Backtesting Value-at-Risk: A Duration-Based Approach
Texte intégral
Figure
Documents relatifs
Gwenaël PIGANEAU, Directeur de recherche, CNRS Adam EYRE-WALKER, Professor, University of Sussex Carole SMADJA, Chargée de recherche, CNRS Laurent DURET, Directeur de recherche,
In fact, a model that does not satisfy the independence property can lead to clusterings of margin exceedances even if it has the correct average number of violations.. (7) This
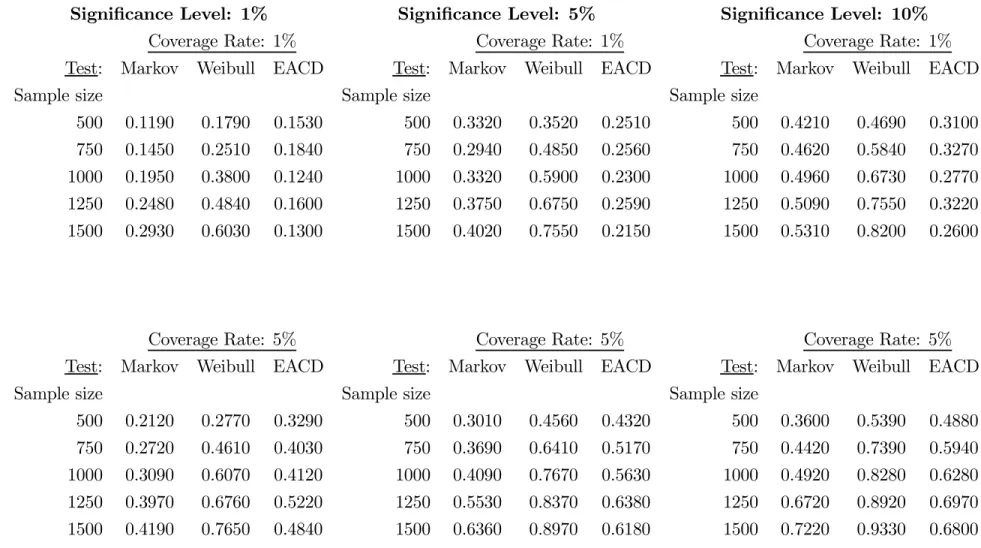
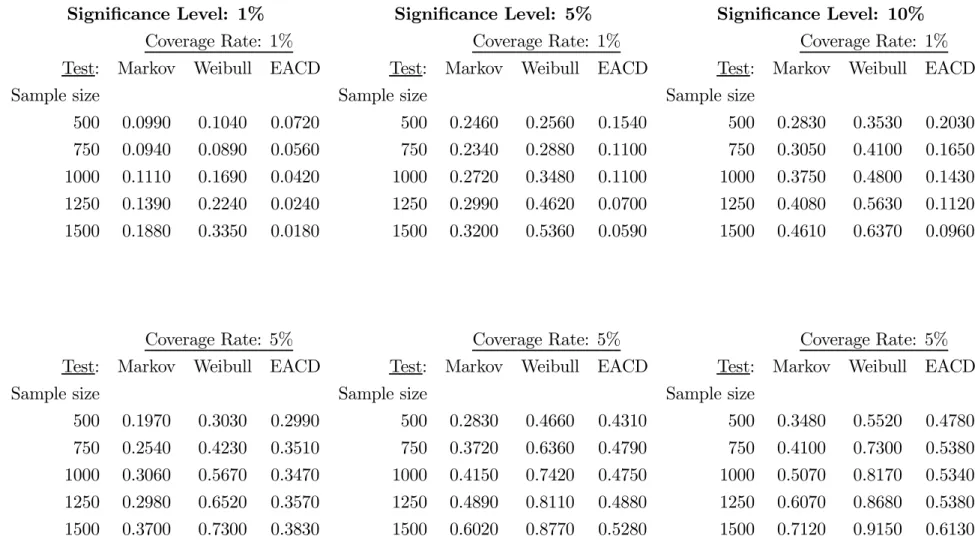
On the contrary, the backtests based on bootstrap critical values display empirical sizes that are close to the nominal size of 5% for all reported sample sizes and risk levels..
In addition, the existing tests can be used to identify relevant pieces of model executions that make it possible to reach a given state in the property automaton, helping
This dissimilarity measure is used in conjunction with the McDiarmid Theorem within the a contrario approach in order to design a robust Variable Size Block Matching (VSBM)
a backtesting sample size of 250, the LR independence tests have an e¤ec- tive power that ranges from 4.6% (continuous Weibull test) to 7.3% (discrete Weibull test) for a
‘ Density Forecast Evaluation’ approach to the assessment of the tail of return distribution only, we suggest adapting a test of the ‘ Event Probability Forecast
13 conditional coverage tests are used, namely 7 dynamic binary specifications DB, 6 DQ tests (Engle and Manganelli, 2004) including several lags of the violations variable and VaR,
