Estimations de satisfaisabilité
Texte intégral
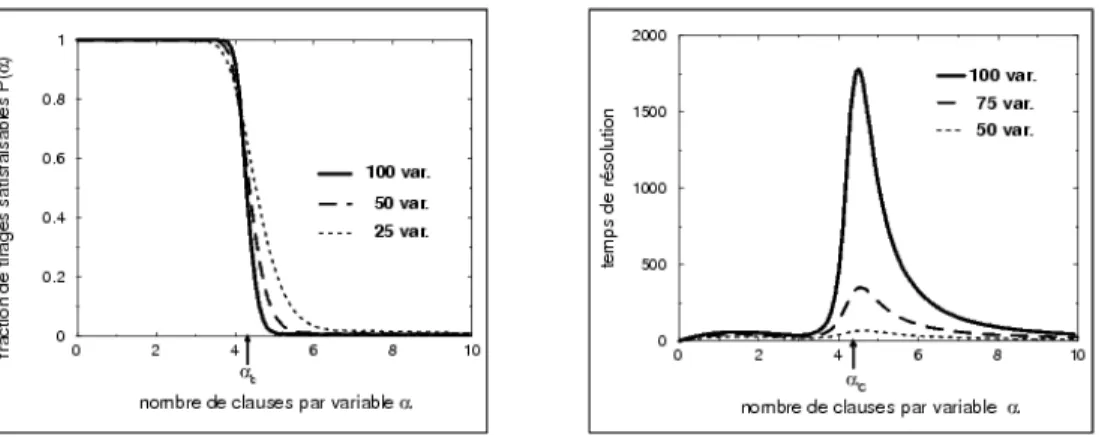
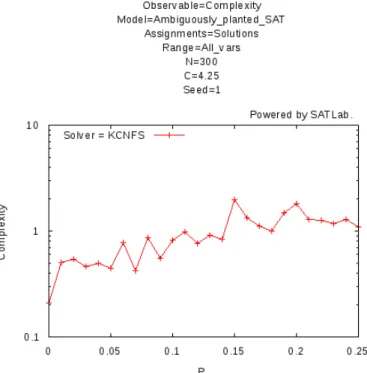
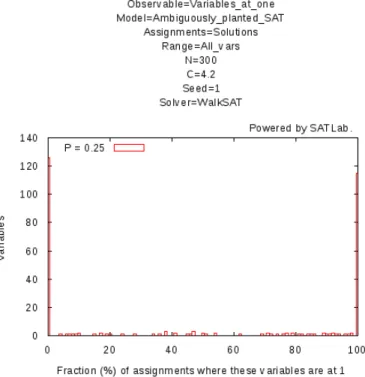
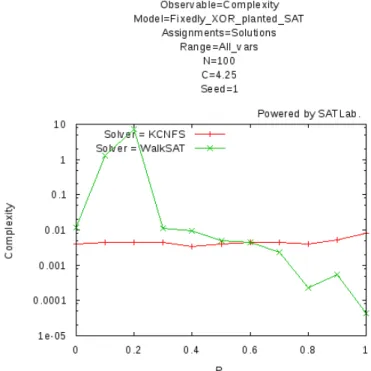
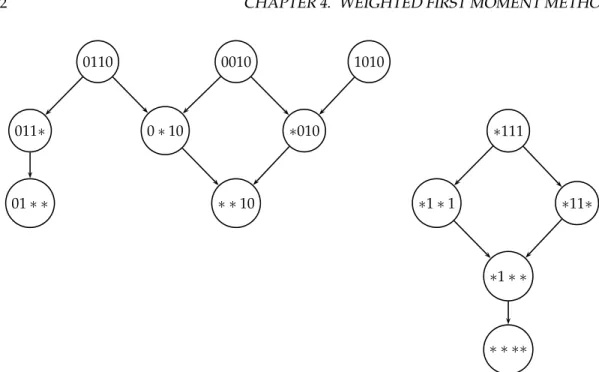
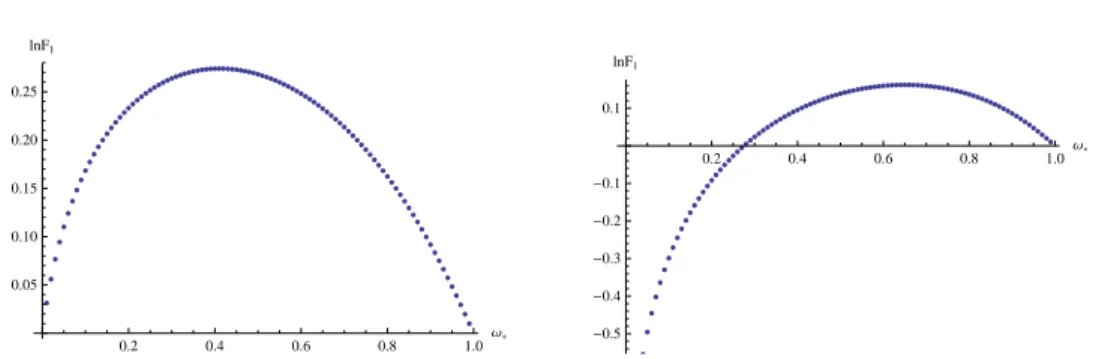
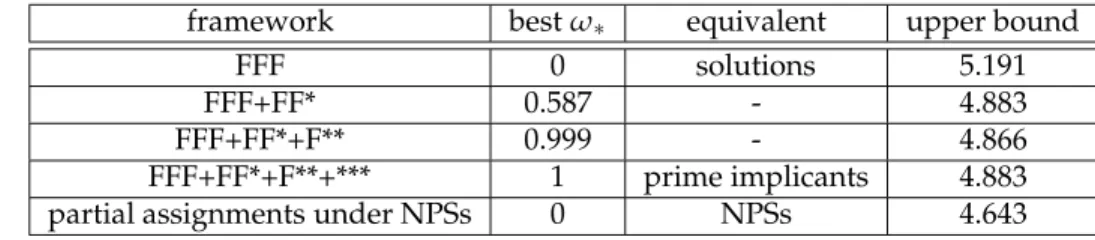
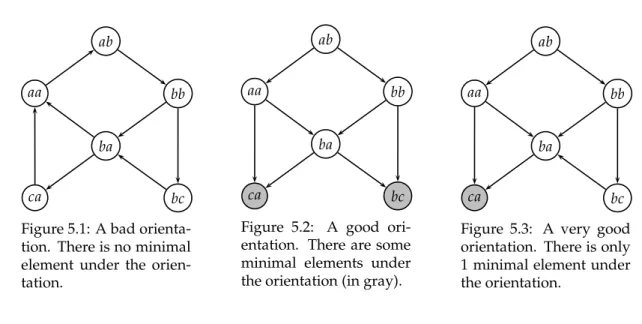
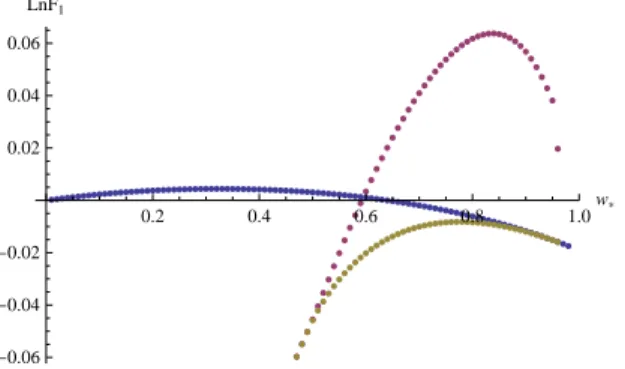
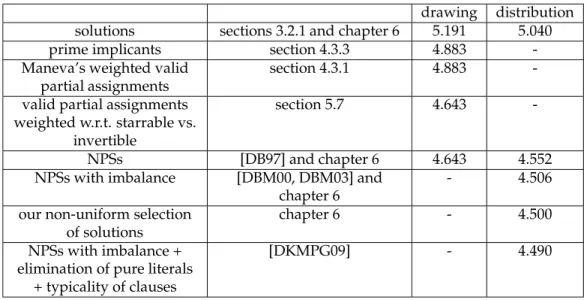
Figure
Documents relatifs
Corrigendum to “Differentiating the stochastic entropy in negatively curved spaces under conformal changes”.. Tome 71, n o 1
In the 1 st step the thermal break effect is not taken into account, and a spring with rotational stiffness is used to represent the bending moment effect from the floor applied
Collaborative design scenario: in the sketching application (1) the user draws the object outlines in the drawing plane, (2) draws an extrusion path, (3) and generates the 3D
FARE UNA PRESSIONE BREVE MAKE A SHORT PRESS IL LED SI ACCENDE THE LED TURNS ON. 1 1 minuto / 1 minute 2 3 minuti / 3 minutes 3 5 minuti / 5 minutes 4 15 minuti / 15
Four cpu-times are reported: (1) OSAC LP: time taken by CPLEX to solve the first lin- ear relaxation (2) OSAC MIP: time taken to get the first in- teger solution, (3) MEDAC: time taken
As early as 1983, we discovered an agronomic fact of prime importance in Côte d’Ivoire: in a plot with declining yields, removing three in four trees increased the final yield per
Les végétaux à racines nues seront pralinés au moment de la plantation avec un mélange de composition 1/3 d’eau, 1/3 de terre végétale et 1/3 de compost selon la réglementation
Thus folding yields a symmetric continued fraction expansion, perturbed.. (cf [3]) in the given example by the word ah , c - 1,1, ah -
