [Brody et Elhadad, 2010; Ding et al., 2008; Hu et Liu, 2004]. Ainsi, les mots d’opinions associés à un aspect peuvent être détectés en considérant les adjectifs et adverbes situés à proximité des mots dénotant des aspects (extraits lors de la phase précé-dente). Popescu et Etzioni [2005] adoptent une approche alternative basée sur un analyseur de dépendance (dependency parser ) et un ensemble de règles définies manuellement.
Afin d’identifier la polarité des opinions extraites, Hu et Liu [2004] définissent tout d’abord manuellement une liste de 30 graines (seed words) clairement positifs ou négatifs (par exemple,
fantastic, cool, dull, bad). Ensuite, la polarité des mots d’opinions est estimée en exploitant
les relations de synonymie et d’antonymie issues de WordNet avec les germes. Une méthode similaire est mise en œuvre dans [Brody et Elhadad, 2010], où la polarité des mots d’opinions est identifiée à partir d’une liste de germes et l’application de l’algorithme de propagation d’étiquettes (label propagation). Ding et al. [2008] étendent les mots d’opinions aux noms et aux verbes en utilisant les germes proposés dans [Hu et Liu, 2004]. La négation est également prise en compte dans [Brody et Elhadad, 2010; Ding et al., 2008] : la polarité d’une opinion est inversée à proximité d’un mot de négation. Dans [Popescu et Etzioni, 2005], l’identifica-tion de la polarité est effectuée en appliquant un algorithme de relaxal’identifica-tion d’étiquettes (label
relaxation) initialisé à partir de mots d’opinion classés par la méthode de Turney [2002].
Snyder et Barzilay [2007] ont quant à eux proposé une approche supervisée basée sur PRanking, un algorithme de perceptron en ligne. L’avantage de cette méthode est qu’elle ne nécessite pas l’identification préalable des mots d’opinions et elle est capable de prendre en compte la négation sans la définition manuelle de règles.
1.3.2.3 Approches conjointes
Plutôt que d’identifier les aspects et les opinions en deux étapes, de multiples travaux ont proposé de modéliser ces deux dimensions conjointement [He et al., 2012, 2013; Jo et Oh, 2011; Kim et al., 2013; Lim et Buntine, 2014; Lin et He, 2009; Lin et al., 2012; Mei et al., 2007; Moghaddam et Ester, 2011; Rahman et Wang, 2016; Wang et al., 2016; Zhao et al., 2010]. Pour ce faire, ces travaux se basent sur des approches de type modèle thématique probabiliste14 (probabilistic topic models) tels que l’analyse sémantique latente probabiliste
(probabilistic latent semantic analysis – PLSA) [Hofmann, 1999, 2001] ou l’allocation de Diri-chlet latente (latent DiriDiri-chlet allocation – LDA) [Blei et al., 2001, 2003]. Les approches basées sur les modèles thématiques supposent l’équivalence entre thème et aspect, et considèrent la polarité de l’opinion comme une dimension supplémentaire au thème. Les mots de polarité positive et les mots de polarité négative sont distingués en se basant sur des lexiques de
mots d’opinions tels que MPQA (multi-perspective question answering) [Wilson et al., 2005] et SentiWordNet [Baccianella et al., 2010].
Mei et al. [2007] s’inspirent de PLSA en utilisant un mélange de lois multinomiales afin de capturer à la fois la composante thématique et la composante d’opinion. Les travaux décrits dans [He et al., 2012, 2013; Jo et Oh, 2011; Kim et al., 2013; Lim et Buntine, 2014; Lin et He, 2009; Lin et al., 2012; Moghaddam et Ester, 2011; Rahman et Wang, 2016; Wang
et al., 2016; Zhao et al., 2010] étendent quant à eux le modèle LDA. Dans leur modèle
précurseur JST (joint sentiment/topic), Lin et He [2009]; Lin et al. [2012] modifient LDA en ajoutant simplement une variable latente dénotant la polarité au niveau du mot – en plus de la variable latente dénotant le thème. Cette approche est par la suite adaptée dans [He
et al., 2012, 2013] pour intégrer la dimension temporelle et ainsi modéliser la dynamique
à la fois thématique et d’opinions. Dans [Moghaddam et Ester, 2011], les mots d’opinions et les mots thématiques sont tout d’abord extraits par la méthode non supervisée décrite dans [Moghaddam, 2010], puis à partir de ces observations, le modèle identifie les notes (ratings) latentes – indicateurs similaires à la polarité dans le cadre des critiques en ligne – et les aspects latents. Lim et Buntine [2014] ont proposé un modèle inspiré de [Moghaddam et Ester, 2011] basé sur le processus de Pitman-Yor (Pitman-Yor process) et adapté à Twitter en intégrant les hashtags. Le modèle de Wang et al. [2016] fait quant à lui la distinction entre les mots dénotant un aspect, les mots traduisant une opinion générale et les mots exprimant une opinion spécifique à un aspect. De plus, afin d’intégrer la corrélation entre mots d’opinions issus de plusieurs domaines, les auteurs exploitent le modèle d’urnes de Pólya généralisées, qui étend le phénomène de co-occurrence des modèles thématiques.
Les modèles décrits précédemment ont choisi de modéliser les aspects (c’est-à-dire les thèmes) au niveau du mot. Une alternative est de supposer que chaque phrase se voit assigner un aspect unique. Il a en effet été observé qu’une phrase de critique en ligne, par exemple, contient souvent un unique aspect [Jo et Oh, 2011]. Cette hypothèse a été adoptée dans plu-sieurs modélisations conjointes des thèmes et des opinions [Jo et Oh, 2011; Kim et al., 2013; Rahman et Wang, 2016; Zhao et al., 2010]. Zhao et al. [2010] ont par ailleurs ajouté une dimension supervisée à leur approche par un modèle de maximum d’entropie afin de faciliter l’identification des aspects et des opinions. De manière similaire au modèle de Wang et al. [2016], le modèle proposé dans [Zhao et al., 2010] distingue les mots vides de sens (background
words), les mots d’opinions et d’aspects généraux, et les mots d’opinions et d’aspects
spéci-fiques. L’approche de Rahman et Wang [2016] s’inspire quant à elle des modèles de Markov cachés en supposant une dépendance markovienne entre les thèmes des phrases successives d’une critique en ligne. L’intuition derrière cette dépendance est que le même aspect peut être discuté sur deux phrases successives, soit en conservant la même opinion, soit en nuan-çant l’opinion (c’est-à-dire en inversant la polarité). Plutôt qu’organiser tous les aspects à un même niveau de granularité, l’approche décrite dans [Kim et al., 2013] forme automatiquement une hiérarchie d’aspects – et de sous-aspects, etc. – en adoptant une méthode similaire aux processus stochastiques des restaurants chinois emboîtés (nested chinese restaurant process).
Après l’identification des opinions d’un texte et de leur polarité (éventuellement vis-à-vis d’aspects), l’étape finale d’un système de fouille d’opinions consiste à organiser les opinions
![Figure 1.3 – Exemple de résumé d’opinions visuel basé sur les aspects. Capture d’écran du système Opinion Observer tirée de [Hu et Liu, 2004].](https://thumb-eu.123doks.com/thumbv2/123doknet/2227037.15614/38.892.146.757.159.618/figure-exemple-resume-opinions-capture-systeme-opinion-observer.webp)