Deep Sets for Generalization in RL
Texte intégral
Figure
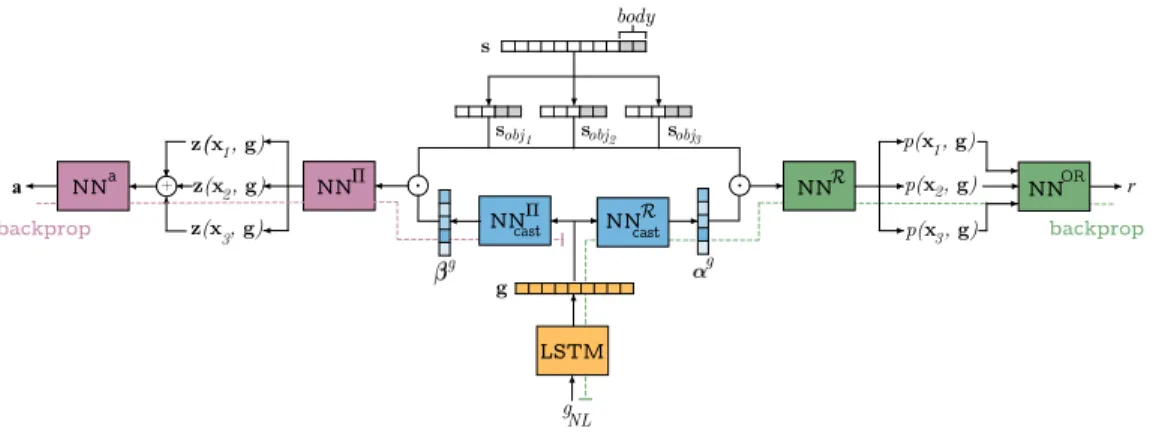
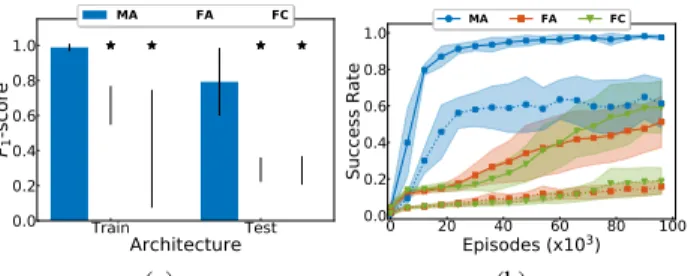
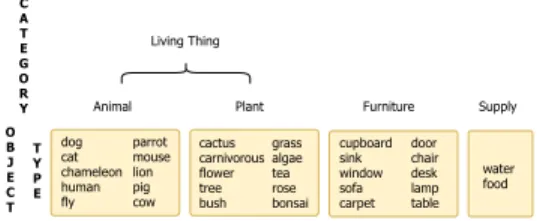
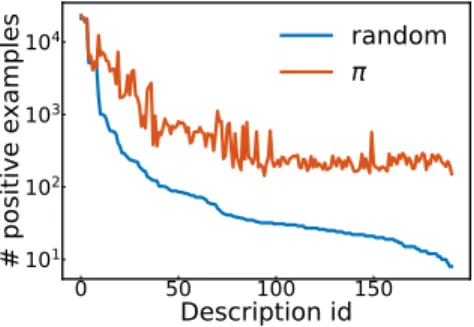

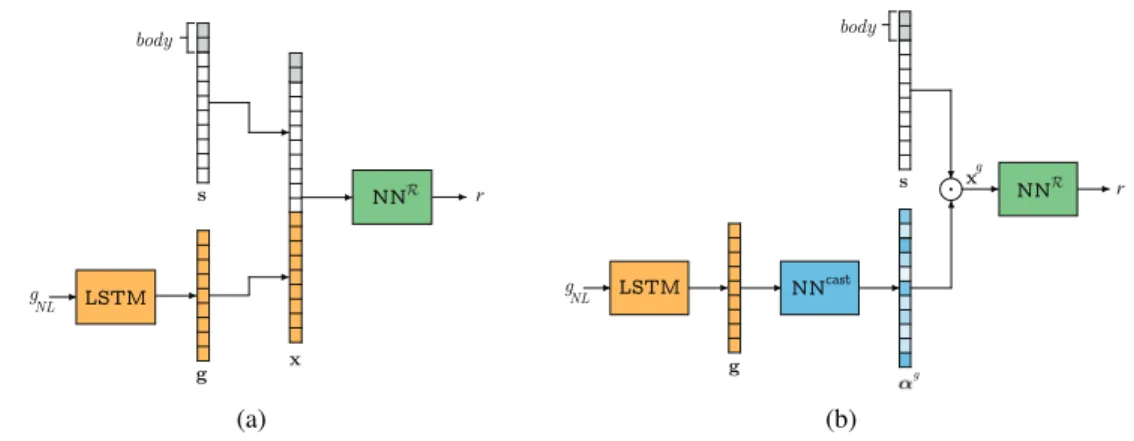
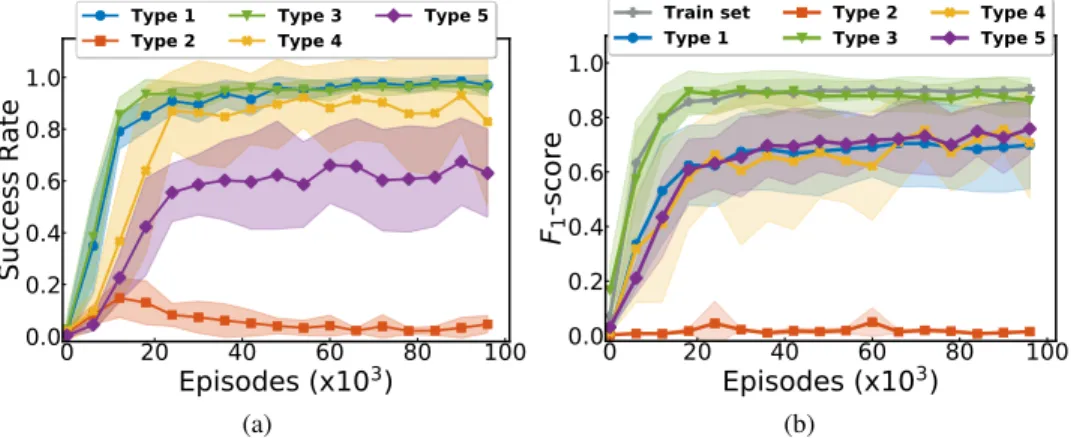
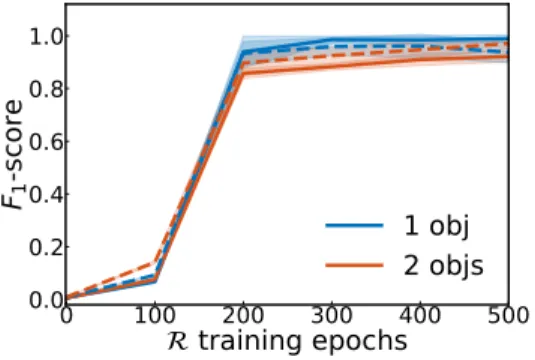
Documents relatifs
From the preceding section, we know that the distribution of the random path is given by a Markov chain: Each left step is followed by a right step, and each right step is followed by
If business and human capital actor-networks that represent powerful specializations in the region mobilize around particular strategies, they may influence the output of
is sufficient to diffuse elements, grow grains, and develop semiconductor products • Cu rich grown absorbers contain fewer defects and have a potential to produce higher V oc
L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des
GREEN yellow...
light blue dark blue.. www.lutinbazar.fr
The leaf-specific LOX2, LOX3, LOX4, and LOX6 contrib- ute to the synthesis of jasmonate precursors and play specific roles in growth restriction in response to wounding or in
Pocket Reference / Red Hat Linux Pocket Administrator / Petersen/ 222974-8 / Chapter 1 Color profile: Generic CMYK printer profile.. Composite
